 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fast Empirical Scenarios
Jul 08, 2023
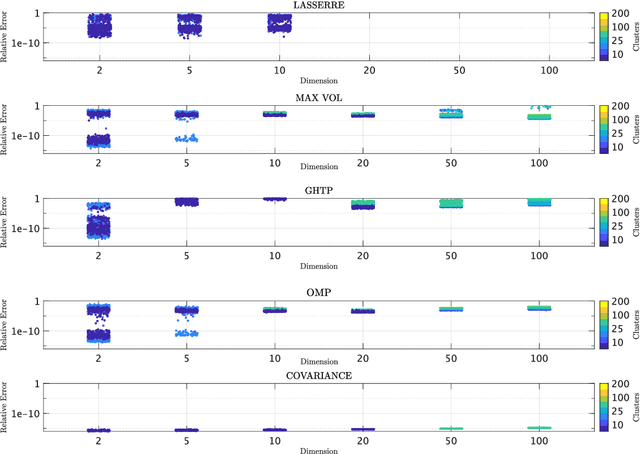
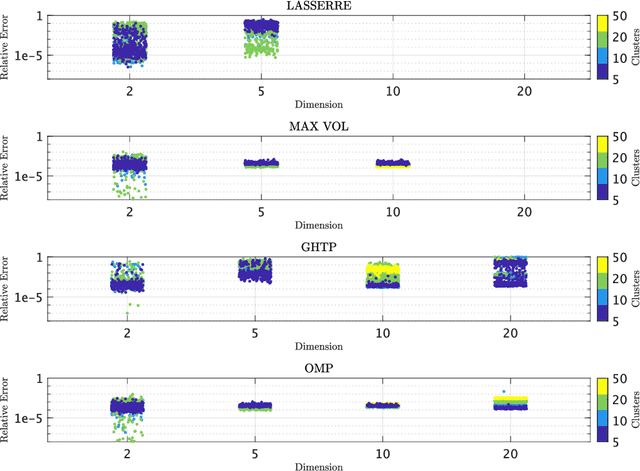
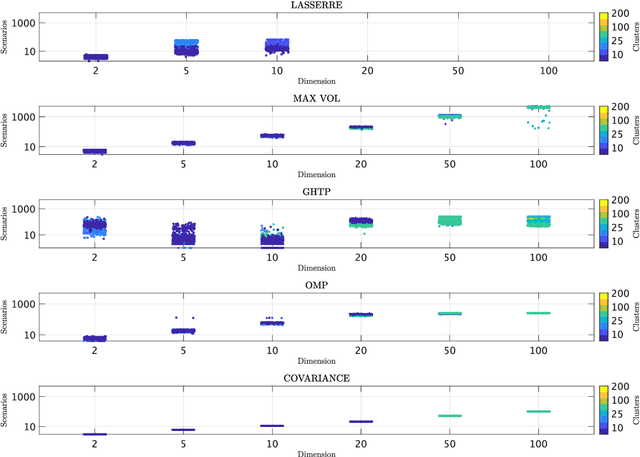
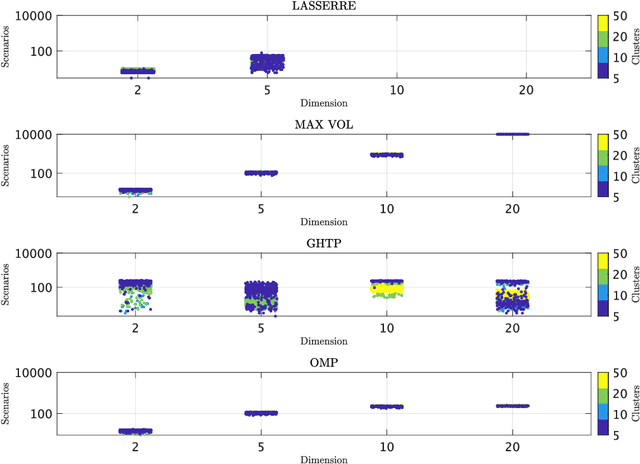
We seek to extract a small number of representative scenarios from large and high-dimensional panel data that are consistent with sample moments. Among two novel algorithms, the first identifies scenarios that have not been observed before, and comes with a scenario-based representation of covariance matrices. The second proposal picks important data points from states of the world that have already realized, and are consistent with higher-order sample moment information. Both algorithms are efficient to compute, and lend themselves to consistent scenario-based modeling and high-dimensional numerical integration. Extensive numerical benchmarking studies and an application in portfolio optimization favor the proposed algorithms.
