 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Discovery of Disease Subgroups by Contrasting with Healthy Controls
May 20, 2026In biomedical Subgroup Discovery, practitioners are interested in discovering interpretable and homogeneous subgroups within a group of patients. In this paper, assuming that healthy subjects (i.e., controls) share common but irrelevant factors of variation with the patients, we motivate and develop a Contrastive Subgroup Discovery method, entitled Deep UCSL. By contrasting patients with controls, Deep UCSL identifies subgroups driven solely by pathological factors, ignoring common variability shared with healthy subjects. Our framework employs a deep feature extractor to learn a discriminative representation space. Mathematically, we derive a novel loss based on the conditional joint likelihood of latent clusters and patient/control labels, optimized via an Expectation-Maximization strategy alternating between subgroup inference and feature encoder updates. A regularization term further encourages representations to capture disease-specific variability while ignoring variability shared with controls. Compared to previous related works, our approach quantitatively improves the quality of the estimated subgroups, as demonstrated on a MNIST example and four distinct real medical imaging datasets. Code and datasets are available at: https://github.com/rlouiset/deep_ucsl.
A Unified Geometric Framework for Weighted Contrastive Learning
May 13, 2026Contrastive learning (CL) aims to preserve relational structure between samples by learning representations that reflect a similarity graph. Yet, the geometry of the resulting embeddings remains poorly understood. Here we show that weighted InfoNCE objectives can be interpreted as Distance Geometry Problems, where the weighting scheme specifies the target geometry to be realized by the representation. This viewpoint yields exact characterizations of the optimal embeddings for several supervised and weakly supervised objectives. In supervised classification, both SupCon and Soft SupCon (a dense relaxation of it where pairs from distinct classes have small non-zero similarity) collapse samples within each class to a single prototype. However, while balanced SupCon recovers the classical regular simplex geometry, class imbalance breaks this symmetry: SupCon induces non-uniform inter-class similarities depending on class sizes, whereas Soft SupCon preserves a regular simplex geometry regardless of class imbalance. In continuous-label settings, our framework reveals a different failure mode: y-Aware CL generally cannot attain its entropic optimum unless the labels lie on a hypersphere, exposing a mismatch between Euclidean label weights and spherical latent similarity. By contrast, geometrically consistent choices such as Euclidean-Euclidean weighting or X-CLR admit unique optimal embeddings. Our results show that the choice of weighting scheme determines whether contrastive learning is geometrically realizable, degenerate, or inconsistent, providing a principled framework for designing contrastive objectives.
Improving clinical interpretability of linear neuroimaging models through feature whitening
Apr 22, 2026Linear models are widely used in computational neuroimaging to identify biomarkers associated with brain pathologies. However, interpreting the learned weights remains challenging, as they do not always yield clinically meaningful insights. This difficulty arises in part from the inherent correlation between brain regions, which causes linear weights to reflect shared rather than region-specific contributions. In particular, some groups of regions, including homologous structures in the left and right hemispheres, are known to exhibit strong anatomical correlations. In this work, we leverage this prior neuroanatomical knowledge to introduce a whitening approach applied to groups of regions with known shared variance, designed to disentangle overlapping information across correlated brain measures. We additionally propose a regularized variant that allows controlled tuning of the degree of decorrelation. We evaluate this method using region-of-interest features in two psychiatric classification tasks, distinguishing individuals with bipolar disorder or schizophrenia from healthy controls. Importantly, unlike PCA or ICA which use whitening as a dimensionality reduction step, our approach decorrelates anatomically informed pairs of neuroanatomical regions while retaining the full input signal, making it specifically suited for feature interpretation rather than feature selection. Our findings demonstrate that whitening improves the interpretability of model weights while preserving predictive performance, providing a robust framework for linking linear model outputs to neurobiological mechanisms.
How and why does deep ensemble coupled with transfer learning increase performance in bipolar disorder and schizophrenia classification?
Apr 02, 2026Transfer learning (TL) and deep ensemble learning (DE) have recently been shown to outperform simple machine learning in classifying psychiatric disorders. However, there is still a lack of understanding as to why that is. This paper aims to understand how and why DE and TL reduce the variability of single-subject classification models in bipolar disorder (BD) and schizophrenia (SCZ). To this end, we investigated the training stability of TL and DE models. For the two classification tasks under consideration, we compared the results of multiple trainings with the same backbone but with different initializations. In this way, we take into account the epistemic uncertainty associated with the uncertainty in the estimation of the model parameters. It has been shown that the performance of classifiers can be significantly improved by using TL with DE. Based on these results, we investigate i) how many models are needed to benefit from the performance improvement of DE when classifying BD and SCZ from healthy controls, and ii) how TL induces better generalization, with and without DE. In the first case, we show that DE reaches a plateau when 10 models are included in the ensemble. In the second case, we find that using a pre-trained model constrains TL models with the same pre-training to stay in the same basin of the loss function. This is not the case for DL models with randomly initialized weights.
