 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntention-Adaptive LLM Fine-Tuning for Text Revision Generation
Jan 31, 2026Large Language Models (LLMs) have achieved impressive capabilities in various context-based text generation tasks, such as summarization and reasoning; however, their applications in intention-based generation tasks remain underexplored. One such example is revision generation, which requires the generated text to explicitly reflect the writer's actual intentions. Identifying intentions and generating desirable revisions are challenging due to their complex and diverse nature. Although prior work has employed LLMs to generate revisions with few-shot learning, they struggle with handling entangled multi-intent scenarios. While fine-tuning LLMs using intention-based instructions appears promising, it demands large amounts of annotated data, which is expensive and scarce in the revision community. To address these challenges, we propose Intention-Tuning, an intention-adaptive layer-wise LLM fine-tuning framework that dynamically selects a subset of LLM layers to learn the intentions and subsequently transfers their representations to revision generation. Experimental results suggest that Intention-Tuning is effective and efficient on small revision corpora, outperforming several PEFT baselines.
eRevise+RF: A Writing Evaluation System for Assessing Student Essay Revisions and Providing Formative Feedback
Jan 01, 2025



The ability to revise essays in response to feedback is important for students' writing success. An automated writing evaluation (AWE) system that supports students in revising their essays is thus essential. We present eRevise+RF, an enhanced AWE system for assessing student essay revisions (e.g., changes made to an essay to improve its quality in response to essay feedback) and providing revision feedback. We deployed the system with 6 teachers and 406 students across 3 schools in Pennsylvania and Louisiana. The results confirmed its effectiveness in (1) assessing student essays in terms of evidence usage, (2) extracting evidence and reasoning revisions across essays, and (3) determining revision success in responding to feedback. The evaluation also suggested eRevise+RF is a helpful system for young students to improve their argumentative writing skills through revision and formative feedback.
LogicPrpBank: A Corpus for Logical Implication and Equivalence
Feb 14, 2024



Logic reasoning has been critically needed in problem-solving and decision-making. Although Language Models (LMs) have demonstrated capabilities of handling multiple reasoning tasks (e.g., commonsense reasoning), their ability to reason complex mathematical problems, specifically propositional logic, remains largely underexplored. This lack of exploration can be attributed to the limited availability of annotated corpora. Here, we present a well-labeled propositional logic corpus, LogicPrpBank, containing 7093 Propositional Logic Statements (PLSs) across six mathematical subjects, to study a brand-new task of reasoning logical implication and equivalence. We benchmark LogicPrpBank with widely-used LMs to show that our corpus offers a useful resource for this challenging task and there is ample room for model improvement.
Overview of ImageArg-2023: The First Shared Task in Multimodal Argument Mining
Oct 24, 2023This paper presents an overview of the ImageArg shared task, the first multimodal Argument Mining shared task co-located with the 10th Workshop on Argument Mining at EMNLP 2023. The shared task comprises two classification subtasks - (1) Subtask-A: Argument Stance Classification; (2) Subtask-B: Image Persuasiveness Classification. The former determines the stance of a tweet containing an image and a piece of text toward a controversial topic (e.g., gun control and abortion). The latter determines whether the image makes the tweet text more persuasive. The shared task received 31 submissions for Subtask-A and 21 submissions for Subtask-B from 9 different teams across 6 countries. The top submission in Subtask-A achieved an F1-score of 0.8647 while the best submission in Subtask-B achieved an F1-score of 0.5561.
Ticket-BERT: Labeling Incident Management Tickets with Language Models
Jun 30, 2023An essential aspect of prioritizing incident tickets for resolution is efficiently labeling tickets with fine-grained categories. However, ticket data is often complex and poses several unique challenges for modern machine learning methods: (1) tickets are created and updated either by machines with pre-defined algorithms or by engineers with domain expertise that share different protocols, (2) tickets receive frequent revisions that update ticket status by modifying all or parts of ticket descriptions, and (3) ticket labeling is time-sensitive and requires knowledge updates and new labels per the rapid software and hardware improvement lifecycle. To handle these issues, we introduce Ticket- BERT which trains a simple yet robust language model for labeling tickets using our proposed ticket datasets. Experiments demonstrate the superiority of Ticket-BERT over baselines and state-of-the-art text classifiers on Azure Cognitive Services. We further encapsulate Ticket-BERT with an active learning cycle and deploy it on the Microsoft IcM system, which enables the model to quickly finetune on newly-collected tickets with a few annotations.
Predicting the Quality of Revisions in Argumentative Writing
Jun 01, 2023



The ability to revise in response to feedback is critical to students' writing success. In the case of argument writing in specific, identifying whether an argument revision (AR) is successful or not is a complex problem because AR quality is dependent on the overall content of an argument. For example, adding the same evidence sentence could strengthen or weaken existing claims in different argument contexts (ACs). To address this issue we developed Chain-of-Thought prompts to facilitate ChatGPT-generated ACs for AR quality predictions. The experiments on two corpora, our annotated elementary essays and existing college essays benchmark, demonstrate the superiority of the proposed ACs over baselines.
Task-Adaptive Meta-Learning Framework for Advancing Spatial Generalizability
Dec 10, 2022



