 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Universal Visual Decomposer: Long-Horizon Manipulation Made Easy
Oct 12, 2023
Real-world robotic tasks stretch over extended horizons and encompass multiple stages. Learning long-horizon manipulation tasks, however, is a long-standing challenge, and demands decomposing the overarching task into several manageable subtasks to facilitate policy learning and generalization to unseen tasks. Prior task decomposition methods require task-specific knowledge, are computationally intensive, and cannot readily be applied to new tasks. To address these shortcomings, we propose Universal Visual Decomposer (UVD), an off-the-shelf task decomposition method for visual long horizon manipulation using pre-trained visual representations designed for robotic control. At a high level, UVD discovers subgoals by detecting phase shifts in the embedding space of the pre-trained representation. Operating purely on visual demonstrations without auxiliary information, UVD can effectively extract visual subgoals embedded in the videos, while incurring zero additional training cost on top of standard visuomotor policy training. Goal-conditioned policies learned with UVD-discovered subgoals exhibit significantly improved compositional generalization at test time to unseen tasks. Furthermore, UVD-discovered subgoals can be used to construct goal-based reward shaping that jump-starts temporally extended exploration for reinforcement learning. We extensively evaluate UVD on both simulation and real-world tasks, and in all cases, UVD substantially outperforms baselines across imitation and reinforcement learning settings on in-domain and out-of-domain task sequences alike, validating the clear advantage of automated visual task decomposition within the simple, compact UVD framework.
Rethinking Negative Pairs in Code Search
Oct 12, 2023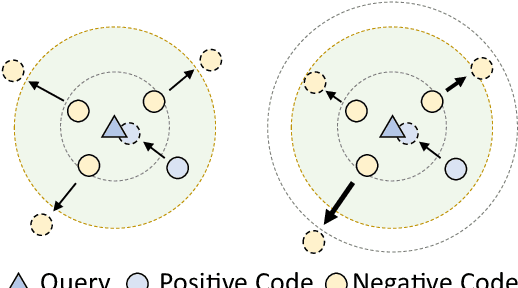
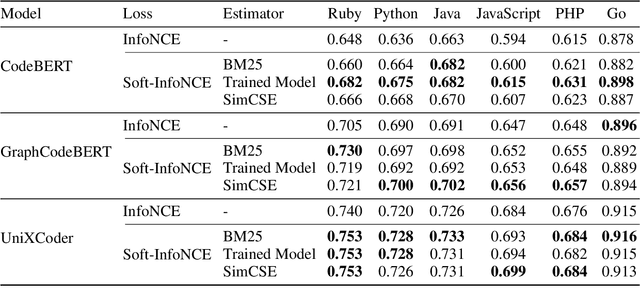
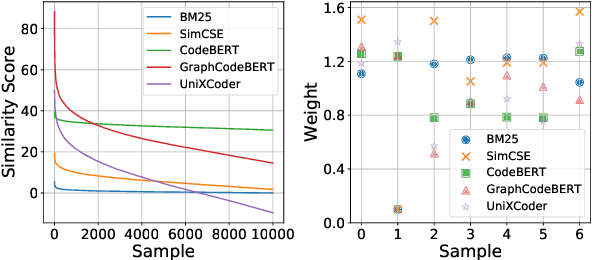
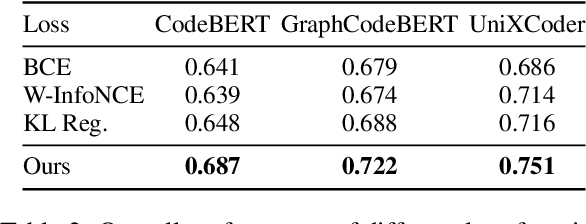
Recently, contrastive learning has become a key component in fine-tuning code search models for software development efficiency and effectiveness. It pulls together positive code snippets while pushing negative samples away given search queries. Among contrastive learning, InfoNCE is the most widely used loss function due to its better performance. However, the following problems in negative samples of InfoNCE may deteriorate its representation learning: 1) The existence of false negative samples in large code corpora due to duplications. 2). The failure to explicitly differentiate between the potential relevance of negative samples. As an example, a bubble sorting algorithm example is less ``negative'' than a file saving function for the quick sorting algorithm query. In this paper, we tackle the above problems by proposing a simple yet effective Soft-InfoNCE loss that inserts weight terms into InfoNCE. In our proposed loss function, we apply three methods to estimate the weights of negative pairs and show that the vanilla InfoNCE loss is a special case of Soft-InfoNCE. Theoretically, we analyze the effects of Soft-InfoNCE on controlling the distribution of learnt code representations and on deducing a more precise mutual information estimation. We furthermore discuss the superiority of proposed loss functions with other design alternatives. Extensive experiments demonstrate the effectiveness of Soft-InfoNCE and weights estimation methods under state-of-the-art code search models on a large-scale public dataset consisting of six programming languages. Source code is available at \url{https://github.com/Alex-HaochenLi/Soft-InfoNCE}.
