 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Anti-spoofing Countermeasures Robustness through Joint Optimization and Transfer Learning
Jul 29, 2024Current research in synthesized speech detection primarily focuses on the generalization of detection systems to unknown spoofing methods of noise-free speech. However, the performance of anti-spoofing countermeasures (CM) system is often don't work as well in more challenging scenarios, such as those involving noise and reverberation. To address the problem of enhancing the robustness of CM systems, we propose a transfer learning-based speech enhancement front-end joint optimization (TL-SEJ) method, investigating its effectiveness in improving robustness against noise and reverberation. We evaluated the proposed method's performance through a series of comparative and ablation experiments. The experimental results show that, across different signal-to-noise ratio test conditions, the proposed TL-SEJ method improves recognition accuracy by 2.7% to 15.8% compared to the baseline. Compared to conventional data augmentation methods, our system achieves an accuracy improvement ranging from 0.7% to 5.8% in various noisy conditions and from 1.7% to 2.8% under different RT60 reverberation scenarios. These experiments demonstrate that the proposed method effectively enhances system robustness in noisy and reverberant conditions.
Proceedings of the Dialogue Robot Competition 2023
Jan 15, 2024The Dialogic Robot Competition 2023 (DRC2023) is a competition for humanoid robots (android robots that closely resemble humans) to compete in interactive capabilities. This is the third year of the competition. The top four teams from the preliminary competition held in November 2023 will compete in the final competition on Saturday, December 23. The task for the interactive robots is to recommend a tourism plan for a specific region. The robots can employ multimodal behaviors, such as language and gestures, to engage the user in the sightseeing plan they recommend. In the preliminary round, the interactive robots were stationed in a travel agency office, where visitors conversed with them and rated their performance via a questionnaire. In the final round, dialogue researchers and tourism industry professionals interacted with the robots and evaluated their performance. This event allows visitors to gain insights into the types of dialogue services that future dialogue robots should offer. The proceedings include papers on dialogue systems developed by the 12 teams participating in DRC2023, as well as an overview of the papers provided by all the teams.
Overview of Dialogue Robot Competition 2023
Jan 07, 2024We have held dialogue robot competitions in 2020 and 2022 to compare the performances of interactive robots using an android that closely resembles a human. In 2023, the third competition DRC2023 was held. The task of DRC2023 was designed to be more challenging than the previous travel agent dialogue tasks. Since anyone can now develop a dialogue system using LLMs, the participating teams are required to develop a system that effectively uses information about the situation on the spot (real-time information), which is not handled by ChatGPT and other systems. DRC2023 has two rounds, a preliminary round and the final round as well as the previous competitions. The preliminary round has held on Oct.27 -- Nov.20, 2023 at real travel agency stores. The final round will be held on December 23, 2023. This paper provides an overview of the task settings and evaluation method of DRC2023 and the preliminary round results.
Pretraining Conformer with ASR or ASV for Anti-Spoofing Countermeasure
Jul 04, 2023



This paper introduces the Multi-scale Feature Aggregation Conformer (MFA-Conformer) structure for audio anti-spoofing countermeasure (CM). MFA-Conformer combines a convolutional neural networkbased on the Transformer, allowing it to aggregate global andlocal information. This may benefit the anti-spoofing CM system to capture the synthetic artifacts hidden both locally and globally. In addition, given the excellent performance of MFA Conformer on automatic speech recognition (ASR) and automatic speaker verification (ASV) tasks, we present a transfer learning method that utilizes pretrained Conformer models on ASR or ASV tasks to enhance the robustness of CM systems. The proposed method is evaluated on both Chinese and Englishs poofing detection databases. On the FAD clean set, the MFA-Conformer model pretrained on the ASR task achieves an EER of 0.038%, which dramatically outperforms the baseline. Moreover, experimental results demonstrate that proposed transfer learning method on Conformer is effective on pure speech segments after voice activity detection processing.
Low Pass Filtering and Bandwidth Extension for Robust Anti-spoofing Countermeasure Against Codec Variabilities
Nov 12, 2022A reliable voice anti-spoofing countermeasure system needs to robustly protect automatic speaker verification (ASV) systems in various kinds of spoofing scenarios. However, the performance of countermeasure systems could be degraded by channel effects and codecs. In this paper, we show that using the low-frequency subbands of signals as input can mitigate the negative impact introduced by codecs on the countermeasure systems. To validate this, two types of low-pass filters with different cut-off frequencies are applied to countermeasure systems, and the equal error rate (EER) is reduced by up to 25% relatively. In addition, we propose a deep learning based bandwidth extension approach to further improve the detection accuracy. Recent studies show that the error rate of countermeasure systems increase dramatically when the silence part is removed by Voice Activity Detection (VAD), our experimental results show that the filtering and bandwidth extension approaches are also effective under the codec condition when VAD is applied.
