 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RGBManip: Monocular Image-based Robotic Manipulation through Active Object Pose Estimation
Oct 05, 2023
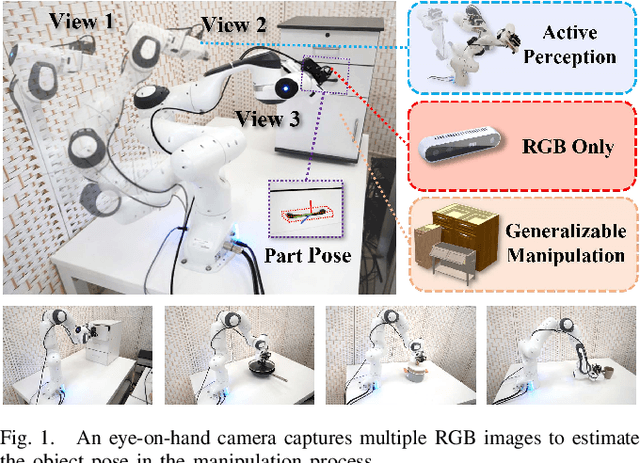
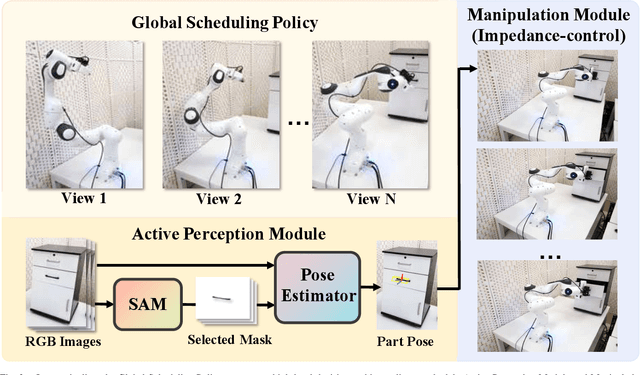

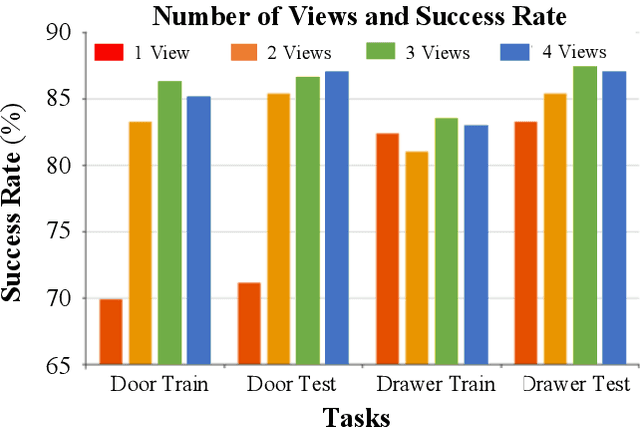
Robotic manipulation requires accurate perception of the environment, which poses a significant challenge due to its inherent complexity and constantly changing nature. In this context, RGB image and point-cloud observations are two commonly used modalities in visual-based robotic manipulation, but each of these modalities have their own limitations. Commercial point-cloud observations often suffer from issues like sparse sampling and noisy output due to the limits of the emission-reception imaging principle. On the other hand, RGB images, while rich in texture information, lack essential depth and 3D information crucial for robotic manipulation. To mitigate these challenges, we propose an image-only robotic manipulation framework that leverages an eye-on-hand monocular camera installed on the robot's parallel gripper. By moving with the robot gripper, this camera gains the ability to actively perceive object from multiple perspectives during the manipulation process. This enables the estimation of 6D object poses, which can be utilized for manipulation. While, obtaining images from more and diverse viewpoints typically improves pose estimation, it also increases the manipulation time. To address this trade-off, we employ a reinforcement learning policy to synchronize the manipulation strategy with active perception, achieving a balance between 6D pose accuracy and manipulation efficiency. Our experimental results in both simulated and real-world environments showcase the state-of-the-art effectiveness of our approach. %, which, to the best of our knowledge, is the first to achieve robust real-world robotic manipulation through active pose estimation. We believe that our method will inspire further research on real-world-oriented robotic manipulation.
