 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Social Choice with Few Queries: A Moment-Based Approach
Mar 19, 2026Most social choice rules assume access to full rankings, while current alignment practice -- despite aiming for diversity -- typically treats voters as anonymous and comparisons as independent, effectively extracting only about one bit per voter. Motivated by this gap, we study social choice under an extreme communication budget in the linear social choice model, where each voter's utility is the inner product between a latent voter type and the embedding of the context and candidate. The candidate and voter spaces may be very large or even infinite. Our core idea is to model the electorate as an unknown distribution over voter types and to recover its moments as informative summary statistics for candidate selection. We show that one pairwise comparison per voter already suffices to select a candidate that maximizes social welfare, but this elicitation cannot identify the second moment and therefore cannot support objectives that account for inequality. We prove that two pairwise comparisons per voter, or alternatively a single graded comparison, identify the second moment; moreover, these richer queries suffice to identify all moments, and hence the entire voter-type distribution. These results enable principled solutions to a range of social choice objectives including inequality-aware welfare criteria such as taking into account the spread of voter utilities and choosing a representative subset.
The Distortion of Binomial Voting Defies Expectation
Jun 27, 2023In computational social choice, the distortion of a voting rule quantifies the degree to which the rule overcomes limited preference information to select a socially desirable outcome. This concept has been investigated extensively, but only through a worst-case lens. Instead, we study the expected distortion of voting rules with respect to an underlying distribution over voter utilities. Our main contribution is the design and analysis of a novel and intuitive rule, binomial voting, which provides strong expected distortion guarantees for all distributions.
The Goal-Gradient Hypothesis in Stack Overflow
Feb 14, 2020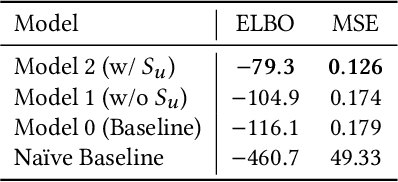
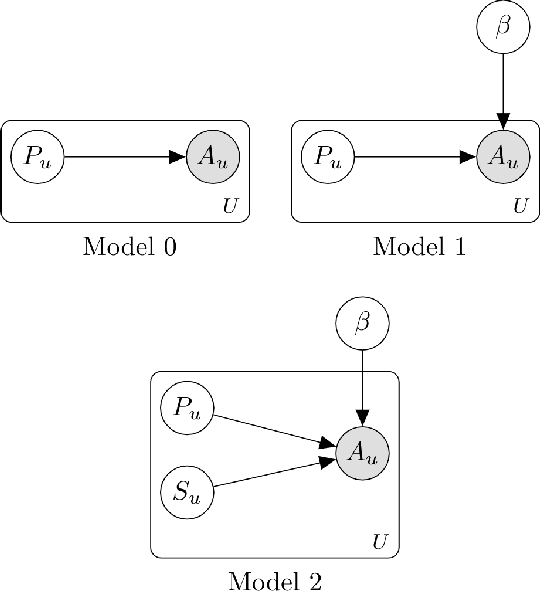

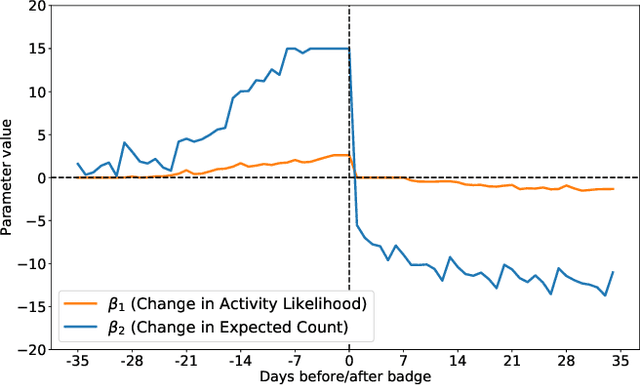
According to the goal-gradient hypothesis, people increase their efforts toward a reward as they close in on the reward. This hypothesis has recently been used to explain users' behavior in online communities that use badges as rewards for completing specific activities. In such settings, users exhibit a "steering effect," a dramatic increase in activity as the users approach a badge threshold, thereby following the predictions made by the goal-gradient hypothesis. This paper provides a new probabilistic model of users' behavior, which captures users who exhibit different levels of steering. We apply this model to data from the popular Q&A site, Stack Overflow, and study users who achieve one of the badges available on this platform. Our results show that only a fraction (20%) of all users strongly experience steering, whereas the activity of more than 40% of badge achievers appears not to be affected by the badge. In particular, we find that for some of the population, an increased activity in and around the badge acquisition date may reflect a statistical artifact rather than steering, as was previously thought in prior work. These results are important for system designers who hope to motivate and guide their users towards certain actions. We have highlighted the need for further studies which investigate what motivations drive the non-steered users to contribute to online communities.