Training and Predicting Visual Error for Real-Time Applications
Oct 13, 2023
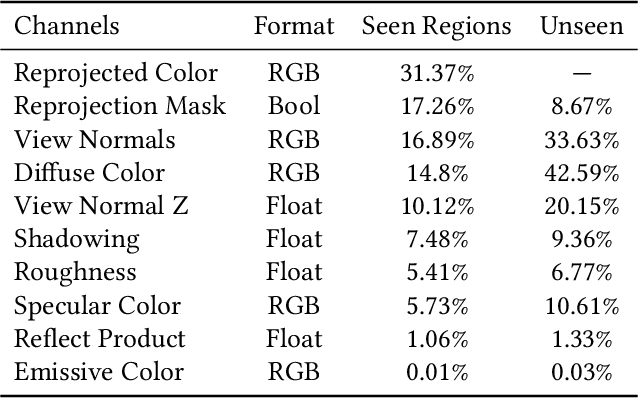
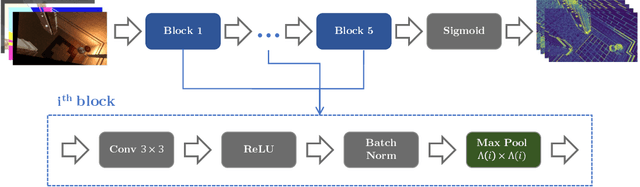
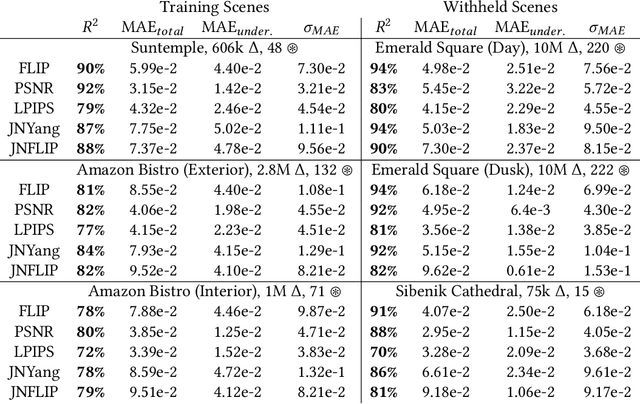
Visual error metrics play a fundamental role in the quantification of perceived image similarity. Most recently, use cases for them in real-time applications have emerged, such as content-adaptive shading and shading reuse to increase performance and improve efficiency. A wide range of different metrics has been established, with the most sophisticated being capable of capturing the perceptual characteristics of the human visual system. However, their complexity, computational expense, and reliance on reference images to compare against prevent their generalized use in real-time, restricting such applications to using only the simplest available metrics. In this work, we explore the abilities of convolutional neural networks to predict a variety of visual metrics without requiring either reference or rendered images. Specifically, we train and deploy a neural network to estimate the visual error resulting from reusing shading or using reduced shading rates. The resulting models account for 70%-90% of the variance while achieving up to an order of magnitude faster computation times. Our solution combines image-space information that is readily available in most state-of-the-art deferred shading pipelines with reprojection from previous frames to enable an adequate estimate of visual errors, even in previously unseen regions. We describe a suitable convolutional network architecture and considerations for data preparation for training. We demonstrate the capability of our network to predict complex error metrics at interactive rates in a real-time application that implements content-adaptive shading in a deferred pipeline. Depending on the portion of unseen image regions, our approach can achieve up to $2\times$ performance compared to state-of-the-art methods.