3D-SeqMOS: A Novel Sequential 3D Moving Object Segmentation in Autonomous Driving
Jul 18, 2023

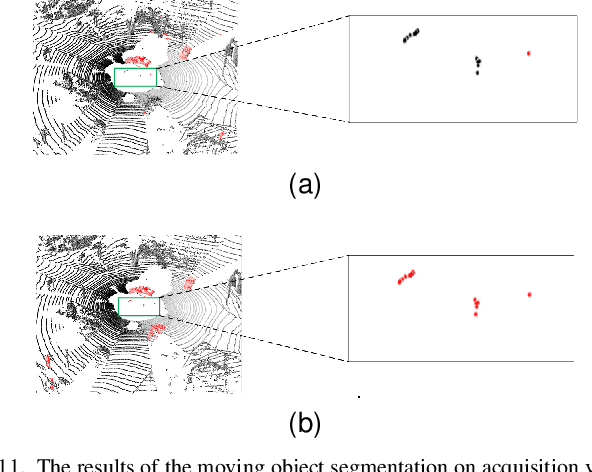
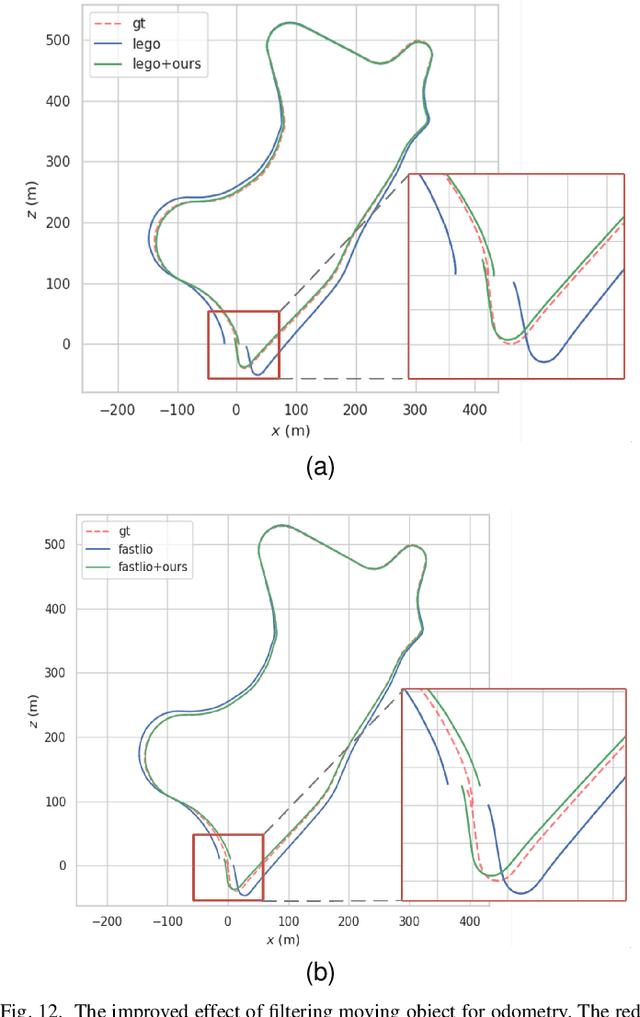
For the SLAM system in robotics and autonomous driving, the accuracy of front-end odometry and back-end loop-closure detection determine the whole intelligent system performance. But the LiDAR-SLAM could be disturbed by current scene moving objects, resulting in drift errors and even loop-closure failure. Thus, the ability to detect and segment moving objects is essential for high-precision positioning and building a consistent map. In this paper, we address the problem of moving object segmentation from 3D LiDAR scans to improve the odometry and loop-closure accuracy of SLAM. We propose a novel 3D Sequential Moving-Object-Segmentation (3D-SeqMOS) method that can accurately segment the scene into moving and static objects, such as moving and static cars. Different from the existing projected-image method, we process the raw 3D point cloud and build a 3D convolution neural network for MOS task. In addition, to make full use of the spatio-temporal information of point cloud, we propose a point cloud residual mechanism using the spatial features of current scan and the temporal features of previous residual scans. Besides, we build a complete SLAM framework to verify the effectiveness and accuracy of 3D-SeqMOS. Experiments on SemanticKITTI dataset show that our proposed 3D-SeqMOS method can effectively detect moving objects and improve the accuracy of LiDAR odometry and loop-closure detection. The test results show our 3D-SeqMOS outperforms the state-of-the-art method by 12.4%. We extend the proposed method to the SemanticKITTI: Moving Object Segmentation competition and achieve the 2nd in the leaderboard, showing its effectiveness.
