 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Geom-Erasing: Geometry-Driven Removal of Implicit Concept in Diffusion Models
Oct 10, 2023
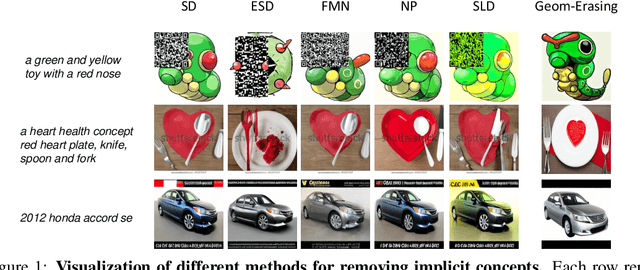

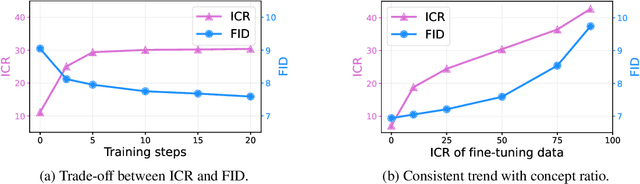
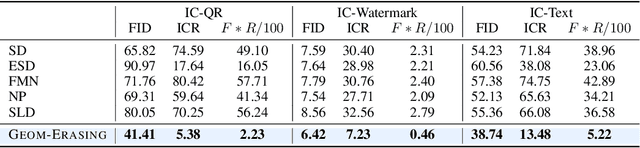
Fine-tuning diffusion models through personalized datasets is an acknowledged method for improving generation quality across downstream tasks, which, however, often inadvertently generates unintended concepts such as watermarks and QR codes, attributed to the limitations in image sources and collecting methods within specific downstream tasks. Existing solutions suffer from eliminating these unintentionally learned implicit concepts, primarily due to the dependency on the model's ability to recognize concepts that it actually cannot discern. In this work, we introduce Geom-Erasing, a novel approach that successfully removes the implicit concepts with either an additional accessible classifier or detector model to encode geometric information of these concepts into text domain. Moreover, we propose Implicit Concept, a novel image-text dataset imbued with three implicit concepts (i.e., watermarks, QR codes, and text) for training and evaluation. Experimental results demonstrate that Geom-Erasing not only identifies but also proficiently eradicates implicit concepts, revealing a significant improvement over the existing methods. The integration of geometric information marks a substantial progression in the precise removal of implicit concepts in diffusion models.
Unsupervised bias discovery in medical image segmentation
Sep 01, 2023It has recently been shown that deep learning models for anatomical segmentation in medical images can exhibit biases against certain sub-populations defined in terms of protected attributes like sex or ethnicity. In this context, auditing fairness of deep segmentation models becomes crucial. However, such audit process generally requires access to ground-truth segmentation masks for the target population, which may not always be available, especially when going from development to deployment. Here we propose a new method to anticipate model biases in biomedical image segmentation in the absence of ground-truth annotations. Our unsupervised bias discovery method leverages the reverse classification accuracy framework to estimate segmentation quality. Through numerical experiments in synthetic and realistic scenarios we show how our method is able to successfully anticipate fairness issues in the absence of ground-truth labels, constituting a novel and valuable tool in this field.
Efficient Model-Agnostic Multi-Group Equivariant Networks
Oct 14, 2023Constructing model-agnostic group equivariant networks, such as equitune (Basu et al., 2023b) and its generalizations (Kim et al., 2023), can be computationally expensive for large product groups. We address this by providing efficient model-agnostic equivariant designs for two related problems: one where the network has multiple inputs each with potentially different groups acting on them, and another where there is a single input but the group acting on it is a large product group. For the first design, we initially consider a linear model and characterize the entire equivariant space that satisfies this constraint. This characterization gives rise to a novel fusion layer between different channels that satisfies an invariance-symmetry (IS) constraint, which we call an IS layer. We then extend this design beyond linear models, similar to equitune, consisting of equivariant and IS layers. We also show that the IS layer is a universal approximator of invariant-symmetric functions. Inspired by the first design, we use the notion of the IS property to design a second efficient model-agnostic equivariant design for large product groups acting on a single input. For the first design, we provide experiments on multi-image classification where each view is transformed independently with transformations such as rotations. We find equivariant models are robust to such transformations and perform competitively otherwise. For the second design, we consider three applications: language compositionality on the SCAN dataset to product groups; fairness in natural language generation from GPT-2 to address intersectionality; and robust zero-shot image classification with CLIP. Overall, our methods are simple and general, competitive with equitune and its variants, while also being computationally more efficient.