* Published at Proceedings of the ACM in Computer Graphics and Interactive Techniques. 14 Pages, 16 Figures, 3 Tables. For paper website and higher quality figures, see https://jaliborc.github.io/rt-percept/
TMac: Temporal Multi-Modal Graph Learning for Acoustic Event Classification
Sep 26, 2023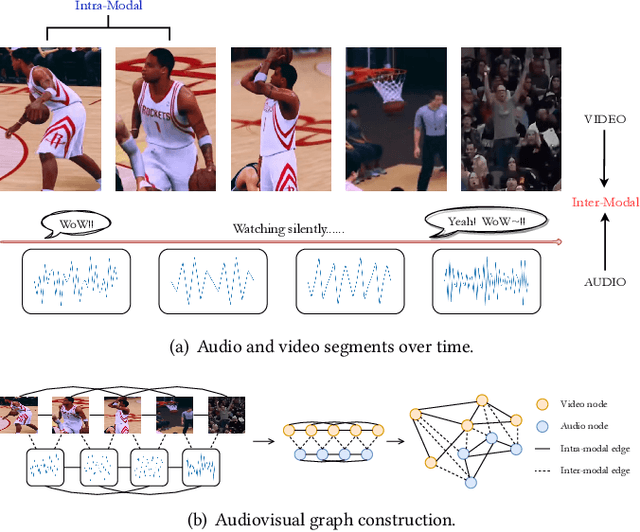

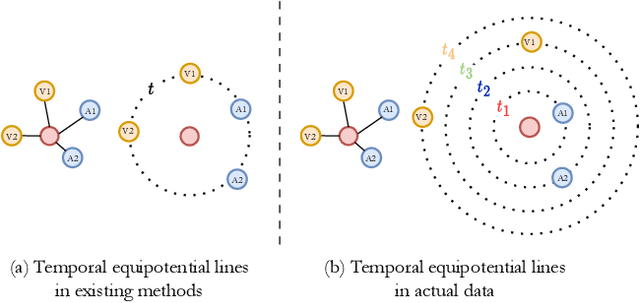
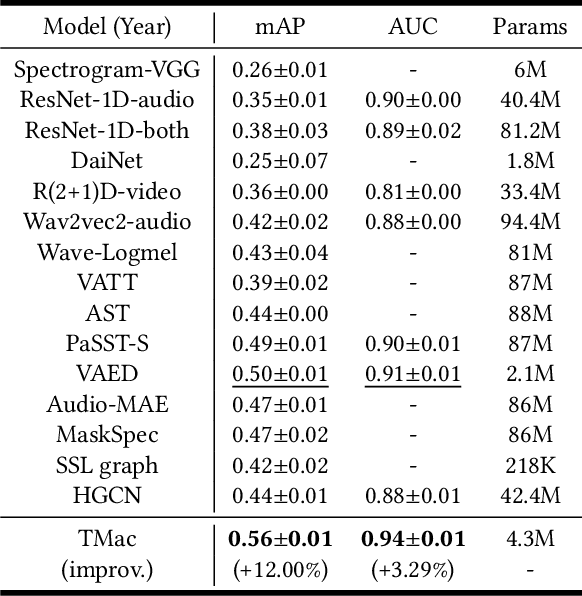
Audiovisual data is everywhere in this digital age, which raises higher requirements for the deep learning models developed on them. To well handle the information of the multi-modal data is the key to a better audiovisual modal. We observe that these audiovisual data naturally have temporal attributes, such as the time information for each frame in the video. More concretely, such data is inherently multi-modal according to both audio and visual cues, which proceed in a strict chronological order. It indicates that temporal information is important in multi-modal acoustic event modeling for both intra- and inter-modal. However, existing methods deal with each modal feature independently and simply fuse them together, which neglects the mining of temporal relation and thus leads to sub-optimal performance. With this motivation, we propose a Temporal Multi-modal graph learning method for Acoustic event Classification, called TMac, by modeling such temporal information via graph learning techniques. In particular, we construct a temporal graph for each acoustic event, dividing its audio data and video data into multiple segments. Each segment can be considered as a node, and the temporal relationships between nodes can be considered as timestamps on their edges. In this case, we can smoothly capture the dynamic information in intra-modal and inter-modal. Several experiments are conducted to demonstrate TMac outperforms other SOTA models in performance. Our code is available at https://github.com/MGitHubL/TMac.