Robust brain age estimation from structural MRI with contrastive learning
Jul 02, 2025Estimating brain age from structural MRI has emerged as a powerful tool for characterizing normative and pathological aging. In this work, we explore contrastive learning as a scalable and robust alternative to supervised approaches for brain age estimation. We introduce a novel contrastive loss function, $\mathcal{L}^{exp}$, and evaluate it across multiple public neuroimaging datasets comprising over 20,000 scans. Our experiments reveal four key findings. First, scaling pre-training on diverse, multi-site data consistently improves generalization performance, cutting external mean absolute error (MAE) nearly in half. Second, $\mathcal{L}^{exp}$ is robust to site-related confounds, maintaining low scanner-predictability as training size increases. Third, contrastive models reliably capture accelerated aging in patients with cognitive impairment and Alzheimer's disease, as shown through brain age gap analysis, ROC curves, and longitudinal trends. Lastly, unlike supervised baselines, $\mathcal{L}^{exp}$ maintains a strong correlation between brain age accuracy and downstream diagnostic performance, supporting its potential as a foundation model for neuroimaging. These results position contrastive learning as a promising direction for building generalizable and clinically meaningful brain representations.
Separating common from salient patterns with Contrastive Representation Learning
Feb 19, 2024Contrastive Analysis is a sub-field of Representation Learning that aims at separating common factors of variation between two datasets, a background (i.e., healthy subjects) and a target (i.e., diseased subjects), from the salient factors of variation, only present in the target dataset. Despite their relevance, current models based on Variational Auto-Encoders have shown poor performance in learning semantically-expressive representations. On the other hand, Contrastive Representation Learning has shown tremendous performance leaps in various applications (classification, clustering, etc.). In this work, we propose to leverage the ability of Contrastive Learning to learn semantically expressive representations well adapted for Contrastive Analysis. We reformulate it under the lens of the InfoMax Principle and identify two Mutual Information terms to maximize and one to minimize. We decompose the first two terms into an Alignment and a Uniformity term, as commonly done in Contrastive Learning. Then, we motivate a novel Mutual Information minimization strategy to prevent information leakage between common and salient distributions. We validate our method, called SepCLR, on three visual datasets and three medical datasets, specifically conceived to assess the pattern separation capability in Contrastive Analysis. Code available at https://github.com/neurospin-projects/2024_rlouiset_sep_clr.
SepVAE: a contrastive VAE to separate pathological patterns from healthy ones
Jul 12, 2023Contrastive Analysis VAE (CA-VAEs) is a family of Variational auto-encoders (VAEs) that aims at separating the common factors of variation between a background dataset (BG) (i.e., healthy subjects) and a target dataset (TG) (i.e., patients) from the ones that only exist in the target dataset. To do so, these methods separate the latent space into a set of salient features (i.e., proper to the target dataset) and a set of common features (i.e., exist in both datasets). Currently, all models fail to prevent the sharing of information between latent spaces effectively and to capture all salient factors of variation. To this end, we introduce two crucial regularization losses: a disentangling term between common and salient representations and a classification term between background and target samples in the salient space. We show a better performance than previous CA-VAEs methods on three medical applications and a natural images dataset (CelebA). Code and datasets are available on GitHub https://github.com/neurospin-projects/2023_rlouiset_sepvae.
Contrastive learning for regression in multi-site brain age prediction
Nov 14, 2022



Building accurate Deep Learning (DL) models for brain age prediction is a very relevant topic in neuroimaging, as it could help better understand neurodegenerative disorders and find new biomarkers. To estimate accurate and generalizable models, large datasets have been collected, which are often multi-site and multi-scanner. This large heterogeneity negatively affects the generalization performance of DL models since they are prone to overfit site-related noise. Recently, contrastive learning approaches have been shown to be more robust against noise in data or labels. For this reason, we propose a novel contrastive learning regression loss for robust brain age prediction using MRI scans. Our method achieves state-of-the-art performance on the OpenBHB challenge, yielding the best generalization capability and robustness to site-related noise.
