 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Perception for Humanoid Robots
Sep 27, 2023
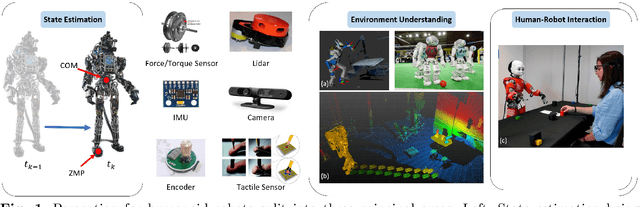
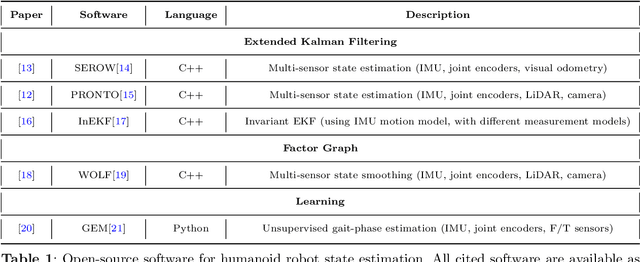

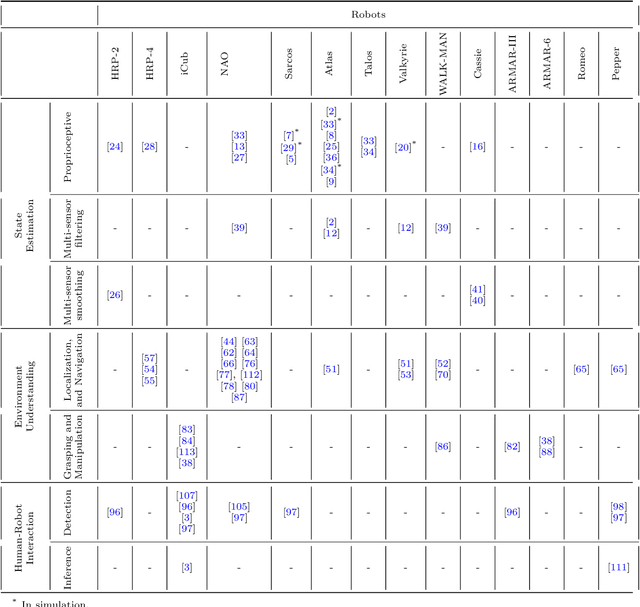
Purpose of Review: The field of humanoid robotics, perception plays a fundamental role in enabling robots to interact seamlessly with humans and their surroundings, leading to improved safety, efficiency, and user experience. This scientific study investigates various perception modalities and techniques employed in humanoid robots, including visual, auditory, and tactile sensing by exploring recent state-of-the-art approaches for perceiving and understanding the internal state, the environment, objects, and human activities. Recent Findings: Internal state estimation makes extensive use of Bayesian filtering methods and optimization techniques based on maximum a-posteriori formulation by utilizing proprioceptive sensing. In the area of external environment understanding, with an emphasis on robustness and adaptability to dynamic, unforeseen environmental changes, the new slew of research discussed in this study have focused largely on multi-sensor fusion and machine learning in contrast to the use of hand-crafted, rule-based systems. Human robot interaction methods have established the importance of contextual information representation and memory for understanding human intentions. Summary: This review summarizes the recent developments and trends in the field of perception in humanoid robots. Three main areas of application are identified, namely, internal state estimation, external environment estimation, and human robot interaction. The applications of diverse sensor modalities in each of these areas are considered and recent significant works are discussed.
