 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SPPNet: A Single-Point Prompt Network for Nuclei Image Segmentation
Aug 23, 2023
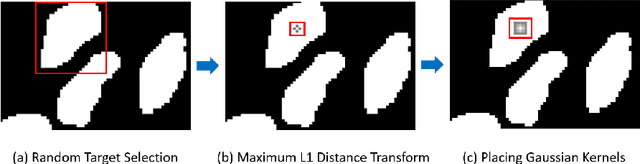
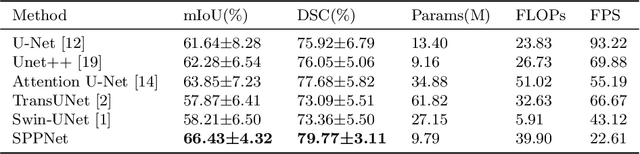
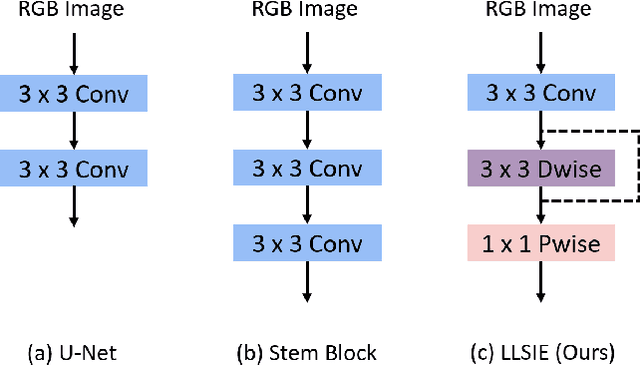
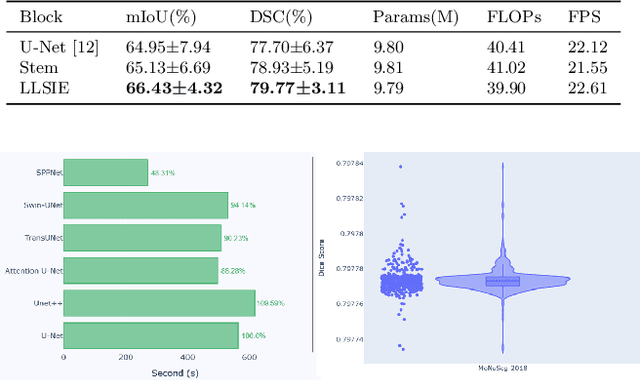
Image segmentation plays an essential role in nuclei image analysis. Recently, the segment anything model has made a significant breakthrough in such tasks. However, the current model exists two major issues for cell segmentation: (1) the image encoder of the segment anything model involves a large number of parameters. Retraining or even fine-tuning the model still requires expensive computational resources. (2) in point prompt mode, points are sampled from the center of the ground truth and more than one set of points is expected to achieve reliable performance, which is not efficient for practical applications. In this paper, a single-point prompt network is proposed for nuclei image segmentation, called SPPNet. We replace the original image encoder with a lightweight vision transformer. Also, an effective convolutional block is added in parallel to extract the low-level semantic information from the image and compensate for the performance degradation due to the small image encoder. We propose a new point-sampling method based on the Gaussian kernel. The proposed model is evaluated on the MoNuSeg-2018 dataset. The result demonstrated that SPPNet outperforms existing U-shape architectures and shows faster convergence in training. Compared to the segment anything model, SPPNet shows roughly 20 times faster inference, with 1/70 parameters and computational cost. Particularly, only one set of points is required in both the training and inference phases, which is more reasonable for clinical applications. The code for our work and more technical details can be found at https://github.com/xq141839/SPPNet.
