 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Pose-Guided Imitation Learning for Robotic Precise Insertion
May 14, 2025Recent studies have proved that imitation learning shows strong potential in the field of robotic manipulation. However, existing methods still struggle with precision manipulation task and rely on inefficient image/point cloud observations. In this paper, we explore to introduce SE(3) object pose into imitation learning and propose the pose-guided efficient imitation learning methods for robotic precise insertion task. First, we propose a precise insertion diffusion policy which utilizes the relative SE(3) pose as the observation-action pair. The policy models the source object SE(3) pose trajectory relative to the target object. Second, we explore to introduce the RGBD data to the pose-guided diffusion policy. Specifically, we design a goal-conditioned RGBD encoder to capture the discrepancy between the current state and the goal state. In addition, a pose-guided residual gated fusion method is proposed, which takes pose features as the backbone, and the RGBD features selectively compensate for pose feature deficiencies through an adaptive gating mechanism. Our methods are evaluated on 6 robotic precise insertion tasks, demonstrating competitive performance with only 7-10 demonstrations. Experiments demonstrate that the proposed methods can successfully complete precision insertion tasks with a clearance of about 0.01 mm. Experimental results highlight its superior efficiency and generalization capability compared to existing baselines. Code will be available at https://github.com/sunhan1997/PoseInsert.
Grasp Stability Assessment Through Attention-Guided Cross-Modality Fusion and Transfer Learning
Aug 02, 2023Extensive research has been conducted on assessing grasp stability, a crucial prerequisite for achieving optimal grasping strategies, including the minimum force grasping policy. However, existing works employ basic feature-level fusion techniques to combine visual and tactile modalities, resulting in the inadequate utilization of complementary information and the inability to model interactions between unimodal features. This work proposes an attention-guided cross-modality fusion architecture to comprehensively integrate visual and tactile features. This model mainly comprises convolutional neural networks (CNNs), self-attention, and cross-attention mechanisms. In addition, most existing methods collect datasets from real-world systems, which is time-consuming and high-cost, and the datasets collected are comparatively limited in size. This work establishes a robotic grasping system through physics simulation to collect a multimodal dataset. To address the sim-to-real transfer gap, we propose a migration strategy encompassing domain randomization and domain adaptation techniques. The experimental results demonstrate that the proposed fusion framework achieves markedly enhanced prediction performance (approximately 10%) compared to other baselines. Moreover, our findings suggest that the trained model can be reliably transferred to real robotic systems, indicating its potential to address real-world challenges.
PointNet++ Grasping: Learning An End-to-end Spatial Grasp Generation Algorithm from Sparse Point Clouds
Mar 21, 2020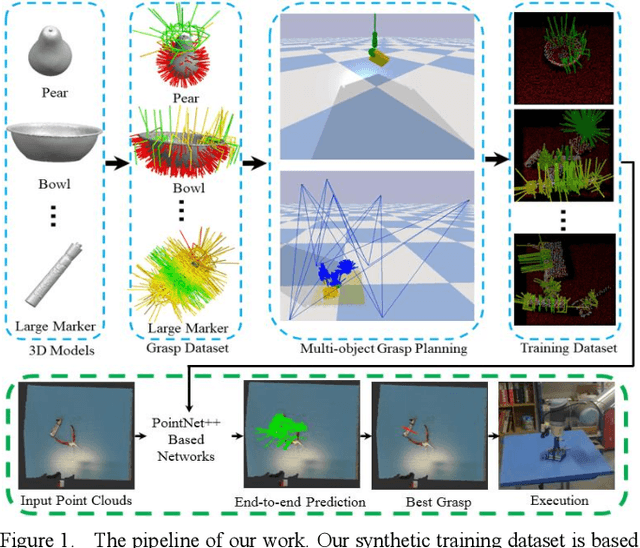
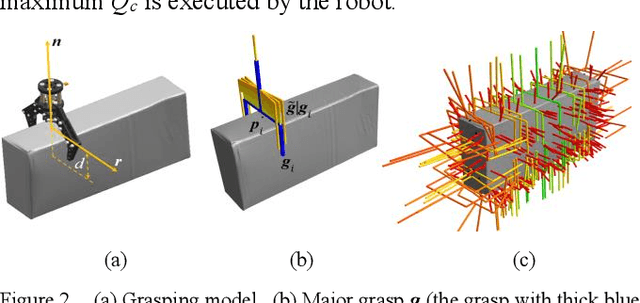
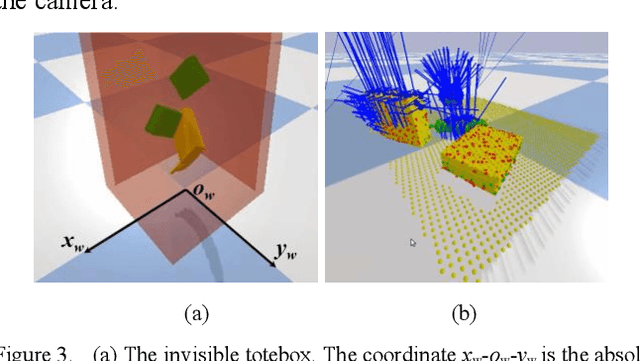
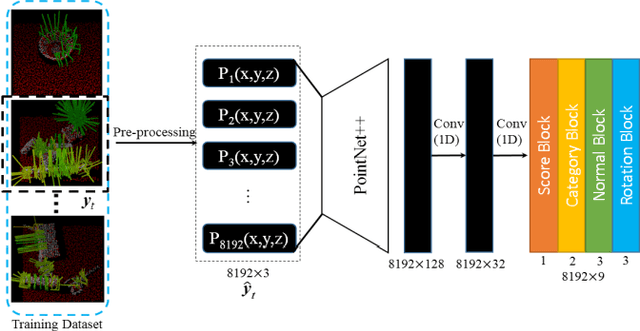
Grasping for novel objects is important for robot manipulation in unstructured environments. Most of current works require a grasp sampling process to obtain grasp candidates, combined with local feature extractor using deep learning. This pipeline is time-costly, expecially when grasp points are sparse such as at the edge of a bowl. In this paper, we propose an end-to-end approach to directly predict the poses, categories and scores (qualities) of all the grasps. It takes the whole sparse point clouds as the input and requires no sampling or search process. Moreover, to generate training data of multi-object scene, we propose a fast multi-object grasp detection algorithm based on Ferrari Canny metrics. A single-object dataset (79 objects from YCB object set, 23.7k grasps) and a multi-object dataset (20k point clouds with annotations and masks) are generated. A PointNet++ based network combined with multi-mask loss is introduced to deal with different training points. The whole weight size of our network is only about 11.6M, which takes about 102ms for a whole prediction process using a GeForce 840M GPU. Our experiment shows our work get 71.43% success rate and 91.60% completion rate, which performs better than current state-of-art works.