 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of LLMs in Speech is Often Flawed: Test Set Contamination in Large Language Models for Speech Recognition
May 28, 2025Recent work suggests that large language models (LLMs) can improve performance of speech tasks compared to existing systems. To support their claims, results on LibriSpeech and Common Voice are often quoted. However, this work finds that a substantial amount of the LibriSpeech and Common Voice evaluation sets appear in public LLM pretraining corpora. This calls into question the reliability of findings drawn from these two datasets. To measure the impact of contamination, LLMs trained with or without contamination are compared, showing that a contaminated LLM is more likely to generate test sentences it has seen during training. Speech recognisers using contaminated LLMs shows only subtle differences in error rates, but assigns significantly higher probabilities to transcriptions seen during training. Results show that LLM outputs can be biased by tiny amounts of data contamination, highlighting the importance of evaluating LLM-based speech systems with held-out data.
Loquacious Set: 25,000 Hours of Transcribed and Diverse English Speech Recognition Data for Research and Commercial Use
May 27, 2025


Automatic speech recognition (ASR) research is driven by the availability of common datasets between industrial researchers and academics, encouraging comparisons and evaluations. LibriSpeech, despite its long success as an ASR benchmark, is now limited by its size and focus on clean, read speech, leading to near-zero word error rates. More recent datasets, including MOSEL, YODAS, Gigaspeech, OWSM, Libriheavy or People's Speech suffer from major limitations including licenses that researchers in the industry cannot use, unreliable transcriptions, incorrect audio data, or the lack of evaluation sets. This work presents the Loquacious Set, a 25,000-hour curated collection of commercially usable English speech. Featuring hundreds of thousands of speakers with diverse accents and a wide range of speech types (read, spontaneous, talks, clean, noisy), the Loquacious Set is designed to work for academics and researchers in the industry to build ASR systems in real-world scenarios.
Benchmarking Rotary Position Embeddings for Automatic Speech Recognition
Jan 10, 2025Rotary Position Embedding (RoPE) encodes relative and absolute positional information in Transformer-based models through rotation matrices applied to input vectors within sequences. While RoPE has demonstrated superior performance compared to other positional embedding technologies in natural language processing tasks, its effectiveness in speech processing applications remains understudied. In this work, we conduct a comprehensive evaluation of RoPE across diverse automatic speech recognition (ASR) tasks. Our experimental results demonstrate that for ASR tasks, RoPE consistently achieves lower error rates compared to the currently widely used relative positional embedding. To facilitate further research, we release the implementation and all experimental recipes through the SpeechBrain toolkit.
Linear Time Complexity Conformers with SummaryMixing for Streaming Speech Recognition
Sep 11, 2024


Automatic speech recognition (ASR) with an encoder equipped with self-attention, whether streaming or non-streaming, takes quadratic time in the length of the speech utterance. This slows down training and decoding, increase their cost, and limit the deployment of the ASR in constrained devices. SummaryMixing is a promising linear-time complexity alternative to self-attention for non-streaming speech recognition that, for the first time, preserves or outperforms the accuracy of self-attention models. Unfortunately, the original definition of SummaryMixing is not suited to streaming speech recognition. Hence, this work extends SummaryMixing to a Conformer Transducer that works in both a streaming and an offline mode. It shows that this new linear-time complexity speech encoder outperforms self-attention in both scenarios while requiring less compute and memory during training and decoding.
Linear-Complexity Self-Supervised Learning for Speech Processing
Jul 18, 2024Self-supervised learning (SSL) models usually require weeks of pre-training with dozens of high-end GPUs. These models typically have a multi-headed self-attention (MHSA) context encoder. However, MHSA takes quadratic time and space in the input length, contributing to the high pre-training cost. Linear-complexity alternatives to MHSA have been proposed. For instance, in supervised training, the SummaryMixing model is the first to outperform MHSA across multiple speech processing tasks. However, these cheaper alternatives have not been explored for SSL yet. This paper studies a linear-complexity context encoder for SSL for the first time. With better or equivalent performance for the downstream tasks of the MP3S benchmark, SummaryMixing reduces the pre-training time and peak VRAM of wav2vec 2.0 model by 18% and by 23%, respectively, leading to the pre-training of a 155M wav2vec 2.0 model finished within one week with 4 Tesla A100 GPUs. Code is available at https://github.com/SamsungLabs/SummaryMixing.
DP-DyLoRA: Fine-Tuning Transformer-Based Models On-Device under Differentially Private Federated Learning using Dynamic Low-Rank Adaptation
May 10, 2024



