 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RT-SRTS: Angle-Agnostic Real-Time Simultaneous 3D Reconstruction and Tumor Segmentation from Single X-Ray Projection
Oct 12, 2023
Radiotherapy is one of the primary treatment methods for tumors, but the organ movement caused by respiratory motion limits its accuracy. Recently, 3D imaging from single X-ray projection receives extensive attentions as a promising way to address this issue. However, current methods can only reconstruct 3D image without direct location of the tumor and are only validated for fixed-angle imaging, which fails to fully meet the requirement of motion control in radiotherapy. In this study, we propose a novel imaging method RT-SRTS which integrates 3D imaging and tumor segmentation into one network based on the multi-task learning (MTL) and achieves real-time simultaneous 3D reconstruction and tumor segmentation from single X-ray projection at any angle. Futhermore, we propose the attention enhanced calibrator (AEC) and uncertain-region elaboration (URE) modules to aid feature extraction and improve segmentation accuracy. We evaluated the proposed method on ten patient cases and compared it with two state-of-the-art methods. Our approach not only delivered superior 3D reconstruction but also demonstrated commendable tumor segmentation results. The simultaneous reconstruction and segmentation could be completed in approximately 70 ms, significantly faster than the required time threshold for real-time tumor tracking. The efficacy of both AEC and URE was also validated through ablation studies.
Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
Sep 29, 2023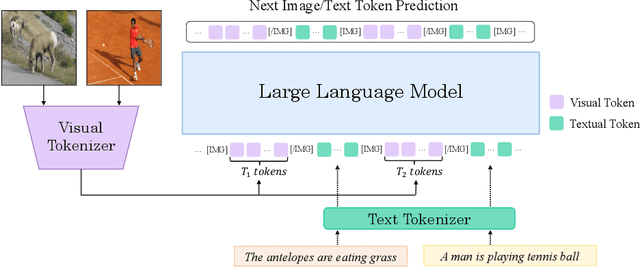
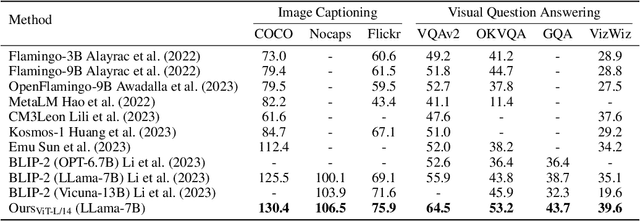
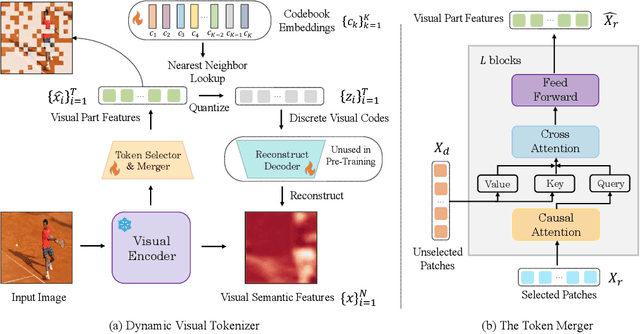
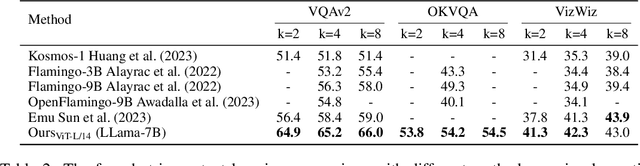
Recently, the remarkable advance of the Large Language Model (LLM) has inspired researchers to transfer its extraordinary reasoning capability to both vision and language data. However, the prevailing approaches primarily regard the visual input as a prompt and focus exclusively on optimizing the text generation process conditioned upon vision content by a frozen LLM. Such an inequitable treatment of vision and language heavily constrains the model's potential. In this paper, we break through this limitation by representing both vision and language in a unified form. Specifically, we introduce a well-designed visual tokenizer to translate the non-linguistic image into a sequence of discrete tokens like a foreign language that LLM can read. The resulting visual tokens encompass high-level semantics worthy of a word and also support dynamic sequence length varying from the image. Coped with this tokenizer, the presented foundation model called LaVIT can handle both image and text indiscriminately under the same generative learning paradigm. This unification empowers LaVIT to serve as an impressive generalist interface to understand and generate multi-modal content simultaneously. Extensive experiments further showcase that it outperforms the existing models by a large margin on massive vision-language tasks. Our code and models will be available at https://github.com/jy0205/LaVIT.