DPMAC: Differentially Private Communication for Cooperative Multi-Agent Reinforcement Learning
Aug 19, 2023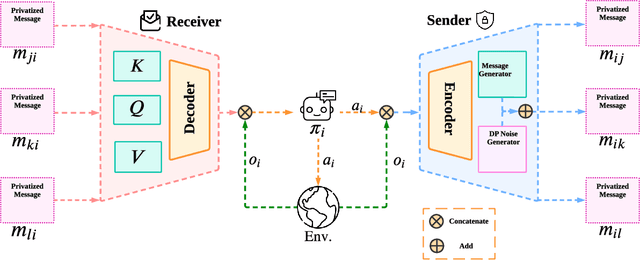
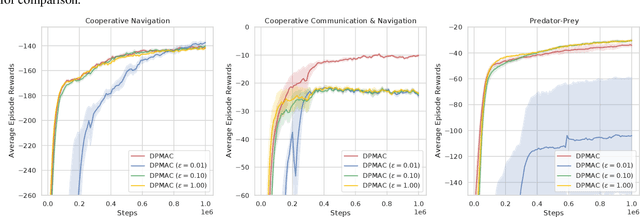
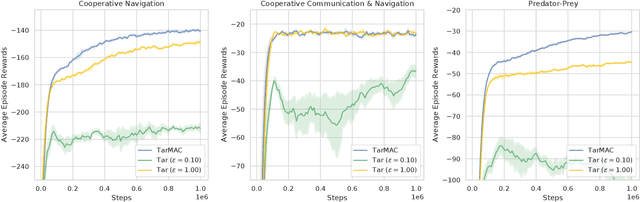
Communication lays the foundation for cooperation in human society and in multi-agent reinforcement learning (MARL). Humans also desire to maintain their privacy when communicating with others, yet such privacy concern has not been considered in existing works in MARL. To this end, we propose the \textit{differentially private multi-agent communication} (DPMAC) algorithm, which protects the sensitive information of individual agents by equipping each agent with a local message sender with rigorous $(\epsilon, \delta)$-differential privacy (DP) guarantee. In contrast to directly perturbing the messages with predefined DP noise as commonly done in privacy-preserving scenarios, we adopt a stochastic message sender for each agent respectively and incorporate the DP requirement into the sender, which automatically adjusts the learned message distribution to alleviate the instability caused by DP noise. Further, we prove the existence of a Nash equilibrium in cooperative MARL with privacy-preserving communication, which suggests that this problem is game-theoretically learnable. Extensive experiments demonstrate a clear advantage of DPMAC over baseline methods in privacy-preserving scenarios.
Breast Lesion Diagnosis Using Static Images and Dynamic Video
Aug 19, 2023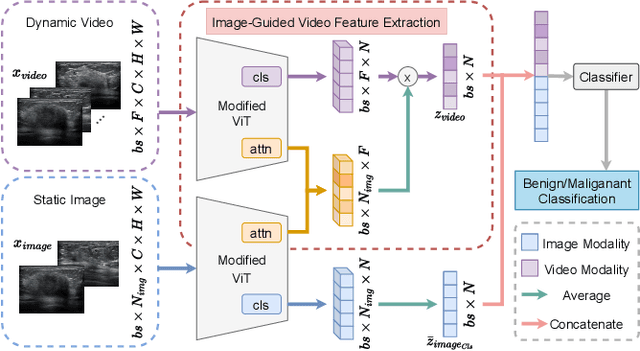
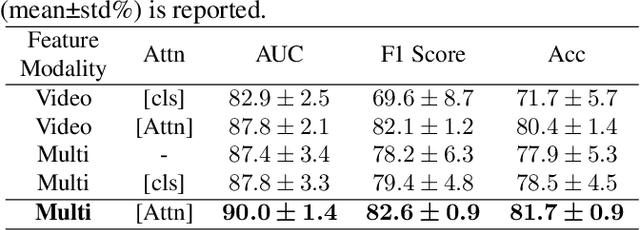
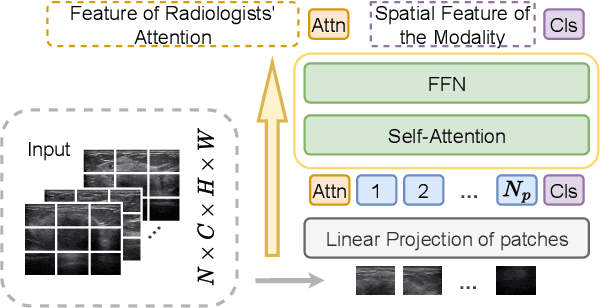
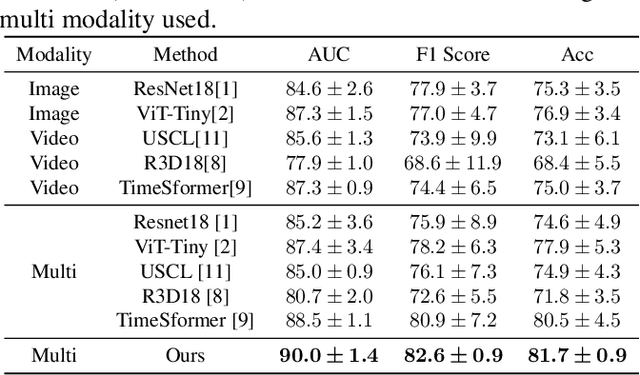
Deep learning based Computer Aided Diagnosis (CAD) systems have been developed to treat breast ultrasound. Most of them focus on a single ultrasound imaging modality, either using representative static images or the dynamic video of a real-time scan. In fact, these two image modalities are complementary for lesion diagnosis. Dynamic videos provide detailed three-dimensional information about the lesion, while static images capture the typical sections of the lesion. In this work, we propose a multi-modality breast tumor diagnosis model to imitate the diagnosing process of radiologists, which