 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving BERT with Hybrid Pooling Network and Drop Mask
Jul 14, 2023
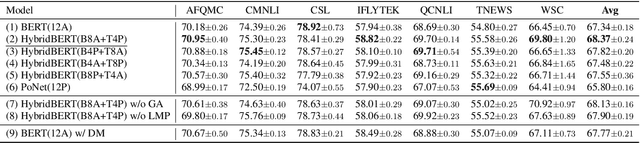
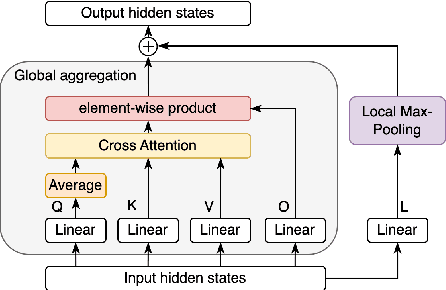
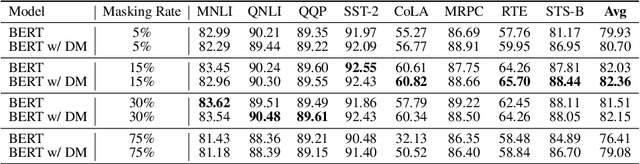
Transformer-based pre-trained language models, such as BERT, achieve great success in various natural language understanding tasks. Prior research found that BERT captures a rich hierarchy of linguistic information at different layers. However, the vanilla BERT uses the same self-attention mechanism for each layer to model the different contextual features. In this paper, we propose a HybridBERT model which combines self-attention and pooling networks to encode different contextual features in each layer. Additionally, we propose a simple DropMask method to address the mismatch between pre-training and fine-tuning caused by excessive use of special mask tokens during Masked Language Modeling pre-training. Experiments show that HybridBERT outperforms BERT in pre-training with lower loss, faster training speed (8% relative), lower memory cost (13% relative), and also in transfer learning with 1.5% relative higher accuracies on downstream tasks. Additionally, DropMask improves accuracies of BERT on downstream tasks across various masking rates.
VS-TransGRU: A Novel Transformer-GRU-based Framework Enhanced by Visual-Semantic Fusion for Egocentric Action Anticipation
Jul 08, 2023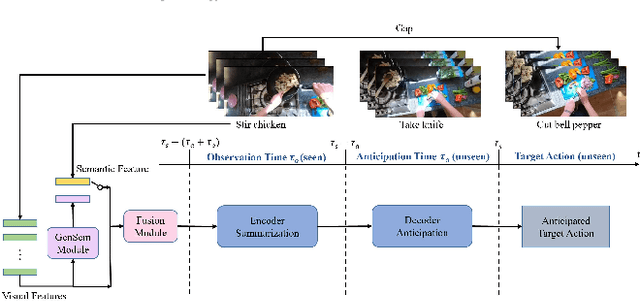
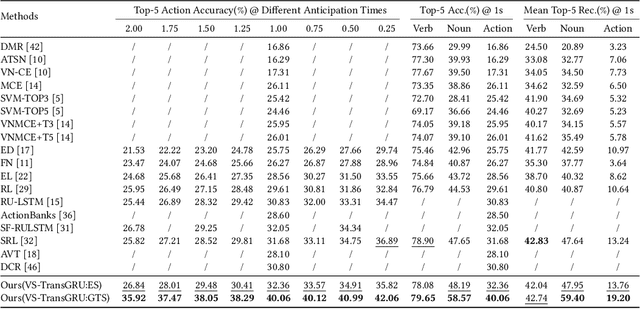

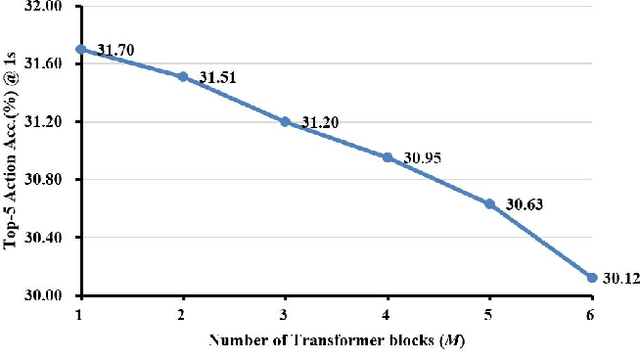
Egocentric action anticipation is a challenging task that aims to make advanced predictions of future actions from current and historical observations in the first-person view. Most existing methods focus on improving the model architecture and loss function based on the visual input and recurrent neural network to boost the anticipation performance. However, these methods, which merely consider visual information and rely on a single network architecture, gradually reach a performance plateau. In order to fully understand what has been observed and capture the dependencies between current observations and future actions well enough, we propose a novel visual-semantic fusion enhanced and Transformer