SatDM: Synthesizing Realistic Satellite Image with Semantic Layout Conditioning using Diffusion Models
Sep 28, 2023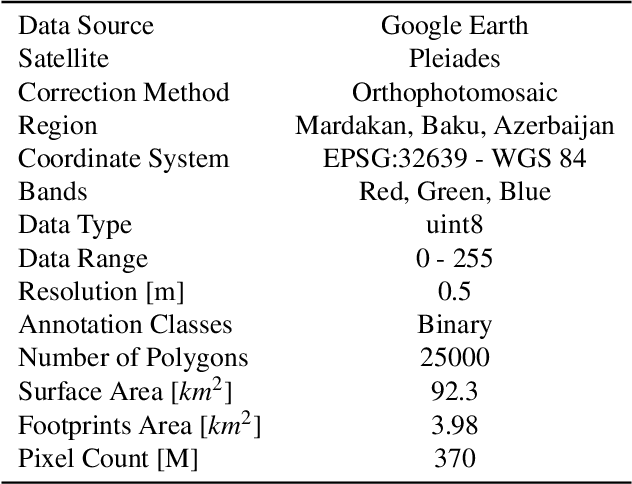
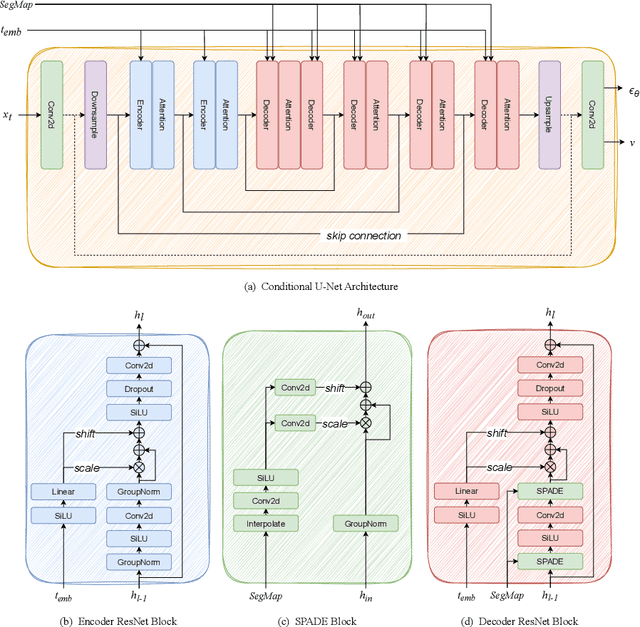
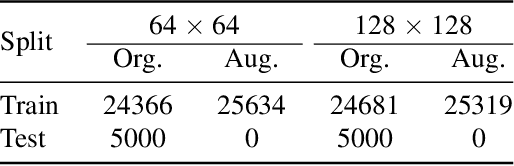
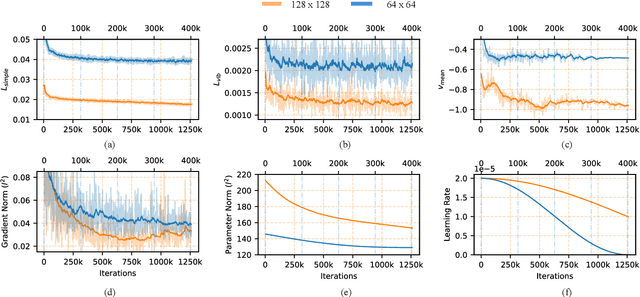
Deep learning models in the Earth Observation domain heavily rely on the availability of large-scale accurately labeled satellite imagery. However, obtaining and labeling satellite imagery is a resource-intensive endeavor. While generative models offer a promising solution to address data scarcity, their potential remains underexplored. Recently, Denoising Diffusion Probabilistic Models (DDPMs) have demonstrated significant promise in synthesizing realistic images from semantic layouts. In this paper, a conditional DDPM model capable of taking a semantic map and generating high-quality, diverse, and correspondingly accurate satellite images is implemented. Additionally, a comprehensive illustration of the optimization dynamics is provided. The proposed methodology integrates cutting-edge techniques such as variance learning, classifier-free guidance, and improved noise scheduling. The denoising network architecture is further complemented by the incorporation of adaptive normalization and self-attention mechanisms, enhancing the model's capabilities. The effectiveness of our proposed model is validated using a meticulously labeled dataset introduced within the context of this study. Validation encompasses both algorithmic methods such as Frechet Inception Distance (FID) and Intersection over Union (IoU), as well as a human opinion study. Our findings indicate that the generated samples exhibit minimal deviation from real ones, opening doors for practical applications such as data augmentation. We look forward to further explorations of DDPMs in a wider variety of settings and data modalities. An open-source reference implementation of the algorithm and a link to the benchmarked dataset are provided at https://github.com/obaghirli/syn10-diffusion.