RBF Weighted Hyper-Involution for RGB-D Object Detection
Sep 30, 2023A vast majority of conventional augmented reality devices are equipped with depth sensors. Depth images produced by such sensors contain complementary information for object detection when used with color images. Despite the benefits, it remains a complex task to simultaneously extract photometric and depth features in real time due to the immanent difference between depth and color images. Moreover, standard convolution operations are not sufficient to properly extract information directly from raw depth images leading to intermediate representations of depth which is inefficient. To address these issues, we propose a real-time and two stream RGBD object detection model. The proposed model consists of two new components: a depth guided hyper-involution that adapts dynamically based on the spatial interaction pattern in the raw depth map and an up-sampling based trainable fusion layer that combines the extracted depth and color image features without blocking the information transfer between them. We show that the proposed model outperforms other RGB-D based object detection models on NYU Depth v2 dataset and achieves comparable (second best) results on SUN RGB-D. Additionally, we introduce a new outdoor RGB-D object detection dataset where our proposed model outperforms other models. The performance evaluation on diverse synthetic data generated from CAD models and images shows the potential of the proposed model to be adapted to augmented reality based applications.
Conceptualizing Machine Learning for Dynamic Information Retrieval of Electronic Health Record Notes
Aug 09, 2023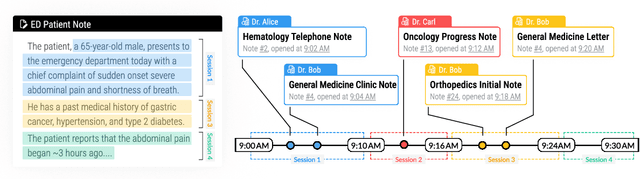
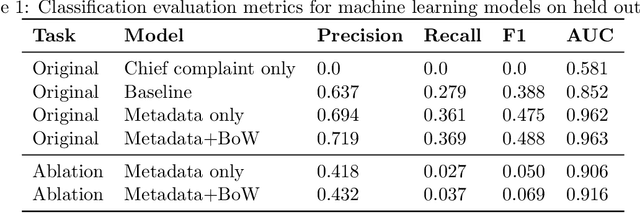
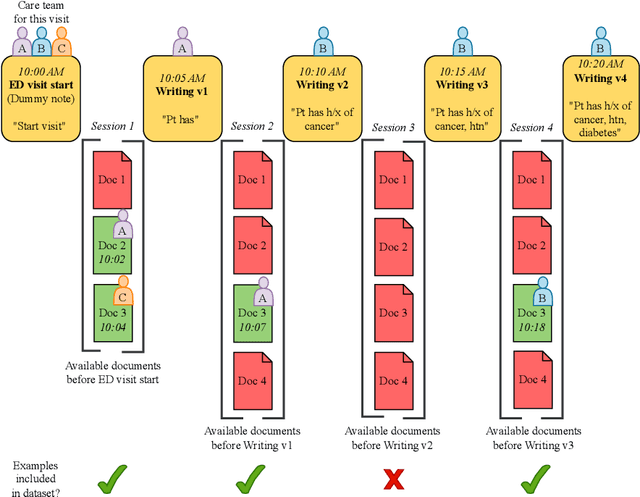
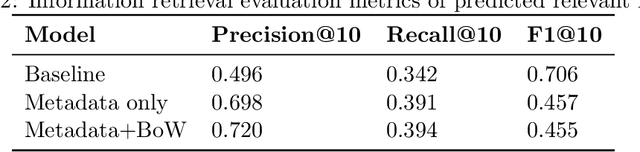
The large amount of time clinicians spend sifting through patient notes and documenting in electronic health records (EHRs) is a leading cause of clinician burnout. By proactively and dynamically retrieving relevant notes during the documentation process, we can reduce the effort required to find relevant patient history. In this work, we conceptualize the use of EHR audit logs for machine learning as a source of supervision of note relevance in a specific clinical context, at a particular point in time. Our evaluation focuses on the dynamic retrieval in the emergency department, a high acuity setting with unique patterns of information retrieval and note writing. We show that our methods can achieve an AUC of 0.963 for predicting which notes will be read in an individual note writing session. We additionally conduct a user study with several clinicians and find that our framework can help clinicians retrieve relevant information more efficiently. Demonstrating that our framework and methods can perform well in this demanding setting is a promising proof of concept that they will translate to other clinical settings and data modalities (e.g., labs, medications, imaging).
StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding
Sep 25, 2023
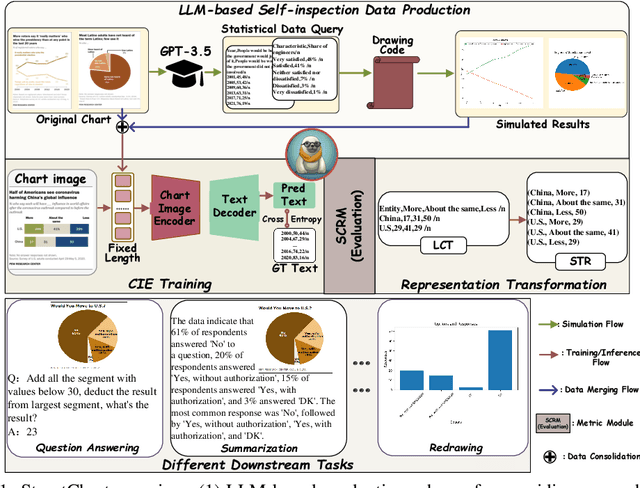
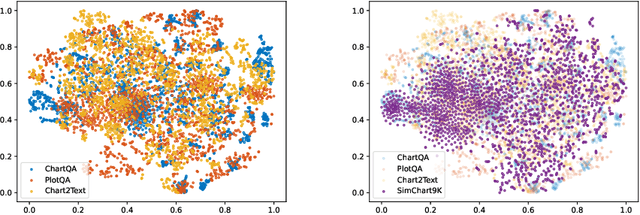
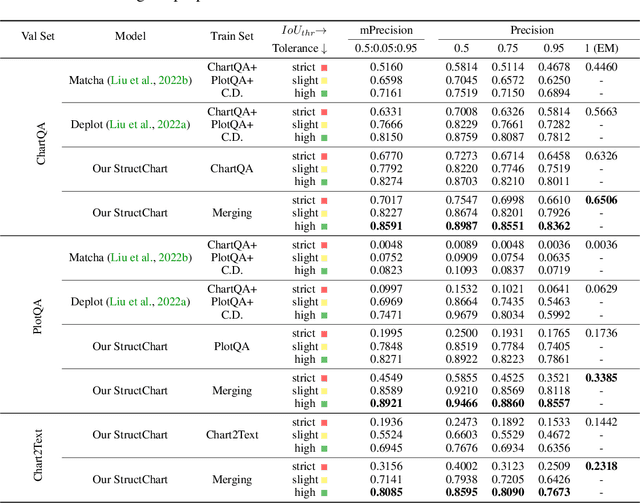
Charts are common in literature across different scientific fields, conveying rich information easily accessible to readers. Current chart-related tasks focus on either chart perception which refers to extracting information from the visual charts, or performing reasoning given the extracted data, e.g. in a tabular form. In this paper, we aim to establish a unified and label-efficient learning paradigm for joint perception and reasoning tasks, which can be generally applicable to different downstream tasks, beyond the question-answering task as specifically studied in peer works. Specifically, StructChart first reformulates the chart information from the popular tubular form (specifically linearized CSV) to the proposed Structured Triplet Representations (STR), which is more friendly for reducing the task gap between chart perception and reasoning due to the employed structured information extraction for charts. We then propose a Structuring Chart-oriented Representation Metric (SCRM) to quantitatively evaluate the performance for the chart perception task. To enrich the dataset for training, we further explore the possibility of leveraging the Large Language Model (LLM), enhancing the chart diversity in terms of both chart visual style and its statistical information. Extensive experiments are conducted on various chart-related tasks, demonstrating the effectiveness and promising potential for a unified chart perception-reasoning paradigm to push the frontier of chart understanding.
