 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Aggregating Local and Global Features via Selective State Spaces Model for Efficient Image Deblurring
Mar 29, 2024
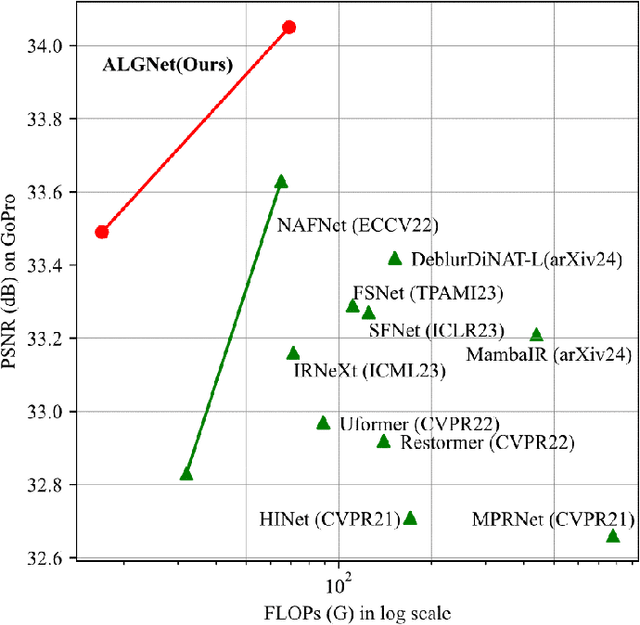
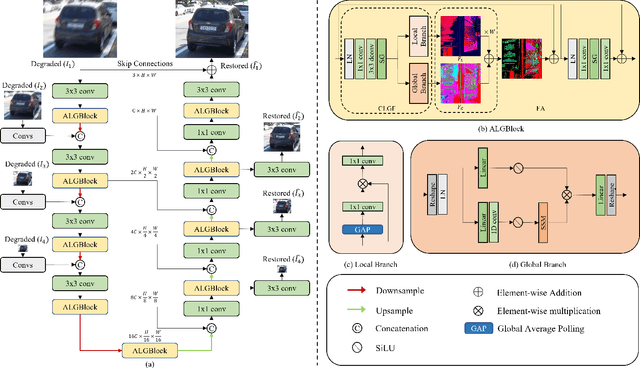

Image deblurring is a process of restoring a high quality image from the corresponding blurred image. Significant progress in this field has been made possible by the emergence of various effective deep learning models, including CNNs and Transformers. However, these methods often face the dilemma between eliminating long-range blur degradation perturbations and maintaining computational efficiency, which hinders their practical application. To address this issue, we propose an efficient image deblurring network that leverages selective structured state spaces model to aggregate enriched and accurate features. Specifically, we design an aggregate local and global block (ALGBlock) to capture and fuse both local invariant properties and non-local information. The ALGBlock consists of two blocks: (1) The local block models local connectivity using simplified channel attention. (2) The global block captures long-range dependency features with linear complexity through selective structured state spaces. Nevertheless, we note that the image details are local features of images, we accentuate the local part for restoration by recalibrating the weight when aggregating the two branches for recovery. Experimental results demonstrate that the proposed method outperforms state-of-the-art approaches on widely used benchmarks, highlighting its superior performance.