ClusterFormer: Clustering As A Universal Visual Learner
Oct 01, 2023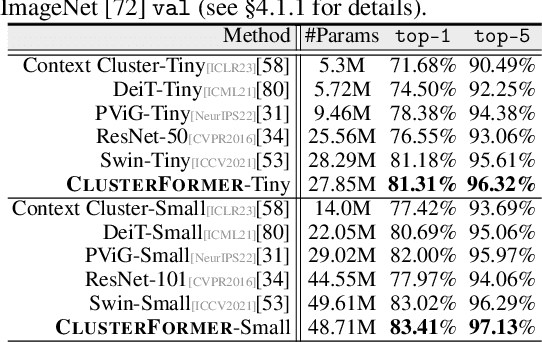
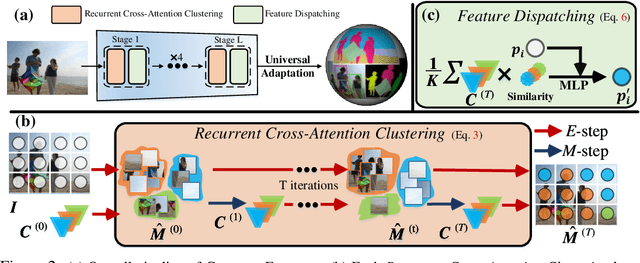
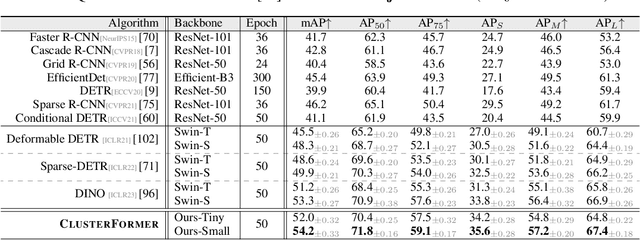

This paper presents CLUSTERFORMER, a universal vision model that is based on the CLUSTERing paradigm with TransFORMER. It comprises two novel designs: 1. recurrent cross-attention clustering, which reformulates the cross-attention mechanism in Transformer and enables recursive updates of cluster centers to facilitate strong representation learning; and 2. feature dispatching, which uses the updated cluster centers to redistribute image features through similarity-based metrics, resulting in a transparent pipeline. This elegant design streamlines an explainable and transferable workflow, capable of tackling heterogeneous vision tasks (i.e., image classification, object detection, and image segmentation) with varying levels of clustering granularity (i.e., image-, box-, and pixel-level). Empirical results demonstrate that CLUSTERFORMER outperforms various well-known specialized architectures, achieving 83.41% top-1 acc. over ImageNet-1K for image classification, 54.2% and 47.0% mAP over MS COCO for object detection and instance segmentation, 52.4% mIoU over ADE20K for semantic segmentation, and 55.8% PQ over COCO Panoptic for panoptic segmentation. For its efficacy, we hope our work can catalyze a paradigm shift in universal models in computer vision.
A Comprehensive Review of Generative AI in Healthcare
Oct 01, 2023
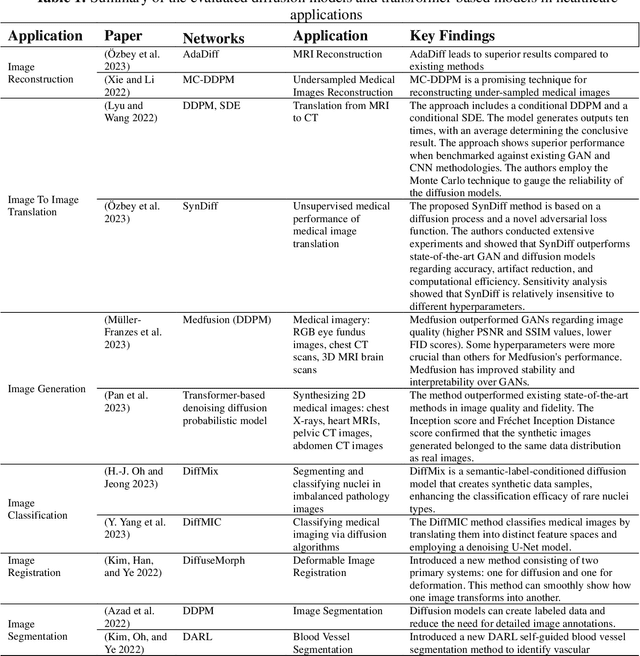
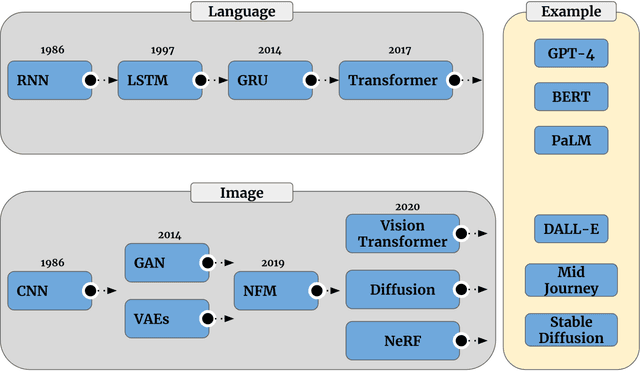
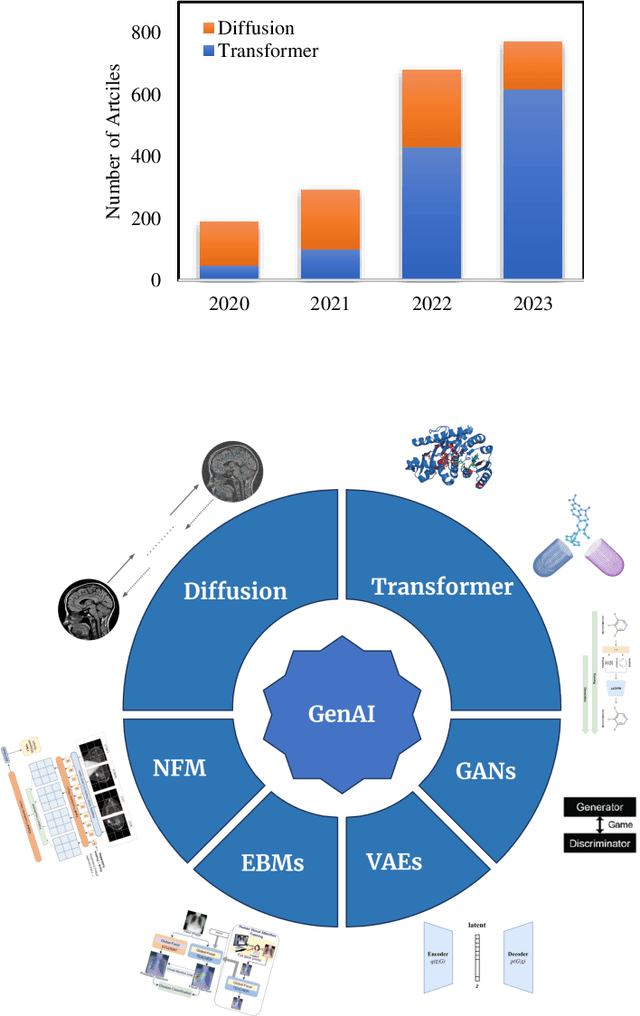
The advancement of Artificial Intelligence (AI) has catalyzed revolutionary changes across various sectors, notably in healthcare. Among the significant developments in this field are the applications of generative AI models, specifically transformers and diffusion models. These models have played a crucial role in analyzing diverse forms of data, including medical imaging (encompassing image reconstruction, image-to-image