Validating transformers for redaction of text from electronic health records in real-world healthcare
Oct 05, 2023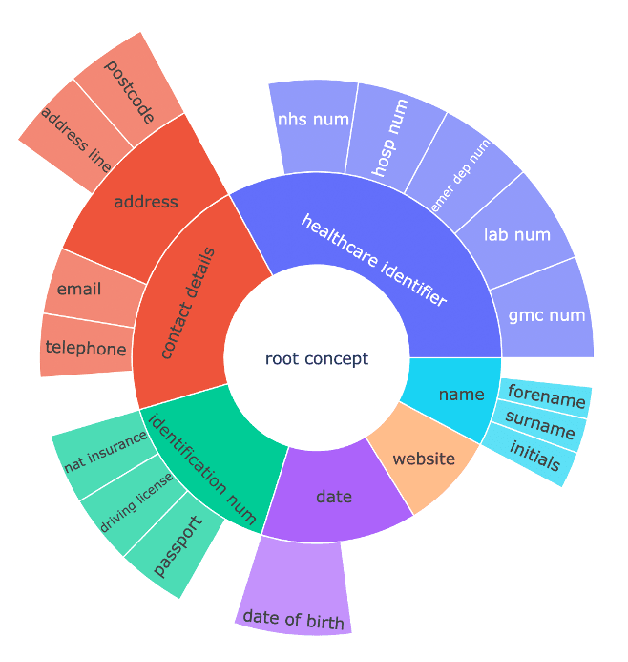
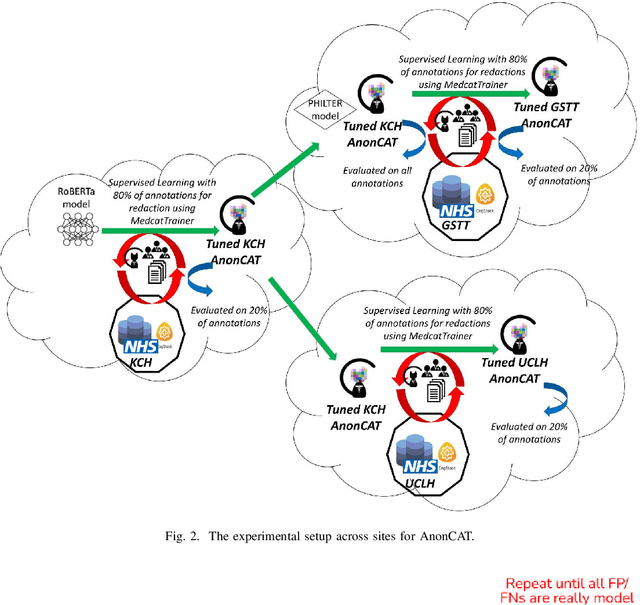
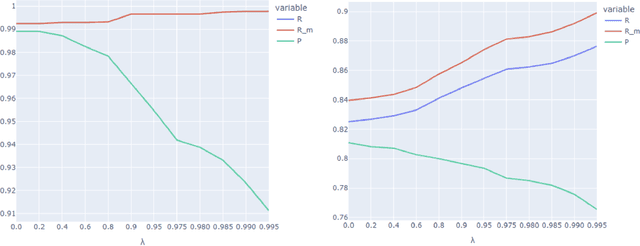
Protecting patient privacy in healthcare records is a top priority, and redaction is a commonly used method for obscuring directly identifiable information in text. Rule-based methods have been widely used, but their precision is often low causing over-redaction of text and frequently not being adaptable enough for non-standardised or unconventional structures of personal health information. Deep learning techniques have emerged as a promising solution, but implementing them in real-world environments poses challenges due to the differences in patient record structure and language across different departments, hospitals, and countries. In this study, we present AnonCAT, a transformer-based model and a blueprint on how deidentification models can be deployed in real-world healthcare. AnonCAT was trained through a process involving manually annotated redactions of real-world documents from three UK hospitals with different electronic health record systems and 3116 documents. The model achieved high performance in all three hospitals with a Recall of 0.99, 0.99 and 0.96. Our findings demonstrate the potential of deep learning techniques for improving the efficiency and accuracy of redaction in global healthcare data and highlight the importance of building workflows which not just use these models but are also able to continually fine-tune and audit the performance of these algorithms to ensure continuing effectiveness in real-world settings. This approach provides a blueprint for the real-world use of de-identifying algorithms through fine-tuning and localisation, the code together with tutorials is available on GitHub (https://github.com/CogStack/MedCAT).
