 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIMID: Time-Dependent Mistake Detection in Videos of Robot Executions
Mar 10, 2026As robotic systems execute increasingly difficult task sequences, so does the number of ways in which they can fail. Video Anomaly Detection (VAD) frameworks typically focus on singular, low-level kinematic or action failures, struggling to identify more complex temporal or spatial task violations, because they do not necessarily manifest as low-level execution errors. To address this problem, the main contribution of this paper is a new VAD-inspired architecture, TIMID, which is able to detect robot time-dependent mistakes when executing high-level tasks. Our architecture receives as inputs a video and prompts of the task and the potential mistake, and returns a frame-level prediction in the video of whether the mistake is present or not. By adopting a VAD formulation, the model can be trained with weak supervision, requiring only a single label per video. Additionally, to alleviate the problem of data scarcity of incorrect executions, we introduce a multi-robot simulation dataset with controlled temporal errors and real executions for zero-shot sim-to-real evaluation. Our experiments demonstrate that out-of-the-box VLMs lack the explicit temporal reasoning required for this task, whereas our framework successfully detects different types of temporal errors. Project: https://ropertunizar.github.io/TIMID/
CHORAL: Traversal-Aware Planning for Safe and Efficient Heterogeneous Multi-Robot Routing
Jan 15, 2026Monitoring large, unknown, and complex environments with autonomous robots poses significant navigation challenges, where deploying teams of heterogeneous robots with complementary capabilities can substantially improve both mission performance and feasibility. However, effectively modeling how different robotic platforms interact with the environment requires rich, semantic scene understanding. Despite this, existing approaches often assume homogeneous robot teams or focus on discrete task compatibility rather than continuous routing. Consequently, scene understanding is not fully integrated into routing decisions, limiting their ability to adapt to the environment and to leverage each robot's strengths. In this paper, we propose an integrated semantic-aware framework for coordinating heterogeneous robots. Starting from a reconnaissance flight, we build a metric-semantic map using open-vocabulary vision models and use it to identify regions requiring closer inspection and capability-aware paths for each platform to reach them. These are then incorporated into a heterogeneous vehicle routing formulation that jointly assigns inspection tasks and computes robot trajectories. Experiments in simulation and in a real inspection mission with three robotic platforms demonstrate the effectiveness of our approach in planning safer and more efficient routes by explicitly accounting for each platform's navigation capabilities. We release our framework, CHORAL, as open source to support reproducibility and deployment of diverse robot teams.
Aion: Towards Hierarchical 4D Scene Graphs with Temporal Flow Dynamics
Dec 10, 2025Autonomous navigation in dynamic environments requires spatial representations that capture both semantic structure and temporal evolution. 3D Scene Graphs (3DSGs) provide hierarchical multi-resolution abstractions that encode geometry and semantics, but existing extensions toward dynamics largely focus on individual objects or agents. In parallel, Maps of Dynamics (MoDs) model typical motion patterns and temporal regularities, yet are usually tied to grid-based discretizations that lack semantic awareness and do not scale well to large environments. In this paper we introduce Aion, a framework that embeds temporal flow dynamics directly within a hierarchical 3DSG, effectively incorporating the temporal dimension. Aion employs a graph-based sparse MoD representation to capture motion flows over arbitrary time intervals and attaches them to navigational nodes in the scene graph, yielding more interpretable and scalable predictions that improve planning and interaction in complex dynamic environments.
Towards Map-Agnostic Policies for Adaptive Informative Path Planning
Oct 22, 2024



Robots are frequently tasked to gather relevant sensor data in unknown terrains. A key challenge for classical path planning algorithms used for autonomous information gathering is adaptively replanning paths online as the terrain is explored given limited onboard compute resources. Recently, learning-based approaches emerged that train planning policies offline and enable computationally efficient online replanning performing policy inference. These approaches are designed and trained for terrain monitoring missions assuming a single specific map representation, which limits their applicability to different terrains. To address these issues, we propose a novel formulation of the adaptive informative path planning problem unified across different map representations, enabling training and deploying planning policies in a larger variety of monitoring missions. Experimental results validate that our novel formulation easily integrates with classical non-learning-based planning approaches while maintaining their performance. Our trained planning policy performs similarly to state-of-the-art map-specifically trained policies. We validate our learned policy on unseen real-world terrain datasets.
Gen-Swarms: Adapting Deep Generative Models to Swarms of Drones
Aug 28, 2024



Gen-Swarms is an innovative method that leverages and combines the capabilities of deep generative models with reactive navigation algorithms to automate the creation of drone shows. Advancements in deep generative models, particularly diffusion models, have demonstrated remarkable effectiveness in generating high-quality 2D images. Building on this success, various works have extended diffusion models to 3D point cloud generation. In contrast, alternative generative models such as flow matching have been proposed, offering a simple and intuitive transition from noise to meaningful outputs. However, the application of flow matching models to 3D point cloud generation remains largely unexplored. Gen-Swarms adapts these models to automatically generate drone shows. Existing 3D point cloud generative models create point trajectories which are impractical for drone swarms. In contrast, our method not only generates accurate 3D shapes but also guides the swarm motion, producing smooth trajectories and accounting for potential collisions through a reactive navigation algorithm incorporated into the sampling process. For example, when given a text category like Airplane, Gen-Swarms can rapidly and continuously generate numerous variations of 3D airplane shapes. Our experiments demonstrate that this approach is particularly well-suited for drone shows, providing feasible trajectories, creating representative final shapes, and significantly enhancing the overall performance of drone show generation.
AVOCADO: Adaptive Optimal Collision Avoidance driven by Opinion
Jun 29, 2024