Binarized Low-light Raw Video Enhancement
Mar 29, 2024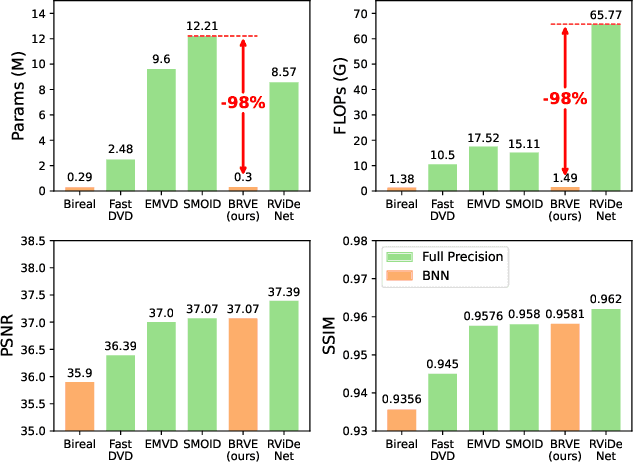
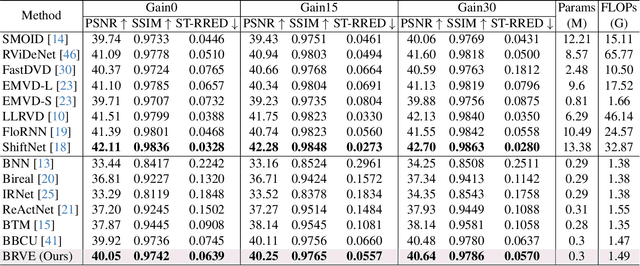
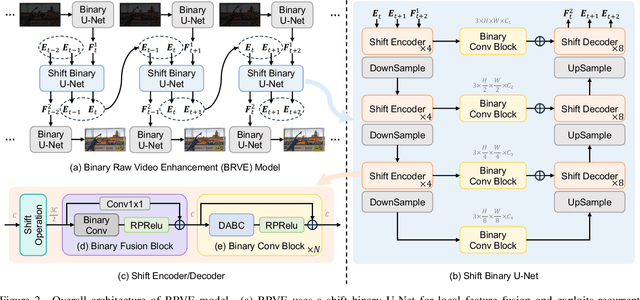
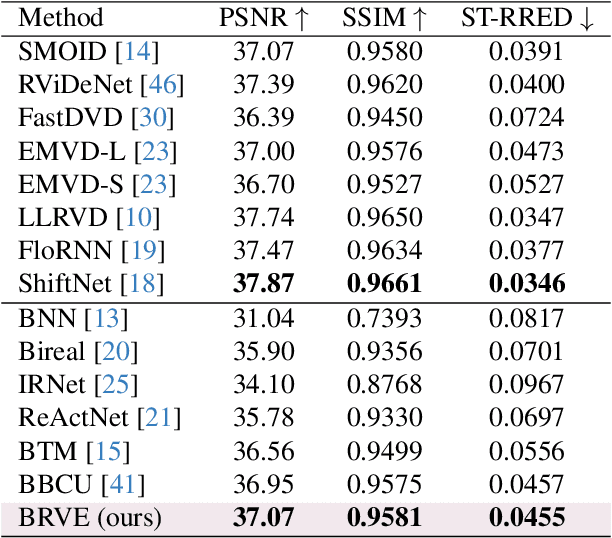
Recently, deep neural networks have achieved excellent performance on low-light raw video enhancement. However, they often come with high computational complexity and large memory costs, which hinder their applications on resource-limited devices. In this paper, we explore the feasibility of applying the extremely compact binary neural network (BNN) to low-light raw video enhancement. Nevertheless, there are two main issues with binarizing video enhancement models. One is how to fuse the temporal information to improve low-light denoising without complex modules. The other is how to narrow the performance gap between binary convolutions with the full precision ones. To address the first issue, we introduce a spatial-temporal shift operation, which is easy-to-binarize and effective. The temporal shift efficiently aggregates the features of neighbor frames and the spatial shift handles the misalignment caused by the large motion in videos. For the second issue, we present a distribution-aware binary convolution, which captures the distribution characteristics of real-valued input and incorporates them into plain binary convolutions to alleviate the degradation in performance. Extensive quantitative and qualitative experiments have shown our high-efficiency binarized low-light raw video enhancement method can attain a promising performance.
Context-Aware Integration of Language and Visual References for Natural Language Tracking
Mar 29, 2024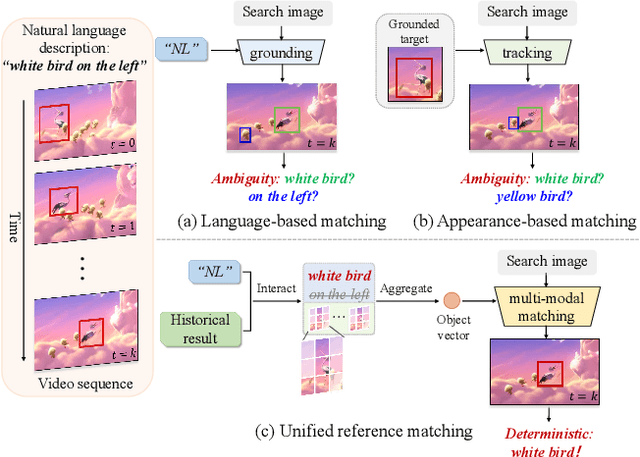

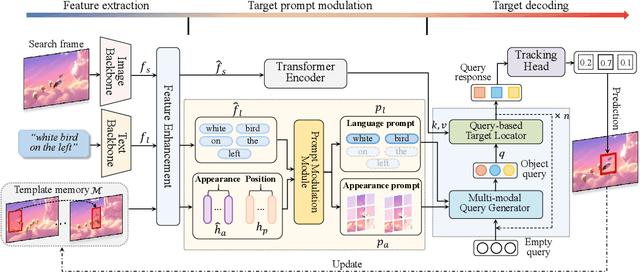
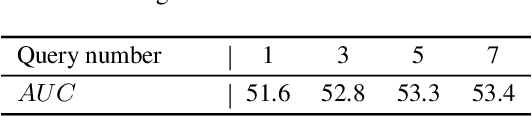
Tracking by natural language specification (TNL) aims to consistently localize a target in a video sequence given a linguistic description in the initial frame. Existing methodologies perform language-based and template-based matching for target reasoning separately and merge the matching results from two sources, which suffer from tracking drift when language and visual templates miss-align with the dynamic target state and ambiguity in the later merging stage. To tackle the issues, we propose a joint multi-modal tracking framework with 1) a prompt modulation module to leverage the complementarity between temporal visual templates and language expressions, enabling precise and context-aware appearance and linguistic cues, and 2) a unified target decoding module to integrate the multi-modal reference cues and executes the integrated queries on the search image to predict the target location in an end-to-end manner directly. This design ensures spatio-temporal consistency by leveraging historical visual information and introduces an integrated solution, generating predictions in a single step. Extensive experiments conducted on TNL2K, OTB-Lang, LaSOT, and RefCOCOg validate the efficacy of our proposed approach. The results demonstrate competitive performance against state-of-the-art methods for both tracking and grounding.
