 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Nest-DGIL: Nesterov-optimized Deep Geometric Incremental Learning for CS Image Reconstruction
Aug 06, 2023
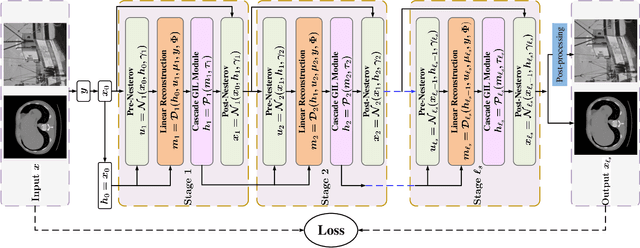
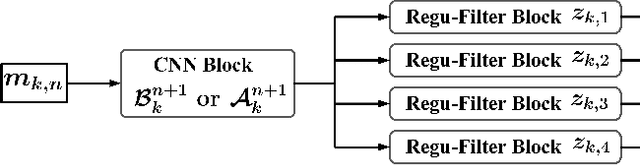
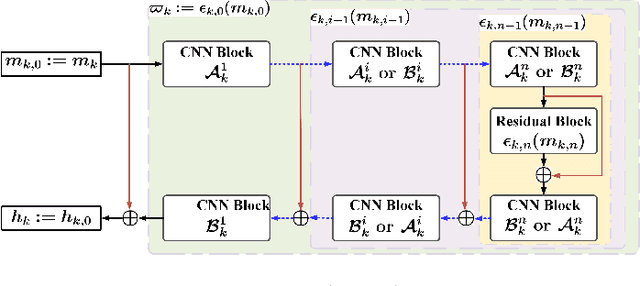
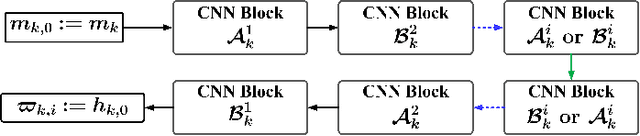
Proximal gradient-based optimization is one of the most common strategies for solving image inverse problems as well as easy to implement. However, these techniques often generate heavy artifacts in image reconstruction. One of the most popular refinement methods is to fine-tune the regularization parameter to alleviate such artifacts, but it may not always be sufficient or applicable due to increased computational costs. In this work, we propose a deep geometric incremental learning framework based on second Nesterov proximal gradient optimization. The proposed end-to-end network not only has the powerful learning ability for high/low frequency image features,but also can theoretically guarantee that geometric texture details will be reconstructed from preliminary linear reconstruction.Furthermore, it can avoid the risk of intermediate reconstruction results falling outside the geometric decomposition domains and achieve fast convergence. Our reconstruction framework is decomposed into four modules including general linear reconstruction, cascade geometric incremental restoration, Nesterov acceleration and post-processing. In the image restoration step,a cascade geometric incremental learning module is designed to compensate for the missing texture information from different geometric spectral decomposition domains. Inspired by overlap-tile strategy, we also develop a post-processing module to remove the block-effect in patch-wise-based natural image reconstruction. All parameters in the proposed model are learnable,an adaptive initialization technique of physical-parameters is also employed to make model flexibility and ensure converging smoothly. We compare the reconstruction performance of the proposed method with existing state-of-the-art methods to demonstrate its superiority. Our source codes are available at https://github.com/fanxiaohong/Nest-DGIL.
