 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Vision-Language Pseudo-Labels for Single-Positive Multi-Label Learning
Oct 24, 2023
This paper presents a novel approach to Single-Positive Multi-label Learning. In general multi-label learning, a model learns to predict multiple labels or categories for a single input image. This is in contrast with standard multi-class image classification, where the task is predicting a single label from many possible labels for an image. Single-Positive Multi-label Learning (SPML) specifically considers learning to predict multiple labels when there is only a single annotation per image in the training data. Multi-label learning is in many ways a more realistic task than single-label learning as real-world data often involves instances belonging to multiple categories simultaneously; however, most common computer vision datasets predominantly contain single labels due to the inherent complexity and cost of collecting multiple high quality annotations for each instance. We propose a novel approach called Vision-Language Pseudo-Labeling (VLPL), which uses a vision-language model to suggest strong positive and negative pseudo-labels, and outperforms the current SOTA methods by 5.5% on Pascal VOC, 18.4% on MS-COCO, 15.2% on NUS-WIDE, and 8.4% on CUB-Birds. Our code and data are available at https://github.com/mvrl/VLPL.
Exploring the Potential of Generative AI for the World Wide Web
Oct 26, 2023Generative Artificial Intelligence (AI) is a cutting-edge technology capable of producing text, images, and various media content leveraging generative models and user prompts. Between 2022 and 2023, generative AI surged in popularity with a plethora of applications spanning from AI-powered movies to chatbots. In this paper, we delve into the potential of generative AI within the realm of the World Wide Web, specifically focusing on image generation. Web developers already harness generative AI to help crafting text and images, while Web browsers might use it in the future to locally generate images for tasks like repairing broken webpages, conserving bandwidth, and enhancing privacy. To explore this research area, we have developed WebDiffusion, a tool that allows to simulate a Web powered by stable diffusion, a popular text-to-image model, from both a client and server perspective. WebDiffusion further supports crowdsourcing of user opinions, which we use to evaluate the quality and accuracy of 409 AI-generated images sourced from 60 webpages. Our findings suggest that generative AI is already capable of producing pertinent and high-quality Web images, even without requiring Web designers to manually input prompts, just by leveraging contextual information available within the webpages. However, we acknowledge that direct in-browser image generation remains a challenge, as only highly powerful GPUs, such as the A40 and A100, can (partially) compete with classic image downloads. Nevertheless, this approach could be valuable for a subset of the images, for example when fixing broken webpages or handling highly private content.
Context Does Matter: End-to-end Panoptic Narrative Grounding with Deformable Attention Refined Matching Network
Oct 25, 2023Panoramic Narrative Grounding (PNG) is an emerging visual grounding task that aims to segment visual objects in images based on dense narrative captions. The current state-of-the-art methods first refine the representation of phrase by aggregating the most similar $k$ image pixels, and then match the refined text representations with the pixels of the image feature map to generate segmentation results. However, simply aggregating sampled image features ignores the contextual information, which can lead to phrase-to-pixel mis-match. In this paper, we propose a novel learning framework called Deformable Attention Refined Matching Network (DRMN), whose main idea is to bring deformable attention in the iterative process of feature learning to incorporate essential context information of different scales of pixels. DRMN iteratively re-encodes pixels with the deformable attention network after updating the feature representation of the top-$k$ most similar pixels. As such, DRMN can lead to accurate yet discriminative pixel representations, purify the top-$k$ most similar pixels, and consequently alleviate the phrase-to-pixel mis-match substantially.Experimental results show that our novel design significantly improves the matching results between text phrases and image pixels. Concretely, DRMN achieves new state-of-the-art performance on the PNG benchmark with an average recall improvement 3.5%. The codes are available in: https://github.com/JaMesLiMers/DRMN.