Radar-STDA: A High-Performance Spatial-Temporal Denoising Autoencoder for Interference Mitigation of FMCW Radars
Jul 18, 2023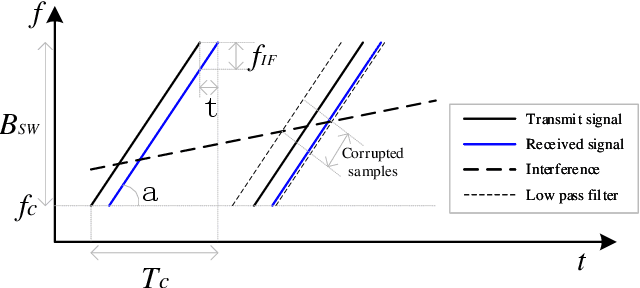
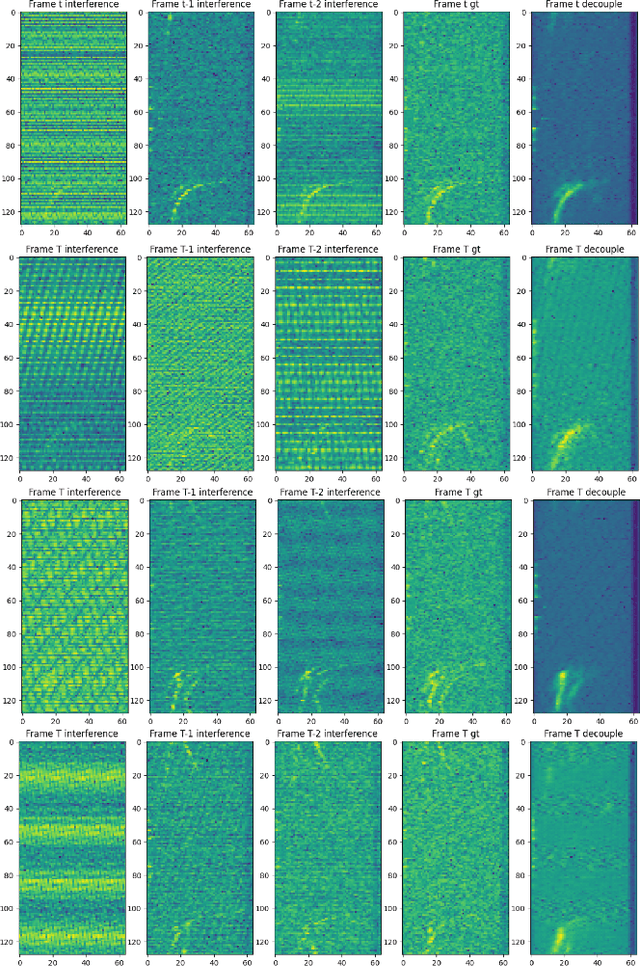
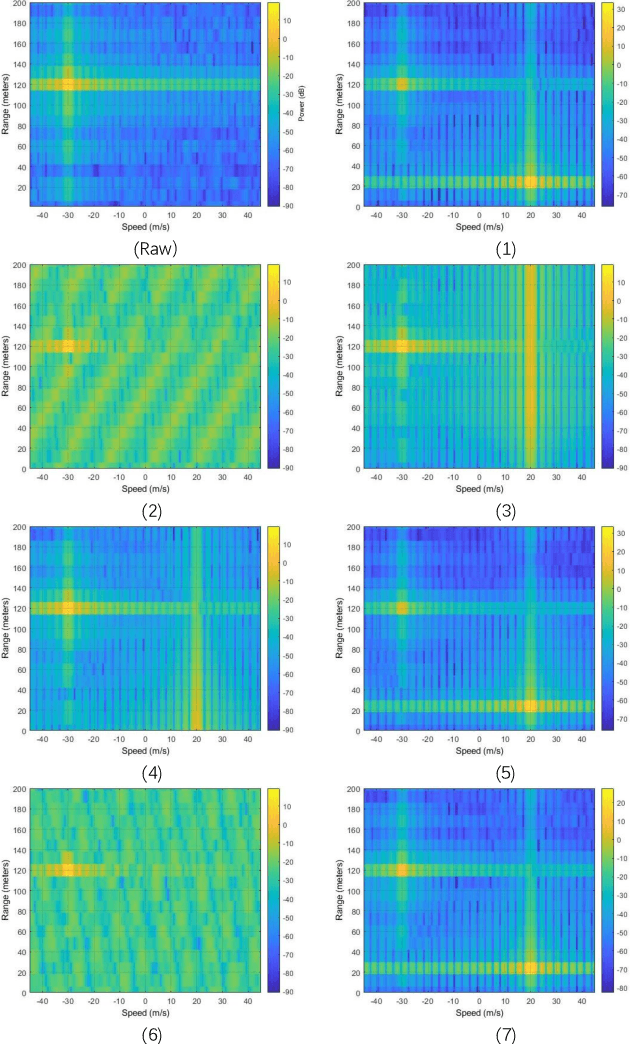
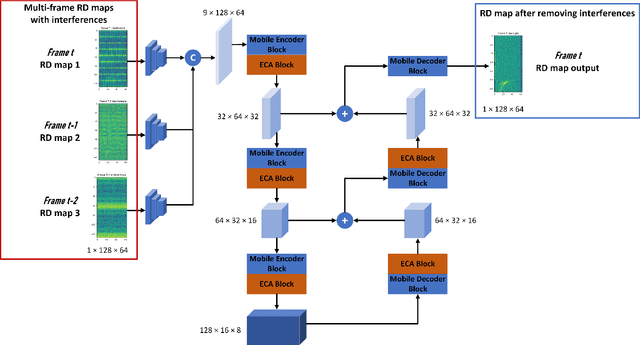
With its small size, low cost and all-weather operation, millimeter-wave radar can accurately measure the distance, azimuth and radial velocity of a target compared to other traffic sensors. However, in practice, millimeter-wave radars are plagued by various interferences, leading to a drop in target detection accuracy or even failure to detect targets. This is undesirable in autonomous vehicles and traffic surveillance, as it is likely to threaten human life and cause property damage. Therefore, interference mitigation is of great significance for millimeter-wave radar-based target detection. Currently, the development of deep learning is rapid, but existing deep learning-based interference mitigation models still have great limitations in terms of model size and inference speed. For these reasons, we propose Radar-STDA, a Radar-Spatial Temporal Denoising Autoencoder. Radar-STDA is an efficient nano-level denoising autoencoder that takes into account both spatial and temporal information of range-Doppler maps. Among other methods, it achieves a maximum SINR of 17.08 dB with only 140,000 parameters. It obtains 207.6 FPS on an RTX A4000 GPU and 56.8 FPS on an NVIDIA Jetson AGXXavier respectively when denoising range-Doppler maps for three consecutive frames. Moreover, we release a synthetic data set called Ra-inf for the task, which involves 384,769 range-Doppler maps with various clutters from objects of no interest and receiver noise in realistic scenarios. To the best of our knowledge, Ra-inf is the first synthetic dataset of radar interference. To support the community, our research is open-source via the link \url{https://github.com/GuanRunwei/rd_map_temporal_spatial_denoising_autoencoder}.