MARIO: Model Agnostic Recipe for Improving OOD Generalization of Graph Contrastive Learning
Aug 02, 2023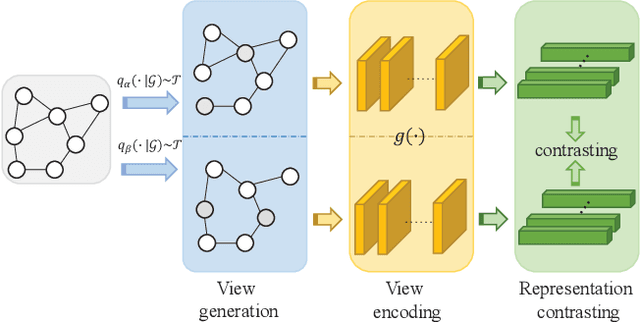

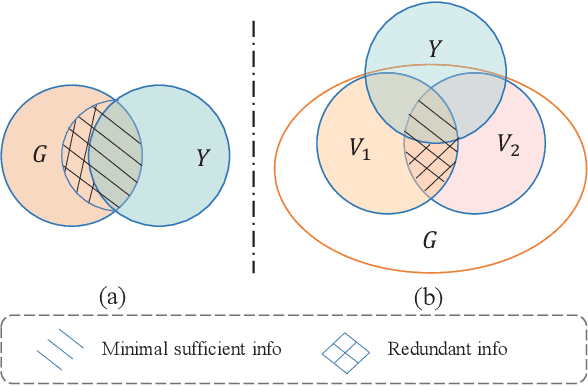
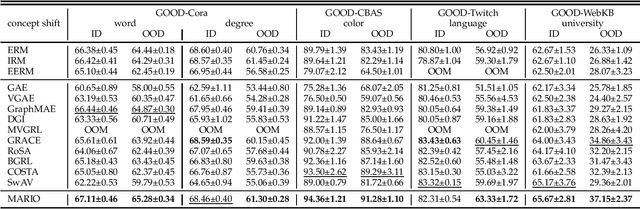
In this work, we investigate the problem of out-of-distribution (OOD) generalization for unsupervised learning methods on graph data. This scenario is particularly challenging because graph neural networks (GNNs) have been shown to be sensitive to distributional shifts, even when labels are available. To address this challenge, we propose a \underline{M}odel-\underline{A}gnostic \underline{R}ecipe for \underline{I}mproving \underline{O}OD generalizability of unsupervised graph contrastive learning methods, which we refer to as MARIO. MARIO introduces two principles aimed at developing distributional-shift-robust graph contrastive methods to overcome the limitations of existing frameworks: (i) Information Bottleneck (IB) principle for achieving generalizable representations and (ii) Invariant principle that incorporates adversarial data augmentation to obtain invariant representations. To the best of our knowledge, this is the first work that investigates the OOD generalization problem of graph contrastive learning, with a specific focus on node-level tasks. Through extensive experiments, we demonstrate that our method achieves state-of-the-art performance on the OOD test set, while maintaining comparable performance on the in-distribution test set when compared to existing approaches. The source code for our method can be found at: https://github.com/ZhuYun97/MARIO
A Novel Cross-Perturbation for Single Domain Generalization
Aug 02, 2023
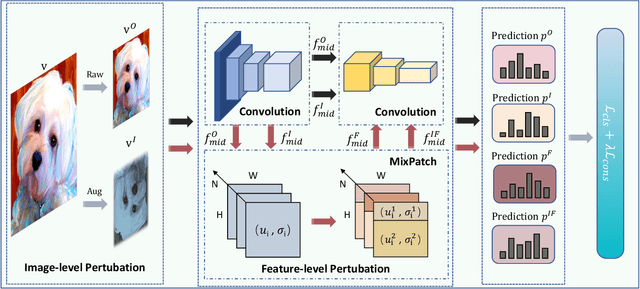
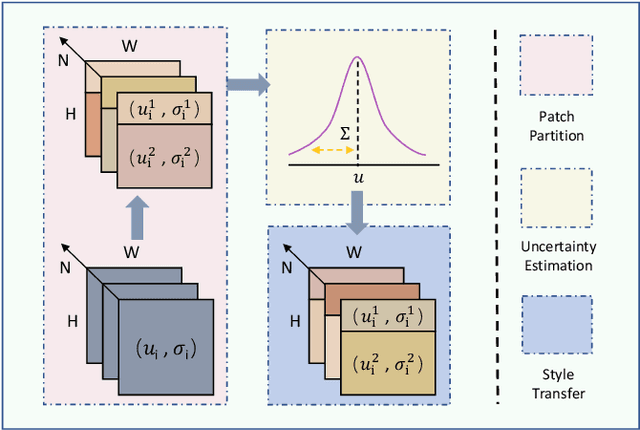

Single domain generalization aims to enhance the ability of the model to generalize to unknown domains when trained on a single source domain. However, the limited diversity in the training data hampers the learning of domain-invariant features, resulting in compromised generalization performance. To address this, data perturbation (augmentation) has emerged as a crucial method to increase data diversity. Nevertheless, existing perturbation methods often focus on either image-level or feature-level perturbations independently, neglecting their synergistic effects. To overcome these limitations, we propose CPerb, a simple yet effective cross-perturbation method. Specifically, CPerb utilizes both horizontal and vertical operations. Horizontally, it applies image-level and feature-level perturbations to enhance the diversity of the training data, mitigating the issue of limited diversity in single-source domains. Vertically, it introduces multi-route perturbation to learn domain-invariant features from different perspectives of samples with the same semantic category, thereby enhancing the generalization capability of the model. Additionally, we propose MixPatch, a novel feature-level perturbation method that exploits local image style information to further diversify the training data. Extensive experiments on various benchmark datasets validate the effectiveness of our method.
