 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pretraining Conformer with ASR or ASV for Anti-Spoofing Countermeasure
Jul 04, 2023
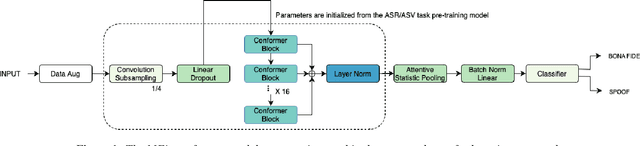
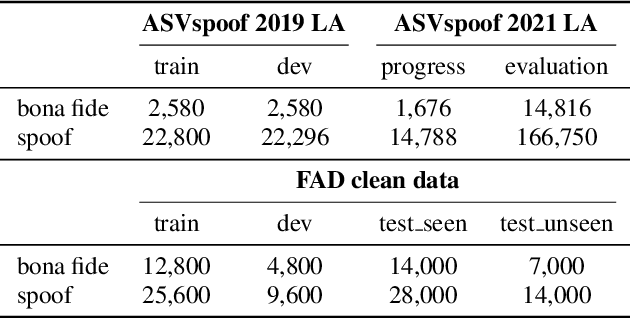
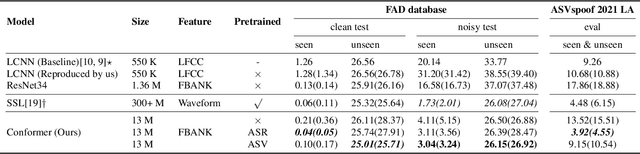
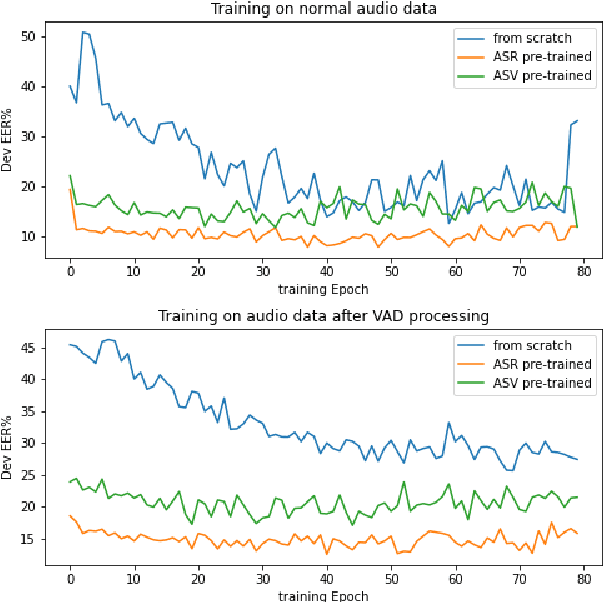
This paper introduces the Multi-scale Feature Aggregation Conformer (MFA-Conformer) structure for audio anti-spoofing countermeasure (CM). MFA-Conformer combines a convolutional neural networkbased on the Transformer, allowing it to aggregate global andlocal information. This may benefit the anti-spoofing CM system to capture the synthetic artifacts hidden both locally and globally. In addition, given the excellent performance of MFA Conformer on automatic speech recognition (ASR) and automatic speaker verification (ASV) tasks, we present a transfer learning method that utilizes pretrained Conformer models on ASR or ASV tasks to enhance the robustness of CM systems. The proposed method is evaluated on both Chinese and Englishs poofing detection databases. On the FAD clean set, the MFA-Conformer model pretrained on the ASR task achieves an EER of 0.038%, which dramatically outperforms the baseline. Moreover, experimental results demonstrate that proposed transfer learning method on Conformer is effective on pure speech segments after voice activity detection processing.