Quantum computer-enabled receivers for optical communication
Sep 27, 2023Optical communication is the standard for high-bandwidth information transfer in today's digital age. The increasing demand for bandwidth has led to the maturation of coherent transceivers that use phase- and amplitude-modulated optical signals to encode more bits of information per transmitted pulse. Such encoding schemes achieve higher information density, but also require more complicated receivers to discriminate the signaling states. In fact, achieving the ultimate limit of optical communication capacity, especially in the low light regime, requires coherent joint detection of multiple pulses. Despite their superiority, such joint detection receivers are not in widespread use because of the difficulty of constructing them in the optical domain. In this work we describe how optomechanical transduction of phase information from coherent optical pulses to superconducting qubit states followed by the execution of trained short-depth variational quantum circuits can perform joint detection of communication codewords with error probabilities that surpass all classical, individual pulse detection receivers. Importantly, we utilize a model of optomechanical transduction that captures non-idealities such as thermal noise and loss in order to understand the transduction performance necessary to achieve a quantum advantage with such a scheme. We also execute the trained variational circuits on an IBM-Q device with the modeled transduced states as input to demonstrate that a quantum advantage is possible even with current levels of quantum computing hardware noise.
Exploiting Facial Relationships and Feature Aggregation for Multi-Face Forgery Detection