Targeted Image Data Augmentation Increases Basic Skills Captioning Robustness
Sep 27, 2023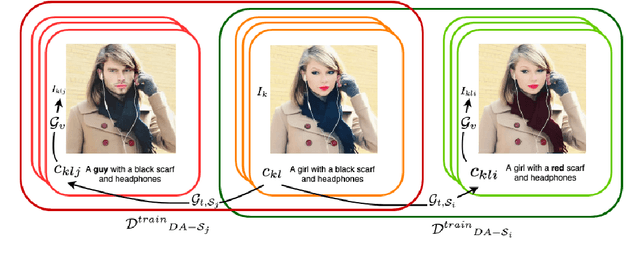
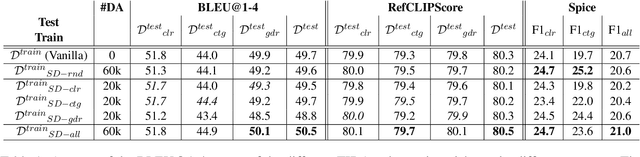
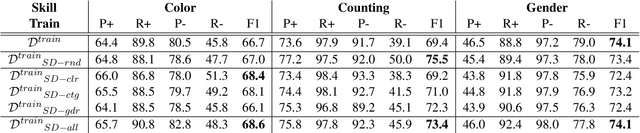
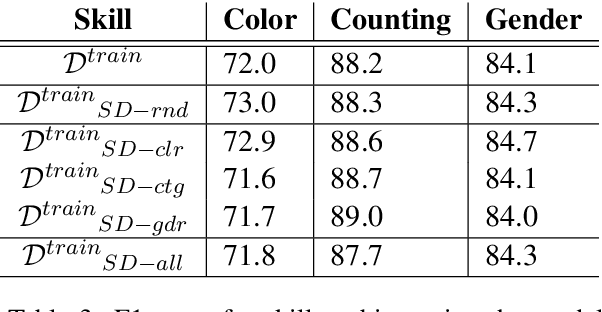
Artificial neural networks typically struggle in generalizing to out-of-context examples. One reason for this limitation is caused by having datasets that incorporate only partial information regarding the potential correlational structure of the world. In this work, we propose TIDA (Targeted Image-editing Data Augmentation), a targeted data augmentation method focused on improving models' human-like abilities (e.g., gender recognition) by filling the correlational structure gap using a text-to-image generative model. More specifically, TIDA identifies specific skills in captions describing images (e.g., the presence of a specific gender in the image), changes the caption (e.g., "woman" to "man"), and then uses a text-to-image model to edit the image in order to match the novel caption (e.g., uniquely changing a woman to a man while maintaining the context identical). Based on the Flickr30K benchmark, we show that, compared with the original data set, a TIDA-enhanced dataset related to gender, color, and counting abilities induces better performance in several image captioning metrics. Furthermore, on top of relying on the classical BLEU metric, we conduct a fine-grained analysis of the improvements of our models against the baseline in different ways. We compared text-to-image generative models and found different behaviors of the image captioning models in terms of encoding visual encoding and textual decoding.
PRIS: Practical robust invertible network for image steganography
Sep 24, 2023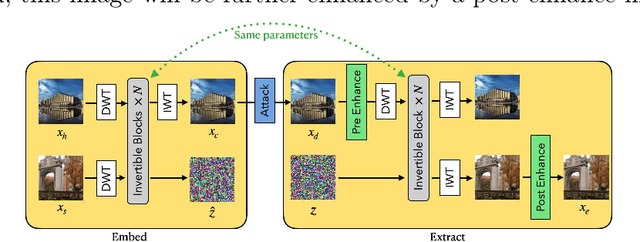
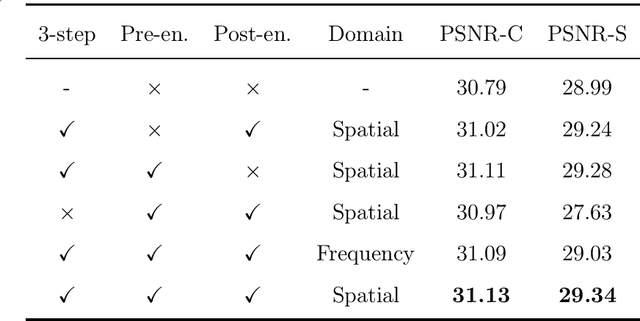
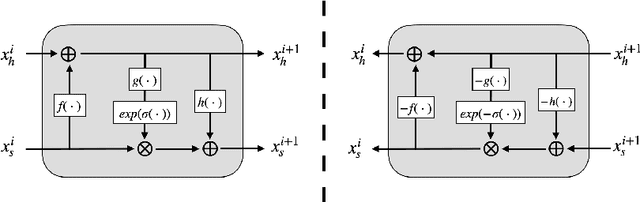