Syntax Error-Free and Generalizable Tool Use for LLMs via Finite-State Decoding
Oct 10, 2023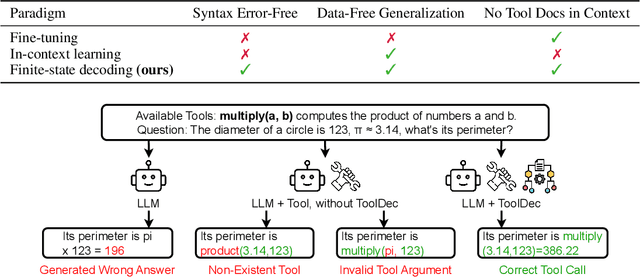
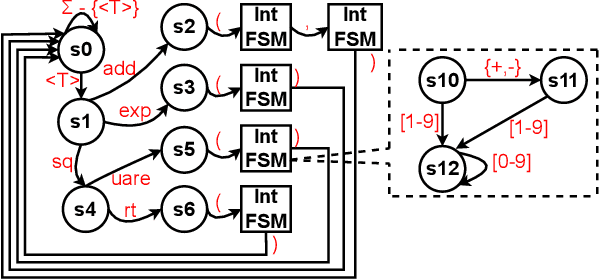

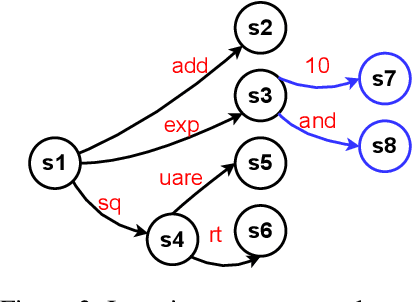
Large language models (LLMs) have shown promising capabilities in using external tools to solve complex problems. However, existing approaches either involve fine-tuning on tool demonstrations, which do not generalize to new tools without additional training, or providing tool documentation in context, limiting the number of tools. Both approaches often generate syntactically invalid tool calls. In this paper, we propose ToolDec, a finite-state machine-guided decoding algorithm for tool-augmented LLMs. ToolDec eliminates tool-related errors for any tool-augmented LLMs by ensuring valid tool names and type-conforming arguments. Furthermore, ToolDec enables LLM to effectively select tools using only the information contained in their names, with no need for fine-tuning or in-context documentation. We evaluated multiple prior methods and their ToolDec-enhanced versions on a variety of tasks involving tools like math functions, knowledge graph relations, and complex real-world RESTful APIs. Our experiments show that ToolDec reduces syntactic errors to zero, consequently achieving significantly better performance and as much as a 2x speedup. We also show that ToolDec achieves superior generalization performance on unseen tools, performing up to 8x better than the baselines.
Regret Analysis of Repeated Delegated Choice
Oct 10, 2023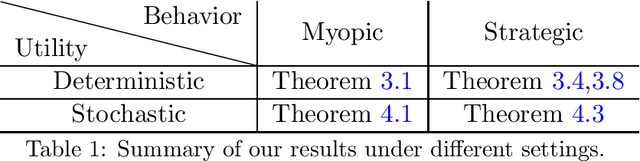
We present a study on a repeated delegated choice problem, which is the first to consider an online learning variant of Kleinberg and Kleinberg, EC'18. In this model, a principal interacts repeatedly with an agent who possesses an exogenous set of solutions to search for efficient ones. Each solution can yield varying utility for both the principal and the agent, and the agent may propose a solution to maximize its own utility in a selfish manner. To mitigate this behavior, the principal announces an eligible set which screens out a certain set of solutions. The principal, however, does not have any information on the distribution of solutions in advance. Therefore, the principal dynamically announces various eligible sets to efficiently learn the distribution. The principal's objective is to minimize cumulative regret compared to the optimal eligible set in hindsight. We explore two dimensions of the problem setup, whether the agent behaves myopically or strategizes across the rounds, and whether the solutions yield deterministic or stochastic utility. Our analysis mainly characterizes some regimes under which the principal can recover the sublinear regret, thereby shedding light on the rise and fall of the repeated delegation procedure in various regimes.