Oct 07, 2023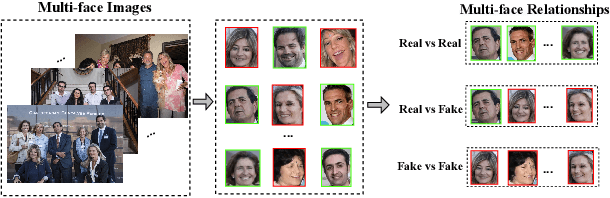
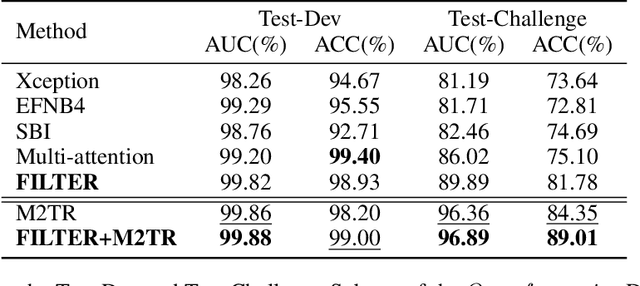
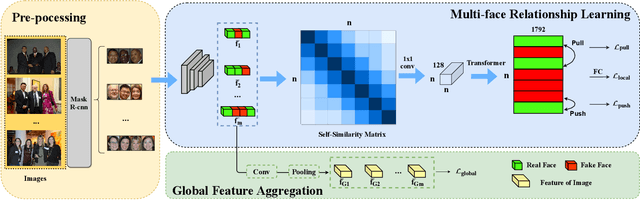
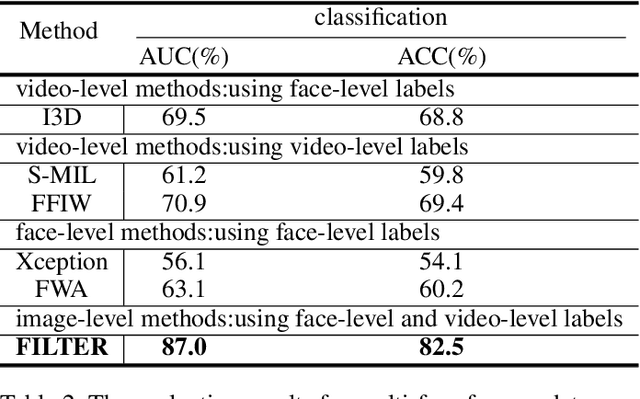
Face forgery techniques have emerged as a forefront concern, and numerous detection approaches have been proposed to address this challenge. However, existing methods predominantly concentrate on single-face manipulation detection, leaving the more intricate and realistic realm of multi-face forgeries relatively unexplored. This paper proposes a novel framework explicitly tailored for multi-face forgery detection,filling a critical gap in the current research. The framework mainly involves two modules:(i) a facial relationships learning module, which generates distinguishable local features for each face within images,(ii) a global feature aggregation module that leverages the mutual constraints between global and local information to enhance forgery detection accuracy.Our experimental results on two publicly available multi-face forgery datasets demonstrate that the proposed approach achieves state-of-the-art performance in multi-face forgery detection scenarios.
Streamlining Attack Tree Generation: A Fragment-Based Approach
Oct 01, 2023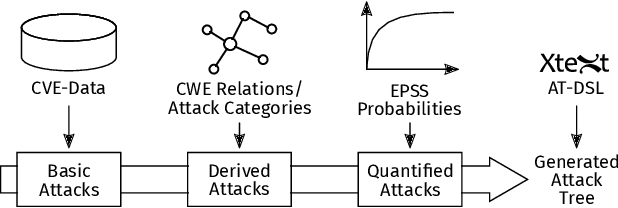
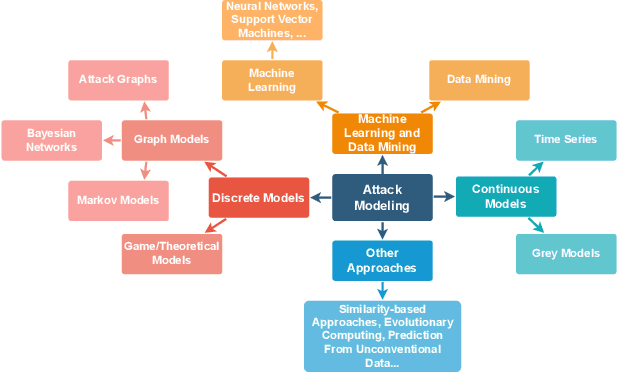
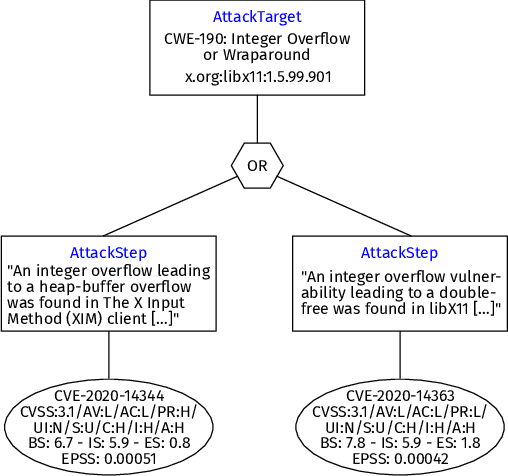
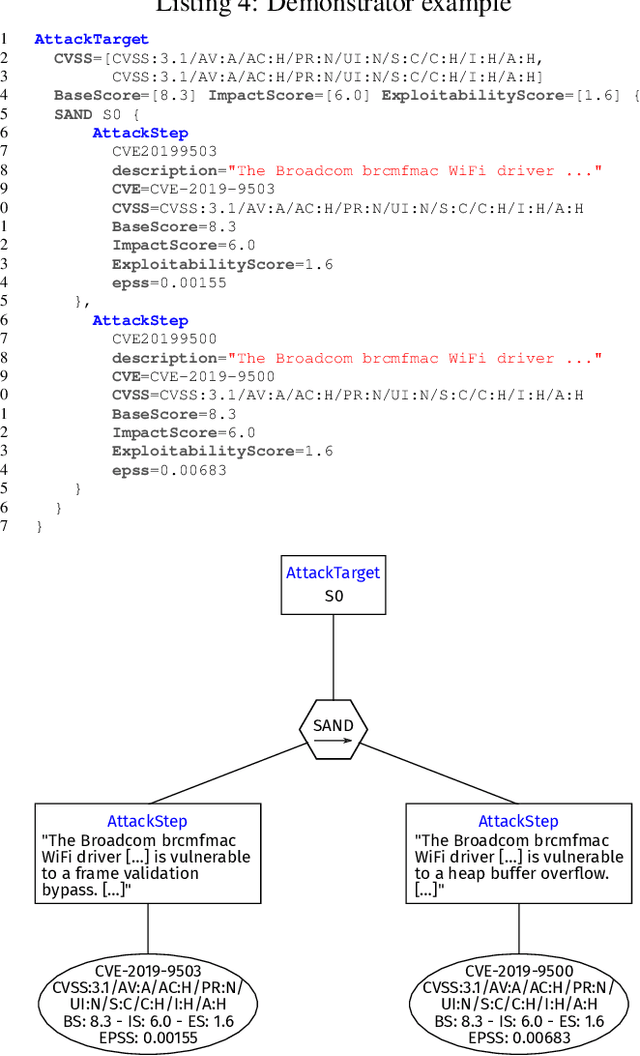
Attack graphs are a tool for analyzing security vulnerabilities that capture different and prospective attacks on a system. As a threat modeling tool, it shows possible paths that an attacker can exploit to achieve a particular goal. However, due to the large number of