Federated learning (FL) allows clients in an Internet of Things (IoT) system to collaboratively train a global model without sharing their local data with a server. However, clients' contributions to the server can still leak sensitive information. Differential privacy (DP) addresses such leakage by providing formal privacy guarantees, with mechanisms that add randomness to the clients' contributions. The randomness makes it infeasible to train large transformer-based models, common in modern IoT systems. In this work, we empirically evaluate the practicality of fine-tuning large scale on-device transformer-based models with differential privacy in a federated learning system. We conduct comprehensive experiments on various system properties for tasks spanning a multitude of domains: speech recognition, computer vision (CV) and natural language understanding (NLU). Our results show that full fine-tuning under differentially private federated learning (DP-FL) generally leads to huge performance degradation which can be alleviated by reducing the dimensionality of contributions through parameter-efficient fine-tuning (PEFT). Our benchmarks of existing DP-PEFT methods show that DP-Low-Rank Adaptation (DP-LoRA) consistently outperforms other methods. An even more promising approach, DyLoRA, which makes the low rank variable, when naively combined with FL would straightforwardly break differential privacy. We therefore propose an adaptation method that can be combined with differential privacy and call it DP-DyLoRA. Finally, we are able to reduce the accuracy degradation and word error rate (WER) increase due to DP to less than 2% and 7% respectively with 1 million clients and a stringent privacy budget of {\epsilon}=2.
pfl-research: simulation framework for accelerating research in Private Federated Learning
Apr 09, 2024



Federated learning (FL) is an emerging machine learning (ML) training paradigm where clients own their data and collaborate to train a global model, without revealing any data to the server and other participants. Researchers commonly perform experiments in a simulation environment to quickly iterate on ideas. However, existing open-source tools do not offer the efficiency required to simulate FL on larger and more realistic FL datasets. We introduce pfl-research, a fast, modular, and easy-to-use Python framework for simulating FL. It supports TensorFlow, PyTorch, and non-neural network models, and is tightly integrated with state-of-the-art privacy algorithms. We study the speed of open-source FL frameworks and show that pfl-research is 7-72$\times$ faster than alternative open-source frameworks on common cross-device setups. Such speedup will significantly boost the productivity of the FL research community and enable testing hypotheses on realistic FL datasets that were previously too resource intensive. We release a suite of benchmarks that evaluates an algorithm's overall performance on a diverse set of realistic scenarios. The code is available on GitHub at https://github.com/apple/pfl-research.
Globally Normalising the Transducer for Streaming Speech Recognition
Jul 20, 2023