learns the features of both static images and dynamic video and explores the potential relationship between the two modalities. Considering that static images are carefully selected by professional radiologists, we propose to aggregate dynamic video features under the guidance of domain knowledge from static images before fusing multi-modality features. Our work is validated on a breast ultrasound dataset composed of 897 sets of ultrasound images and videos. Experimental results show that our model boosts the performance of Benign/Malignant classification, achieving 90.0% in AUC and 81.7% in accuracy.
Modeling Random Networks with Heterogeneous Reciprocity
Aug 19, 2023Reciprocity, or the tendency of individuals to mirror behavior, is a key measure that describes information exchange in a social network. Users in social networks tend to engage in different levels of reciprocal behavior. Differences in such behavior may indicate the existence of communities that reciprocate links at varying rates. In this paper, we develop methodology to model the diverse reciprocal behavior in growing social networks. In particular, we present a preferential attachment model with heterogeneous reciprocity that imitates the attraction users have for popular users, plus the heterogeneous nature by which they reciprocate links. We compare Bayesian and frequentist model fitting techniques for large networks, as well as computationally efficient variational alternatives. Cases where the number of communities are known and unknown are both considered. We apply the presented methods to the analysis of a Facebook wallpost network where users have non-uniform reciprocal behavior patterns. The fitted model captures the heavy-tailed nature of the empirical degree distributions in the Facebook data and identifies multiple groups of users that differ in their tendency to reply to and receive responses to wallposts.
Scaling Clinical Trial Matching Using Large Language Models: A Case Study in Oncology
Aug 18, 2023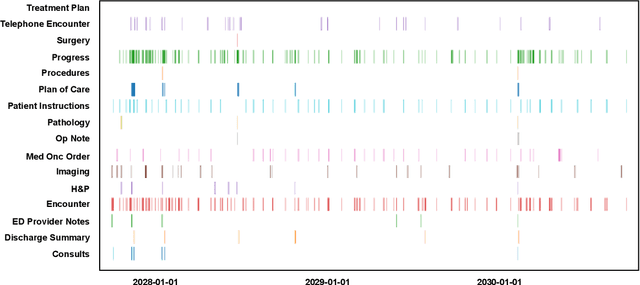
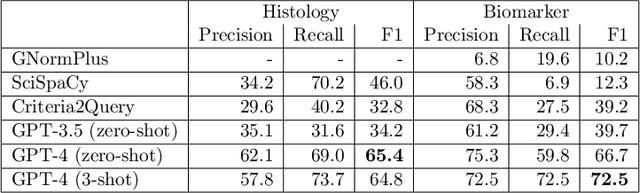
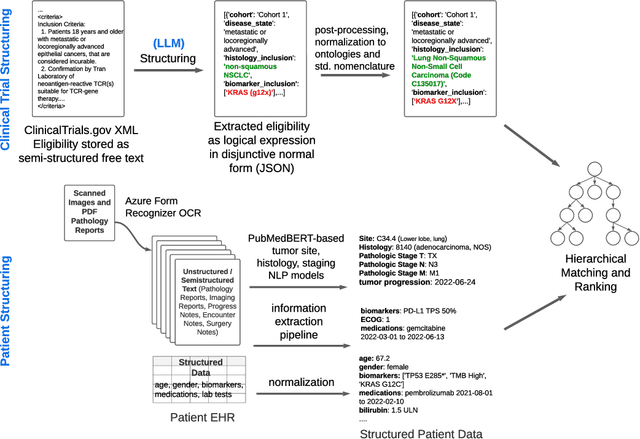