In Defense of Clip-based Video Relation Detection
Jul 18, 2023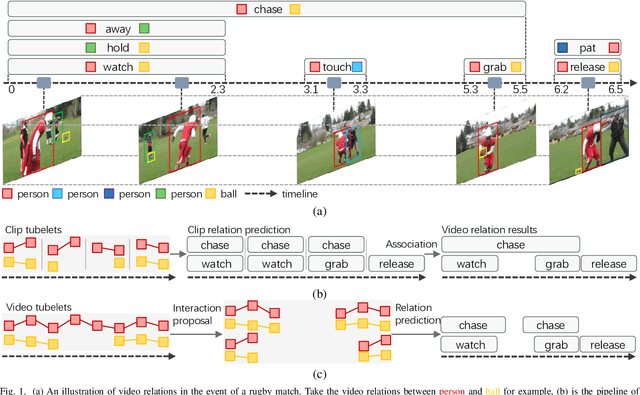
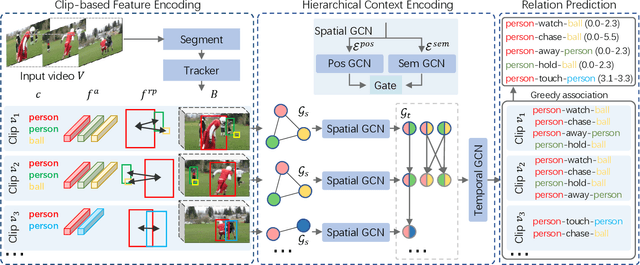
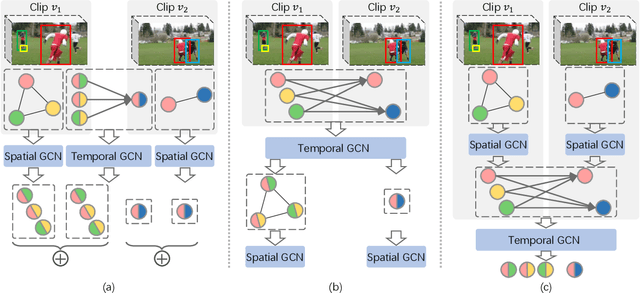

Video Visual Relation Detection (VidVRD) aims to detect visual relationship triplets in videos using spatial bounding boxes and temporal boundaries. Existing VidVRD methods can be broadly categorized into bottom-up and top-down paradigms, depending on their approach to classifying relations. Bottom-up methods follow a clip-based approach where they classify relations of short clip tubelet pairs and then merge them into long video relations. On the other hand, top-down methods directly classify long video tubelet pairs. While recent video-based methods utilizing video tubelets have shown promising results, we argue that the effective modeling of spatial and temporal context plays a more significant role than the choice between clip tubelets and video tubelets. This motivates us to revisit the clip-based paradigm and explore the key success factors in VidVRD. In this paper, we propose a Hierarchical Context Model (HCM) that enriches the object-based spatial context and relation-based temporal context based on clips. We demonstrate that using clip tubelets can achieve superior performance compared to most video-based methods. Additionally, using clip tubelets offers more flexibility in model designs and helps alleviate the limitations associated with video tubelets, such as the challenging long-term object tracking problem and the loss of temporal information in long-term tubelet feature compression. Extensive experiments conducted on two challenging VidVRD benchmarks validate that our HCM achieves a new state-of-the-art performance, highlighting the effectiveness of incorporating advanced spatial and temporal context modeling within the clip-based paradigm.