On Large Language Models' Hallucination with Regard to Known Facts
Mar 29, 2024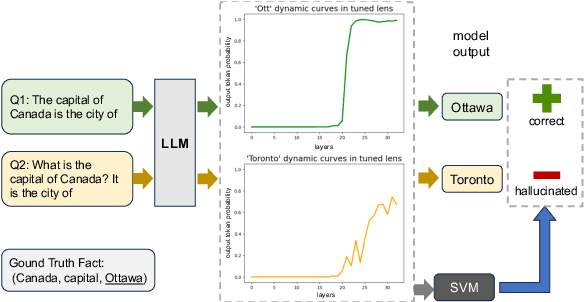
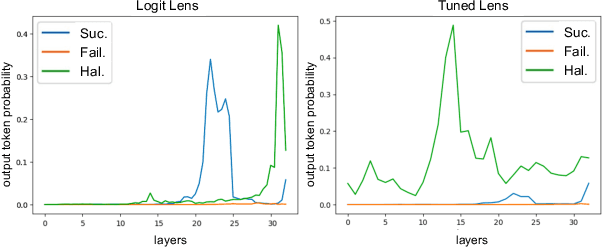
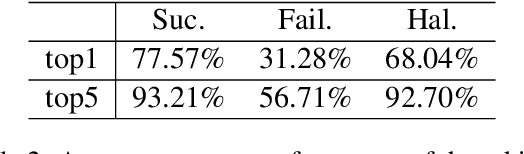
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88\% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
Spectral Convolutional Transformer: Harmonizing Real vs. Complex Multi-View Spectral Operators for Vision Transformer
Mar 26, 2024Transformers used in vision have been investigated through diverse architectures - ViT, PVT, and Swin. These have worked to improve the attention mechanism and make it more efficient. Differently, the need for including local information was felt, leading to incorporating convolutions in transformers such as CPVT and CvT. Global information is captured using a complex Fourier basis to achieve global token mixing through various methods, such as AFNO, GFNet, and Spectformer. We advocate combining three diverse views of data - local, global, and long-range dependence. We also investigate the simplest global representation using only the real domain spectral representation - obtained through the Hartley transform. We use a convolutional operator in the initial layers to capture local information. Through these two contributions, we are able to optimize and obtain a spectral convolution transformer (SCT) that provides improved performance over the state-of-the-art methods while reducing the number of parameters. Through extensive experiments, we show that SCT-C-small gives state-of-the-art performance on the ImageNet dataset and reaches 84.5\% top-1 accuracy, while SCT-C-Large reaches 85.9\% and SCT-C-Huge reaches 86.4\%. We evaluate SCT on transfer learning on datasets such as CIFAR-10, CIFAR-100, Oxford Flower, and Stanford Car. We also evaluate SCT on downstream tasks i.e. instance segmentation on the MSCOCO dataset. The project page is available on this webpage.\url{https://github.com/badripatro/sct}
Learning from Reduced Labels for Long-Tailed Data
Mar 25, 2024Long-tailed data is prevalent in real-world classification tasks and heavily relies on supervised information, which makes the annotation process exceptionally labor-intensive and time-consuming. Unfortunately, despite being a common approach to mitigate labeling costs, existing weakly supervised learning methods struggle to adequately preserve supervised information for tail samples, resulting in a decline in accuracy for the tail classes. To alleviate this problem, we introduce a novel weakly supervised labeling setting called Reduced Label. The proposed labeling setting not only avoids the decline of supervised information for the tail samples, but also decreases the labeling costs associated with long-tailed data. Additionally, we propose an straightforward and highly efficient unbiased framework with strong theoretical guarantees to learn from these Reduced Labels. Extensive experiments conducted on benchmark datasets including ImageNet validate the effectiveness of our approach, surpassing the performance of state-of-the-art weakly supervised methods.