Clinical trial matching is a key process in health delivery and discovery. In practice, it is plagued by overwhelming unstructured data and unscalable manual processing. In this paper, we conduct a systematic study on scaling clinical trial matching using large language models (LLMs), with oncology as the focus area. Our study is grounded in a clinical trial matching system currently in test deployment at a large U.S. health network. Initial findings are promising: out of box, cutting-edge LLMs, such as GPT-4, can already structure elaborate eligibility criteria of clinical trials and extract complex matching logic (e.g., nested AND/OR/NOT). While still far from perfect, LLMs substantially outperform prior strong baselines and may serve as a preliminary solution to help triage patient-trial candidates with humans in the loop. Our study also reveals a few significant growth areas for applying LLMs to end-to-end clinical trial matching, such as context limitation and accuracy, especially in structuring patient information from longitudinal medical records.
Joint Beamforming and Antenna Movement Design for Moveable Antenna Systems Based on Statistical CSI
Aug 18, 2023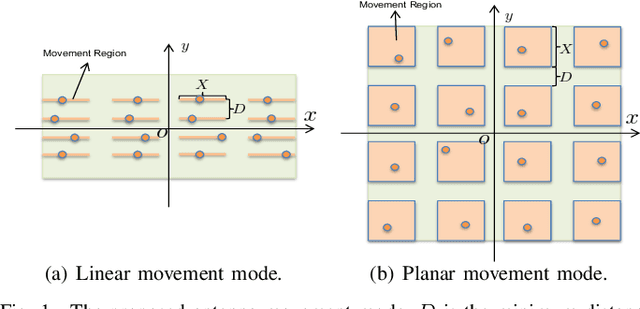
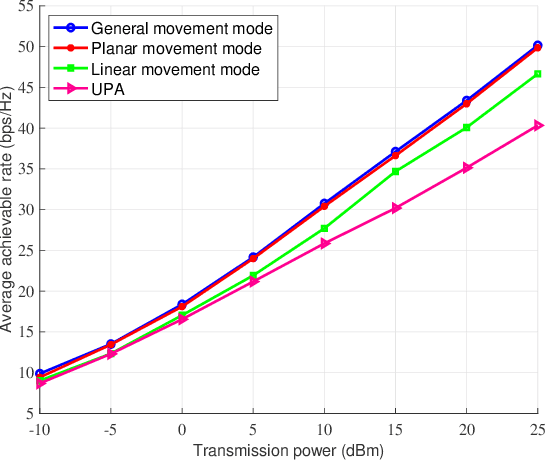
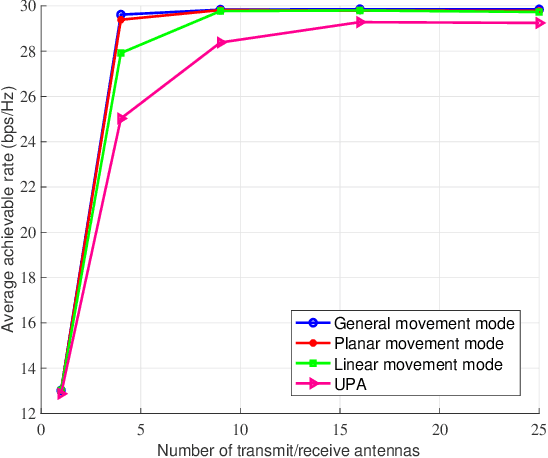
This paper studies a novel movable antenna (MA)-enhanced multiple-input multiple-output (MIMO) system to leverage the corresponding spatial degrees of freedom (DoFs) for improving the performance of wireless communications. We aim to maximize the achievable rate by jointly optimizing the MA positions and the transmit covariance matrix based on statistical channel state information (CSI). To solve the resulting design problem, we develop a constrained stochastic successive convex approximation (CSSCA) algorithm applicable for the general movement mode. Furthermore, we propose two simplified antenna movement modes, namely the linear movement mode and the planar movement mode, to facilitate efficient antenna movement and reduce the computational complexity of the CSSCA algorithm. Numerical results show that the considered MA-enhanced system can significantly improve the achievable rate compared to conventional MIMO systems employing uniform planar arrays (UPAs) and that the proposed planar movement mode performs closely to the performance upper bound achieved by the general movement mode.