Unlocking Context Constraints of LLMs: Enhancing Context Efficiency of LLMs with Self-Information-Based Content Filtering
Apr 24, 2023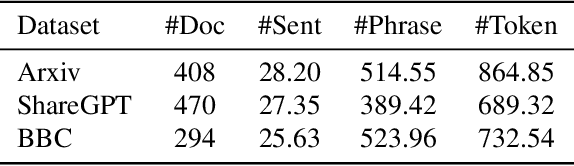

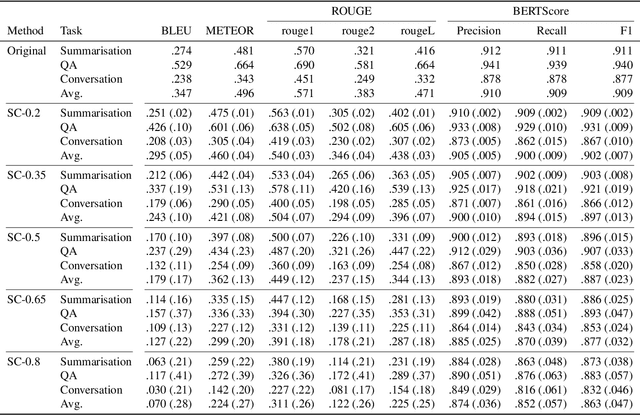
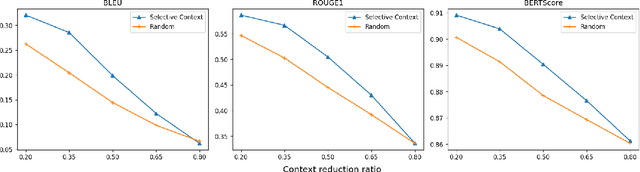
Large language models (LLMs) have received significant attention by achieving remarkable performance across various tasks. However, their fixed context length poses challenges when processing long documents or maintaining extended conversations. This paper proposes a method called \textit{Selective Context} that employs self-information to filter out less informative content, thereby enhancing the efficiency of the fixed context length. We demonstrate the effectiveness of our approach on tasks of summarisation and question answering across different data sources, including academic papers, news articles, and conversation transcripts.
In silico Ptychography of Lithium-ion Cathode Materials from Subsampled 4-D STEM Data
Jul 12, 2023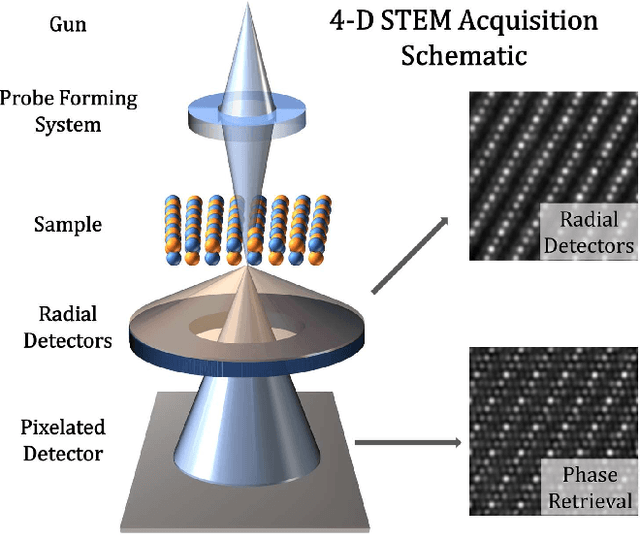

High quality scanning transmission electron microscopy (STEM) data acquisition and analysis has become increasingly important due to the commercial demand for investigating the properties of complex materials such as battery cathodes; however, multidimensional techniques (such as 4-D STEM) which can improve resolution and sample information are ultimately limited by the beam-damage properties of the materials or the signal-to-noise ratio of the result. subsampling offers a solution to this problem by retaining high signal, but distributing the dose across the sample such that the damage can be reduced. It is for these reasons that we propose a method of subsampling for 4-D STEM, which can take advantage of the redundancy within said data to recover functionally identical results to the ground truth. We apply these ideas to a simulated 4-D STEM data set of a LiMnO2 sample and we obtained high quality reconstruction of phase images using 12.5% subsampling.