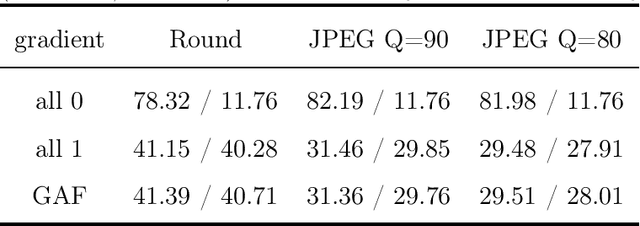
Image steganography is a technique of hiding secret information inside another image, so that the secret is not visible to human eyes and can be recovered when needed. Most of the existing image steganography methods have low hiding robustness when the container images affected by distortion. Such as Gaussian noise and lossy compression. This paper proposed PRIS to improve the robustness of image steganography, it based on invertible neural networks, and put two enhance modules before and after the extraction process with a 3-step training strategy. Moreover, rounding error is considered which is always ignored by existing methods, but actually it is unavoidable in practical. A gradient approximation function (GAF) is also proposed to overcome the undifferentiable issue of rounding distortion. Experimental results show that our PRIS outperforms the state-of-the-art robust image steganography method in both robustness and practicability. Codes are available at https://github.com/yanghangAI/PRIS, demonstration of our model in practical at http://yanghang.site/hide/.
MediViSTA-SAM: Zero-shot Medical Video Analysis with Spatio-temporal SAM Adaptation
Sep 24, 2023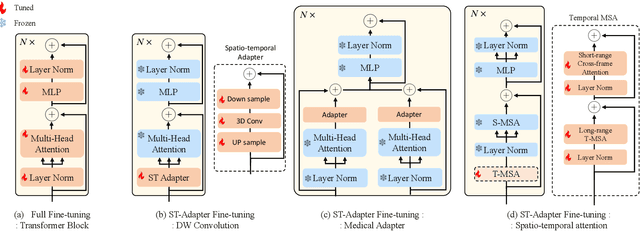
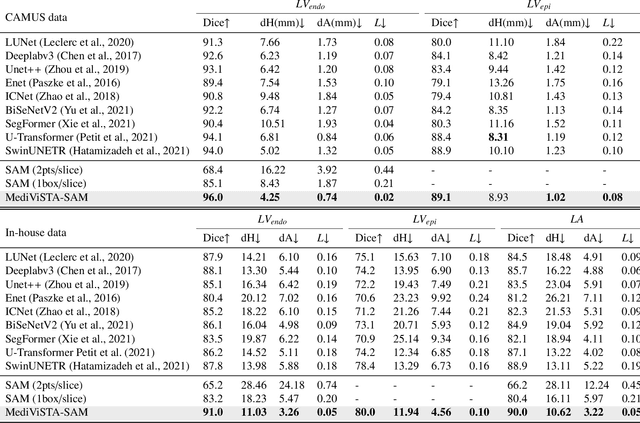
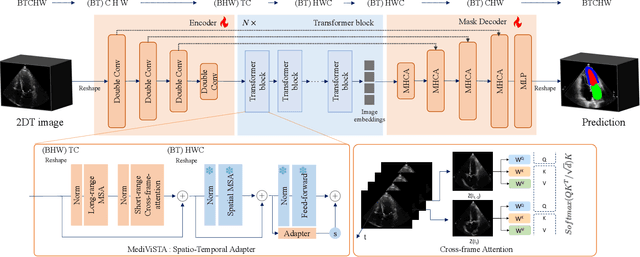
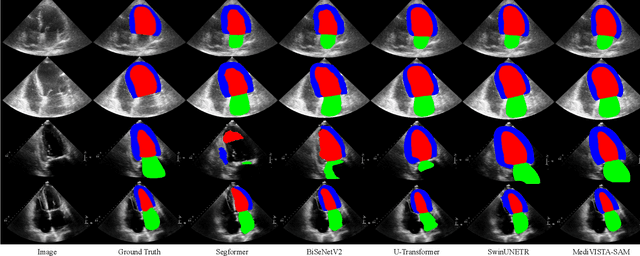
In recent years, the Segmentation Anything Model (SAM) has attracted considerable attention as a foundational model well-known for its robust generalization capabilities across various downstream tasks. However, SAM does not exhibit satisfactory performance in the realm of medical image analysis. In this study, we introduce the first study on adapting SAM on video segmentation, called MediViSTA-SAM, a novel approach designed for medical video segmentation. Given video data, MediViSTA, spatio-temporal adapter captures