 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Nepotistically Trained Generative-AI Models Collapse
Nov 20, 2023


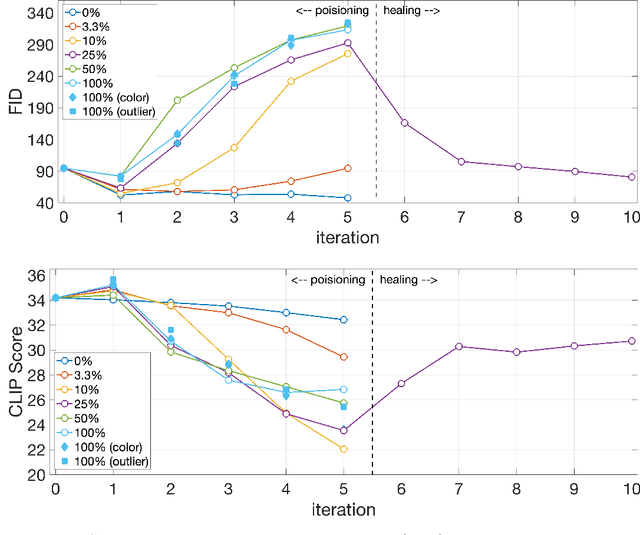
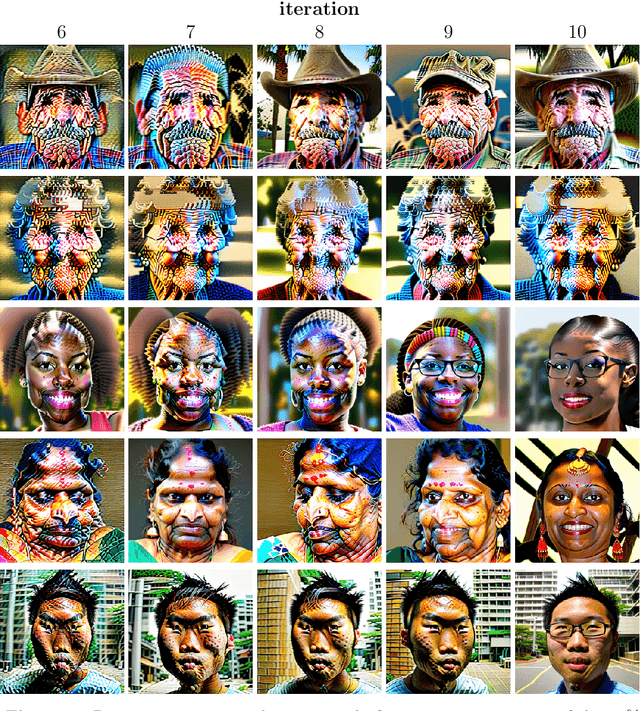
Trained on massive amounts of human-generated content, AI (artificial intelligence) image synthesis is capable of reproducing semantically coherent images that match the visual appearance of its training data. We show that when retrained on even small amounts of their own creation, these generative-AI models produce highly distorted images. We also show that this distortion extends beyond the text prompts used in retraining, and that once poisoned, the models struggle to fully heal even after retraining on only real images.
IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts
Oct 09, 2023
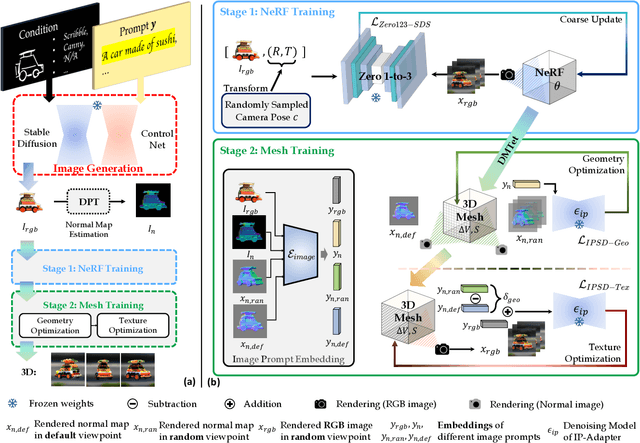


Recent advances in text-to-3D generation have been remarkable, with methods such as DreamFusion leveraging large-scale text-to-image diffusion-based models to supervise 3D generation. These methods, including the variational score distillation proposed by ProlificDreamer, enable the synthesis of detailed and photorealistic textured meshes. However, the appearance of 3D objects generated by these methods is often random and uncontrollable, posing a challenge in achieving appearance-controllable 3D objects. To address this challenge, we introduce IPDreamer, a novel approach that incorporates image prompts to provide specific and comprehensive appearance information for 3D object generation. Our results demonstrate that IPDreamer effectively generates high-quality 3D objects that are consistent with both the provided text and image prompts, demonstrating its promising capability in appearance-controllable 3D object generation.