We present AVOCADO (AdaptiVe Optimal Collision Avoidance Driven by Opinion), a novel navigation approach to address holonomic robot collision avoidance when the degree of cooperation of the other agents in the environment is unknown. AVOCADO departs from a Velocity Obstacle's formulation akin to the Optimal Reciprocal Collision Avoidance method. However, instead of assuming reciprocity, AVOCADO poses an adaptive control problem that aims at adapting in real-time to the cooperation degree of other robots and agents. Adaptation is achieved through a novel nonlinear opinion dynamics design that relies solely on sensor observations. As a by-product, based on the nonlinear opinion dynamics, we propose a novel method to avoid the deadlocks under geometrical symmetries among robots and agents. Extensive numerical simulations show that AVOCADO surpasses existing geometrical, learning and planning-based approaches in mixed cooperative/non-cooperative navigation environments in terms of success rate, time to goal and computational time. In addition, we conduct multiple real experiments that verify that AVOCADO is able to avoid collisions in environments crowded with other robots and humans.
EventSleep: Sleep Activity Recognition with Event Cameras
Apr 02, 2024Event cameras are a promising technology for activity recognition in dark environments due to their unique properties. However, real event camera datasets under low-lighting conditions are still scarce, which also limits the number of approaches to solve these kind of problems, hindering the potential of this technology in many applications. We present EventSleep, a new dataset and methodology to address this gap and study the suitability of event cameras for a very relevant medical application: sleep monitoring for sleep disorders analysis. The dataset contains synchronized event and infrared recordings emulating common movements that happen during the sleep, resulting in a new challenging and unique dataset for activity recognition in dark environments. Our novel pipeline is able to achieve high accuracy under these challenging conditions and incorporates a Bayesian approach (Laplace ensembles) to increase the robustness in the predictions, which is fundamental for medical applications. Our work is the first application of Bayesian neural networks for event cameras, the first use of Laplace ensembles in a realistic problem, and also demonstrates for the first time the potential of event cameras in a new application domain: to enhance current sleep evaluation procedures. Our activity recognition results highlight the potential of event cameras under dark conditions, and its capacity and robustness for sleep activity recognition, and open problems as the adaptation of event data pre-processing techniques to dark environments.
SpectralWaste Dataset: Multimodal Data for Waste Sorting Automation
Mar 26, 2024The increase in non-biodegradable waste is a worldwide concern. Recycling facilities play a crucial role, but their automation is hindered by the complex characteristics of waste recycling lines like clutter or object deformation. In addition, the lack of publicly available labeled data for these environments makes developing robust perception systems challenging. Our work explores the benefits of multimodal perception for object segmentation in real waste management scenarios. First, we present SpectralWaste, the first dataset collected from an operational plastic waste sorting facility that provides synchronized hyperspectral and conventional RGB images. This dataset contains labels for several categories of objects that commonly appear in sorting plants and need to be detected and separated from the main trash flow for several reasons, such as security in the management line or reuse. Additionally, we propose a pipeline employing different object segmentation architectures and evaluate the alternatives on our dataset, conducting an extensive analysis for both multimodal and unimodal alternatives. Our evaluation pays special attention to efficiency and suitability for real-time processing and demonstrates how HSI can bring a boost to RGB-only perception in these realistic industrial settings without much computational overhead.
CLIPSwarm: Generating Drone Shows from Text Prompts with Vision-Language Models
Mar 20, 2024



This paper introduces CLIPSwarm, a new algorithm designed to automate the modeling of swarm drone formations based on natural language. The algorithm begins by enriching a provided word, to compose a text prompt that serves as input to an iterative approach to find the formation that best matches the provided word. The algorithm iteratively refines formations of robots to align with the textual description, employing different steps for "exploration" and "exploitation". Our framework is currently evaluated on simple formation targets, limited to contour shapes. A formation is visually represented through alpha-shape contours and the most representative color is automatically found for the input word. To measure the similarity between the description and the visual representation of the formation, we use CLIP [1], encoding text and images into vectors and assessing their similarity. Subsequently, the algorithm rearranges the formation to visually represent the word more effectively, within the given constraints of available drones. Control actions are then assigned to the drones, ensuring robotic behavior and collision-free movement. Experimental results demonstrate the system's efficacy in accurately modeling robot formations from natural language descriptions. The algorithm's versatility is showcased through the execution of drone shows in photorealistic simulation with varying shapes. We refer the reader to the supplementary video for a visual reference of the results.
Cooperative Periodic Coverage With Collision Avoidance
Jan 24, 2024
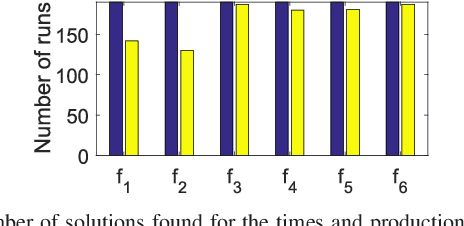


In this paper we propose a periodic solution to the problem of persistently covering a finite set of interest points with a group of autonomous mobile agents. These agents visit periodically the points and spend some time carrying out the coverage task, which we call coverage time. Since this periodic persistent coverage problem is NP-hard, we split it into three subproblems to counteract its complexity. In the first place, we plan individual closed paths for the agents to cover all the points. Second, we formulate a quadratically constrained linear program to find the optimal coverage times and actions that satisfy the coverage objective. Finally, we join together the individual plans of the agents in a periodic team plan by obtaining a schedule that guarantees collision avoidance. To this end, we solve a mixed integer linear program that minimizes the time in which two or more agents move at the same time. Eventually, we apply the proposed solution to an induction hob with mobile inductors for a domestic heating application and show its performance with experiments on a real prototype.
* This is the accepted version an already published manuscript. See journal reference for details