Rethinking Positive Sampling for Contrastive Learning with Kernel
Jun 03, 2022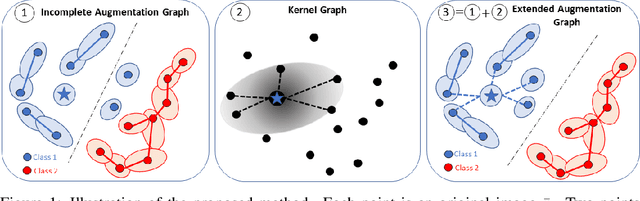
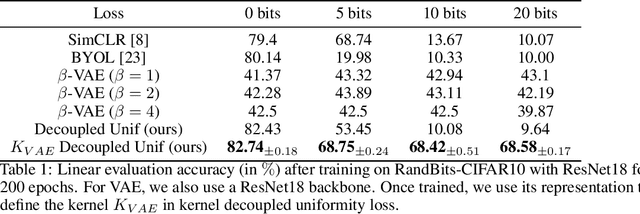
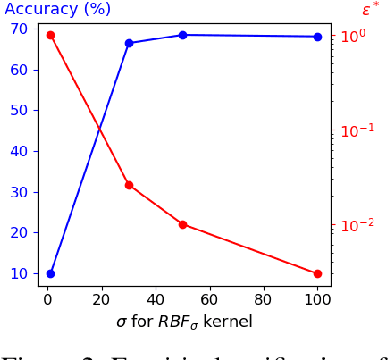

Data augmentation is a crucial component in unsupervised contrastive learning (CL). It determines how positive samples are defined and, ultimately, the quality of the representation. While efficient augmentations have been found for standard vision datasets, such as ImageNet, it is still an open problem in other applications, such as medical imaging, or in datasets with easy-to-learn but irrelevant imaging features. In this work, we propose a new way to define positive samples using kernel theory along with a novel loss called decoupled uniformity. We propose to integrate prior information, learnt from generative models or given as auxiliary attributes, into contrastive learning, to make it less dependent on data augmentation. We draw a connection between contrastive learning and the conditional mean embedding theory to derive tight bounds on the downstream classification loss. In an unsupervised setting, we empirically demonstrate that CL benefits from generative models, such as VAE and GAN, to less rely on data augmentations. We validate our framework on vision datasets including CIFAR10, CIFAR100, STL10 and ImageNet100 and a brain MRI dataset. In the weakly supervised setting, we demonstrate that our formulation provides state-of-the-art results.
Conditional Alignment and Uniformity for Contrastive Learning with Continuous Proxy Labels
Nov 10, 2021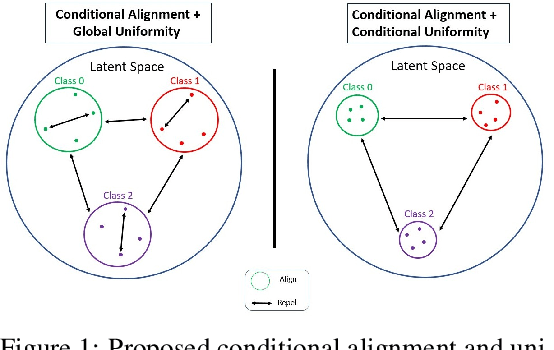
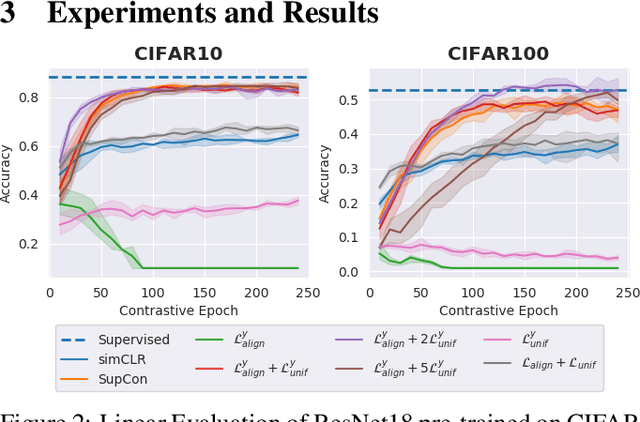
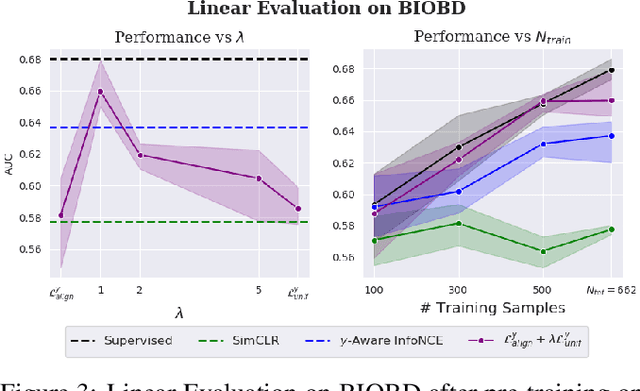
Contrastive Learning has shown impressive results on natural and medical images, without requiring annotated data. However, a particularity of medical images is the availability of meta-data (such as age or sex) that can be exploited for learning representations. Here, we show that the recently proposed contrastive y-Aware InfoNCE loss, that integrates multi-dimensional meta-data, asymptotically optimizes two properties: conditional alignment and global uniformity. Similarly to [Wang, 2020], conditional alignment means that similar samples should have similar features, but conditionally on the meta-data. Instead, global uniformity means that the (normalized) features should be uniformly distributed on the unit hyper-sphere, independently of the meta-data. Here, we propose to define conditional uniformity, relying on the meta-data, that repel only samples with dissimilar meta-data. We show that direct optimization of both conditional alignment and uniformity improves the representations, in terms of linear evaluation, on both CIFAR-100 and a brain MRI dataset.