Grasp Stability Assessment Through Attention-Guided Cross-Modality Fusion and Transfer Learning
Aug 02, 2023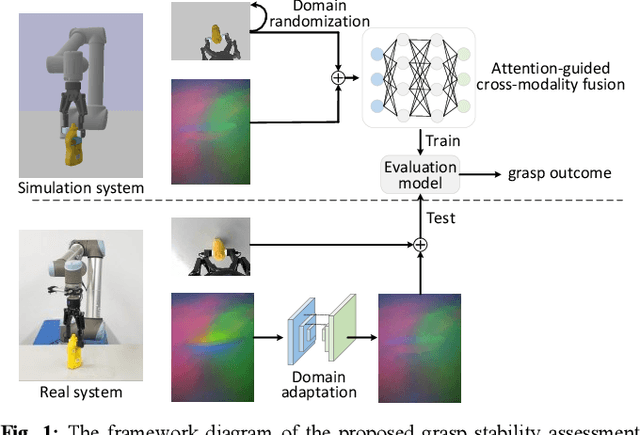
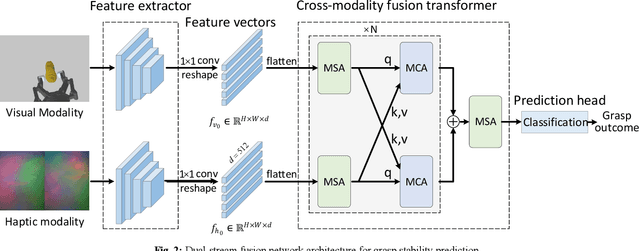
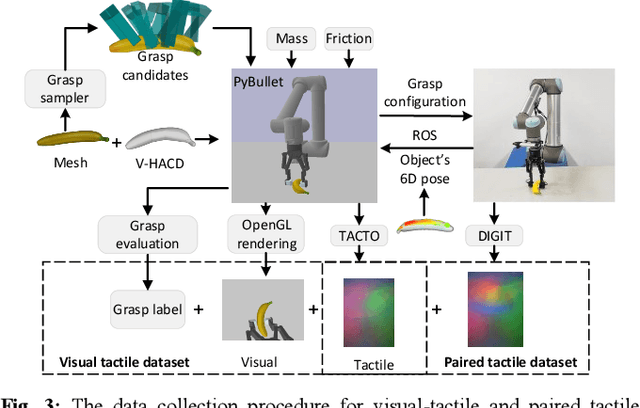
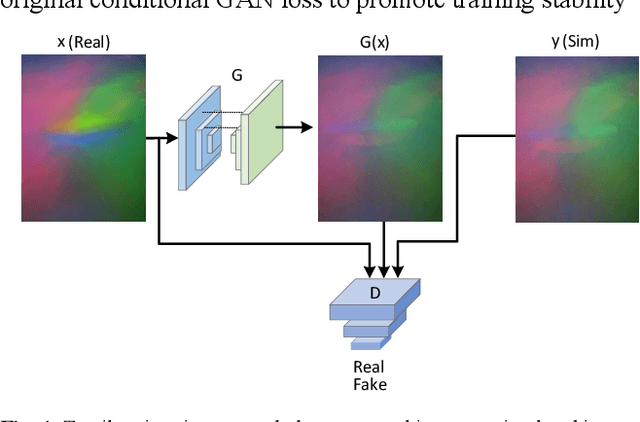
Extensive research has been conducted on assessing grasp stability, a crucial prerequisite for achieving optimal grasping strategies, including the minimum force grasping policy. However, existing works employ basic feature-level fusion techniques to combine visual and tactile modalities, resulting in the inadequate utilization of complementary information and the inability to model interactions between unimodal features. This work proposes an attention-guided cross-modality fusion architecture to comprehensively integrate visual and tactile features. This model mainly comprises convolutional neural networks (CNNs), self-attention, and cross-attention mechanisms. In addition, most existing methods collect datasets from real-world systems, which is time-consuming and high-cost, and the datasets collected are comparatively limited in size. This work establishes a robotic grasping system through physics simulation to collect a multimodal dataset. To address the sim-to-real transfer gap, we propose a migration strategy encompassing domain randomization and domain adaptation techniques. The experimental results demonstrate that the proposed fusion framework achieves markedly enhanced prediction performance (approximately 10%) compared to other baselines. Moreover, our findings suggest that the trained model can be reliably transferred to real robotic systems, indicating its potential to address real-world challenges.