WIKITIDE: A Wikipedia-Based Timestamped Definition Pairs Dataset
Aug 18, 2023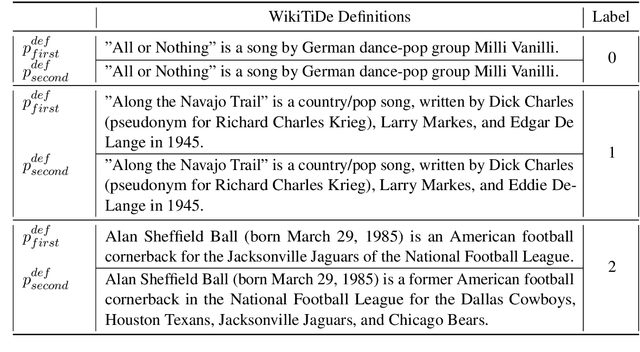
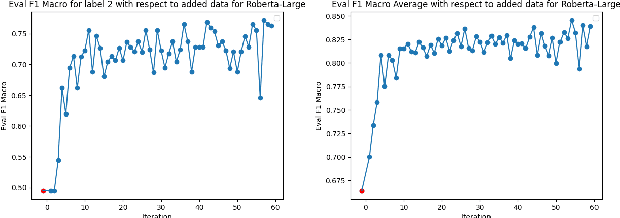
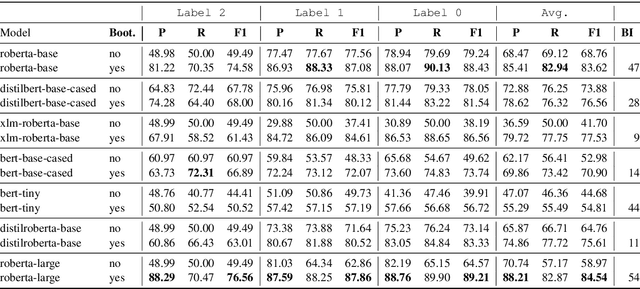
A fundamental challenge in the current NLP context, dominated by language models, comes from the inflexibility of current architectures to 'learn' new information. While model-centric solutions like continual learning or parameter-efficient fine tuning are available, the question still remains of how to reliably identify changes in language or in the world. In this paper, we propose WikiTiDe, a dataset derived from pairs of timestamped definitions extracted from Wikipedia. We argue that such resource can be helpful for accelerating diachronic NLP, specifically, for training models able to scan knowledge resources for core updates concerning a concept, an event, or a named entity. Our proposed end-to-end method is fully automatic, and leverages a bootstrapping algorithm for gradually creating a high-quality dataset. Our results suggest that bootstrapping the seed version of WikiTiDe leads to better fine-tuned models. We also leverage fine-tuned models in a number of downstream tasks, showing promising results with respect to competitive baselines.