A Study on How Attention Scores in the BERT Model are Aware of Lexical Categories in Syntactic and Semantic Tasks on the GLUE Benchmark
Mar 25, 2024This study examines whether the attention scores between tokens in the BERT model significantly vary based on lexical categories during the fine-tuning process for downstream tasks. Drawing inspiration from the notion that in human language processing, syntactic and semantic information is parsed differently, we categorize tokens in sentences according to their lexical categories and focus on changes in attention scores among these categories. Our hypothesis posits that in downstream tasks that prioritize semantic information, attention scores centered on content words are enhanced, while in cases emphasizing syntactic information, attention scores centered on function words are intensified. Through experimentation conducted on six tasks from the GLUE benchmark dataset, we substantiate our hypothesis regarding the fine-tuning process. Furthermore, our additional investigations reveal the presence of BERT layers that consistently assign more bias to specific lexical categories, irrespective of the task, highlighting the existence of task-agnostic lexical category preferences.
Image Captioning in news report scenario
Mar 26, 2024Image captioning strives to generate pertinent captions for specified images, situating itself at the crossroads of Computer Vision (CV) and Natural Language Processing (NLP). This endeavor is of paramount importance with far-reaching applications in recommendation systems, news outlets, social media, and beyond. Particularly within the realm of news reporting, captions are expected to encompass detailed information, such as the identities of celebrities captured in the images. However, much of the existing body of work primarily centers around understanding scenes and actions. In this paper, we explore the realm of image captioning specifically tailored for celebrity photographs, illustrating its broad potential for enhancing news industry practices. This exploration aims to augment automated news content generation, thereby facilitating a more nuanced dissemination of information. Our endeavor shows a broader horizon, enriching the narrative in news reporting through a more intuitive image captioning framework.
MineLand: Simulating Large-Scale Multi-Agent Interactions with Limited Multimodal Senses and Physical Needs
Mar 28, 2024Conventional multi-agent simulators often assume perfect information and limitless capabilities, hindering the ecological validity of social interactions. We propose a multi-agent Minecraft simulator, MineLand, that bridges this gap by introducing limited multimodal senses and physical needs. Our simulator supports up to 48 agents with limited visual, auditory, and environmental awareness, forcing them to actively communicate and collaborate to fulfill physical needs like food and resources. This fosters dynamic and valid multi-agent interactions. We further introduce an AI agent framework, Alex, inspired by multitasking theory, enabling agents to handle intricate coordination and scheduling. Our experiments demonstrate that the simulator, the corresponding benchmark, and the AI agent framework contribute to more ecological and nuanced collective behavior. The source code of MineLand and Alex is openly available at https://github.com/cocacola-lab/MineLand.
SGDM: Static-Guided Dynamic Module Make Stronger Visual Models
Mar 27, 2024The spatial attention mechanism has been widely used to improve object detection performance. However, its operation is currently limited to static convolutions lacking content-adaptive features. This paper innovatively approaches from the perspective of dynamic convolution. We propose Razor Dynamic Convolution (RDConv) to address thetwo flaws in dynamic weight convolution, making it hard to implement in spatial mechanism: 1) it is computation-heavy; 2) when generating weights, spatial information is disregarded. Firstly, by using Razor Operation to generate certain features, we vastly reduce the parameters of the entire dynamic convolution operation. Secondly, we added a spatial branch inside RDConv to generate convolutional kernel parameters with richer spatial information. Embedding dynamic convolution will also bring the problem of sensitivity to high-frequency noise. We propose the Static-Guided Dynamic Module (SGDM) to address this limitation. By using SGDM, we utilize a set of asymmetric static convolution kernel parameters to guide the construction of dynamic convolution. We introduce the mechanism of shared weights in static convolution to solve the problem of dynamic convolution being sensitive to high-frequency noise. Extensive experiments illustrate that multiple different object detection backbones equipped with SGDM achieve a highly competitive boost in performance(e.g., +4% mAP with YOLOv5n on VOC and +1.7% mAP with YOLOv8n on COCO) with negligible parameter increase(i.e., +0.33M on YOLOv5n and +0.19M on YOLOv8n).