Sumformer: A Linear-Complexity Alternative to Self-Attention for Speech Recognition
Jul 12, 2023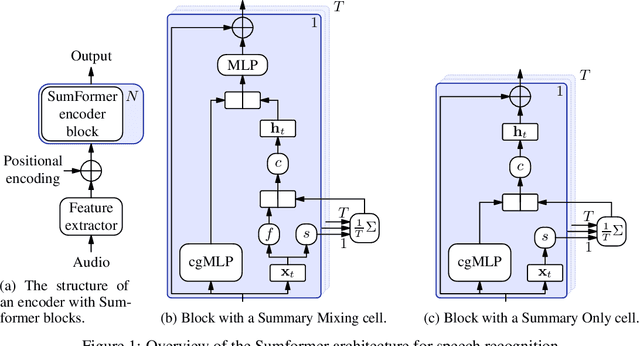
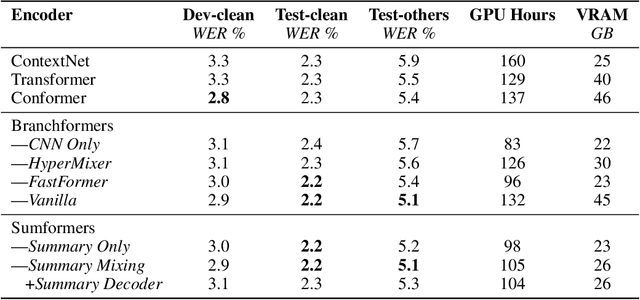
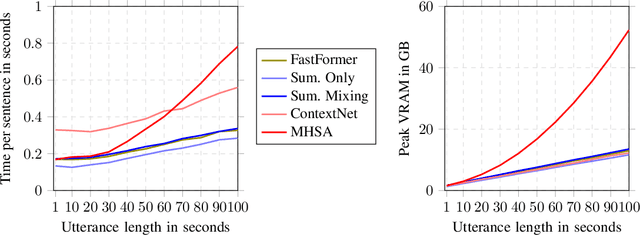
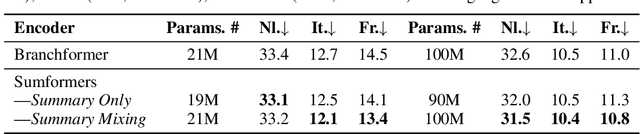
Modern speech recognition systems rely on self-attention. Unfortunately, token mixing with self-attention takes quadratic time in the length of the speech utterance, slowing down inference as well as training and increasing memory consumption. Cheaper alternatives to self-attention for ASR have been developed, but fail to consistently reach the same level of accuracy. In practice, however, the self-attention weights of trained speech recognizers take the form of a global average over time. This paper, therefore, proposes a linear-time alternative to self-attention for speech recognition. It summarises a whole utterance with the mean over vectors for all time steps. This single summary is then combined with time-specific information. We call this method ``Summary Mixing''. Introducing Summary Mixing in state-of-the-art ASR models makes it feasible to preserve or exceed previous speech recognition performance while lowering the training and inference times by up to 27% and reducing the memory budget by a factor of two.