vulnerabilities that are published on a daily basis, they have the potential to rapidly expand in size. Consequently, this necessitates a significant amount of resources to generate attack graphs. In addition, generating composited attack models for complex systems such as self-adaptive or AI is very difficult due to their nature to continuously change. In this paper, we present a novel fragment-based attack graph generation approach that utilizes information from publicly available information security databases. Furthermore, we also propose a domain-specific language for attack modeling, which we employ in the proposed attack graph generation approach. Finally, we present a demonstrator example showcasing the attack generator's capability to replicate a verified attack chain, as previously confirmed by security experts.
PatchMixer: A Patch-Mixing Architecture for Long-Term Time Series Forecasting
Oct 01, 2023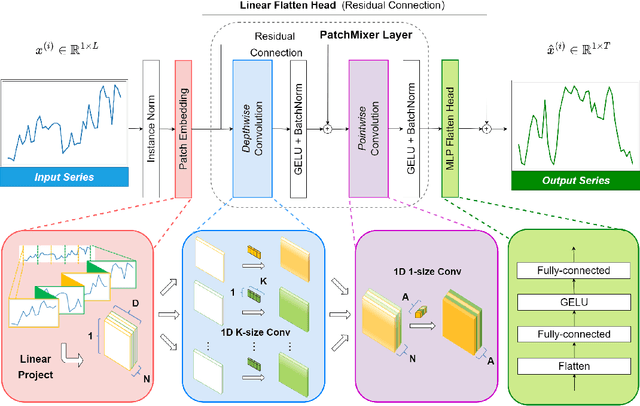
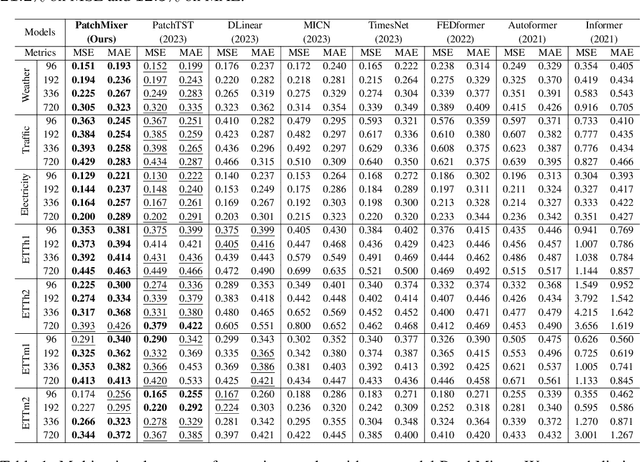
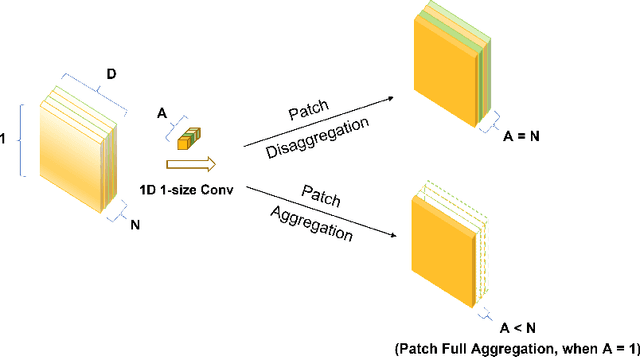
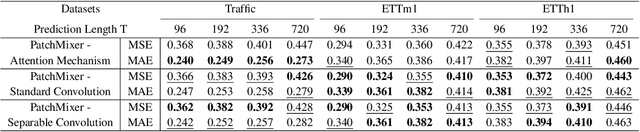
Although the Transformer has been the dominant architecture for time series forecasting tasks in recent years, a fundamental challenge remains: the permutation-invariant self-attention mechanism within Transformers leads to a loss of temporal information. To tackle these challenges, we propose PatchMixer, a novel CNN-based model. It introduces a permutation-variant convolutional structure to preserve temporal information. Diverging from conventional CNNs in this field, which often employ multiple scales or numerous branches, our method relies exclusively on depthwise separable convolutions. This allows us to