Interpreting Transformer's Attention Dynamic Memory and Visualizing the Semantic Information Flow of GPT
May 22, 2023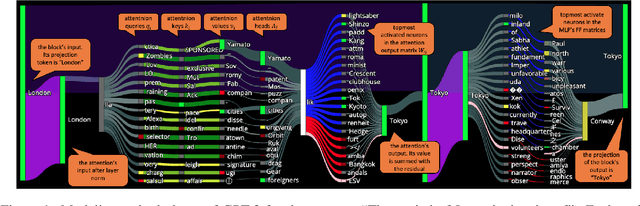
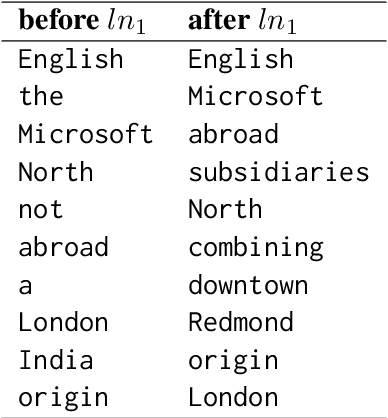

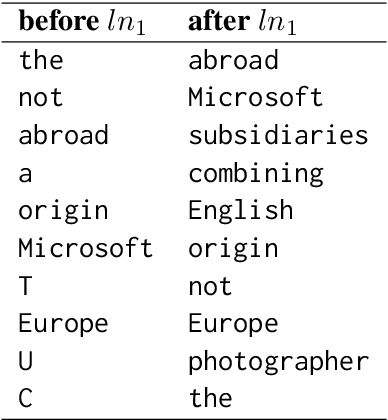
Recent advances in interpretability suggest we can project weights and hidden states of transformer-based language models (LMs) to their vocabulary, a transformation that makes them human interpretable and enables us to assign semantics to what was seen only as numerical vectors. In this paper, we interpret LM attention heads and memory values, the vectors the models dynamically create and recall while processing a given input. By analyzing the tokens they represent through this projection, we identify patterns in the information flow inside the attention mechanism. Based on these discoveries, we create a tool to visualize a forward pass of Generative Pre-trained Transformers (GPTs) as an interactive flow graph, with nodes representing neurons or hidden states and edges representing the interactions between them. Our visualization simplifies huge amounts of data into easy-to-read plots that reflect why models output their results. We demonstrate the utility of our modeling by identifying the effect LM components have on the intermediate processing in the model before outputting a prediction. For instance, we discover that layer norms are used as semantic filters and find neurons that act as regularization vectors.