translation, image generation, and image classification), protein structure prediction, clinical documentation, diagnostic assistance, radiology interpretation, clinical decision support, medical coding, and billing, as well as drug design and molecular representation. Such applications have enhanced clinical diagnosis, data reconstruction, and drug synthesis. This review paper aims to offer a thorough overview of the generative AI applications in healthcare, focusing on transformers and diffusion models. Additionally, we propose potential directions for future research to tackle the existing limitations and meet the evolving demands of the healthcare sector. Intended to serve as a comprehensive guide for researchers and practitioners interested in the healthcare applications of generative AI, this review provides valuable insights into the current state of the art, challenges faced, and prospective future directions.
DELIFFAS: Deformable Light Fields for Fast Avatar Synthesis
Oct 17, 2023Generating controllable and photorealistic digital human avatars is a long-standing and important problem in Vision and Graphics. Recent methods have shown great progress in terms of either photorealism or inference speed while the combination of the two desired properties still remains unsolved. To this end, we propose a novel method, called DELIFFAS, which parameterizes the appearance of the human as a surface light field that is attached to a controllable and deforming human mesh model. At the core, we represent the light field around the human with a deformable two-surface parameterization, which enables fast and accurate inference of the human appearance. This allows perceptual supervision on the full image compared to previous approaches that could only supervise individual pixels or small patches due to their slow runtime. Our carefully designed human representation and supervision strategy leads to state-of-the-art synthesis results and inference time. The video results and code are available at https://vcai.mpi-inf.mpg.de/projects/DELIFFAS.
