 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Global Token Mixing in Task-Dependent MRI Restoration: Insights from Minimal Gated CNN Baselines
Mar 02, 2026Global token mixing, implemented via self-attention or state-space sequence models, has become a popular model design choice for MRI restoration. However, MRI restoration tasks differ substantially in how their degradations vary over image and k-space domains, and in the degree to which global coupling is already imposed by physics-driven data consistency terms. In this work, we ask the question whether global token mixing is actually beneficial in each individual task across three representative settings: accelerated MRI reconstruction with explicit data consistency, MRI super-resolution with k-space center cropping, and denoising of clinical carotid MRI data with spatially heteroscedastic noise. To reduce confounding factors, we establish a controlled testbed comparing a minimal local gated CNN and its large-field variant, benchmarking them directly against state-of-the-art global models under aligned training and evaluation protocols. For accelerated MRI reconstruction, the minimal unrolled gated-CNN baseline is already highly competitive compared to recent token-mixing approaches in public reconstruction benchmarks, suggesting limited additional benefits when the forward model and data-consistency steps provide strong global constraints. For super-resolution, where low-frequency k-space data are largely preserved by the controlled low-pass degradation, local gated models remain competitive, and a lightweight large-field variant yields only modest improvements. In contrast, for denoising with pronounced spatially heteroscedastic noise, token-mixing models achieve the strongest overall performance, consistent with the need to estimate spatially varying reliability. In conclusion, our results demonstrate that the utility of global token mixing in MRI restoration is task-dependent, and it should be tailored to the underlying imaging physics and degradation structure.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
PolyRoom: Room-aware Transformer for Floorplan Reconstruction
Jul 15, 2024



Reconstructing geometry and topology structures from raw unstructured data has always been an important research topic in indoor mapping research. In this paper, we aim to reconstruct the floorplan with a vectorized representation from point clouds. Despite significant advancements achieved in recent years, current methods still encounter several challenges, such as missing corners or edges, inaccuracies in corner positions or angles, self-intersecting or overlapping polygons, and potentially implausible topology. To tackle these challenges, we present PolyRoom, a room-aware Transformer that leverages uniform sampling representation, room-aware query initialization, and room-aware self-attention for floorplan reconstruction. Specifically, we adopt a uniform sampling floorplan representation to enable dense supervision during training and effective utilization of angle information. Additionally, we propose a room-aware query initialization scheme to prevent non-polygonal sequences and introduce room-aware self-attention to enhance memory efficiency and model performance. Experimental results on two widely used datasets demonstrate that PolyRoom surpasses current state-of-the-art methods both quantitatively and qualitatively. Our code is available at: https://github.com/3dv-casia/PolyRoom/.
PRIS: Practical robust invertible network for image steganography
Sep 24, 2023



Image steganography is a technique of hiding secret information inside another image, so that the secret is not visible to human eyes and can be recovered when needed. Most of the existing image steganography methods have low hiding robustness when the container images affected by distortion. Such as Gaussian noise and lossy compression. This paper proposed PRIS to improve the robustness of image steganography, it based on invertible neural networks, and put two enhance modules before and after the extraction process with a 3-step training strategy. Moreover, rounding error is considered which is always ignored by existing methods, but actually it is unavoidable in practical. A gradient approximation function (GAF) is also proposed to overcome the undifferentiable issue of rounding distortion. Experimental results show that our PRIS outperforms the state-of-the-art robust image steganography method in both robustness and practicability. Codes are available at https://github.com/yanghangAI/PRIS, demonstration of our model in practical at http://yanghang.site/hide/.