Phase Matching for Out-of-Distribution Generalization
Aug 01, 2023
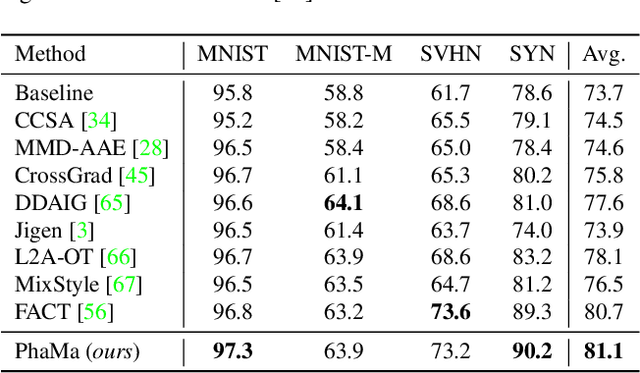
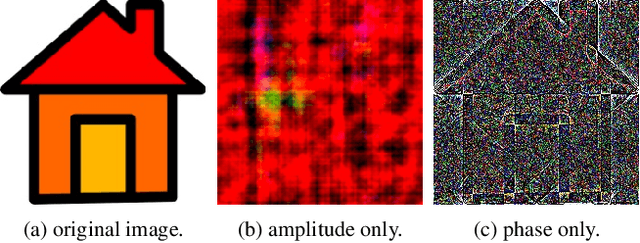
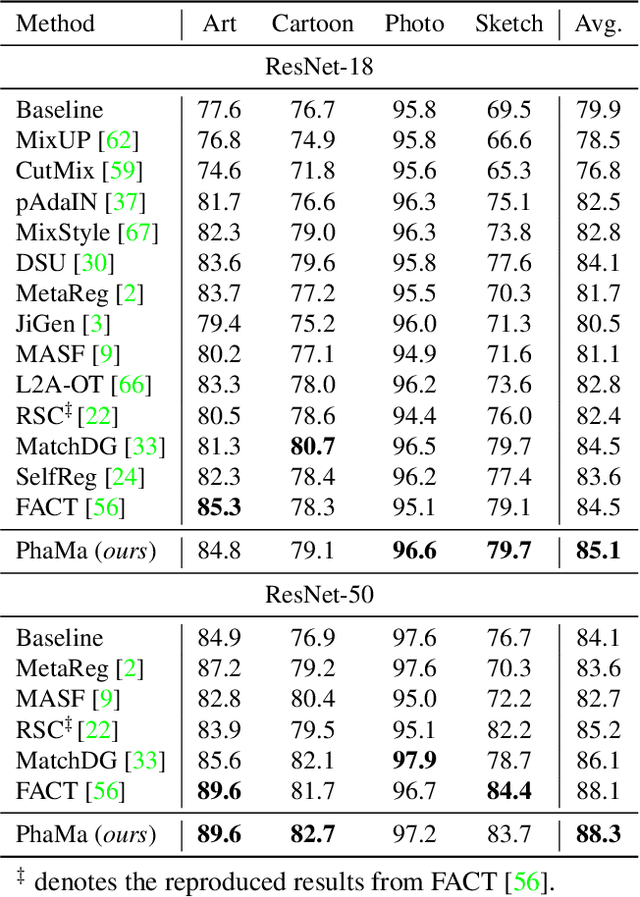
The Fourier transform, serving as an explicit decomposition method for visual signals, has been employed to explain the out-of-distribution generalization behaviors of Convolutional Neural Networks (CNNs). Previous studies have indicated that the amplitude spectrum is susceptible to the disturbance caused by distribution shifts. On the other hand, the phase spectrum preserves highly-structured spatial information, which is crucial for robust visual representation learning. However, the spatial relationships of phase spectrum remain unexplored in previous researches. In this paper, we aim to clarify the relationships between Domain Generalization (DG) and the frequency components, and explore the spatial relationships of the phase spectrum. Specifically, we first introduce a Fourier-based structural causal model which interprets the phase spectrum as semi-causal factors and the amplitude spectrum as non-causal factors. Then, we propose Phase Matching (PhaMa) to address DG problems. Our method introduces perturbations on the amplitude spectrum and establishes spatial relationships to match the phase components. Through experiments on multiple benchmarks, we demonstrate that our proposed method achieves state-of-the-art performance in domain generalization and out-of-distribution robustness tasks.