long and short range temporal attention with cross-frame attention mechanism effectively constraining it to consider the immediately preceding video frame as a reference, while also considering spatial information effectively. Additionally, it incorporates multi-scale fusion by employing a U-shaped encoder and a modified mask decoder to handle objects of varying sizes. To evaluate our approach, extensive experiments were conducted using state-of-the-art (SOTA) methods, assessing its generalization abilities on multi-vendor in-house echocardiography datasets. The results highlight the accuracy and effectiveness of our network in medical video segmentation.
Glancing Future for Simultaneous Machine Translation
Sep 12, 2023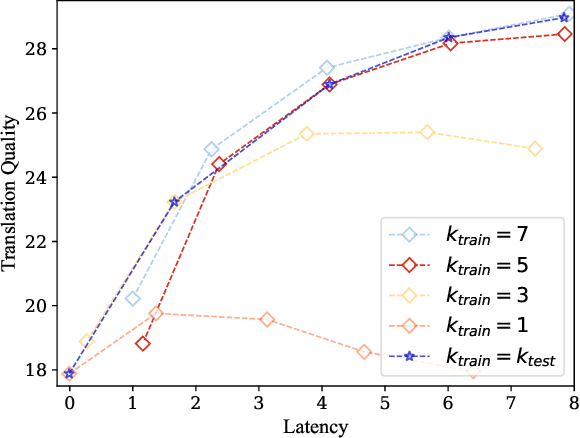

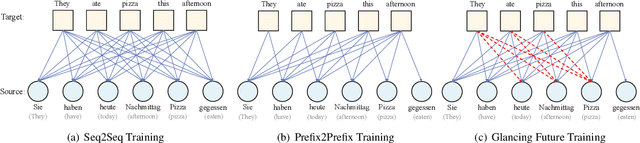

Simultaneous machine translation (SiMT) outputs translation while reading the source sentence. Unlike conventional sequence-to-sequence (seq2seq) training, existing SiMT methods adopt the prefix-to-prefix (prefix2prefix) training, where the model predicts target tokens based on partial source tokens. However, the prefix2prefix training diminishes the ability of the model to capture global information and introduces forced predictions due to the absence of essential source information. Consequently, it is crucial to bridge the gap between the prefix2prefix training and seq2seq training to enhance the translation capability of the SiMT model. In this paper, we propose a novel method that glances future in curriculum learning to achieve the transition from the seq2seq training to prefix2prefix training. Specifically, we gradually reduce the available source information from the whole sentence to the prefix corresponding to that latency. Our method is applicable to a wide range of SiMT methods and experiments demonstrate that our method outperforms strong baselines.