Zero-shot Inversion Process for Image Attribute Editing with Diffusion Models
Aug 30, 2023Denoising diffusion models have shown outstanding performance in image editing. Existing works tend to use either image-guided methods, which provide a visual reference but lack control over semantic coherence, or text-guided methods, which ensure faithfulness to text guidance but lack visual quality. To address the problem, we propose the Zero-shot Inversion Process (ZIP), a framework that injects a fusion of generated visual reference and text guidance into the semantic latent space of a \textit{frozen} pre-trained diffusion model. Only using a tiny neural network, the proposed ZIP produces diverse content and attributes under the intuitive control of the text prompt. Moreover, ZIP shows remarkable robustness for both in-domain and out-of-domain attribute manipulation on real images. We perform detailed experiments on various benchmark datasets. Compared to state-of-the-art methods, ZIP produces images of equivalent quality while providing a realistic editing effect.
Skin Lesion Segmentation Improved by Transformer-based Networks with Inter-scale Dependency Modeling
Oct 20, 2023Melanoma, a dangerous type of skin cancer resulting from abnormal skin cell growth, can be treated if detected early. Various approaches using Fully Convolutional Networks (FCNs) have been proposed, with the U-Net architecture being prominent To aid in its diagnosis through automatic skin lesion segmentation. However, the symmetrical U-Net model's reliance on convolutional operations hinders its ability to capture long-range dependencies crucial for accurate medical image segmentation. Several Transformer-based U-Net topologies have recently been created to overcome this limitation by replacing CNN blocks with different Transformer modules to capture local and global representations. Furthermore, the U-shaped structure is hampered by semantic gaps between the encoder and decoder. This study intends to increase the network's feature re-usability by carefully building the skip connection path. Integrating an already calculated attention affinity within the skip connection path improves the typical concatenation process utilized in the conventional skip connection path. As a result, we propose a U-shaped hierarchical Transformer-based structure for skin lesion segmentation and an Inter-scale Context Fusion (ISCF) method that uses attention correlations in each stage of the encoder to adaptively combine the contexts from each stage to mitigate semantic gaps. The findings from two skin lesion segmentation benchmarks support the ISCF module's applicability and effectiveness. The code is publicly available at \url{https://github.com/saniaesk/skin-lesion-segmentation}
DT/MARS-CycleGAN: Improved Object Detection for MARS Phenotyping Robot
Oct 20, 2023Robotic crop phenotyping has emerged as a key technology to assess crops' morphological and physiological traits at scale. These phenotypical measurements are essential for developing new crop varieties with the aim of increasing productivity and dealing with environmental challenges such as climate change. However, developing and deploying crop phenotyping robots face many challenges such as complex and variable crop shapes that complicate robotic object detection, dynamic and unstructured environments that baffle robotic control, and real-time computing and managing big data that challenge robotic hardware/software. This work specifically tackles the first challenge by proposing a novel Digital-Twin(DT)MARS-CycleGAN model for image augmentation to improve our Modular Agricultural Robotic System (MARS)'s crop object detection from complex and variable backgrounds. Our core idea is that in addition to the cycle consistency losses in the CycleGAN model, we designed and enforced a new DT-MARS loss in the deep learning model to penalize the inconsistency between real crop images captured by MARS and synthesized images sensed by DT MARS. Therefore, the generated synthesized crop images closely mimic real images in terms of realism, and they are employed to fine-tune object detectors such as YOLOv8. Extensive experiments demonstrated that our new DT/MARS-CycleGAN framework significantly boosts our MARS' crop object/row detector's performance, contributing to the field of robotic crop phenotyping.
Consistency Regularization Improves Placenta Segmentation in Fetal EPI MRI Time Series
Oct 16, 2023The placenta plays a crucial role in fetal development. Automated 3D placenta segmentation from fetal EPI MRI holds promise for advancing prenatal care. This paper proposes an effective semi-supervised learning method for improving placenta segmentation in fetal EPI MRI time series. We employ consistency regularization loss that promotes consistency under spatial transformation of the same image and temporal consistency across nearby images in a time series. The experimental results show that the method improves the overall segmentation accuracy and provides better performance for outliers and hard samples. The evaluation also indicates that our method improves the temporal coherency of the prediction, which could lead to more accurate computation of temporal placental biomarkers. This work contributes to the study of the placenta and prenatal clinical decision-making. Code is available at https://github.com/firstmover/cr-seg.