3D Semantic Subspace Traverser: Empowering 3D Generative Model with Shape Editing Capability
Aug 01, 2023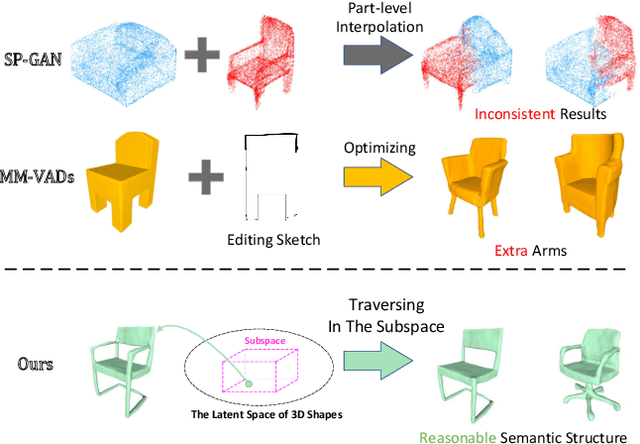
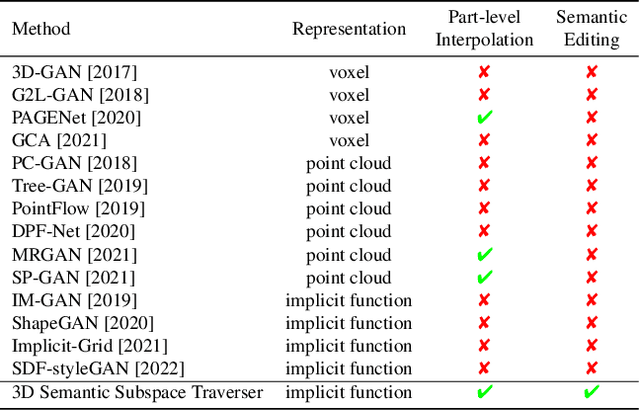
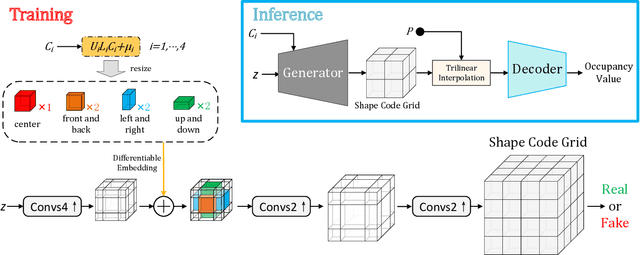
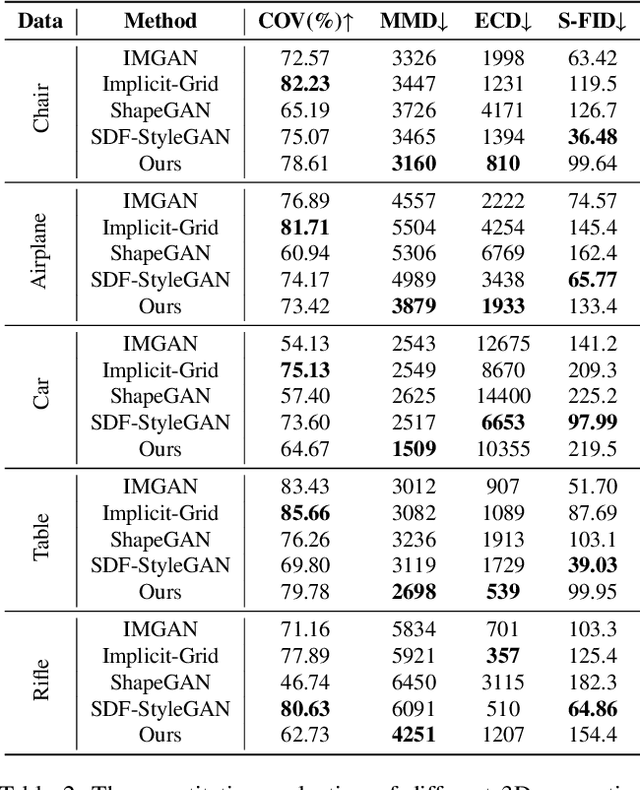
Shape generation is the practice of producing 3D shapes as various representations for 3D content creation. Previous studies on 3D shape generation have focused on shape quality and structure, without or less considering the importance of semantic information. Consequently, such generative models often fail to preserve the semantic consistency of shape structure or enable manipulation of the semantic attributes of shapes during generation. In this paper, we proposed a novel semantic generative model named 3D Semantic Subspace Traverser that utilizes semantic attributes for category-specific 3D shape generation and editing. Our method utilizes implicit functions as the 3D shape representation and combines a novel latent-space GAN with a linear subspace model to discover semantic dimensions in the local latent space of 3D shapes. Each dimension of the subspace corresponds to a particular semantic attribute, and we can edit the attributes of generated shapes by traversing the coefficients of those dimensions. Experimental results demonstrate that our method can produce plausible shapes with complex structures and enable the editing of semantic attributes. The code and trained models are available at https://github.com/TrepangCat/3D_Semantic_Subspace_Traverser