DCID: Deep Canonical Information Decomposition
Jun 27, 2023We consider the problem of identifying the signal shared between two one-dimensional target variables, in the presence of additional multivariate observations. Canonical Correlation Analysis (CCA)-based methods have traditionally been used to identify shared variables, however, they were designed for multivariate targets and only offer trivial solutions for univariate cases. In the context of Multi-Task Learning (MTL), various models were postulated to learn features that are sparse and shared across multiple tasks. However, these methods were typically evaluated by their predictive performance. To the best of our knowledge, no prior studies systematically evaluated models in terms of correctly recovering the shared signal. Here, we formalize the setting of univariate shared information retrieval, and propose ICM, an evaluation metric which can be used in the presence of ground-truth labels, quantifying 3 aspects of the learned shared features. We further propose Deep Canonical Information Decomposition (DCID) - a simple, yet effective approach for learning the shared variables. We benchmark the models on a range of scenarios on synthetic data with known ground-truths and observe DCID outperforming the baselines in a wide range of settings. Finally, we demonstrate a real-life application of DCID on brain Magnetic Resonance Imaging (MRI) data, where we are able to extract more accurate predictors of changes in brain regions and obesity. The code for our experiments as well as the supplementary materials are available at https://github.com/alexrakowski/dcid
Rethinking superpixel segmentation from biologically inspired mechanisms
Sep 23, 2023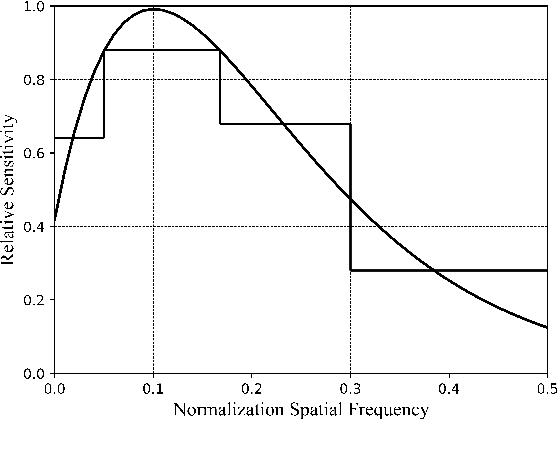
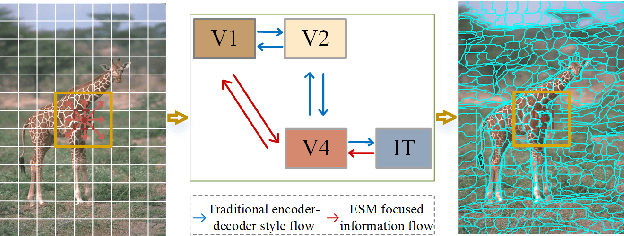
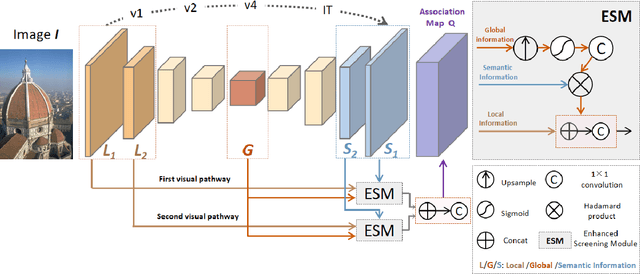
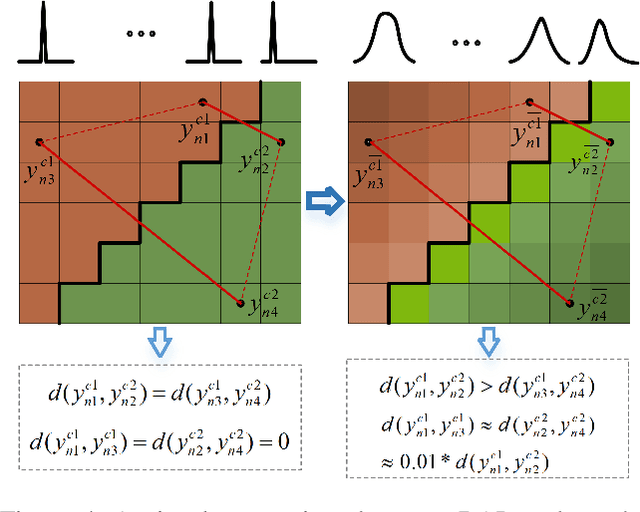
Recently, advancements in deep learning-based superpixel segmentation methods have brought about improvements in both the efficiency and the performance of segmentation. However, a significant challenge remains in generating superpixels that strictly adhere to object boundaries while conveying rich visual significance, especially when cross-surface color correlations may interfere with objects. Drawing inspiration from neural structure and visual mechanisms, we propose a biological network architecture comprising an Enhanced Screening Module (ESM) and a novel Boundary-Aware Label (BAL) for superpixel segmentation. The ESM enhances semantic information by simulating the interactive projection mechanisms of the visual cortex. Additionally, the BAL emulates the spatial frequency characteristics of visual cortical cells to facilitate the generation of superpixels with strong boundary adherence. We demonstrate the effectiveness of our approach through evaluations on both the BSDS500 dataset and the NYUv2 dataset.