GRU-based action anticipation framework in this paper. Firstly, high-level semantic information is introduced to improve the performance of action anticipation for the first time. We propose to use the semantic features generated based on the class labels or directly from the visual observations to augment the original visual features. Secondly, an effective visual-semantic fusion module is proposed to make up for the semantic gap and fully utilize the complementarity of different modalities. Thirdly, to take advantage of both the parallel and autoregressive models, we design a Transformer based encoder for long-term sequential modeling and a GRU-based decoder for flexible iteration decoding. Extensive experiments on two large-scale first-person view datasets, i.e., EPIC-Kitchens and EGTEA Gaze+, validate the effectiveness of our proposed method, which achieves new state-of-the-art performance, outperforming previous approaches by a large margin.
Information-Theoretic Diffusion
Feb 07, 2023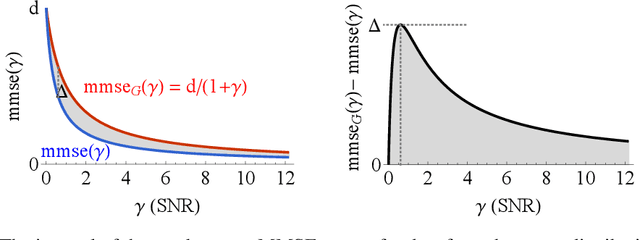
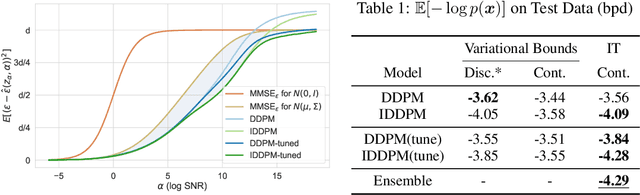
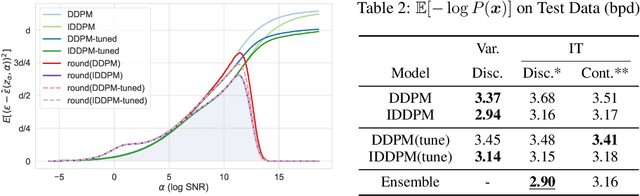
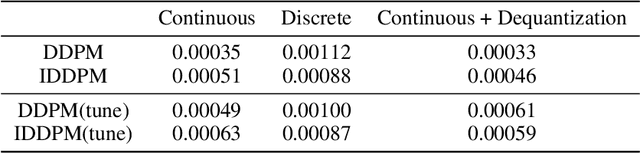
Denoising diffusion models have spurred significant gains in density modeling and image generation, precipitating an industrial revolution in text-guided AI art generation. We introduce a new mathematical foundation for diffusion models inspired by classic results in information theory that connect Information with Minimum Mean Square Error regression, the so-called I-MMSE relations. We generalize the I-MMSE relations to exactly relate the data distribution to an optimal denoising regression problem, leading to an elegant refinement of existing diffusion bounds. This new insight leads to several improvements for probability distribution estimation, including theoretical justification for diffusion model ensembling. Remarkably, our framework shows how continuous and discrete probabilities can be learned with the same regression objective, avoiding domain-specific generative models used in variational methods. Code to reproduce experiments is provided at http://github.com/kxh001/ITdiffusion and simplified demonstration code is at http://github.com/gregversteeg/InfoDiffusionSimple.