Learning ECG signal features without backpropagation
Jul 04, 2023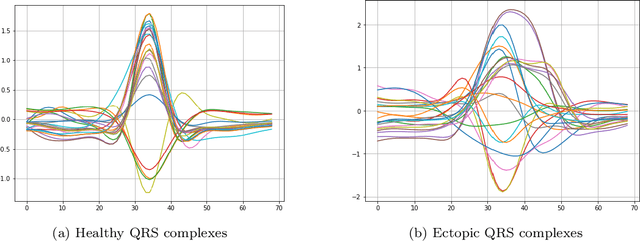
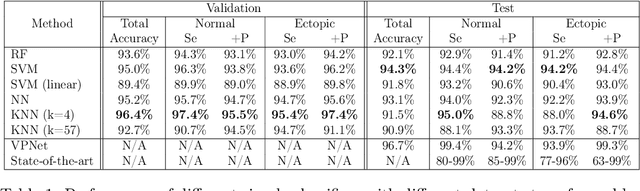
Representation learning has become a crucial area of research in machine learning, as it aims to discover efficient ways of representing raw data with useful features to increase the effectiveness, scope and applicability of downstream tasks such as classification and prediction. In this paper, we propose a novel method to generate representations for time series-type data. This method relies on ideas from theoretical physics to construct a compact representation in a data-driven way, and it can capture both the underlying structure of the data and task-specific information while still remaining intuitive, interpretable and verifiable. This novel methodology aims to identify linear laws that can effectively capture a shared characteristic among samples belonging to a specific class. By subsequently utilizing these laws to generate a classifier-agnostic representation in a forward manner, they become applicable in a generalized setting. We demonstrate the effectiveness of our approach on the task of ECG signal classification, achieving state-of-the-art performance.
The Distortion of Binomial Voting Defies Expectation
Jun 27, 2023In computational social choice, the distortion of a voting rule quantifies the degree to which the rule overcomes limited preference information to select a socially desirable outcome. This concept has been investigated extensively, but only through a worst-case lens. Instead, we study the expected distortion of voting rules with respect to an underlying distribution over voter utilities. Our main contribution is the design and analysis of a novel and intuitive rule, binomial voting, which provides strong expected distortion guarantees for all distributions.
Object Detection in Hyperspectral Image via Unified Spectral-Spatial Feature Aggregation
Jun 14, 2023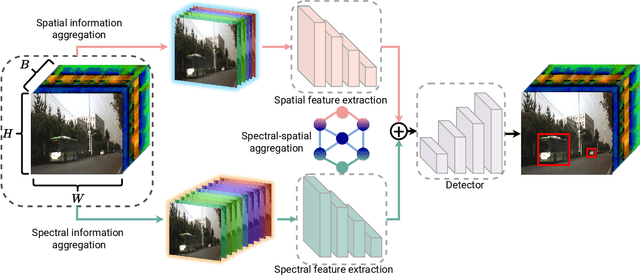

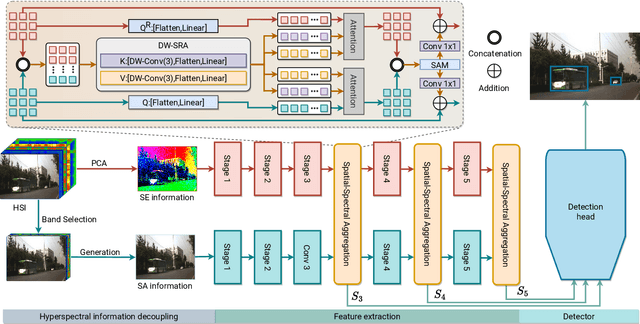
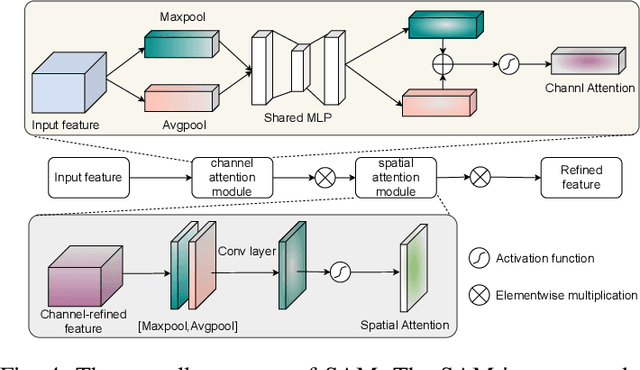
Deep learning-based hyperspectral image (HSI) classification and object detection techniques have gained significant attention due to their vital role in image content analysis, interpretation, and wider HSI applications. However, current hyperspectral object detection approaches predominantly emphasize either spectral or spatial information, overlooking the valuable complementary relationship between these two aspects. In this study, we present a novel \textbf{S}pectral-\textbf{S}patial \textbf{A}ggregation (S2ADet) object detector that effectively harnesses the rich spectral and spatial complementary information inherent in hyperspectral images. S2ADet comprises a hyperspectral information decoupling (HID) module, a two-stream feature extraction network, and a one-stage detection head. The HID module processes hyperspectral images by aggregating spectral and spatial information via band selection and principal components analysis, consequently reducing redundancy. Based on the acquired spatial and spectral aggregation information, we propose a feature aggregation two-stream network for interacting spectral-spatial features. Furthermore, to address the limitations of existing databases, we annotate an extensive dataset, designated as HOD3K, containing 3,242 hyperspectral images captured across diverse real-world scenes and encompassing three object classes. These images possess a resolution of 512x256 pixels and cover 16 bands ranging from 470 nm to 620 nm. Comprehensive experiments on two datasets demonstrate that S2ADet surpasses existing state-of-the-art methods, achieving robust and reliable results. The demo code and dataset of this work are publicly available at \url{https://github.com/hexiao-cs/S2ADet}.