StableVideo: Text-driven Consistency-aware Diffusion Video Editing
Aug 18, 2023
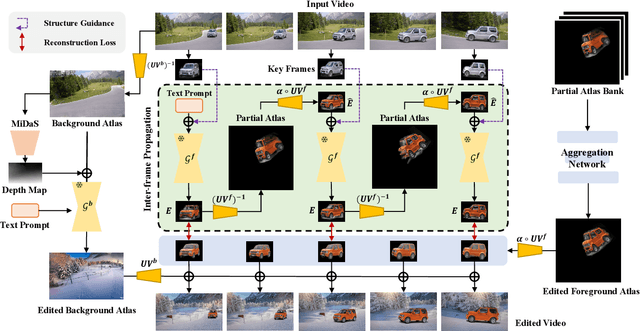
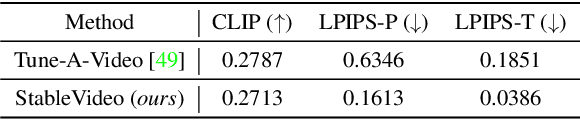
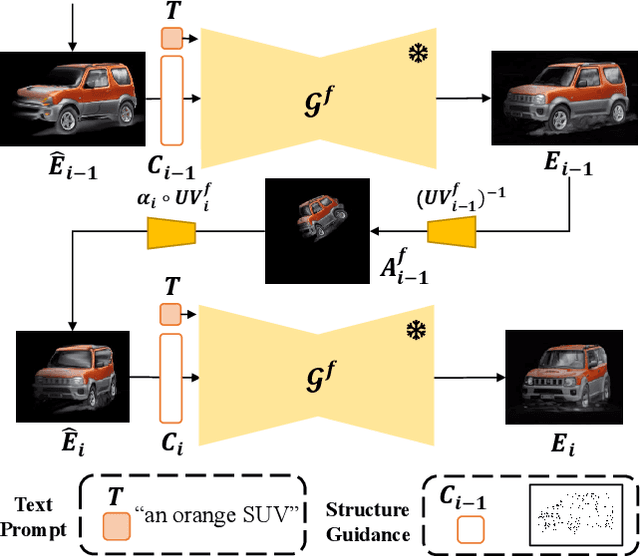
Diffusion-based methods can generate realistic images and videos, but they struggle to edit existing objects in a video while preserving their appearance over time. This prevents diffusion models from being applied to natural video editing in practical scenarios. In this paper, we tackle this problem by introducing temporal dependency to existing text-driven diffusion models, which allows them to generate consistent appearance for the edited objects. Specifically, we develop a novel inter-frame propagation mechanism for diffusion video editing, which leverages the concept of layered representations to propagate the appearance information from one frame to the next. We then build up a text-driven video editing framework based on this mechanism, namely StableVideo, which can achieve consistency-aware video editing. Extensive experiments demonstrate the strong editing capability of our approach. Compared with state-of-the-art video editing methods, our approach shows superior qualitative and quantitative results. Our code is available at \href{https://github.com/rese1f/StableVideo}{this https URL}.