Overview of Dialogue Robot Competition 2022
Oct 23, 2022



Although many competitions have been held on dialogue systems in the past, no competition has been organized specifically for dialogue with humanoid robots. As the first such attempt in the world, we held a dialogue robot competition in 2020 to compare the performances of interactive robots using an android that closely resembles a human. Dialogue Robot Competition 2022 (DRC2022) was the second competition, held in August 2022. The task and regulations followed those of the first competition, while the evaluation method was improved and the event was internationalized. The competition has two rounds, a preliminary round and the final round. In the preliminary round, twelve participating teams competed in performance of a dialogue robot in the manner of a field experiment, and then three of those teams were selected as finalists. The final round will be held on October 25, 2022, in the Robot Competition session of IROS2022. This paper provides an overview of the task settings and evaluation method of DRC2022 and the results of the preliminary round.
Combination of Time-domain, Frequency-domain, and Cepstral-domain Acoustic Features for Speech Commands Classification
Mar 30, 2022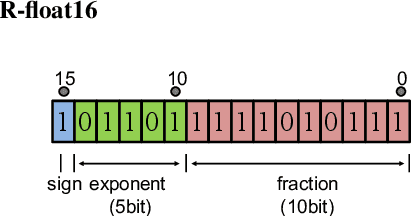
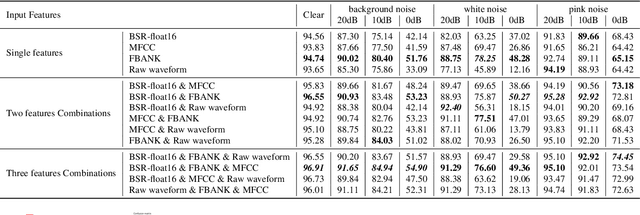
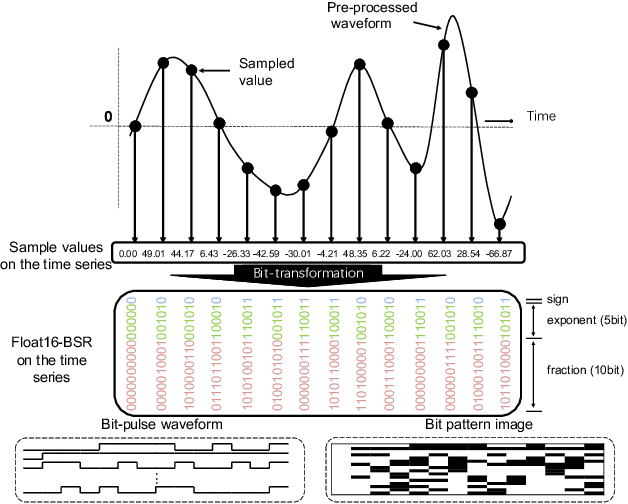
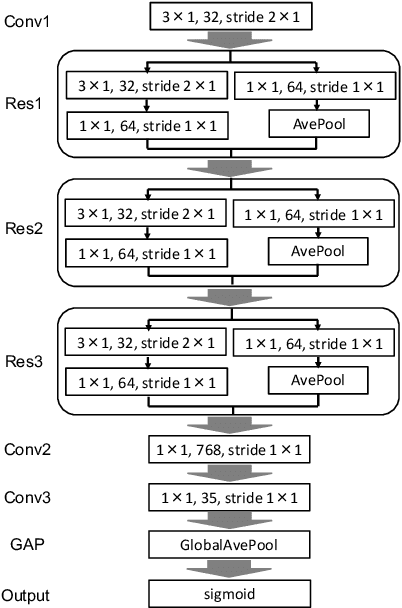
In speech-related classification tasks, frequency-domain acoustic features such as logarithmic Mel-filter bank coefficients (FBANK) and cepstral-domain acoustic features such as Mel-frequency cepstral coefficients (MFCC) are often used. However, time-domain features perform more effectively in some sound classification tasks which contain non-vocal or weakly speech-related sounds. We previously proposed a feature called bit sequence representation (BSR), which is a time-domain binary acoustic feature based on the raw waveform. Compared with MFCC, BSR performed better in environmental sound detection and showed comparable accuracy performance in limited-vocabulary speech recognition tasks. In this paper, we propose a novel improvement BSR feature called BSR-float16 to represent floating-point values more precisely. We experimentally demonstrated the complementarity among time-domain, frequency-domain, and cepstral-domain features using a dataset called Speech Commands proposed by Google. Therefore, we used a simple back-end score fusion method to improve the final classification accuracy. The fusion results also showed better noise robustness.