Functional PCA and Deep Neural Networks-based Bayesian Inverse Uncertainty Quantification with Transient Experimental Data
Jul 10, 2023Inverse UQ is the process to inversely quantify the model input uncertainties based on experimental data. This work focuses on developing an inverse UQ process for time-dependent responses, using dimensionality reduction by functional principal component analysis (PCA) and deep neural network (DNN)-based surrogate models. The demonstration is based on the inverse UQ of TRACE physical model parameters using the FEBA transient experimental data. The measurement data is time-dependent peak cladding temperature (PCT). Since the quantity-of-interest (QoI) is time-dependent that corresponds to infinite-dimensional responses, PCA is used to reduce the QoI dimension while preserving the transient profile of the PCT, in order to make the inverse UQ process more efficient. However, conventional PCA applied directly to the PCT time series profiles can hardly represent the data precisely due to the sudden temperature drop at the time of quenching. As a result, a functional alignment method is used to separate the phase and amplitude information of the transient PCT profiles before dimensionality reduction. DNNs are then trained using PC scores from functional PCA to build surrogate models of TRACE in order to reduce the computational cost in Markov Chain Monte Carlo sampling. Bayesian neural networks are used to estimate the uncertainties of DNN surrogate model predictions. In this study, we compared four different inverse UQ processes with different dimensionality reduction methods and surrogate models. The proposed approach shows an improvement in reducing the dimension of the TRACE transient simulations, and the forward propagation of inverse UQ results has a better agreement with the experimental data.
Joint Salient Object Detection and Camouflaged Object Detection via Uncertainty-aware Learning
Jul 10, 2023
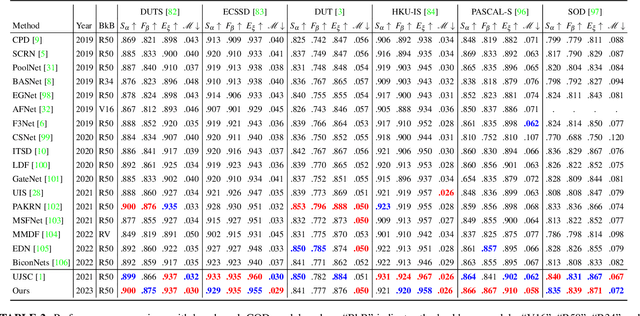

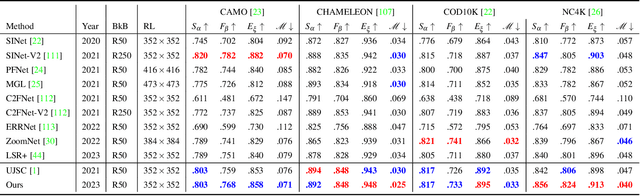
Salient objects attract human attention and usually stand out clearly from their surroundings. In contrast, camouflaged objects share similar colors or textures with the environment. In this case, salient objects are typically non-camouflaged, and camouflaged objects are usually not salient. Due to this inherent contradictory attribute, we introduce an uncertainty-aware learning pipeline to extensively explore the contradictory information of salient object detection (SOD) and camouflaged object detection (COD) via data-level and task-wise contradiction modeling. We first exploit the dataset correlation of these two tasks and claim that the easy samples in the COD dataset can serve as hard samples for SOD to improve the robustness of the SOD model. Based on the assumption that these two models should lead to activation maps highlighting different regions of the same input image, we further introduce a contrastive module with a joint-task contrastive learning framework to explicitly model the contradictory attributes of these two tasks. Different from conventional intra-task contrastive learning for unsupervised representation learning, our contrastive module is designed to model the task-wise correlation, leading to cross-task representation learning. To better understand the two tasks from the perspective of uncertainty, we extensively investigate the uncertainty estimation techniques for modeling the main uncertainties of the two tasks, namely task uncertainty (for SOD) and data uncertainty (for COD), and aiming to effectively estimate the challenging regions for each task to achieve difficulty-aware learning. Experimental results on benchmark datasets demonstrate that our solution leads to both state-of-the-art performance and informative uncertainty estimation.