SEER: A Knapsack approach to Exemplar Selection for In-Context HybridQA
Oct 10, 2023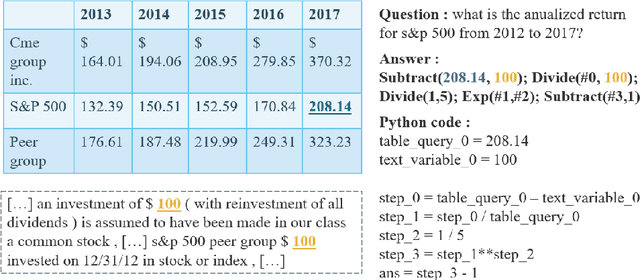
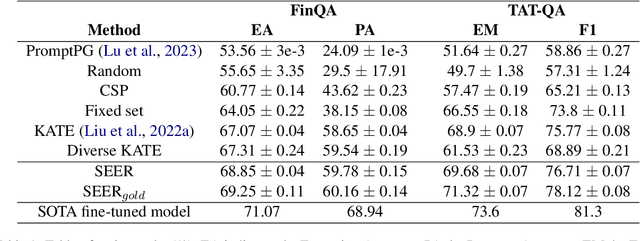
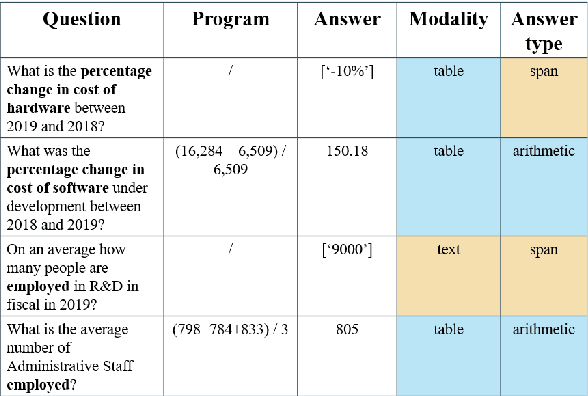
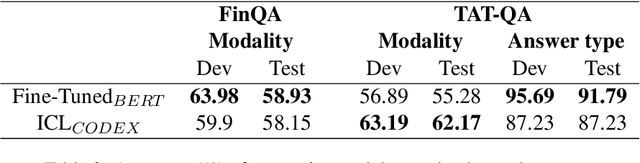
Question answering over hybrid contexts is a complex task, which requires the combination of information extracted from unstructured texts and structured tables in various ways. Recently, In-Context Learning demonstrated significant performance advances for reasoning tasks. In this paradigm, a large language model performs predictions based on a small set of supporting exemplars. The performance of In-Context Learning depends heavily on the selection procedure of the supporting exemplars, particularly in the case of HybridQA, where considering the diversity of reasoning chains and the large size of the hybrid contexts becomes crucial. In this work, we present Selection of ExEmplars for hybrid Reasoning (SEER), a novel method for selecting a set of exemplars that is both representative and diverse. The key novelty of SEER is that it formulates exemplar selection as a Knapsack Integer Linear Program. The Knapsack framework provides the flexibility to incorporate diversity constraints that prioritize exemplars with desirable attributes, and capacity constraints that ensure that the prompt size respects the provided capacity budgets. The effectiveness of SEER is demonstrated on FinQA and TAT-QA, two real-world benchmarks for HybridQA, where it outperforms previous exemplar selection methods.