CPSeg: Finer-grained Image Semantic Segmentation via Chain-of-Thought Language Prompting
Oct 26, 2023
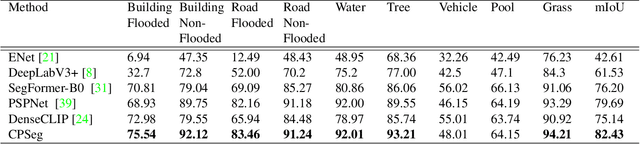


Natural scene analysis and remote sensing imagery offer immense potential for advancements in large-scale language-guided context-aware data utilization. This potential is particularly significant for enhancing performance in downstream tasks such as object detection and segmentation with designed language prompting. In light of this, we introduce the CPSeg, Chain-of-Thought Language Prompting for Finer-grained Semantic Segmentation), an innovative framework designed to augment image segmentation performance by integrating a novel "Chain-of-Thought" process that harnesses textual information associated with images. This groundbreaking approach has been applied to a flood disaster scenario. CPSeg encodes prompt texts derived from various sentences to formulate a coherent chain-of-thought. We propose a new vision-language dataset, FloodPrompt, which includes images, semantic masks, and corresponding text information. This not only strengthens the semantic understanding of the scenario but also aids in the key task of semantic segmentation through an interplay of pixel and text matching maps. Our qualitative and quantitative analyses validate the effectiveness of CPSeg.
Zero-Shot Segmentation of Eye Features Using the Segment Anything Model (SAM)
Nov 14, 2023The advent of foundation models signals a new era in artificial intelligence. The Segment Anything Model (SAM) is the first foundation model for image segmentation. In this study, we evaluate SAM's ability to segment features from eye images recorded in virtual reality setups. The increasing requirement for annotated eye-image datasets presents a significant opportunity for SAM to redefine the landscape of data annotation in gaze estimation. Our investigation centers on SAM's zero-shot learning abilities and the effectiveness of prompts like bounding boxes or point clicks. Our results are consistent with studies in other domains, demonstrating that SAM's segmentation effectiveness can be on-par with specialized models depending on the feature, with prompts improving its performance, evidenced by an IoU of 93.34% for pupil segmentation in one dataset. Foundation models like SAM could revolutionize gaze estimation by enabling quick and easy image segmentation, reducing reliance on specialized models and extensive manual annotation.
Cattle Identification Using Muzzle Images and Deep Learning Techniques
Nov 14, 2023Traditional animal identification methods such as ear-tagging, ear notching, and branding have been effective but pose risks to the animal and have scalability issues. Electrical methods offer better tracking and monitoring but require specialized equipment and are susceptible to attacks. Biometric identification using time-immutable dermatoglyphic features such as muzzle prints and iris patterns is a promising solution. This project explores cattle identification using 4923 muzzle images collected from 268 beef cattle. Two deep learning classification models are implemented - wide ResNet50 and VGG16\_BN and image compression is done to lower the image quality and adapt the models to work for the African context. From the experiments run, a maximum accuracy of 99.5\% is achieved while using the wide ResNet50 model with a compression retaining 25\% of the original image. From the study, it is noted that the time required by the models to train and converge as well as recognition time are dependent on the machine used to run the model.
3D-GOI: 3D GAN Omni-Inversion for Multifaceted and Multi-object Editing
Nov 18, 2023The current GAN inversion methods typically can only edit the appearance and shape of a single object and background while overlooking spatial information. In this work, we propose a 3D editing framework, 3D-GOI, to enable multifaceted editing of affine information (scale, translation, and rotation) on multiple objects. 3D-GOI realizes the complex editing function by inverting the abundance of attribute codes (object shape/appearance/scale/rotation/translation, background shape/appearance, and camera pose) controlled by GIRAFFE, a renowned 3D GAN. Accurately inverting all the codes is challenging, 3D-GOI solves this challenge following three main steps. First, we segment the objects and the background in a multi-object image. Second, we use a custom Neural Inversion Encoder to obtain coarse codes of each object. Finally, we use a round-robin optimization algorithm to get precise codes to reconstruct the image. To the best of our knowledge, 3D-GOI is the first framework to enable multifaceted editing on multiple objects. Both qualitative and quantitative experiments demonstrate that 3D-GOI holds immense potential for flexible, multifaceted editing in complex multi-object scenes.