Graph-Ensemble Learning Model for Multi-label Skin Lesion Classification using Dermoscopy and Clinical Images
Jul 04, 2023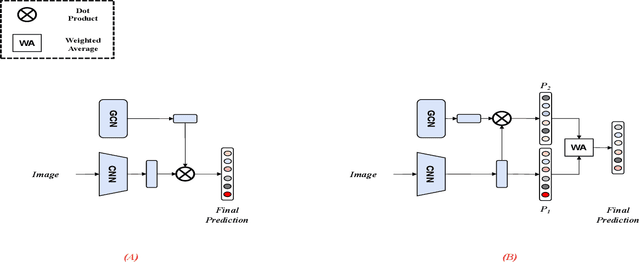
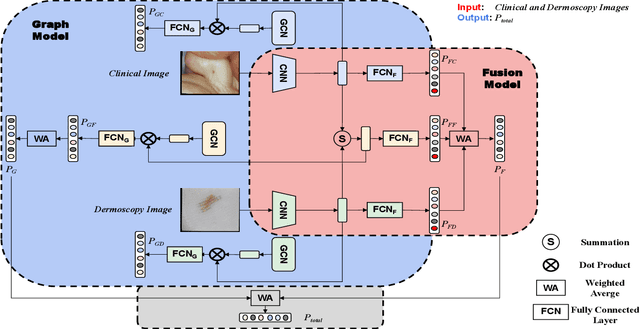
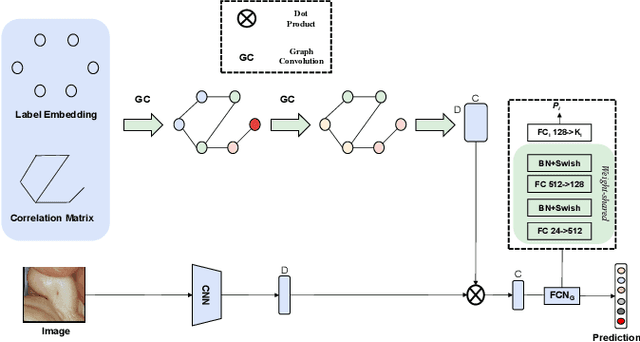
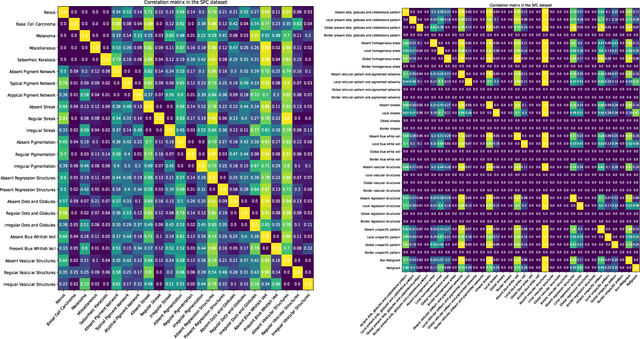
Many skin lesion analysis (SLA) methods recently focused on developing a multi-modal-based multi-label classification method due to two factors. The first is multi-modal data, i.e., clinical and dermoscopy images, which can provide complementary information to obtain more accurate results than single-modal data. The second one is that multi-label classification, i.e., seven-point checklist (SPC) criteria as an auxiliary classification task can not only boost the diagnostic accuracy of melanoma in the deep learning (DL) pipeline but also provide more useful functions to the clinical doctor as it is commonly used in clinical dermatologist's diagnosis. However, most methods only focus on designing a better module for multi-modal data fusion; few methods explore utilizing the label correlation between SPC and skin disease for performance improvement. This study fills the gap that introduces a Graph Convolution Network (GCN) to exploit prior co-occurrence between each category as a correlation matrix into the DL model for the multi-label classification. However, directly applying GCN degraded the performances in our experiments; we attribute this to the weak generalization ability of GCN in the scenario of insufficient statistical samples of medical data. We tackle this issue by proposing a Graph-Ensemble Learning Model (GELN) that views the prediction from GCN as complementary information of the predictions from the fusion model and adaptively fuses them by a weighted averaging scheme, which can utilize the valuable information from GCN while avoiding its negative influences as much as possible. To evaluate our method, we conduct experiments on public datasets. The results illustrate that our GELN can consistently improve the classification performance on different datasets and that the proposed method can achieve state-of-the-art performance in SPC and diagnosis classification.