Medical Image Segmentation with Belief Function Theory and Deep Learning
Sep 12, 2023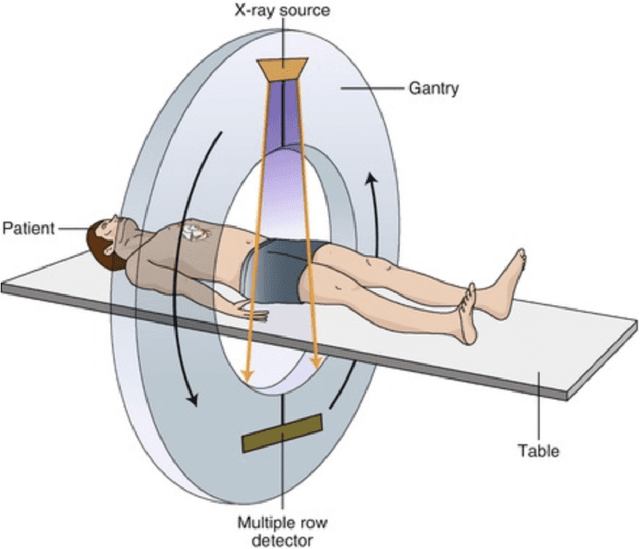
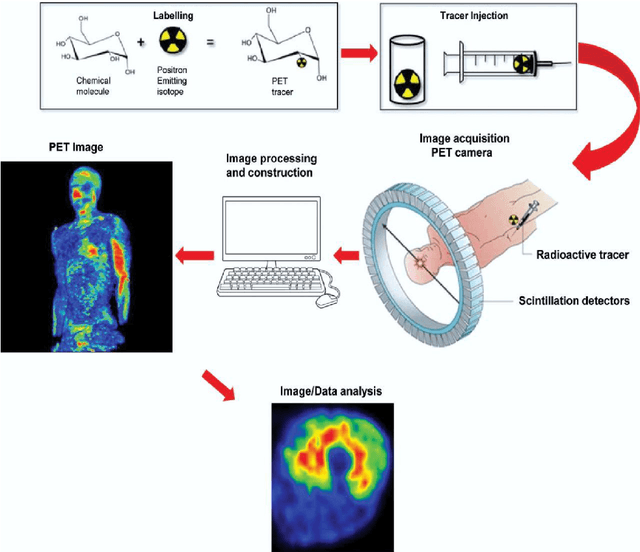
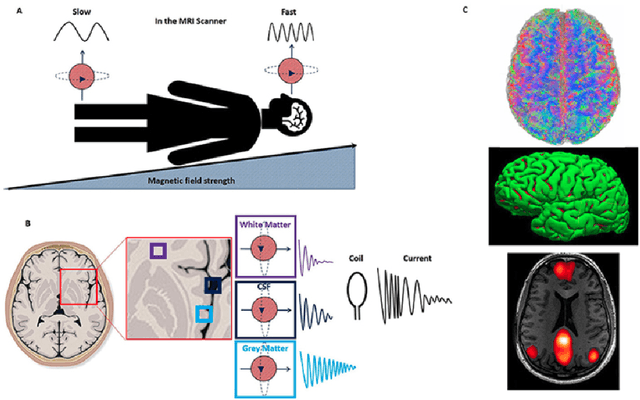
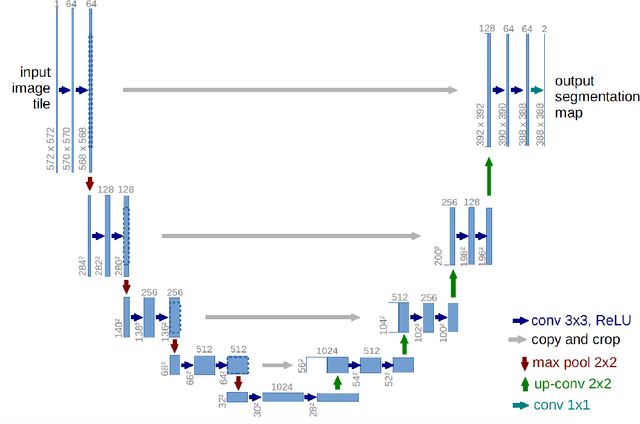
Deep learning has shown promising contributions in medical image segmentation with powerful learning and feature representation abilities. However, it has limitations for reasoning with and combining imperfect (imprecise, uncertain, and partial) information. In this thesis, we study medical image segmentation approaches with belief function theory and deep learning, specifically focusing on information modeling and fusion based on uncertain evidence. First, we review existing belief function theory-based medical image segmentation methods and discuss their advantages and challenges. Second, we present a semi-supervised medical image segmentation framework to decrease the uncertainty caused by the lack of annotations with evidential segmentation and evidence fusion. Third, we compare two evidential classifiers, evidential neural network and radial basis function network, and show the effectiveness of belief function theory in uncertainty quantification; we use the two evidential classifiers with deep neural networks to construct deep evidential models for lymphoma segmentation. Fourth, we present a multimodal medical image fusion framework taking into account the reliability of each MR image source when performing different segmentation tasks using mass functions and contextual discounting.