Generating 3D Brain Tumor Regions in MRI using Vector-Quantization Generative Adversarial Networks
Oct 02, 2023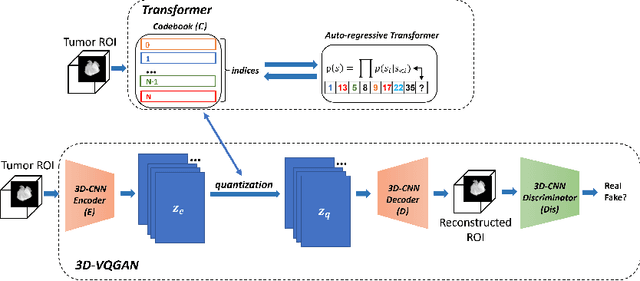
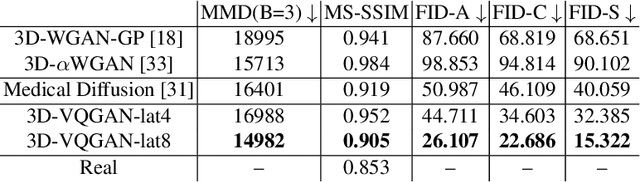
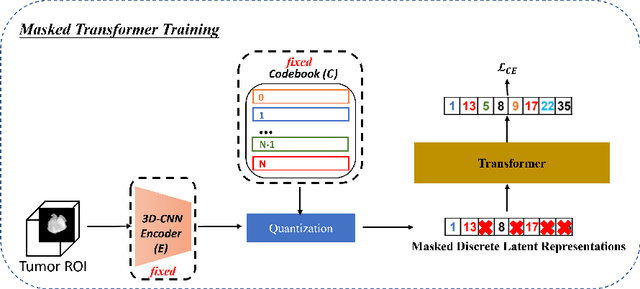
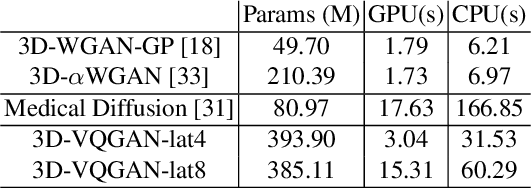
Medical image analysis has significantly benefited from advancements in deep learning, particularly in the application of Generative Adversarial Networks (GANs) for generating realistic and diverse images that can augment training datasets. However, the effectiveness of such approaches is often limited by the amount of available data in clinical settings. Additionally, the common GAN-based approach is to generate entire image volumes, rather than solely the region of interest (ROI). Research on deep learning-based brain tumor classification using MRI has shown that it is easier to classify the tumor ROIs compared to the entire image volumes. In this work, we present a novel framework that uses vector-quantization GAN and a transformer incorporating masked token modeling to generate high-resolution and diverse 3D brain tumor ROIs that can be directly used as augmented data for the classification of brain tumor ROI. We apply our method to two imbalanced datasets where we augment the minority class: (1) the Multimodal Brain Tumor Segmentation Challenge (BraTS) 2019 dataset to generate new low-grade glioma (LGG) ROIs to balance with high-grade glioma (HGG) class; (2) the internal pediatric LGG (pLGG) dataset tumor ROIs with BRAF V600E Mutation genetic marker to balance with BRAF Fusion genetic marker class. We show that the proposed method outperforms various baseline models in both qualitative and quantitative measurements. The generated data was used to balance the data in the brain tumor types classification task. Using the augmented data, our approach surpasses baseline models by 6.4% in AUC on the BraTS 2019 dataset and 4.3% in AUC on our internal pLGG dataset. The results indicate the generated tumor ROIs can effectively address the imbalanced data problem. Our proposed method has the potential to facilitate an accurate diagnosis of rare brain tumors using MRI scans.