Air Bumper: A Collision Detection and Reaction Framework for Autonomous MAV Navigation
Jul 12, 2023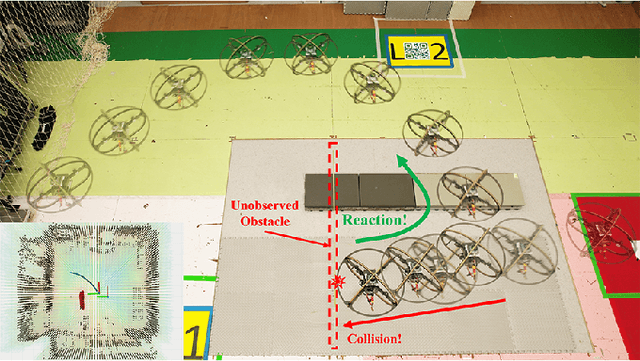
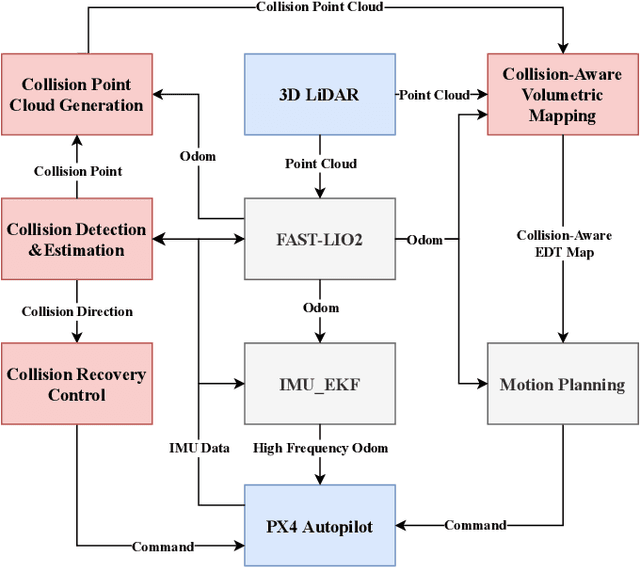

Autonomous navigation in unknown environments with obstacles remains challenging for micro aerial vehicles (MAVs) due to their limited onboard computing and sensing resources. Although various collision avoidance methods have been developed, it is still possible for drones to collide with unobserved obstacles due to unpredictable disturbances, sensor limitations, and control uncertainty. Instead of completely avoiding collisions, this article proposes Air Bumper, a collision detection and reaction framework, for fully autonomous flight in 3D environments to improve the safety of drones. Our framework only utilizes the onboard inertial measurement unit (IMU) to detect and estimate collisions. We further design a collision recovery control for rapid recovery and collision-aware mapping to integrate collision information into general LiDAR-based sensing and planning frameworks. Our simulation and experimental results show that the quadrotor can rapidly detect, estimate, and recover from collisions with obstacles in 3D space and continue the flight smoothly with the help of the collision-aware map.
SepVAE: a contrastive VAE to separate pathological patterns from healthy ones
Jul 12, 2023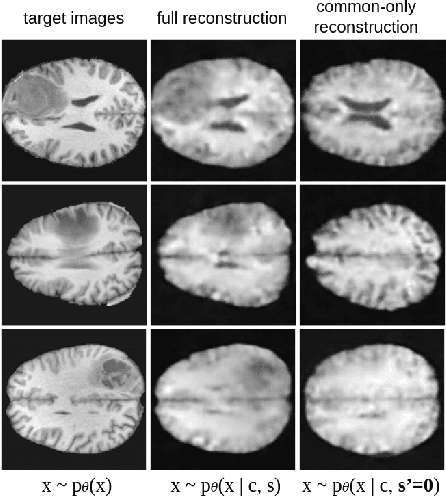

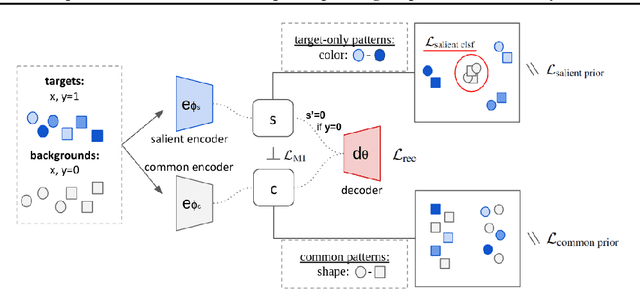
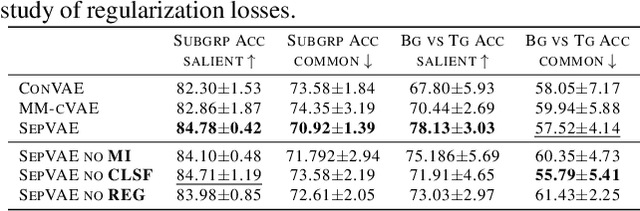
Contrastive Analysis VAE (CA-VAEs) is a family of Variational auto-encoders (VAEs) that aims at separating the common factors of variation between a background dataset (BG) (i.e., healthy subjects) and a target dataset (TG) (i.e., patients) from the ones that only exist in the target dataset. To do so, these methods separate the latent space into a set of salient features (i.e., proper to the target dataset) and a set of common features (i.e., exist in both datasets). Currently, all models fail to prevent the sharing of information between latent spaces effectively and to capture all salient factors of variation. To this end, we introduce two crucial regularization losses: a disentangling term between common and salient representations and a classification term between background and target samples in the salient space. We show a better performance than previous CA-VAEs methods on three medical applications and a natural images dataset (CelebA). Code and datasets are available on GitHub https://github.com/neurospin-projects/2023_rlouiset_sepvae.