GraphCL-DTA: a graph contrastive learning with molecular semantics for drug-target binding affinity prediction
Jul 18, 2023
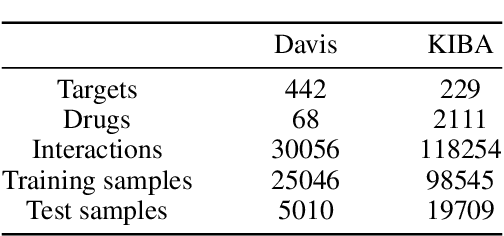
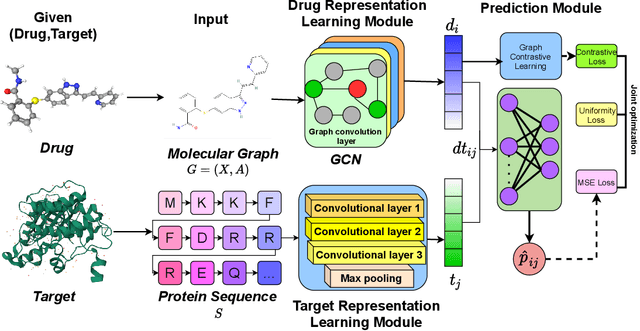

Drug-target binding affinity prediction plays an important role in the early stages of drug discovery, which can infer the strength of interactions between new drugs and new targets. However, the performance of previous computational models is limited by the following drawbacks. The learning of drug representation relies only on supervised data, without taking into account the information contained in the molecular graph itself. Moreover, most previous studies tended to design complicated representation learning module, while uniformity, which is used to measure representation quality, is ignored. In this study, we propose GraphCL-DTA, a graph contrastive learning with molecular semantics for drug-target binding affinity prediction. In GraphCL-DTA, we design a graph contrastive learning framework for molecular graphs to learn drug representations, so that the semantics of molecular graphs are preserved. Through this graph contrastive framework, a more essential and effective drug representation can be learned without additional supervised data. Next, we design a new loss function that can be directly used to smoothly adjust the uniformity of drug and target representations. By directly optimizing the uniformity of representations, the representation quality of drugs and targets can be improved. The effectiveness of the above innovative elements is verified on two real datasets, KIBA and Davis. The excellent performance of GraphCL-DTA on the above datasets suggests its superiority to the state-of-the-art model.
TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT
Jul 18, 2023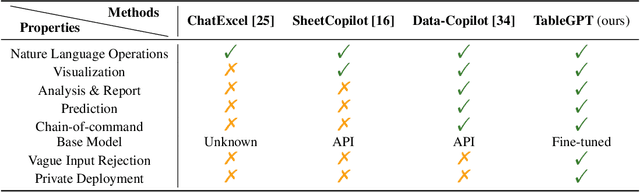
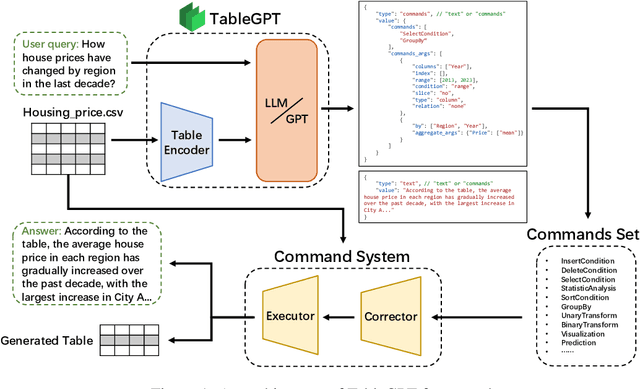
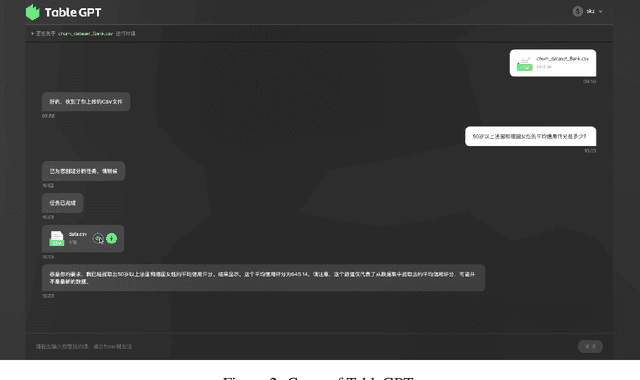
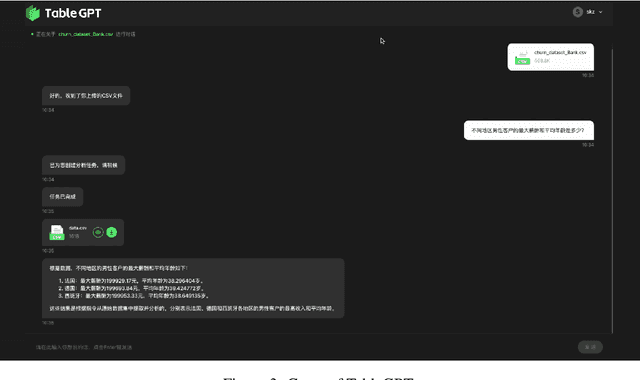
Tables are prevalent in real-world databases, requiring significant time and effort for humans to analyze and manipulate. The advancements in large language models (LLMs) have made it possible to interact with tables using natural language input, bringing this capability closer to reality. In this paper, we present TableGPT, a unified fine-tuned framework that enables LLMs to understand and operate on tables using external functional commands. It introduces the capability to seamlessly interact with tables, enabling a wide range of functionalities such as question answering, data manipulation (e.g., insert, delete, query, and modify operations), data visualization, analysis report generation, and automated prediction. TableGPT aims to provide convenience and accessibility to users by empowering them to effortlessly leverage tabular data. At the core of TableGPT lies the novel concept of global tabular representations, which empowers LLMs to gain a comprehensive understanding of the entire table beyond meta-information. By jointly training LLMs on both table and text modalities, TableGPT achieves a deep understanding of tabular data and the ability to perform complex operations on tables through chain-of-command instructions. Importantly, TableGPT offers the advantage of being a self-contained system rather than relying on external API interfaces. Moreover, it supports efficient data process flow, query rejection (when appropriate) and private deployment, enabling faster domain data fine-tuning and ensuring data privacy, which enhances the framework's adaptability to specific use cases.