The Transducer (e.g. RNN-Transducer or Conformer-Transducer) generates an output label sequence as it traverses the input sequence. It is straightforward to use in streaming mode, where it generates partial hypotheses before the complete input has been seen. This makes it popular in speech recognition. However, in streaming mode the Transducer has a mathematical flaw which, simply put, restricts the model's ability to change its mind. The fix is to replace local normalisation (e.g. a softmax) with global normalisation, but then the loss function becomes impossible to evaluate exactly. A recent paper proposes to solve this by approximating the model, severely degrading performance. Instead, this paper proposes to approximate the loss function, allowing global normalisation to apply to a state-of-the-art streaming model. Global normalisation reduces its word error rate by 9-11% relative, closing almost half the gap between streaming and lookahead mode.
Sumformer: A Linear-Complexity Alternative to Self-Attention for Speech Recognition
Jul 12, 2023Modern speech recognition systems rely on self-attention. Unfortunately, token mixing with self-attention takes quadratic time in the length of the speech utterance, slowing down inference as well as training and increasing memory consumption. Cheaper alternatives to self-attention for ASR have been developed, but fail to consistently reach the same level of accuracy. In practice, however, the self-attention weights of trained speech recognizers take the form of a global average over time. This paper, therefore, proposes a linear-time alternative to self-attention for speech recognition. It summarises a whole utterance with the mean over vectors for all time steps. This single summary is then combined with time-specific information. We call this method ``Summary Mixing''. Introducing Summary Mixing in state-of-the-art ASR models makes it feasible to preserve or exceed previous speech recognition performance while lowering the training and inference times by up to 27% and reducing the memory budget by a factor of two.
Training Large-Vocabulary Neural Language Models by Private Federated Learning for Resource-Constrained Devices
Jul 18, 2022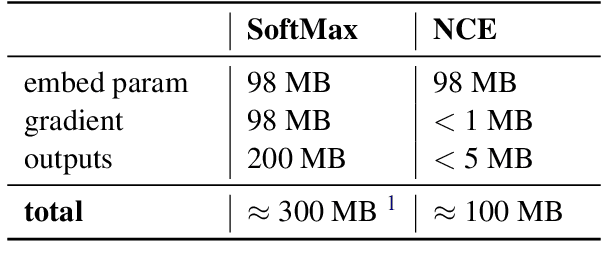
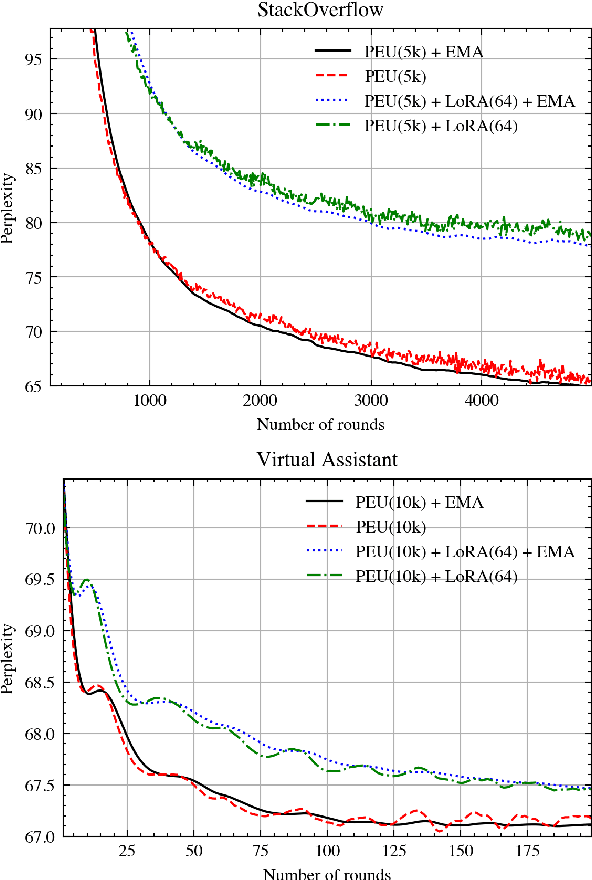

Federated Learning (FL) is a technique to train models using data distributed across devices. Differential Privacy (DP) provides a formal privacy guarantee for sensitive data. Our goal is to train a large neural network language model (NNLM) on compute-constrained devices while preserving privacy using FL and DP. However, the DP-noise introduced to the model increases as the model size grows, which often prevents convergence. We propose Partial Embedding Updates (PEU), a novel technique to decrease noise by decreasing payload size. Furthermore, we adopt Low Rank Adaptation (LoRA) and Noise Contrastive Estimation (NCE) to reduce the memory demands of large models on compute-constrained devices. This combination of techniques makes it possible to train large-vocabulary language models while preserving accuracy and privacy.