SSPFusion: A Semantic Structure-Preserving Approach for Infrared and Visible Image Fusion
Sep 26, 2023
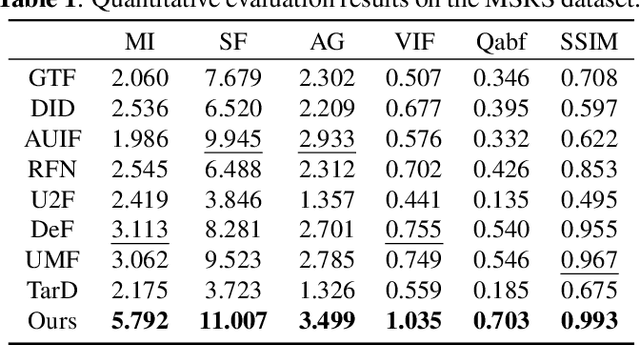
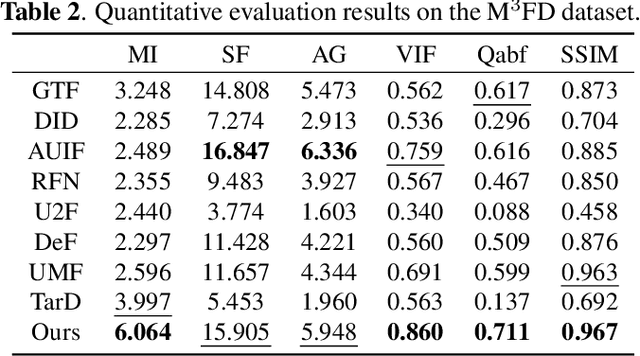
Most existing learning-based infrared and visible image fusion (IVIF) methods exhibit massive redundant information in the fusion images, i.e., yielding edge-blurring effect or unrecognizable for object detectors. To alleviate these issues, we propose a semantic structure-preserving approach for IVIF, namely SSPFusion. At first, we design a Structural Feature Extractor (SFE) to extract the structural features of infrared and visible images. Then, we introduce a multi-scale Structure-Preserving Fusion (SPF) module to fuse the structural features of infrared and visible images, while maintaining the consistency of semantic structures between the fusion and source images. Owing to these two effective modules, our method is able to generate high-quality fusion images from pairs of infrared and visible images, which can boost the performance of downstream computer-vision tasks. Experimental results on three benchmarks demonstrate that our method outperforms eight state-of-the-art image fusion methods in terms of both qualitative and quantitative evaluations. The code for our method, along with additional comparison results, will be made available at: https://github.com/QiaoYang-CV/SSPFUSION.
Multi-Agent 3D Map Reconstruction and Change Detection in Microgravity with Free-Flying Robots
Nov 05, 2023Assistive free-flyer robots autonomously caring for future crewed outposts -- such as NASA's Astrobee robots on the International Space Station (ISS) -- must be able to detect day-to-day interior changes to track inventory, detect and diagnose faults, and monitor the outpost status. This work presents a framework for multi-agent cooperative mapping and change detection to enable robotic maintenance of space outposts. One agent is used to reconstruct a 3D model of the environment from sequences of images and corresponding depth information. Another agent is used to periodically scan the environment for inconsistencies against the 3D model. Change detection is validated after completing the surveys using real image and pose data collected by Astrobee robots in a ground testing environment and from microgravity aboard the ISS. This work outlines the objectives, requirements, and algorithmic modules for the multi-agent reconstruction system, including recommendations for its use by assistive free-flyers aboard future microgravity outposts.
PotholeGuard: A Pothole Detection Approach by Point Cloud Semantic Segmentation
Nov 05, 2023Pothole detection is crucial for road safety and maintenance, traditionally relying on 2D image segmentation. However, existing 3D Semantic Pothole Segmentation research often overlooks point cloud sparsity, leading to suboptimal local feature capture and segmentation accuracy. Our research presents an innovative point cloud-based pothole segmentation architecture. Our model efficiently identifies hidden features and uses a feedback mechanism to enhance local characteristics, improving feature presentation. We introduce a local relationship learning module to understand local shape relationships, enhancing structural insights. Additionally, we propose a lightweight adaptive structure for refining local point features using the K nearest neighbor algorithm, addressing point cloud density differences and domain selection. Shared MLP Pooling is integrated to learn deep aggregation features, facilitating semantic data exploration and segmentation guidance. Extensive experiments on three public datasets confirm PotholeGuard's superior performance over state-of-the-art methods. Our approach offers a promising solution for robust and accurate 3D pothole segmentation, with applications in road maintenance and safety.
Overview of ImageArg-2023: The First Shared Task in Multimodal Argument Mining
Oct 24, 2023This paper presents an overview of the ImageArg shared task, the first multimodal Argument Mining shared task co-located with the 10th Workshop on Argument Mining at EMNLP 2023. The shared task comprises two classification subtasks - (1) Subtask-A: Argument Stance Classification; (2) Subtask-B: Image Persuasiveness Classification. The former determines the stance of a tweet containing an image and a piece of text toward a controversial topic (e.g., gun control and abortion). The latter determines whether the image makes the tweet text more persuasive. The shared task received 31 submissions for Subtask-A and 21 submissions for Subtask-B from 9 different teams across 6 countries. The top submission in Subtask-A achieved an F1-score of 0.8647 while the best submission in Subtask-B achieved an F1-score of 0.5561.