R-Cut: Enhancing Explainability in Vision Transformers with Relationship Weighted Out and Cut
Jul 18, 2023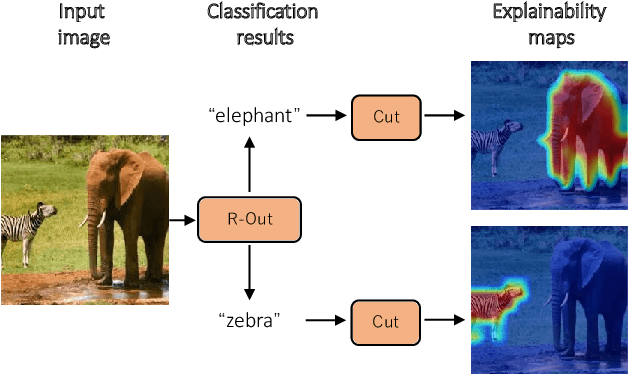
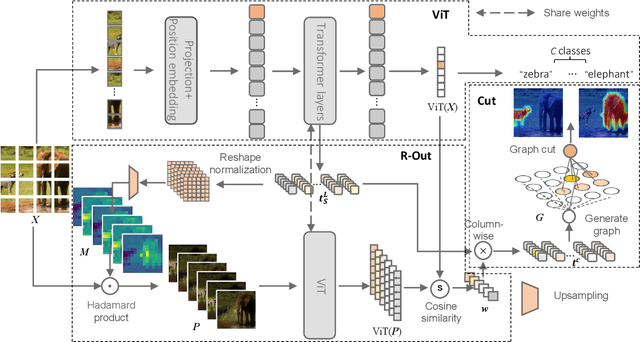
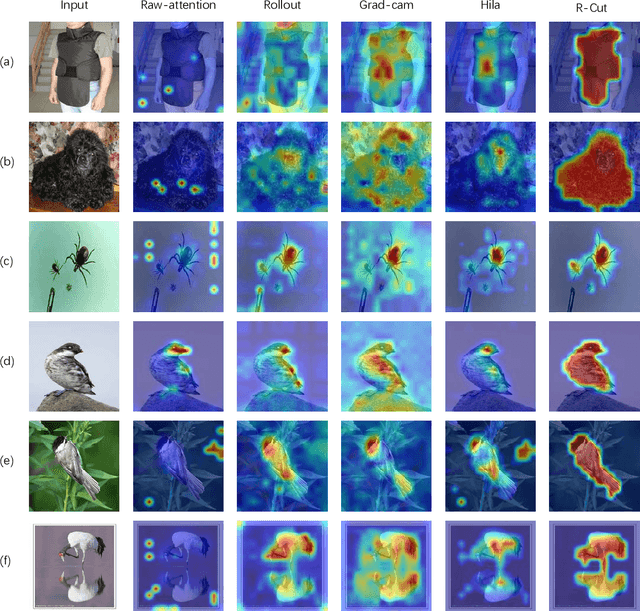
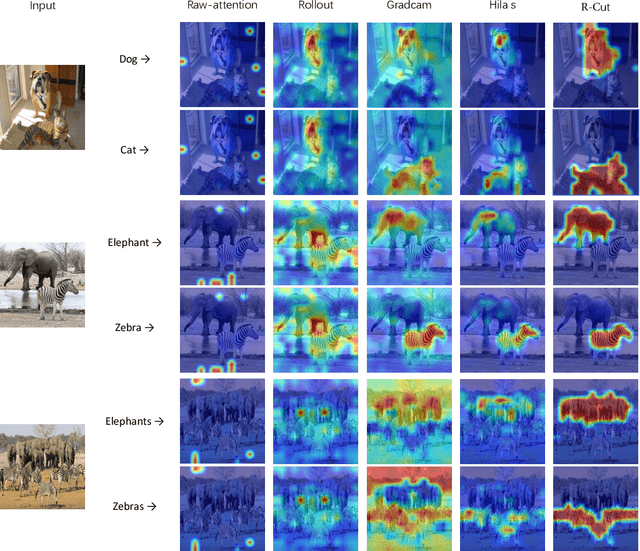
Transformer-based models have gained popularity in the field of natural language processing (NLP) and are extensively utilized in computer vision tasks and multi-modal models such as GPT4. This paper presents a novel method to enhance the explainability of Transformer-based image classification models. Our method aims to improve trust in classification results and empower users to gain a deeper understanding of the model for downstream tasks by providing visualizations of class-specific maps. We introduce two modules: the ``Relationship Weighted Out" and the ``Cut" modules. The ``Relationship Weighted Out" module focuses on extracting class-specific information from intermediate layers, enabling us to highlight relevant features. Additionally, the ``Cut" module performs fine-grained feature decomposition, taking into account factors such as position, texture, and color. By integrating these modules, we generate dense class-specific visual explainability maps. We validate our method with extensive qualitative and quantitative experiments on the ImageNet dataset. Furthermore, we conduct a large number of experiments on the LRN dataset, specifically designed for automatic driving danger alerts, to evaluate the explainability of our method in complex backgrounds. The results demonstrate a significant improvement over previous methods. Moreover, we conduct ablation experiments to validate the effectiveness of each module. Through these experiments, we are able to confirm the respective contributions of each module, thus solidifying the overall effectiveness of our proposed approach.