Seeing Behind Dynamic Occlusions with Event Cameras
Aug 01, 2023
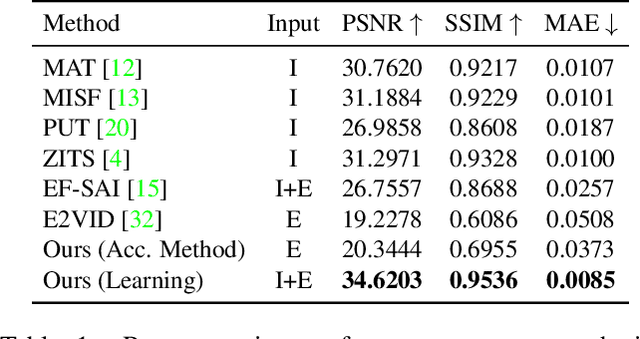
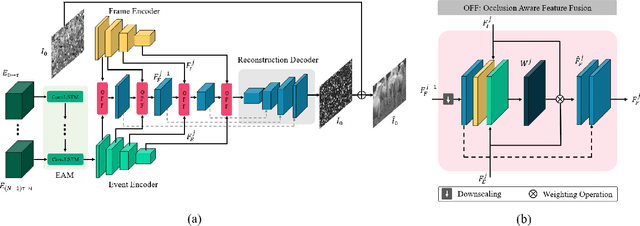
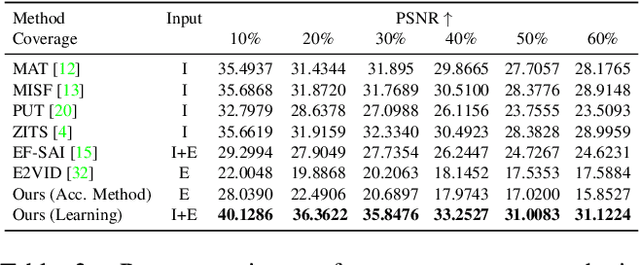
Unwanted camera occlusions, such as debris, dust, rain-drops, and snow, can severely degrade the performance of computer-vision systems. Dynamic occlusions are particularly challenging because of the continuously changing pattern. Existing occlusion-removal methods currently use synthetic aperture imaging or image inpainting. However, they face issues with dynamic occlusions as these require multiple viewpoints or user-generated masks to hallucinate the background intensity. We propose a novel approach to reconstruct the background from a single viewpoint in the presence of dynamic occlusions. Our solution relies for the first time on the combination of a traditional camera with an event camera. When an occlusion moves across a background image, it causes intensity changes that trigger events. These events provide additional information on the relative intensity changes between foreground and background at a high temporal resolution, enabling a truer reconstruction of the background content. We present the first large-scale dataset consisting of synchronized images and event sequences to evaluate our approach. We show that our method outperforms image inpainting methods by 3dB in terms of PSNR on our dataset.