Text-driven Prompt Generation for Vision-Language Models in Federated Learning
Oct 09, 2023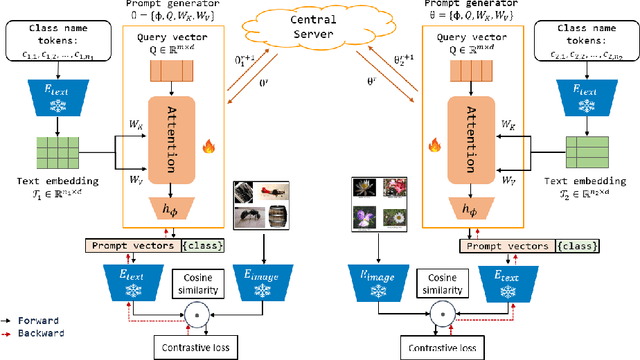
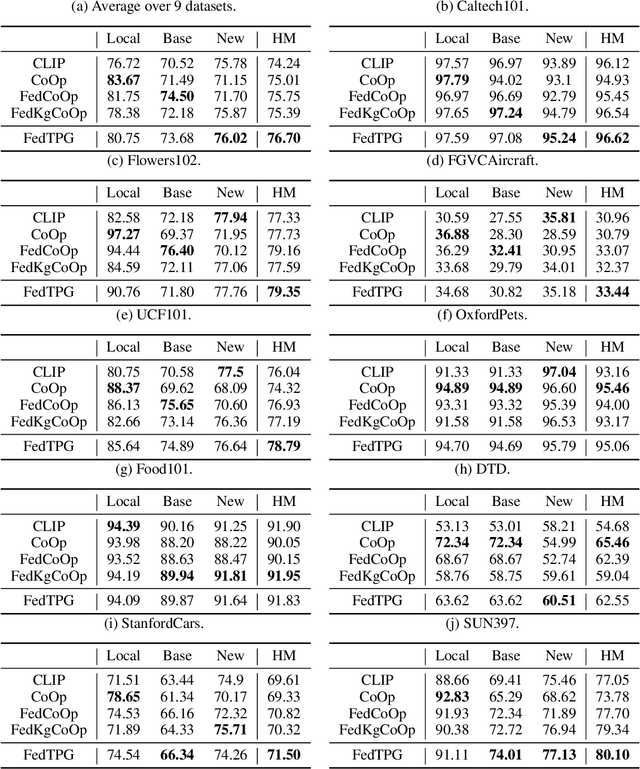
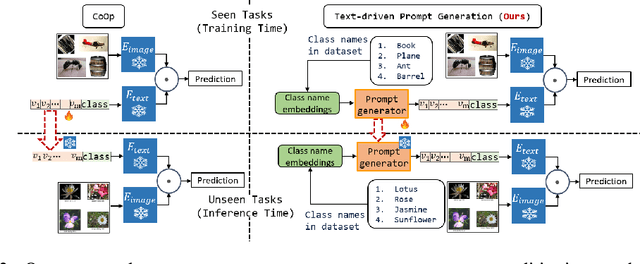
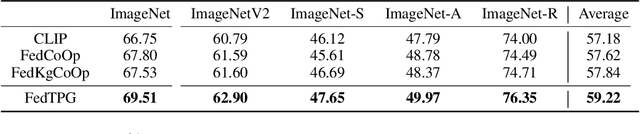
Prompt learning for vision-language models, e.g., CoOp, has shown great success in adapting CLIP to different downstream tasks, making it a promising solution for federated learning due to computational reasons. Existing prompt learning techniques replace hand-crafted text prompts with learned vectors that offer improvements on seen classes, but struggle to generalize to unseen classes. Our work addresses this challenge by proposing Federated Text-driven Prompt Generation (FedTPG), which learns a unified prompt generation network across multiple remote clients in a scalable manner. The prompt generation network is conditioned on task-related text input, thus is context-aware, making it suitable to generalize for both seen and unseen classes. Our comprehensive empirical evaluations on nine diverse image classification datasets show that our method is superior to existing federated prompt learning methods, that achieve overall better generalization on both seen and unseen classes and is also generalizable to unseen datasets.