Channel Pruning Guided by Spatial and Channel Attention for DNNs in Intelligent Edge Computing
Nov 08, 2020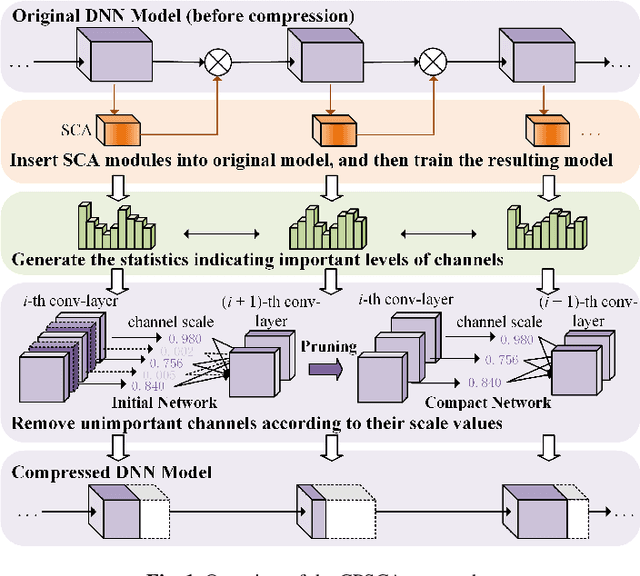
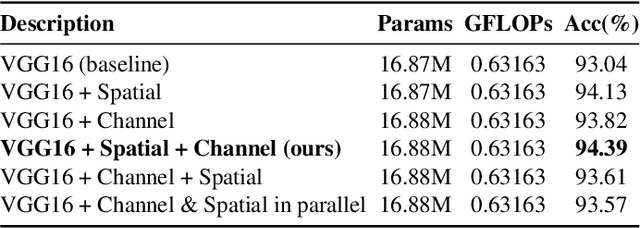
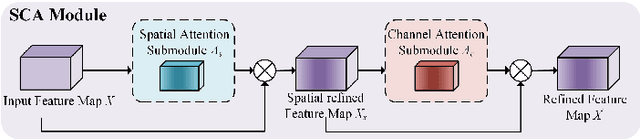
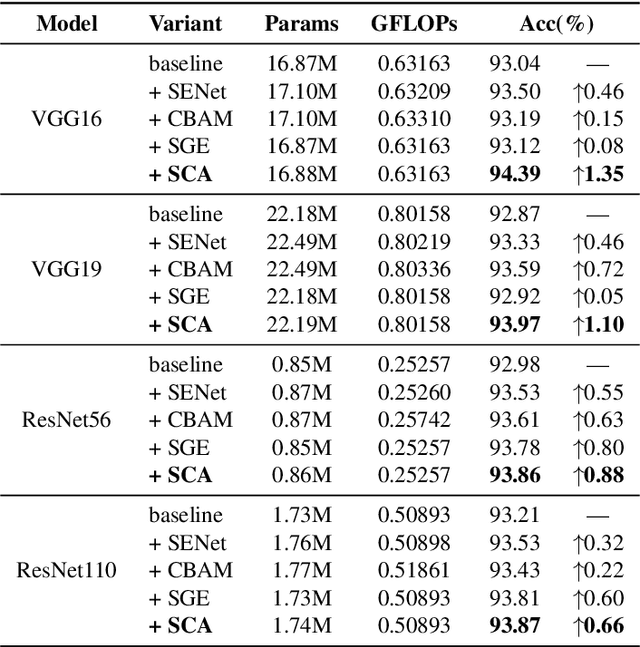
Deep Neural Networks (DNNs) have achieved remarkable success in many computer vision tasks recently, but the huge number of parameters and the high computation overhead hinder their deployments on resource-constrained edge devices. It is worth noting that channel pruning is an effective approach for compressing DNN models. A critical challenge is to determine which channels are to be removed, so that the model accuracy will not be negatively affected. In this paper, we first propose Spatial and Channel Attention (SCA), a new attention module combining both spatial and channel attention that respectively focuses on "where" and "what" are the most informative parts. Guided by the scale values generated by SCA for measuring channel importance, we further propose a new channel pruning approach called Channel Pruning guided by Spatial and Channel Attention (CPSCA). Experimental results indicate that SCA achieves the best inference accuracy, while incurring negligibly extra resource consumption, compared to other state-of-the-art attention modules. Our evaluation on two benchmark datasets shows that, with the guidance of SCA, our CPSCA approach achieves higher inference accuracy than other state-of-the-art pruning methods under the same pruning ratios.