Vision Relation Transformer for Unbiased Scene Graph Generation
Aug 18, 2023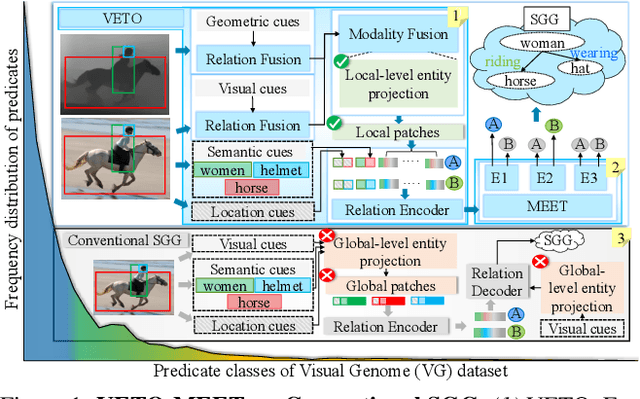
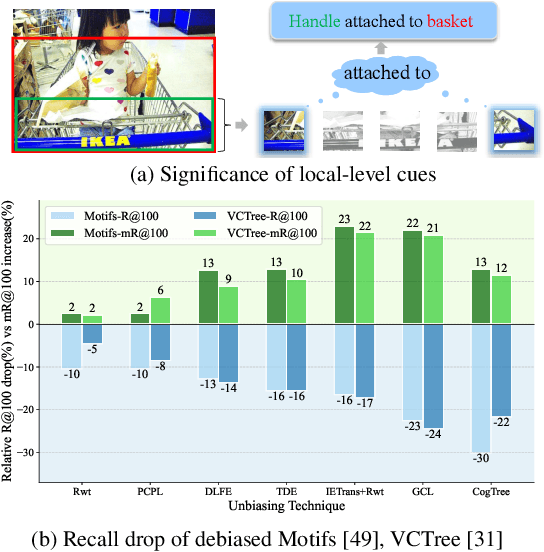
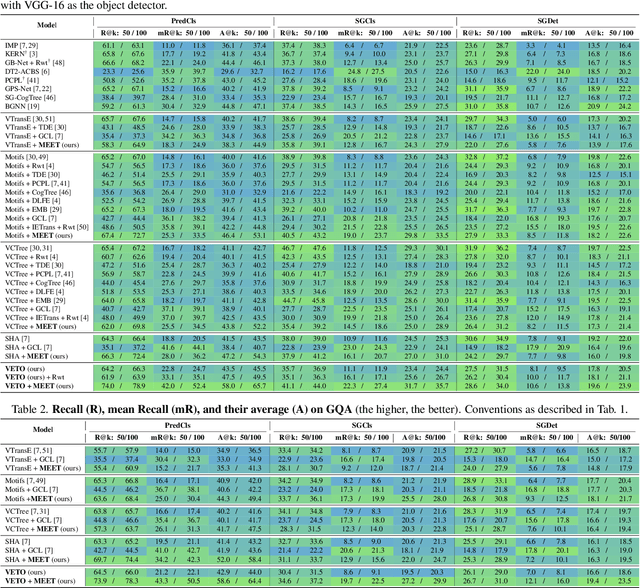
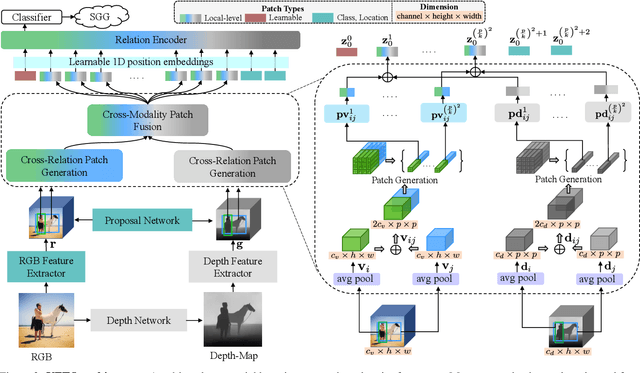
Recent years have seen a growing interest in Scene Graph Generation (SGG), a comprehensive visual scene understanding task that aims to predict entity relationships using a relation encoder-decoder pipeline stacked on top of an object encoder-decoder backbone. Unfortunately, current SGG methods suffer from an information loss regarding the entities local-level cues during the relation encoding process. To mitigate this, we introduce the Vision rElation TransfOrmer (VETO), consisting of a novel local-level entity relation encoder. We further observe that many existing SGG methods claim to be unbiased, but are still biased towards either head or tail classes. To overcome this bias, we introduce a Mutually Exclusive ExperT (MEET) learning strategy that captures important relation features without bias towards head or tail classes. Experimental results on the VG and GQA datasets demonstrate that VETO + MEET boosts the predictive performance by up to 47 percentage over the state of the art while being 10 times smaller.