Spatio-temporal machine learning is critically needed for a variety of societal applications, such as agricultural monitoring, hydrological forecast, and traffic management. These applications greatly rely on regional features that characterize spatial and temporal differences. However, spatio-temporal data are often complex and pose several unique challenges for machine learning models: 1) multiple models are needed to handle region-based data patterns that have significant spatial heterogeneity across different locations; 2) local models trained on region-specific data have limited ability to adapt to other regions that have large diversity and abnormality; 3) spatial and temporal variations entangle data complexity that requires more robust and adaptive models; 4) limited spatial-temporal data in real scenarios (e.g., crop yield data is collected only once a year) makes the problems intrinsically challenging. To bridge these gaps, we propose task-adaptive formulations and a model-agnostic meta-learning framework that ensembles regionally heterogeneous data into location-sensitive meta tasks. We conduct task adaptation following an easy-to-hard task hierarchy in which different meta models are adapted to tasks of different difficulty levels. One major advantage of our proposed method is that it improves the model adaptation to a large number of heterogeneous tasks. It also enhances the model generalization by automatically adapting the meta model of the corresponding difficulty level to any new tasks. We demonstrate the superiority of our proposed framework over a diverse set of baselines and state-of-the-art meta-learning frameworks. Our extensive experiments on real crop yield data show the effectiveness of the proposed method in handling spatial-related heterogeneous tasks in real societal applications.
ImageArg: A Multi-modal Tweet Dataset for Image Persuasiveness Mining
Sep 14, 2022


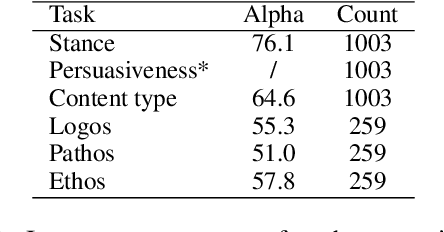
The growing interest in developing corpora of persuasive texts has promoted applications in automated systems, e.g., debating and essay scoring systems; however, there is little prior work mining image persuasiveness from an argumentative perspective. To expand persuasiveness mining into a multi-modal realm, we present a multi-modal dataset, ImageArg, consisting of annotations of image persuasiveness in tweets. The annotations are based on a persuasion taxonomy we developed to explore image functionalities and the means of persuasion. We benchmark image persuasiveness tasks on ImageArg using widely-used multi-modal learning methods. The experimental results show that our dataset offers a useful resource for this rich and challenging topic, and there is ample room for modeling improvement.
Anatomy-Guided Weakly-Supervised Abnormality Localization in Chest X-rays
Jun 25, 2022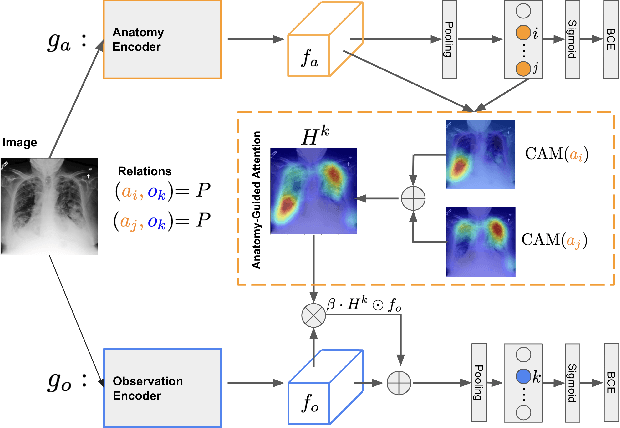
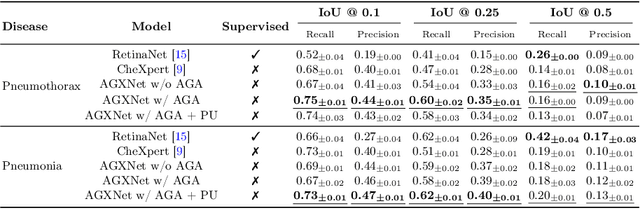
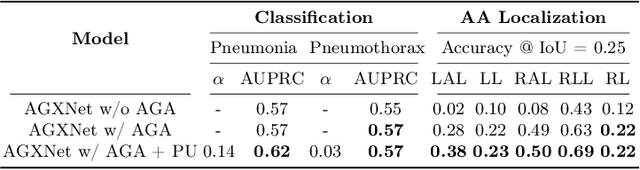
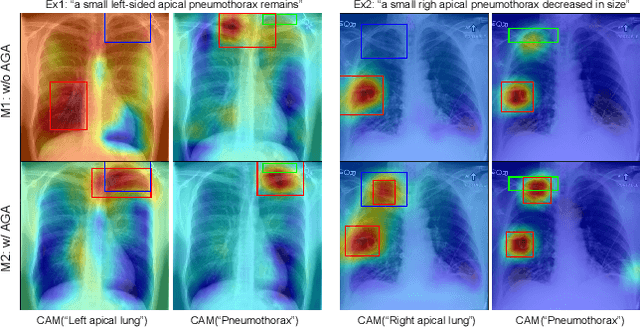
Creating a large-scale dataset of abnormality annotation on medical images is a labor-intensive and costly task. Leveraging weak supervision from readily available data such as radiology reports can compensate lack of large-scale data for anomaly detection methods. However, most of the current methods only use image-level pathological observations, failing to utilize the relevant anatomy mentions in reports. Furthermore, Natural Language Processing (NLP)-mined weak labels are noisy due to label sparsity and linguistic ambiguity. We propose an Anatomy-Guided chest X-ray Network (AGXNet) to address these issues of weak annotation. Our framework consists of a cascade of two networks, one responsible for identifying anatomical abnormalities and the second responsible for pathological observations. The critical component in our framework is an anatomy-guided attention module that aids the downstream observation network in focusing on the relevant anatomical regions generated by the anatomy network. We use Positive Unlabeled (PU) learning to account for the fact that lack of mention does not necessarily mean a negative label. Our quantitative and qualitative results on the MIMIC-CXR dataset demonstrate the effectiveness of AGXNet in disease and anatomical abnormality localization. Experiments on the NIH Chest X-ray dataset show that the learned feature representations are transferable and can achieve the state-of-the-art performances in disease classification and competitive disease localization results. Our code is available at https://github.com/batmanlab/AGXNet
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).