The Role of Linguistic Priors in Measuring Compositional Generalization of Vision-Language Models
Oct 04, 2023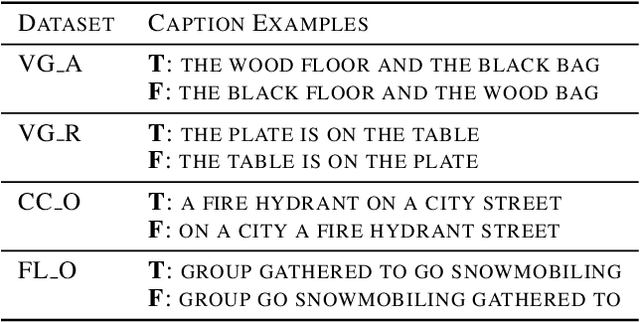
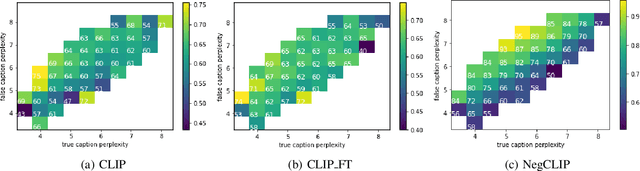
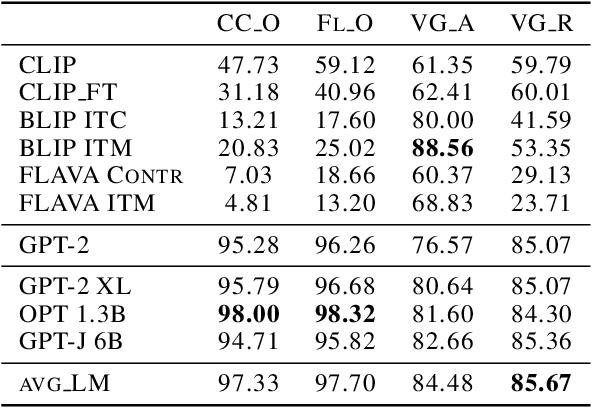
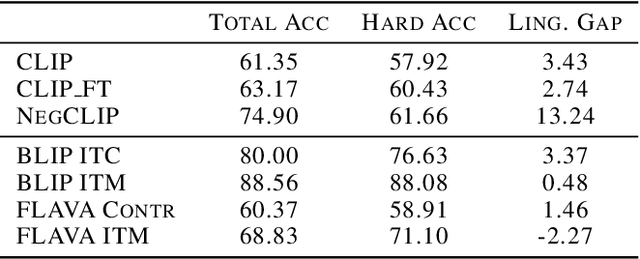
Compositionality is a common property in many modalities including natural languages and images, but the compositional generalization of multi-modal models is not well-understood. In this paper, we identify two sources of visual-linguistic compositionality: linguistic priors and the interplay between images and texts. We show that current attempts to improve compositional generalization rely on linguistic priors rather than on information in the image. We also propose a new metric for compositionality without such linguistic priors.
MBIR Training for a 2.5D DL network in X-ray CT
Sep 23, 2023In computed tomographic imaging, model based iterative reconstruction methods have generally shown better image quality than the more traditional, faster filtered backprojection technique. The cost we have to pay is that MBIR is computationally expensive. In this work we train a 2.5D deep learning (DL) network to mimic MBIR quality image. The network is realized by a modified Unet, and trained using clinical FBP and MBIR image pairs. We achieve the quality of MBIR images faster and with a much smaller computation cost. Visually and in terms of noise power spectrum (NPS), DL-MBIR images have texture similar to that of MBIR, with reduced noise power. Image profile plots, NPS plots, standard deviation, etc. suggest that the DL-MBIR images result from a successful emulation of an MBIR operator.