DDNAS: Discretized Differentiable Neural Architecture Search for Text Classification
Jul 12, 2023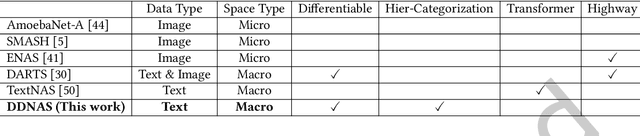
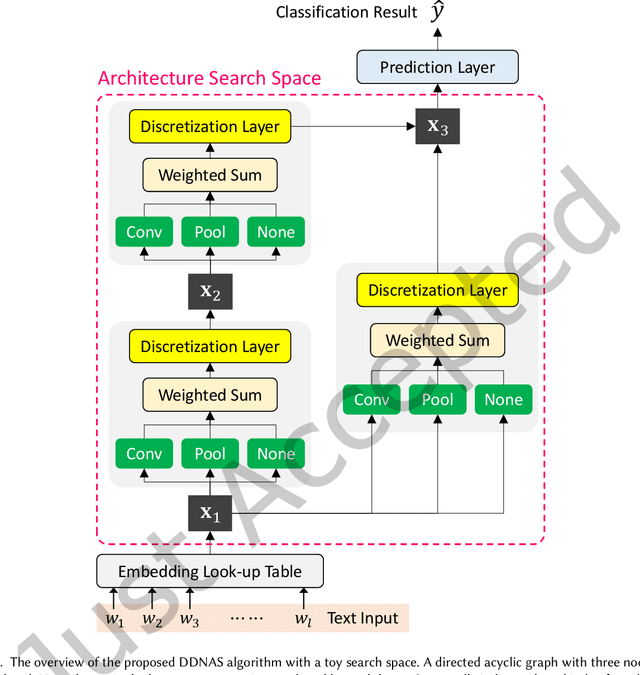
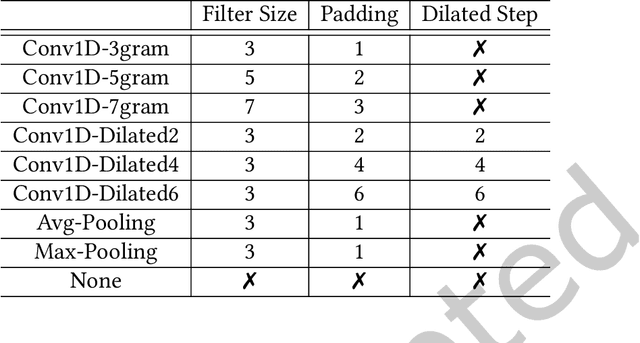
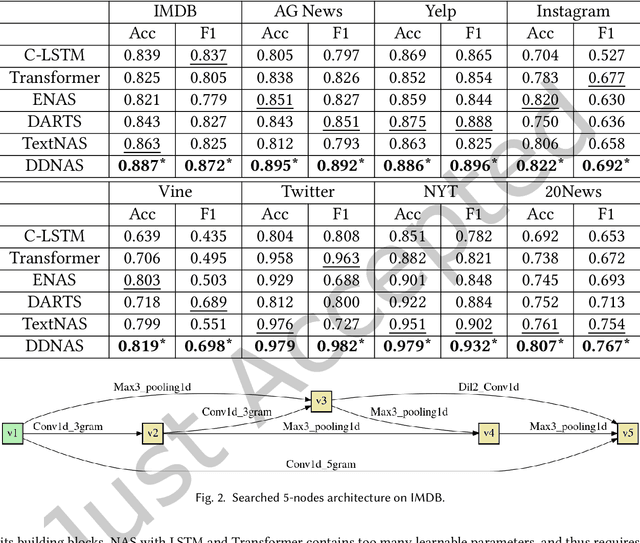
Neural Architecture Search (NAS) has shown promising capability in learning text representation. However, existing text-based NAS neither performs a learnable fusion of neural operations to optimize the architecture, nor encodes the latent hierarchical categorization behind text input. This paper presents a novel NAS method, Discretized Differentiable Neural Architecture Search (DDNAS), for text representation learning and classification. With the continuous relaxation of architecture representation, DDNAS can use gradient descent to optimize the search. We also propose a novel discretization layer via mutual information maximization, which is imposed on every search node to model the latent hierarchical categorization in text representation. Extensive experiments conducted on eight diverse real datasets exhibit that DDNAS can consistently outperform the state-of-the-art NAS methods. While DDNAS relies on only three basic operations, i.e., convolution, pooling, and none, to be the candidates of NAS building blocks, its promising performance is noticeable and extensible to obtain further improvement by adding more different operations.