Implicit Neural Image Stitching With Enhanced and Blended Feature Reconstruction
Sep 12, 2023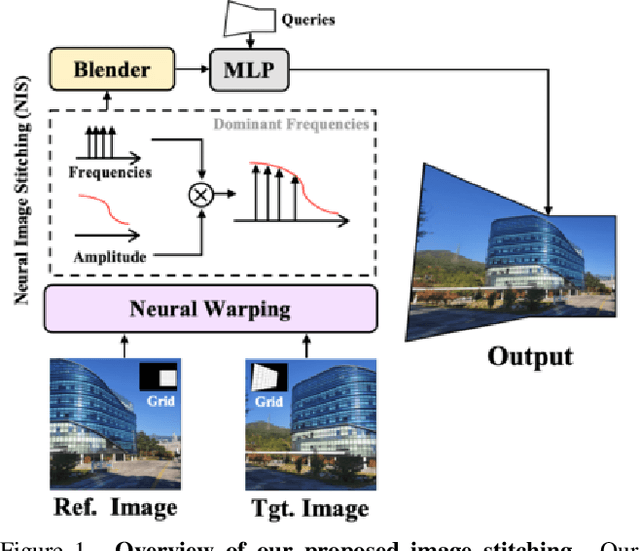
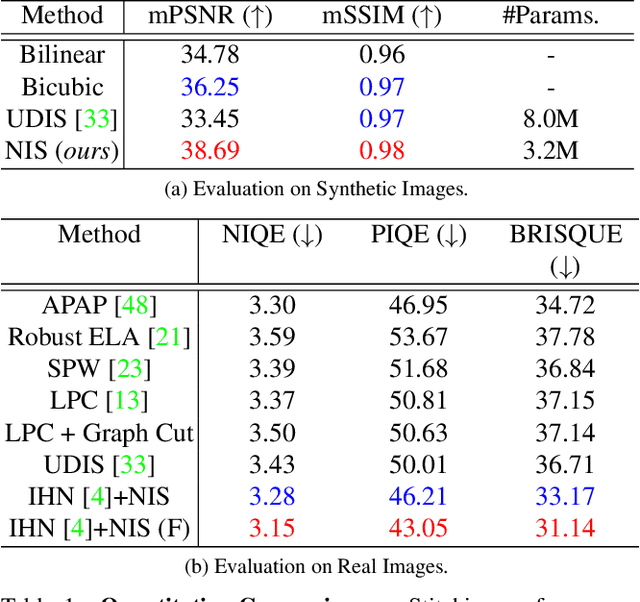

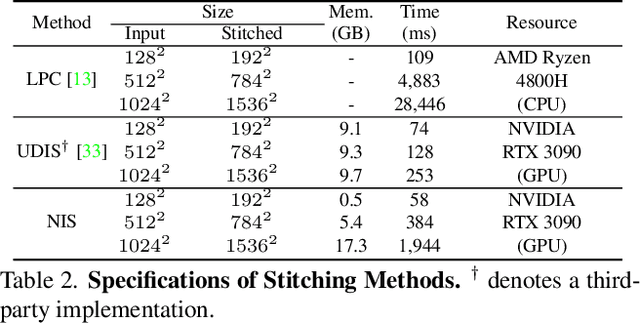
Existing frameworks for image stitching often provide visually reasonable stitchings. However, they suffer from blurry artifacts and disparities in illumination, depth level, etc. Although the recent learning-based stitchings relax such disparities, the required methods impose sacrifice of image qualities failing to capture high-frequency details for stitched images. To address the problem, we propose a novel approach, implicit Neural Image Stitching (NIS) that extends arbitrary-scale super-resolution. Our method estimates Fourier coefficients of images for quality-enhancing warps. Then, the suggested model blends color mismatches and misalignment in the latent space and decodes the features into RGB values of stitched images. Our experiments show that our approach achieves improvement in resolving the low-definition imaging of the previous deep image stitching with favorable accelerated image-enhancing methods. Our source code is available at https://github.com/minshu-kim/NIS.
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors
Oct 18, 2023Enhancing a still image with motion offers more engaged visual experience. Traditional image animation techniques mainly focus on animating natural scenes with random dynamics, such as clouds and fluid, and thus limits their applicability to generic visual contents. To overcome this limitation, we explore the synthesis of dynamic content for open-domain images, converting them into animated videos. The key idea is to utilize the motion prior of text-to-video diffusion models by incorporating the image into the generative process as guidance. Given an image, we first project it into a text-aligned rich image embedding space using a learnable image encoding network, which facilitates the video model to digest the image content compatibly. However, some visual details still struggle to be preserved in the resulting videos. To supplement more precise image information, we further feed the full image to the diffusion model by concatenating it with the initial noises. Experimental results reveal that our proposed method produces visually convincing animated videos, exhibiting both natural motions and high fidelity to the input image. Comparative evaluation demonstrates the notable superiority of our approach over existing competitors. The source code will be released upon publication.