A Versatile Door Opening System with Mobile Manipulator through Adaptive Position-Force Control and Reinforcement Learning
Jul 10, 2023

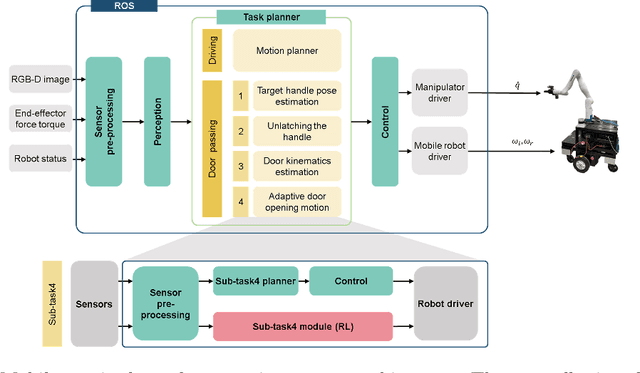
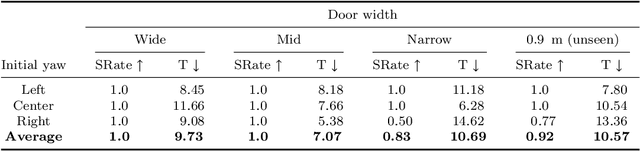
The ability of robots to navigate through doors is crucial for their effective operation in indoor environments. Consequently, extensive research has been conducted to develop robots capable of opening specific doors. However, the diverse combinations of door handles and opening directions necessitate a more versatile door opening system for robots to successfully operate in real-world environments. In this paper, we propose a mobile manipulator system that can autonomously open various doors without prior knowledge. By using convolutional neural networks, point cloud extraction techniques, and external force measurements during exploratory motion, we obtained information regarding handle types, poses, and door characteristics. Through two different approaches, adaptive position-force control and deep reinforcement learning, we successfully opened doors without precise trajectory or excessive external force. The adaptive position-force control method involves moving the end-effector in the direction of the door opening while responding compliantly to external forces, ensuring safety and manipulator workspace. Meanwhile, the deep reinforcement learning policy minimizes applied forces and eliminates unnecessary movements, enabling stable operation across doors with different poses and widths. The RL-based approach outperforms the adaptive position-force control method in terms of compensating for external forces, ensuring smooth motion, and achieving efficient speed. It reduces the maximum force required by 3.27 times and improves motion smoothness by 1.82 times. However, the non-learning-based adaptive position-force control method demonstrates more versatility in opening a wider range of doors, encompassing revolute doors with four distinct opening directions and varying widths.