Augmenting medical image classifiers with synthetic data from latent diffusion models
Aug 23, 2023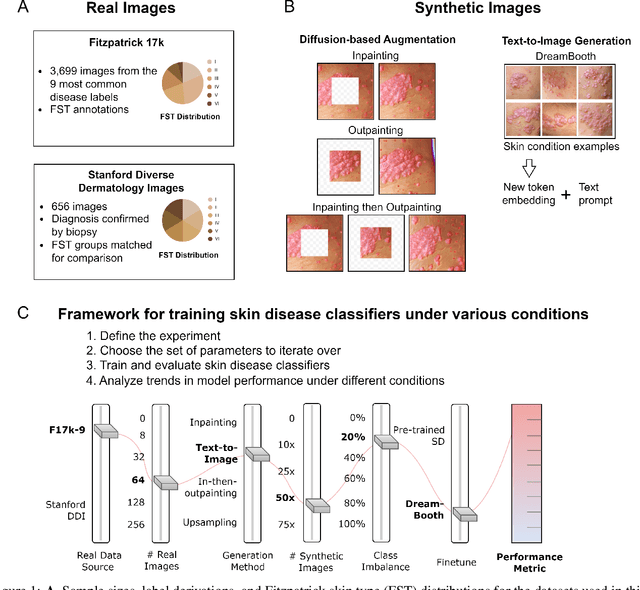
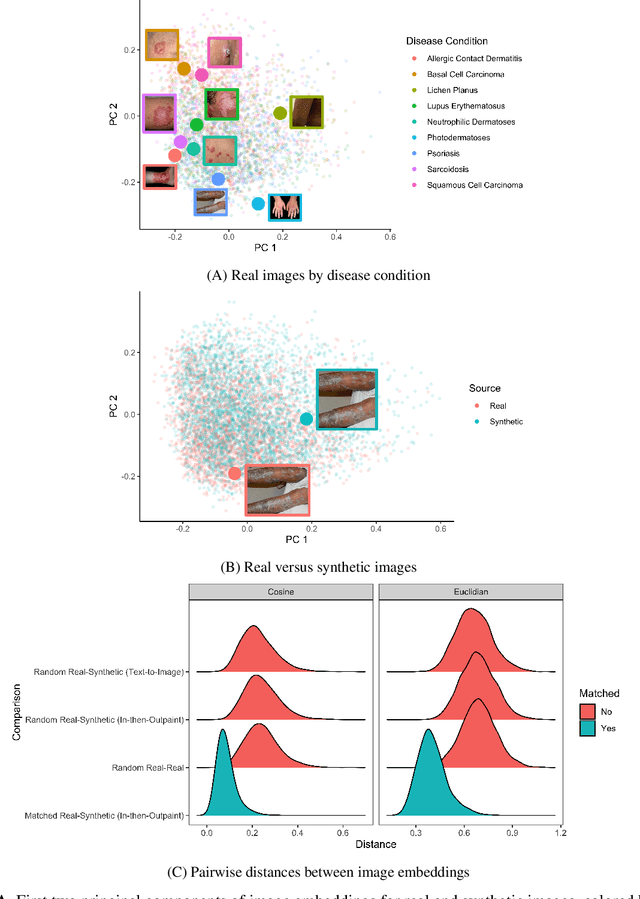
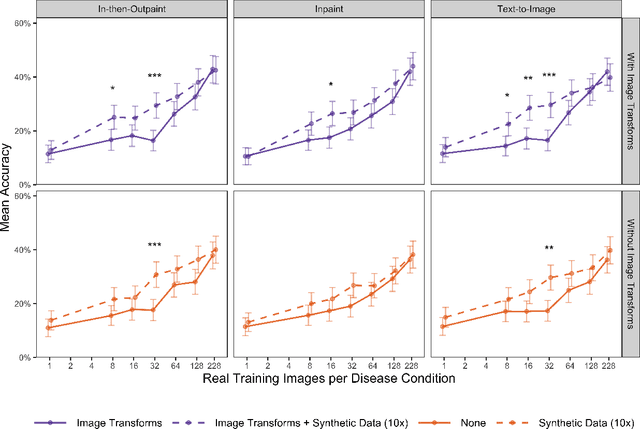

While hundreds of artificial intelligence (AI) algorithms are now approved or cleared by the US Food and Drugs Administration (FDA), many studies have shown inconsistent generalization or latent bias, particularly for underrepresented populations. Some have proposed that generative AI could reduce the need for real data, but its utility in model development remains unclear. Skin disease serves as a useful case study in synthetic image generation due to the diversity of disease appearance, particularly across the protected attribute of skin tone. Here we show that latent diffusion models can scalably generate images of skin disease and that augmenting model training with these data improves performance in data-limited settings. These performance gains saturate at synthetic-to-real image ratios above 10:1 and are substantially smaller than the gains obtained from adding real images. As part of our analysis, we generate and analyze a new dataset of 458,920 synthetic images produced using several generation strategies. Our results suggest that synthetic data could serve as a force-multiplier for model development, but the collection of diverse real-world data remains the most important step to improve medical AI algorithms.