Defending Label Inference Attacks in Split Learning under Regression Setting
Aug 18, 2023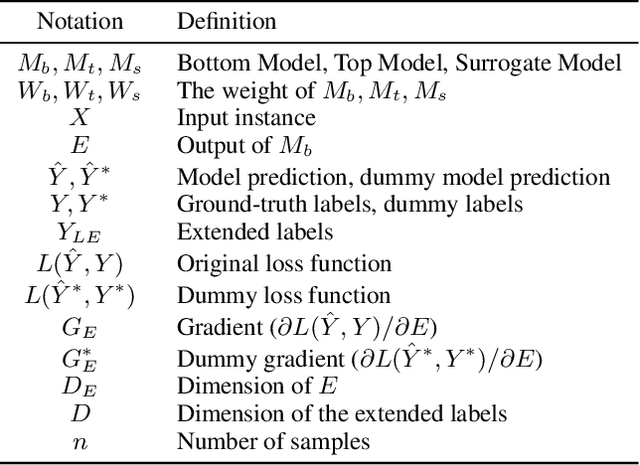
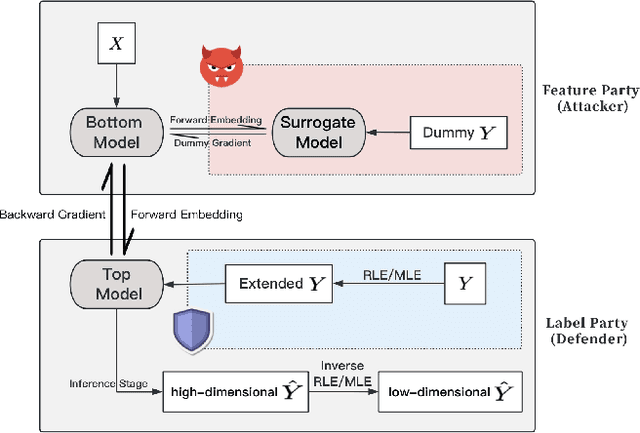
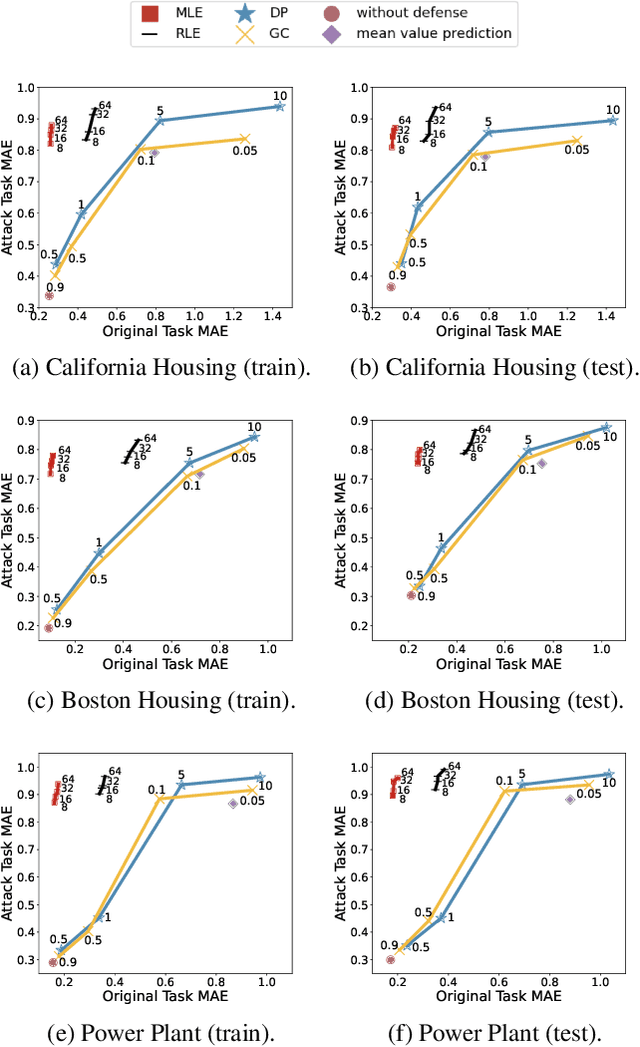
As a privacy-preserving method for implementing Vertical Federated Learning, Split Learning has been extensively researched. However, numerous studies have indicated that the privacy-preserving capability of Split Learning is insufficient. In this paper, we primarily focus on label inference attacks in Split Learning under regression setting, which are mainly implemented through the gradient inversion method. To defend against label inference attacks, we propose Random Label Extension (RLE), where labels are extended to obfuscate the label information contained in the gradients, thereby preventing the attacker from utilizing gradients to train an attack model that can infer the original labels. To further minimize the impact on the original task, we propose Model-based adaptive Label Extension (MLE), where original labels are preserved in the extended labels and dominate the training process. The experimental results show that compared to the basic defense methods, our proposed defense methods can significantly reduce the attack model's performance while preserving the original task's performance.