Perceptual Factors for Environmental Modeling in Robotic Active Perception
Sep 19, 2023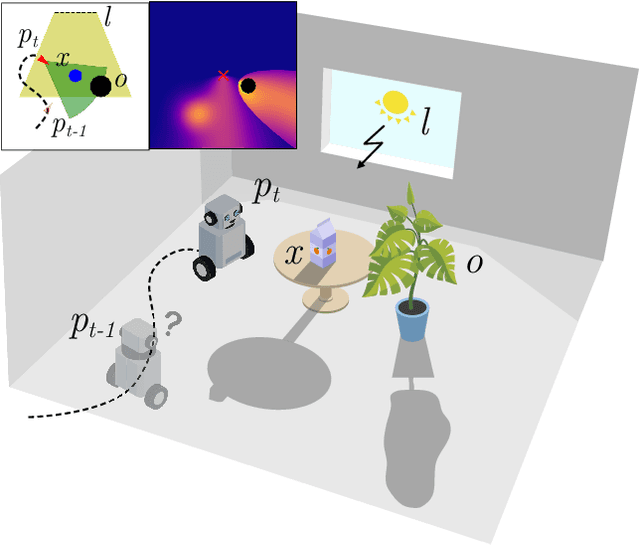
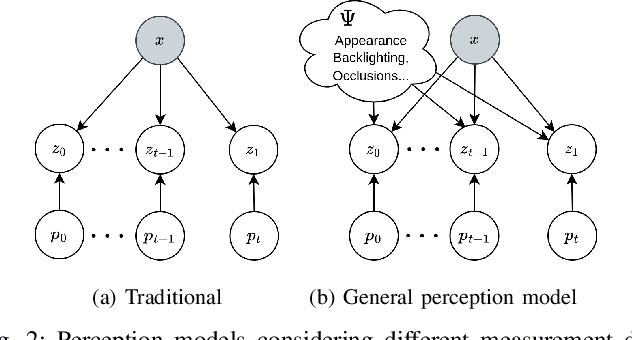
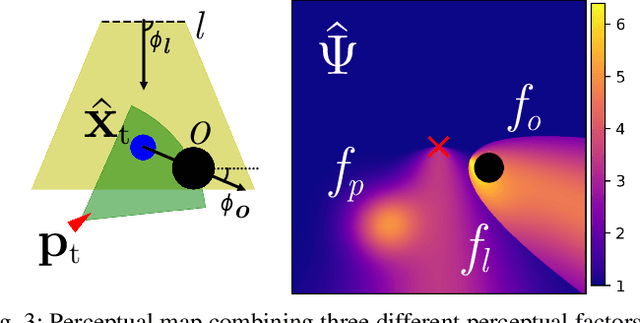
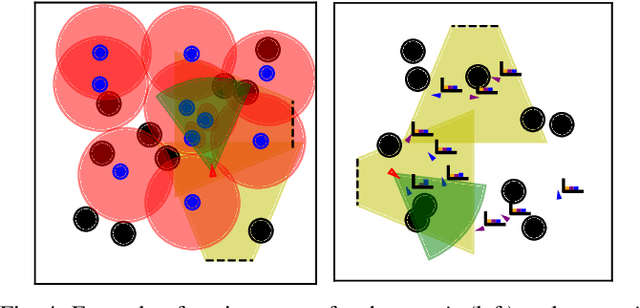
Accurately assessing the potential value of new sensor observations is a critical aspect of planning for active perception. This task is particularly challenging when reasoning about high-level scene understanding using measurements from vision-based neural networks. Due to appearance-based reasoning, the measurements are susceptible to several environmental effects such as the presence of occluders, variations in lighting conditions, and redundancy of information due to similarity in appearance between nearby viewpoints. To address this, we propose a new active perception framework incorporating an arbitrary number of perceptual effects in planning and fusion. Our method models the correlation with the environment by a set of general functions termed perceptual factors to construct a perceptual map, which quantifies the aggregated influence of the environment on candidate viewpoints. This information is seamlessly incorporated into the planning and fusion processes by adjusting the uncertainty associated with measurements to weigh their contributions. We evaluate our perceptual maps in a simulated environment that reproduces environmental conditions common in robotics applications. Our results show that, by accounting for environmental effects within our perceptual maps, we improve in the state estimation by correctly selecting the viewpoints and considering the measurement noise correctly when affected by environmental factors. We furthermore deploy our approach on a ground robot to showcase its applicability for real-world active perception missions.
FastGraphTTS: An Ultrafast Syntax-Aware Speech Synthesis Framework
Sep 16, 2023This paper integrates graph-to-sequence into an end-to-end text-to-speech framework for syntax-aware modelling with syntactic information of input text. Specifically, the input text is parsed by a dependency parsing module to form a syntactic graph. The syntactic graph is then encoded by a graph encoder to extract the syntactic hidden information, which is concatenated with phoneme embedding and input to the alignment