Video-Teller: Enhancing Cross-Modal Generation with Fusion and Decoupling
Oct 11, 2023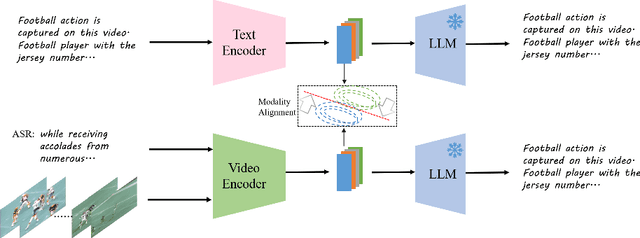
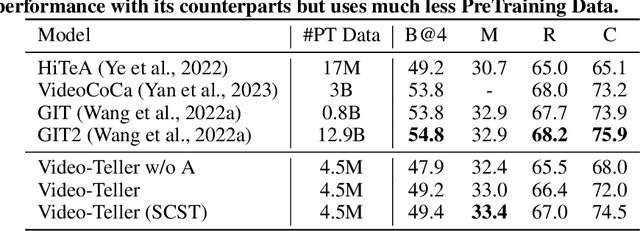
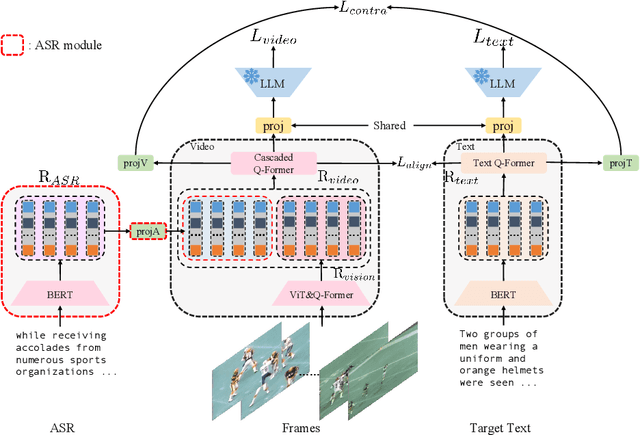

This paper proposes Video-Teller, a video-language foundation model that leverages multi-modal fusion and fine-grained modality alignment to significantly enhance the video-to-text generation task. Video-Teller boosts the training efficiency by utilizing frozen pretrained vision and language modules. It capitalizes on the robust linguistic capabilities of large language models, enabling the generation of both concise and elaborate video descriptions. To effectively integrate visual and auditory information, Video-Teller builds upon the image-based BLIP-2 model and introduces a cascaded Q-Former which fuses information across frames and ASR texts. To better guide video summarization, we introduce a fine-grained modality alignment objective, where the cascaded Q-Former's output embedding is trained to align with the caption/summary embedding created by a pretrained text auto-encoder. Experimental results demonstrate the efficacy of our proposed video-language foundation model in accurately comprehending videos and generating coherent and precise language descriptions. It is worth noting that the fine-grained alignment enhances the model's capabilities (4% improvement of CIDEr score on MSR-VTT) with only 13% extra parameters in training and zero additional cost in inference.