Map Point Selection for Visual SLAM
Jun 22, 2023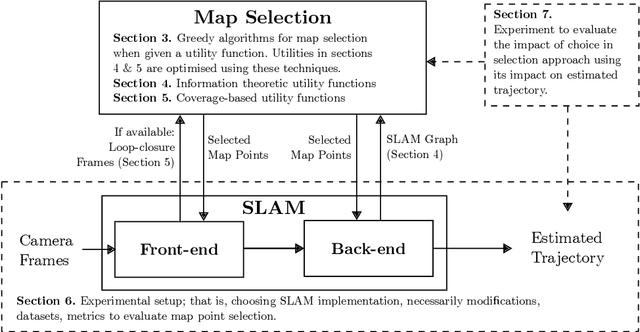

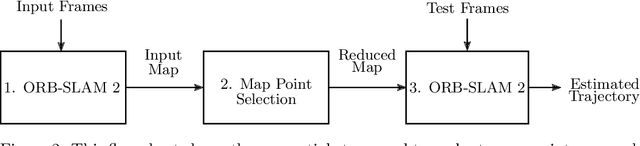
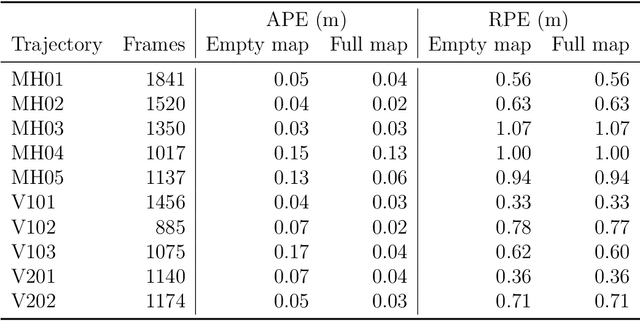
Simultaneous localisation and mapping (SLAM) play a vital role in autonomous robotics. Robotic platforms are often resource-constrained, and this limitation motivates resource-efficient SLAM implementations. While sparse visual SLAM algorithms offer good accuracy for modest hardware requirements, even these more scalable sparse approaches face limitations when applied to large-scale and long-term scenarios. A contributing factor is that the point clouds resulting from SLAM are inefficient to use and contain significant redundancy. This paper proposes the use of subset selection algorithms to reduce the map produced by sparse visual SLAM algorithms. Information-theoretic techniques have been applied to simpler related problems before, but they do not scale if applied to the full visual SLAM problem. This paper proposes a number of novel information\hyp{}theoretic utility functions for map point selection and optimises these functions using greedy algorithms. The reduced maps are evaluated using practical data alongside an existing visual SLAM implementation (ORB-SLAM 2). Approximate selection techniques proposed in this paper achieve trajectory accuracy comparable to an offline baseline while being suitable for online use. These techniques enable the practical reduction of maps for visual SLAM with competitive trajectory accuracy. Results also demonstrate that SLAM front-end performance can significantly impact the performance of map point selection. This shows the importance of testing map point selection with a front-end implementation. To exploit this, this paper proposes an approach that includes a model of the front-end in the utility function when additional information is available. This approach outperforms alternatives on applicable datasets and highlights future research directions.
Learning to Incentivize Information Acquisition: Proper Scoring Rules Meet Principal-Agent Model
Mar 15, 2023
We study the incentivized information acquisition problem, where a principal hires an agent to gather information on her behalf. Such a problem is modeled as a Stackelberg game between the principal and the agent, where the principal announces a scoring rule that specifies the payment, and then the agent then chooses an effort level that maximizes her own profit and reports the information. We study the online setting of such a problem from the principal's perspective, i.e., designing the optimal scoring rule by repeatedly interacting with the strategic agent. We design a provably sample efficient algorithm that tailors the UCB algorithm (Auer et al., 2002) to our model, which achieves a sublinear $T^{2/3}$-regret after $T$ iterations. Our algorithm features a delicate estimation procedure for the optimal profit of the principal, and a conservative correction scheme that ensures the desired agent's actions are incentivized. Furthermore, a key feature of our regret bound is that it is independent of the number of states of the environment.
Meta-Learning Adversarial Bandit Algorithms
Jul 05, 2023We study online meta-learning with bandit feedback, with the goal of improving performance across multiple tasks if they are similar according to some natural similarity measure. As the first to target the adversarial online-within-online partial-information setting, we design meta-algorithms that combine outer learners to simultaneously tune the initialization and other hyperparameters of an inner learner for two important cases: multi-armed bandits (MAB) and bandit linear optimization (BLO). For MAB, the meta-learners initialize and set hyperparameters of the Tsallis-entropy generalization of Exp3, with the task-averaged regret improving if the entropy of the optima-in-hindsight is small. For BLO, we learn to initialize and tune online mirror descent (OMD) with self-concordant barrier regularizers, showing that task-averaged regret varies directly with an action space-dependent measure they induce. Our guarantees rely on proving that unregularized follow-the-leader combined with two levels of low-dimensional hyperparameter tuning is enough to learn a sequence of affine functions of non-Lipschitz and sometimes non-convex Bregman divergences bounding the regret of OMD.