extract both local features and global correlations using a single-scale architecture. Furthermore, we employ dual forecasting heads that encompass both linear and nonlinear components to better model future curve trends and details. Our experimental results on seven time-series forecasting benchmarks indicate that compared with the state-of-the-art method and the best-performing CNN, PatchMixer yields $3.9\%$ and $21.2\%$ relative improvements, respectively, while being 2-3x faster than the most advanced method. We will release our code and model.
Spectral Neural Networks: Approximation Theory and Optimization Landscape
Oct 01, 2023There is a large variety of machine learning methodologies that are based on the extraction of spectral geometric information from data. However, the implementations of many of these methods often depend on traditional eigensolvers, which present limitations when applied in practical online big data scenarios. To address some of these challenges, researchers have proposed different strategies for training neural networks as alternatives to traditional eigensolvers, with one such approach known as Spectral Neural Network (SNN). In this paper, we investigate key theoretical aspects of SNN. First, we present quantitative insights into the tradeoff between the number of neurons and the amount of spectral geometric information a neural network learns. Second, we initiate a theoretical exploration of the optimization landscape of SNN's objective to shed light on the training dynamics of SNN. Unlike typical studies of convergence to global solutions of NN training dynamics, SNN presents an additional complexity due to its non-convex ambient loss function.