and flow-based decoding modules to generate the raw audio waveform. The model is experimented on two languages, English and Mandarin, using single-speaker, few samples of target speakers, and multi-speaker datasets, respectively. Experimental results show better prosodic consistency performance between input text and generated audio, and also get higher scores in the subjective prosodic evaluation, and show the ability of voice conversion. Besides, the efficiency of the model is largely boosted through the design of the AI chip operator with 5x acceleration.
Ultra-low-power Image Classification on Neuromorphic Hardware
Sep 28, 2023Spiking neural networks (SNNs) promise ultra-low-power applications by exploiting temporal and spatial sparsity. The number of binary activations, called spikes, is proportional to the power consumed when executed on neuromorphic hardware. Training such SNNs using backpropagation through time for vision tasks that rely mainly on spatial features is computationally costly. Training a stateless artificial neural network (ANN) to then convert the weights to an SNN is a straightforward alternative when it comes to image recognition datasets. Most conversion methods rely on rate coding in the SNN to represent ANN activation, which uses enormous amounts of spikes and, therefore, energy to encode information. Recently, temporal conversion methods have shown promising results requiring significantly fewer spikes per neuron, but sometimes complex neuron models. We propose a temporal ANN-to-SNN conversion method, which we call Quartz, that is based on the time to first spike (TTFS). Quartz achieves high classification accuracy and can be easily implemented on neuromorphic hardware while using the least amount of synaptic operations and memory accesses. It incurs a cost of two additional synapses per neuron compared to previous temporal conversion methods, which are readily available on neuromorphic hardware. We benchmark Quartz on MNIST, CIFAR10, and ImageNet in simulation to show the benefits of our method and follow up with an implementation on Loihi, a neuromorphic chip by Intel. We provide evidence that temporal coding has advantages in terms of power consumption, throughput, and latency for similar classification accuracy. Our code and models are publicly available.