Continual Learning of Diffusion Models with Generative Distillation
Nov 23, 2023Diffusion models are powerful generative models that achieve state-of-the-art performance in tasks such as image synthesis. However, training them demands substantial amounts of data and computational resources. Continual learning would allow for incrementally learning new tasks and accumulating knowledge, thus reusing already trained models would be possible. One potentially suitable approach is generative replay, where a copy of a generative model trained on previous tasks produces synthetic data that are interleaved with data from the current task. However, standard generative replay applied to diffusion models results in a catastrophic loss in denoising capabilities. In this paper, we propose generative distillation, an approach that distils the entire reverse process of a diffusion model. We demonstrate that our approach significantly improves the continual learning performance of generative replay with only a moderate increase in the computational costs.
Level Set KSVD
Nov 14, 2023We present a new algorithm for image segmentation - Level-set KSVD. Level-set KSVD merges the methods of sparse dictionary learning for feature extraction and variational level-set method for image segmentation. Specifically, we use a generalization of the Chan-Vese functional with features learned by KSVD. The motivation for this model is agriculture based. Aerial images are taken in order to detect the spread of fungi in various crops. Our model is tested on such images of cotton fields. The results are compared to other methods.
Ultrafast 3-D Super Resolution Ultrasound using Row-Column Array specific Coherence-based Beamforming and Rolling Acoustic Sub-aperture Processing: In Vitro, In Vivo and Clinical Study
Nov 15, 2023The row-column addressed array is an emerging probe for ultrafast 3-D ultrasound imaging. It achieves this with far fewer independent electronic channels and a wider field of view than traditional 2-D matrix arrays, of the same channel count, making it a good candidate for clinical translation. However, the image quality of row-column arrays is generally poor, particularly when investigating tissue. Ultrasound localisation microscopy allows for the production of super-resolution images even when the initial image resolution is not high. Unfortunately, the row-column probe can suffer from imaging artefacts that can degrade the quality of super-resolution images as `secondary' lobes from bright microbubbles can be mistaken as microbubble events, particularly when operated using plane wave imaging. These false events move through the image in a physiologically realistic way so can be challenging to remove via tracking, leading to the production of 'false vessels'. Here, a new type of rolling window image reconstruction procedure was developed, which integrated a row-column array-specific coherence-based beamforming technique with acoustic sub-aperture processing for the purposes of reducing `secondary' lobe artefacts, noise and increasing the effective frame rate. Using an {\it{in vitro}} cross tube, it was found that the procedure reduced the percentage of `false' locations from $\sim$26\% to $\sim$15\% compared to traditional orthogonal plane wave compounding. Additionally, it was found that the noise could be reduced by $\sim$7 dB and that the effective frame rate could be increased to over 4000 fps. Subsequently, {\it{in vivo}} ultrasound localisation microscopy was used to produce images non-invasively of a rabbit kidney and a human thyroid.
FastBlend: a Powerful Model-Free Toolkit Making Video Stylization Easier
Nov 15, 2023With the emergence of diffusion models and rapid development in image processing, it has become effortless to generate fancy images in tasks such as style transfer and image editing. However, these impressive image processing approaches face consistency issues in video processing. In this paper, we propose a powerful model-free toolkit called FastBlend to address the consistency problem for video processing. Based on a patch matching algorithm, we design two inference modes, including blending and interpolation. In the blending mode, FastBlend eliminates video flicker by blending the frames within a sliding window. Moreover, we optimize both computational efficiency and video quality according to different application scenarios. In the interpolation mode, given one or more keyframes rendered by diffusion models, FastBlend can render the whole video. Since FastBlend does not modify the generation process of diffusion models, it exhibits excellent compatibility. Extensive experiments have demonstrated the effectiveness of FastBlend. In the blending mode, FastBlend outperforms existing methods for video deflickering and video synthesis. In the interpolation mode, FastBlend surpasses video interpolation and model-based video processing approaches. The source codes have been released on GitHub.