Frequency-Directional Attention Model for Multilingual Automatic Speech Recognition
Mar 29, 2022
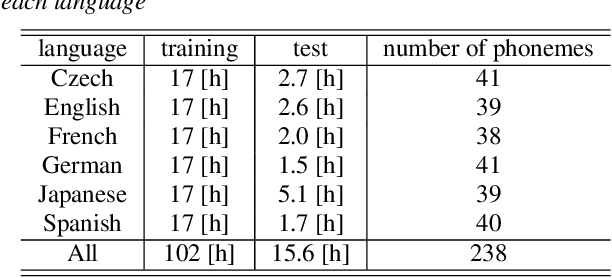
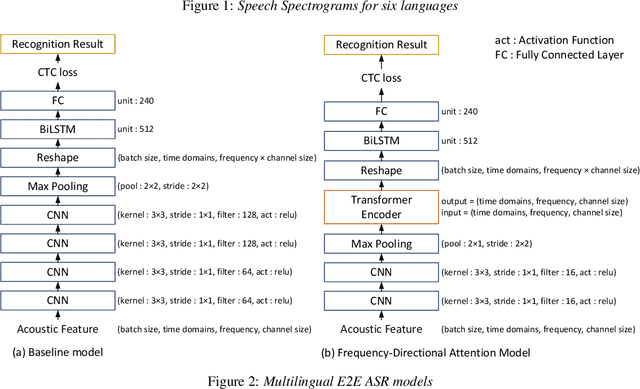

This paper proposes a model for transforming speech features using the frequency-directional attention model for End-to-End (E2E) automatic speech recognition. The idea is based on the hypothesis that in the phoneme system of each language, the characteristics of the frequency bands of speech when uttering them are different. By transforming the input Mel filter bank features with an attention model that characterizes the frequency direction, a feature transformation suitable for ASR in each language can be expected. This paper introduces a Transformer-encoder as a frequency-directional attention model. We evaluated the proposed method on a multilingual E2E ASR system for six different languages and found that the proposed method could achieve, on average, 5.3 points higher accuracy than the ASR model for each language by introducing the frequency-directional attention mechanism. Furthermore, visualization of the attention weights based on the proposed method suggested that it is possible to transform acoustic features considering the frequency characteristics of each language.
Peer Collaborative Learning for Polyphonic Sound Event Detection
Oct 07, 2021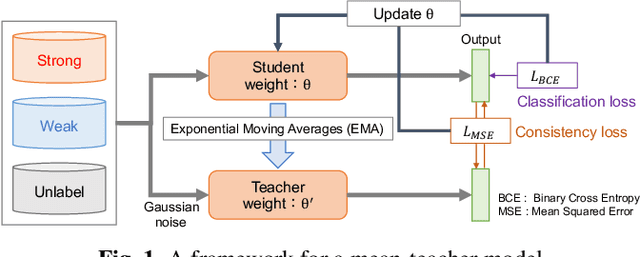
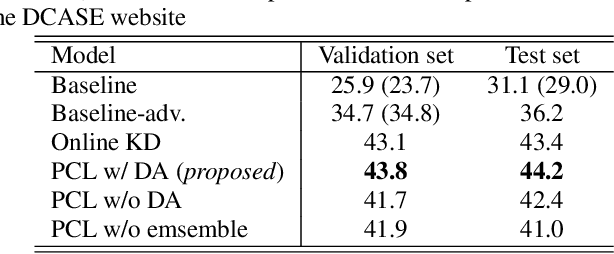
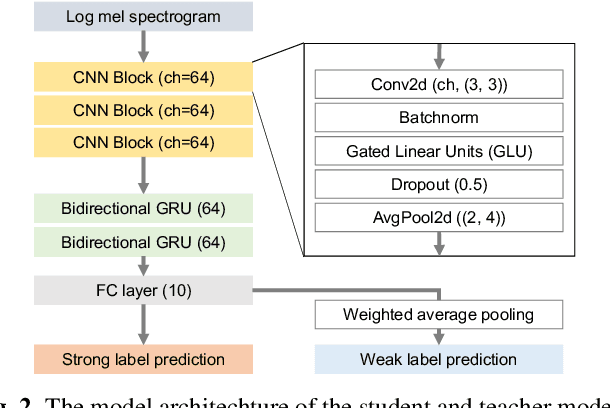
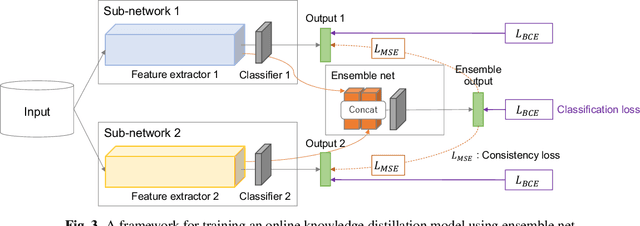
This paper describes that semi-supervised learning called peer collaborative learning (PCL) can be applied to the polyphonic sound event detection (PSED) task, which is one of the tasks in the Detection and Classification of Acoustic Scenes and Events (DCASE) challenge. Many deep learning models have been studied to find out what kind of sound events occur where and for how long in a given audio clip. The characteristic of PCL used in this paper is the combination of ensemble-based knowledge distillation into sub-networks and student-teacher model-based knowledge distillation, which can train a robust PSED model from a small amount of strongly labeled data, weakly labeled data, and a large amount of unlabeled data. We evaluated the proposed PCL model using the DCASE 2019 Task 4 datasets and achieved an F1-score improvement of about 10% compared to the baseline model.