From random-walks to graph-sprints: a low-latency node embedding framework on continuous-time dynamic graphs
Jul 18, 2023
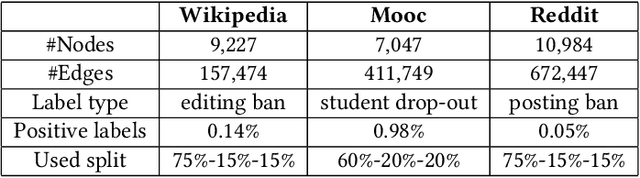
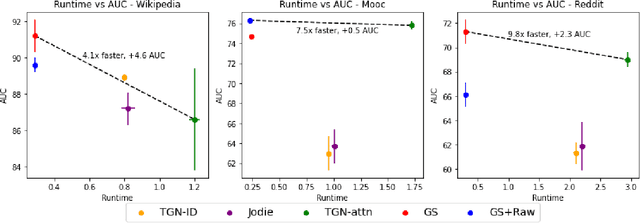
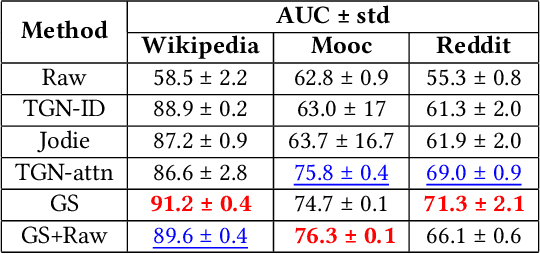
Many real-world datasets have an underlying dynamic graph structure, where entities and their interactions evolve over time. Machine learning models should consider these dynamics in order to harness their full potential in downstream tasks. Previous approaches for graph representation learning have focused on either sampling k-hop neighborhoods, akin to breadth-first search, or random walks, akin to depth-first search. However, these methods are computationally expensive and unsuitable for real-time, low-latency inference on dynamic graphs. To overcome these limitations, we propose graph-sprints a general purpose feature extraction framework for continuous-time-dynamic-graphs (CTDGs) that has low latency and is competitive with state-of-the-art, higher latency models. To achieve this, a streaming, low latency approximation to the random-walk based features is proposed. In our framework, time-aware node embeddings summarizing multi-hop information are computed using only single-hop operations on the incoming edges. We evaluate our proposed approach on three open-source datasets and two in-house datasets, and compare with three state-of-the-art algorithms (TGN-attn, TGN-ID, Jodie). We demonstrate that our graph-sprints features, combined with a machine learning classifier, achieve competitive performance (outperforming all baselines for the node classification tasks in five datasets). Simultaneously, graph-sprints significantly reduce inference latencies, achieving close to an order of magnitude speed-up in our experimental setting.