AE-smnsMLC: Multi-Label Classification with Semantic Matching and Negative Label Sampling for Product Attribute Value Extraction
Oct 11, 2023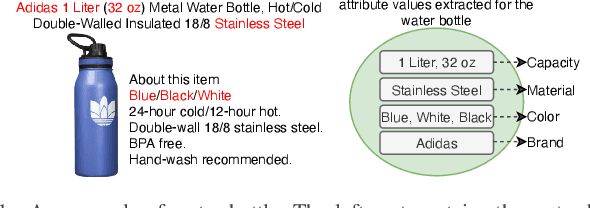
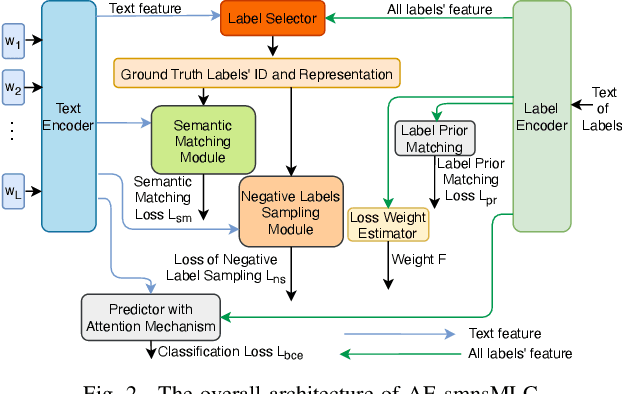
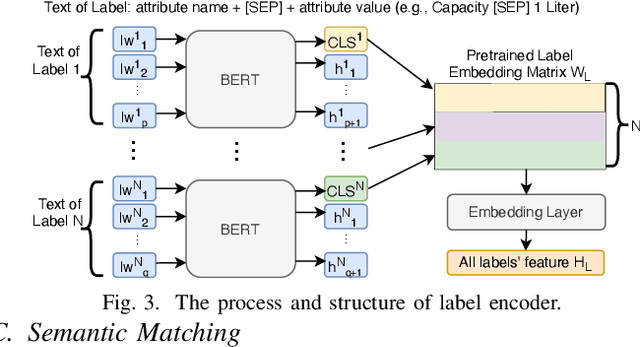
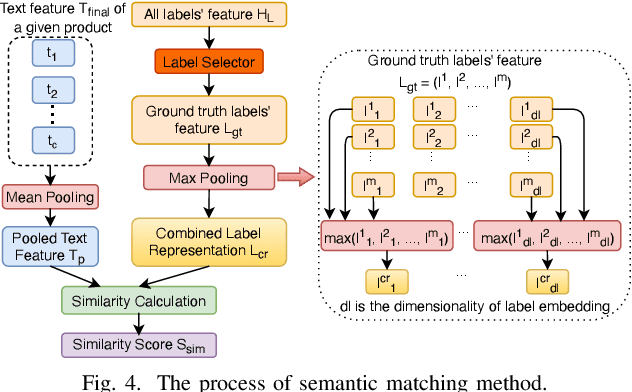
Product attribute value extraction plays an important role for many real-world applications in e-Commerce such as product search and recommendation. Previous methods treat it as a sequence labeling task that needs more annotation for position of values in the product text. This limits their application to real-world scenario in which only attribute values are weakly-annotated for each product without their position. Moreover, these methods only use product text (i.e., product title and description) and do not consider the semantic connection between the multiple attribute values of a given product and its text, which can help attribute value extraction. In this paper, we reformulate this task as a multi-label classification task that can be applied for real-world scenario in which only annotation of attribute values is available to train models (i.e., annotation of positional information of attribute values is not available). We propose a classification model with semantic matching and negative label sampling for attribute value extraction. Semantic matching aims to capture semantic interactions between attribute values of a given product and its text. Negative label sampling aims to enhance the model's ability of distinguishing similar values belonging to the same attribute. Experimental results on three subsets of a large real-world e-Commerce dataset demonstrate the effectiveness and superiority of our proposed model.