ExKaldi-RT: A Real-Time Automatic Speech Recognition Extension Toolkit of Kaldi
Apr 03, 2021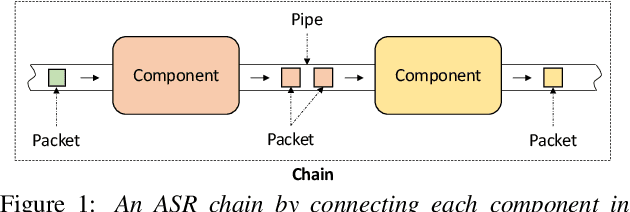

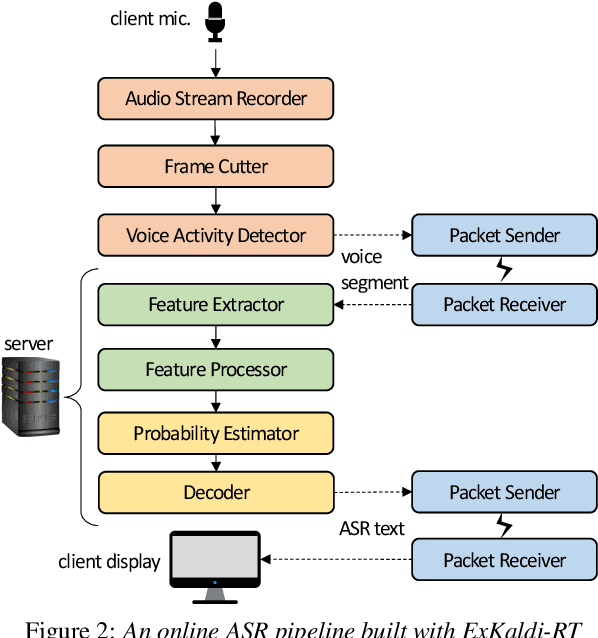
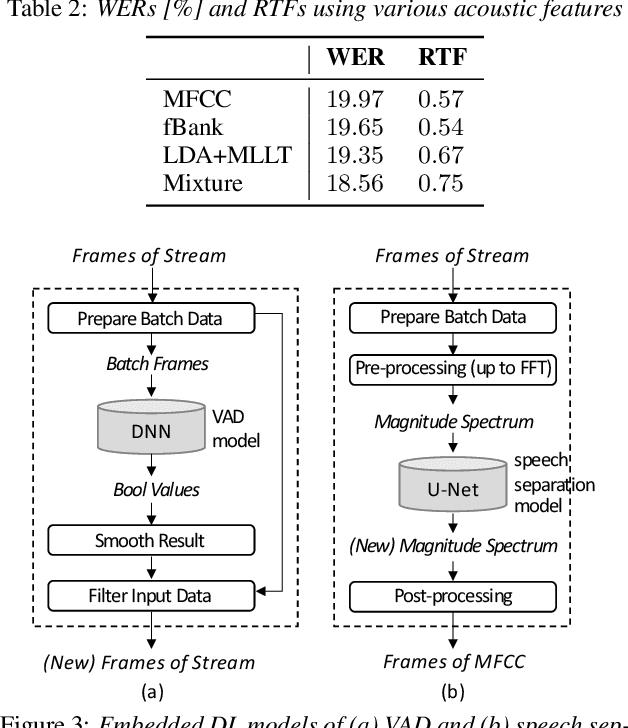
The availability of open-source software is playing a remarkable role in automatic speech recognition (ASR). Kaldi, for instance, is widely used to develop state-of-the-art offline and online ASR systems. This paper describes the "ExKaldi-RT," online ASR toolkit implemented based on Kaldi and Python language. ExKaldi-RT provides tools for providing a real-time audio stream pipeline, extracting acoustic features, transmitting packets with a remote connection, estimating acoustic probabilities with a neural network, and online decoding. While similar functions are available built on Kaldi, a key feature of ExKaldi-RT is completely working on Python language, which has an easy-to-use interface for online ASR system developers to exploit original research, for example, by applying neural network-based signal processing and acoustic model trained with deep learning frameworks. We performed benchmark experiments on the minimum LibriSpeech corpus, and showed that ExKaldi-RT could achieve competitive ASR performance in real-time.