Class-relation Knowledge Distillation for Novel Class Discovery
Jul 18, 2023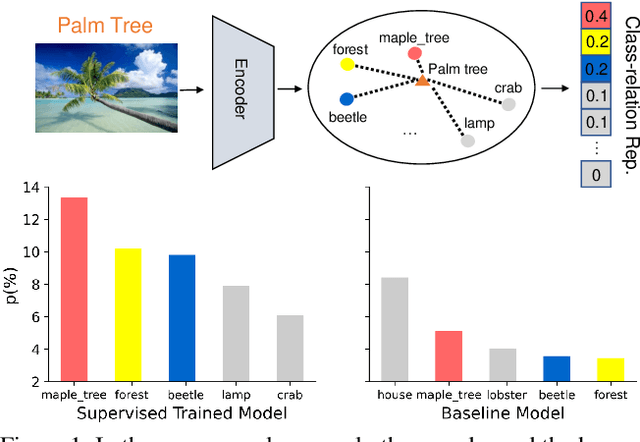
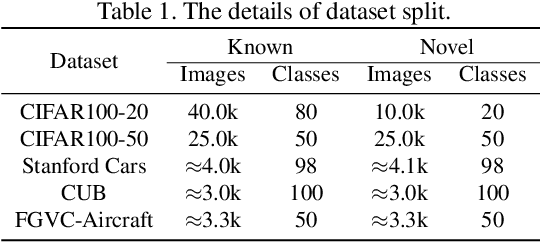
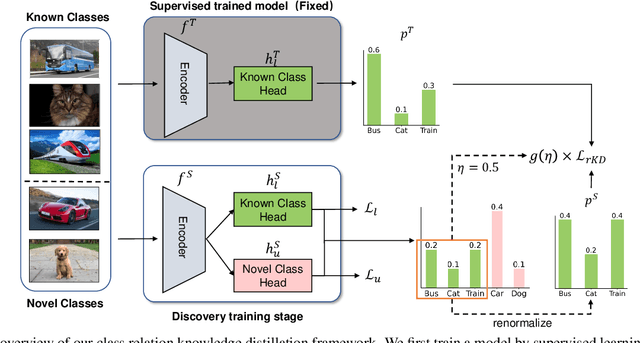
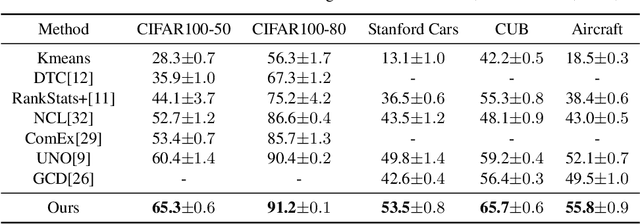
We tackle the problem of novel class discovery, which aims to learn novel classes without supervision based on labeled data from known classes. A key challenge lies in transferring the knowledge in the known-class data to the learning of novel classes. Previous methods mainly focus on building a shared representation space for knowledge transfer and often ignore modeling class relations. To address this, we introduce a class relation representation for the novel classes based on the predicted class distribution of a model trained on known classes. Empirically, we find that such class relation becomes less informative during typical discovery training. To prevent such information loss, we propose a novel knowledge distillation framework, which utilizes our class-relation representation to regularize the learning of novel classes. In addition, to enable a flexible knowledge distillation scheme for each data point in novel classes, we develop a learnable weighting function for the regularization, which adaptively promotes knowledge transfer based on the semantic similarity between the novel and known classes. To validate the effectiveness and generalization of our method, we conduct extensive experiments on multiple benchmarks, including CIFAR100, Stanford Cars, CUB, and FGVC-Aircraft datasets. Our results demonstrate that the proposed method outperforms the previous state-of-the-art methods by a significant margin on almost all benchmarks. Code is available at \href{https://github.com/kleinzcy/Cr-KD-NCD}{here}.
With Flying Colors: Predicting Community Success in Large-scale Collaborative Campaigns
Jul 18, 2023Online communities develop unique characteristics, establish social norms, and exhibit distinct dynamics among their members. Activity in online communities often results in concrete ``off-line'' actions with a broad societal impact (e.g., political street protests and norms related to sexual misconduct). While community dynamics, information diffusion, and online collaborations have been widely studied in the past two decades, quantitative studies that measure the effectiveness of online communities in promoting their agenda are scarce. In this work, we study the correspondence between the effectiveness of a community, measured by its success level in a competitive online campaign, and the underlying dynamics between its members. To this end, we define a novel task: predicting the success level of online communities in Reddit's r/place - a large-scale distributed experiment that required collaboration between community members. We consider an array of definitions for success level; each is geared toward different aspects of collaborative achievement. We experiment with several hybrid models, combining various types of features. Our models significantly outperform all baseline models over all definitions of `success level'. Analysis of the results and the factors that contribute to the success of coordinated campaigns can provide a better understanding of the resilience or the vulnerability of communities to online social threats such as election interference or anti-science trends. We make all data used for this study publicly available for further research.