OpsEval: A Comprehensive Task-Oriented AIOps Benchmark for Large Language Models
Oct 11, 2023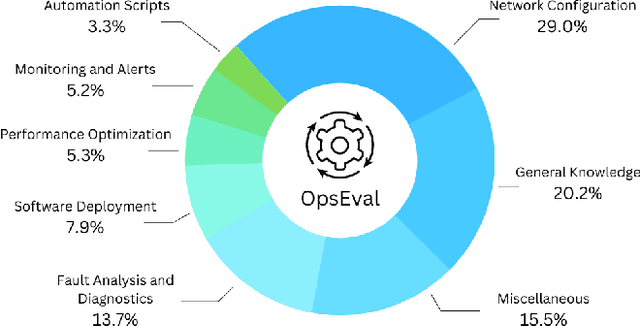
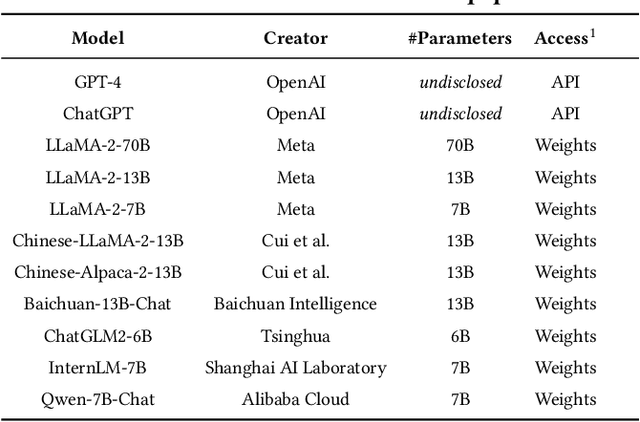


Large language models (LLMs) have exhibited remarkable capabilities in NLP-related tasks such as translation, summarizing, and generation. The application of LLMs in specific areas, notably AIOps (Artificial Intelligence for IT Operations), holds great potential due to their advanced abilities in information summarizing, report analyzing, and ability of API calling. Nevertheless, the performance of current LLMs in AIOps tasks is yet to be determined. Furthermore, a comprehensive benchmark is required to steer the optimization of LLMs tailored for AIOps. Compared with existing benchmarks that focus on evaluating specific fields like network configuration, in this paper, we present \textbf{OpsEval}, a comprehensive task-oriented AIOps benchmark designed for LLMs. For the first time, OpsEval assesses LLMs' proficiency in three crucial scenarios (Wired Network Operation, 5G Communication Operation, and Database Operation) at various ability levels (knowledge recall, analytical thinking, and practical application). The benchmark includes 7,200 questions in both multiple-choice and question-answer (QA) formats, available in English and Chinese. With quantitative and qualitative results, we show how various LLM tricks can affect the performance of AIOps, including zero-shot, chain-of-thought, and few-shot in-context learning. We find that GPT4-score is more consistent with experts than widely used Bleu and Rouge, which can be used to replace automatic metrics for large-scale qualitative evaluations.
Unsupervised Structured Noise Removal with Variational Lossy Autoencoder
Oct 11, 2023Most unsupervised denoising methods are based on the assumption that imaging noise is either pixel-independent, i.e., spatially uncorrelated, or signal-independent, i.e., purely additive. However, in practice many imaging setups, especially in microscopy, suffer from a combination of signal-dependent noise (e.g. Poisson shot noise) and axis-aligned correlated noise (e.g. stripe shaped scanning or readout artifacts). In this paper, we present the first unsupervised deep learning-based denoiser that can remove this type of noise without access to any clean images or a noise model. Unlike self-supervised techniques, our method does not rely on removing pixels by masking or subsampling so can utilize all available information. We implement a Variational Autoencoder (VAE) with a specially designed autoregressive decoder capable of modelling the noise component of an image but incapable of independently modelling the underlying clean signal component. As a consequence, our VAE's encoder learns to encode only underlying clean signal content and to discard imaging noise. We also propose an additional decoder for mapping the encoder's latent variables back into image space, thereby sampling denoised images. Experimental results demonstrate that our approach surpasses existing methods for self- and unsupervised image denoising while being robust with respect to the size of the autoregressive receptive field. Code for this project can be found at https://github.com/krulllab/DVLAE.