Part-level Scene Reconstruction Affords Robot Interaction
Aug 01, 2023
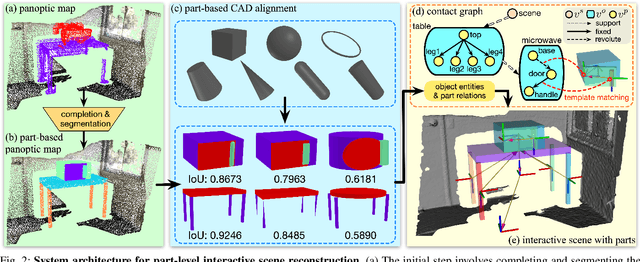
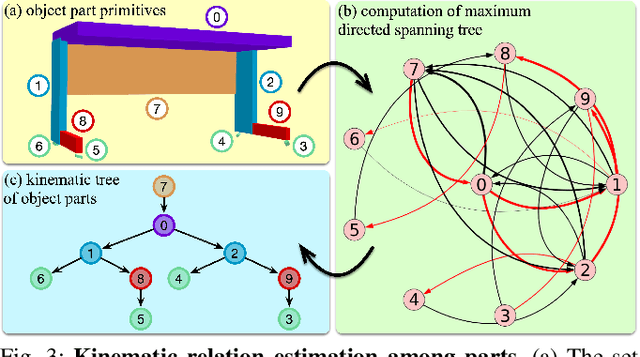
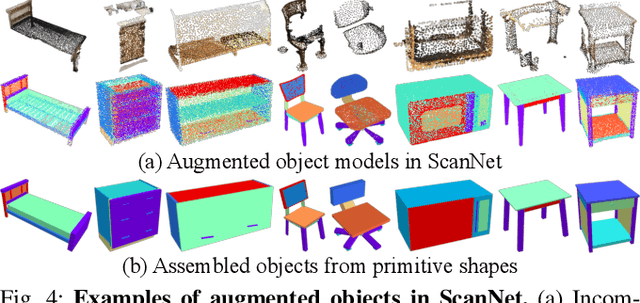
Existing methods for reconstructing interactive scenes primarily focus on replacing reconstructed objects with CAD models retrieved from a limited database, resulting in significant discrepancies between the reconstructed and observed scenes. To address this issue, our work introduces a part-level reconstruction approach that reassembles objects using primitive shapes. This enables us to precisely replicate the observed physical scenes and simulate robot interactions with both rigid and articulated objects. By segmenting reconstructed objects into semantic parts and aligning primitive shapes to these parts, we assemble them as CAD models while estimating kinematic relations, including parent-child contact relations, joint types, and parameters. Specifically, we derive the optimal primitive alignment by solving a series of optimization problems, and estimate kinematic relations based on part semantics and geometry. Our experiments demonstrate that part-level scene reconstruction outperforms object-level reconstruction by accurately capturing finer details and improving precision. These reconstructed part-level interactive scenes provide valuable kinematic information for various robotic applications; we showcase the feasibility of certifying mobile manipulation planning in these interactive scenes before executing tasks in the physical world.
Mapping Computer Science Research: Trends, Influences, and Predictions
Aug 01, 2023This paper explores the current trending research areas in the field of Computer Science (CS) and investigates the factors contributing to their emergence. Leveraging a comprehensive dataset comprising papers, citations, and funding information, we employ advanced machine learning techniques, including Decision Tree and Logistic Regression models, to predict trending research areas. Our analysis reveals that the number of references cited in research papers (Reference Count) plays a pivotal role in determining trending research areas making reference counts the most relevant factor that drives trend in the CS field. Additionally, the influence of NSF grants and patents on trending topics has increased over time. The Logistic Regression model outperforms the Decision Tree model in predicting trends, exhibiting higher accuracy, precision, recall, and F1 score. By surpassing a random guess baseline, our data-driven approach demonstrates higher accuracy and efficacy in identifying trending research areas. The results offer valuable insights into the trending research areas, providing researchers and institutions with a data-driven foundation for decision-making and future research direction.