Echocardiography video synthesis from end diastolic semantic map via diffusion model
Oct 11, 2023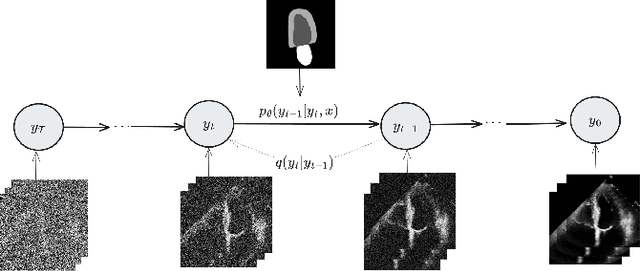
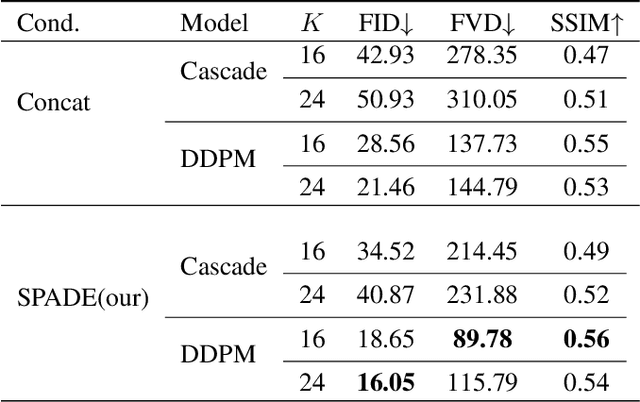
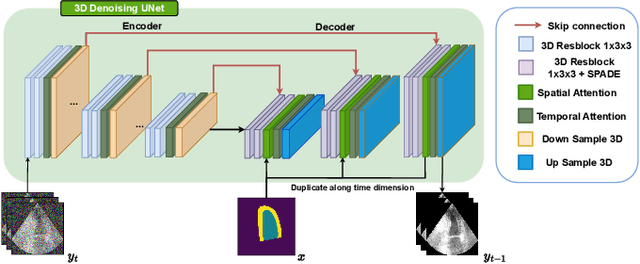
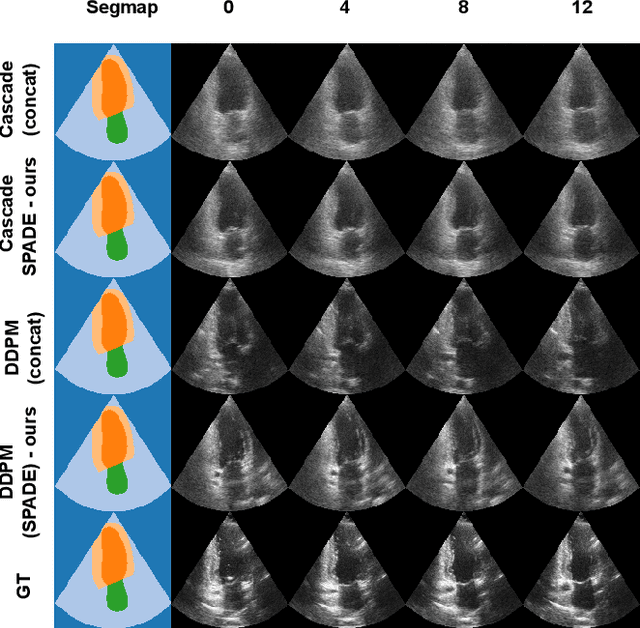
Denoising Diffusion Probabilistic Models (DDPMs) have demonstrated significant achievements in various image and video generation tasks, including the domain of medical imaging. However, generating echocardiography videos based on semantic anatomical information remains an unexplored area of research. This is mostly due to the constraints imposed by the currently available datasets, which lack sufficient scale and comprehensive frame-wise annotations for every cardiac cycle. This paper aims to tackle the aforementioned challenges by expanding upon existing video diffusion models for the purpose of cardiac video synthesis. More specifically, our focus lies in generating video using semantic maps of the initial frame during the cardiac cycle, commonly referred to as end diastole. To further improve the synthesis process, we integrate spatial adaptive normalization into multiscale feature maps. This enables the inclusion of semantic guidance during synthesis, resulting in enhanced realism and coherence of the resultant video sequences. Experiments are conducted on the CAMUS dataset, which is a highly used dataset in the field of echocardiography. Our model exhibits better performance compared to the standard diffusion technique in terms of multiple metrics, including FID, FVD, and SSMI.