 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BiomedJourney: Counterfactual Biomedical Image Generation by Instruction-Learning from Multimodal Patient Journeys
Oct 18, 2023
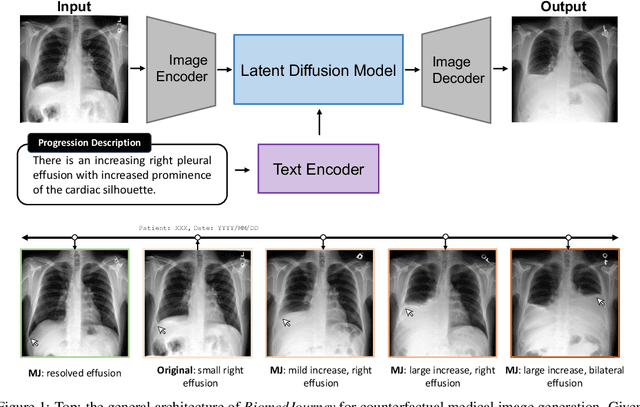
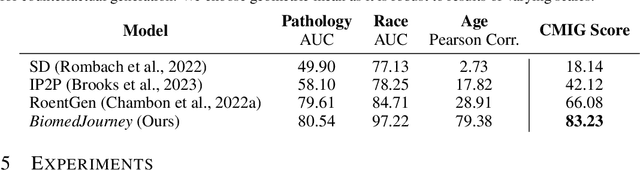
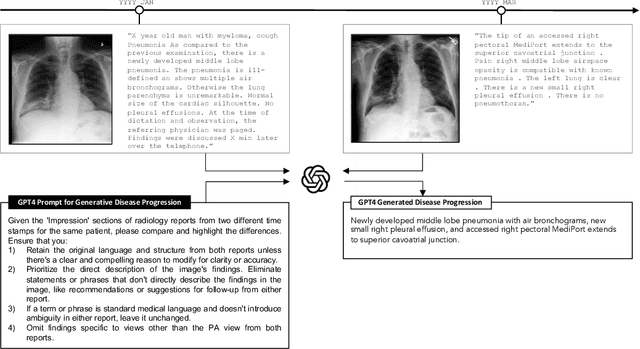
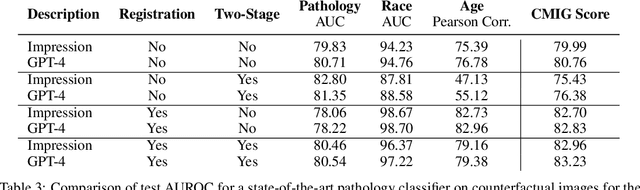
Rapid progress has been made in instruction-learning for image editing with natural-language instruction, as exemplified by InstructPix2Pix. In biomedicine, such methods can be applied to counterfactual image generation, which helps differentiate causal structure from spurious correlation and facilitate robust image interpretation for disease progression modeling. However, generic image-editing models are ill-suited for the biomedical domain, and counterfactual biomedical image generation is largely underexplored. In this paper, we present BiomedJourney, a novel method for counterfactual biomedical image generation by instruction-learning from multimodal patient journeys. Given a patient with two biomedical images taken at different time points, we use GPT-4 to process the corresponding imaging reports and generate a natural language description of disease progression. The resulting triples (prior image, progression description, new image) are then used to train a latent diffusion model for counterfactual biomedical image generation. Given the relative scarcity of image time series data, we introduce a two-stage curriculum that first pretrains the denoising network using the much more abundant single image-report pairs (with dummy prior image), and then continues training using the counterfactual triples. Experiments using the standard MIMIC-CXR dataset demonstrate the promise of our method. In a comprehensive battery of tests on counterfactual medical image generation, BiomedJourney substantially outperforms prior state-of-the-art methods in instruction image editing and medical image generation such as InstructPix2Pix and RoentGen. To facilitate future study in counterfactual medical generation, we plan to release our instruction-learning code and pretrained models.
Towards Unsupervised Representation Learning: Learning, Evaluating and Transferring Visual Representations
Nov 30, 2023Unsupervised representation learning aims at finding methods that learn representations from data without annotation-based signals. Abstaining from annotations not only leads to economic benefits but may - and to some extent already does - result in advantages regarding the representation's structure, robustness, and generalizability to different tasks. In the long run, unsupervised methods are expected to surpass their supervised counterparts due to the reduction of human intervention and the inherently more general setup that does not bias the optimization towards an objective originating from specific annotation-based signals. While major advantages of unsupervised representation learning have been recently observed in natural language processing, supervised methods still dominate in vision domains for most tasks. In this dissertation, we contribute to the field of unsupervised (visual) representation learning from three perspectives: (i) Learning representations: We design unsupervised, backpropagation-free Convolutional Self-Organizing Neural Networks (CSNNs) that utilize self-organization- and Hebbian-based learning rules to learn convolutional kernels and masks to achieve deeper backpropagation-free models. (ii) Evaluating representations: We build upon the widely used (non-)linear evaluation protocol to define pretext- and target-objective-independent metrics for measuring and investigating the objective function mismatch between various unsupervised pretext tasks and target tasks. (iii) Transferring representations: We contribute CARLANE, the first 3-way sim-to-real domain adaptation benchmark for 2D lane detection, and a method based on prototypical self-supervised learning. Finally, we contribute a content-consistent unpaired image-to-image translation method that utilizes masks, global and local discriminators, and similarity sampling to mitigate content inconsistencies.
GeoDream: Disentangling 2D and Geometric Priors for High-Fidelity and Consistent 3D Generation
Nov 29, 2023Text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models has shown great promise but still suffers from inconsistent 3D geometric structures (Janus problems) and severe artifacts. The aforementioned problems mainly stem from 2D diffusion models lacking 3D awareness during the lifting. In this work, we present GeoDream, a novel method that incorporates explicit generalized 3D priors with 2D diffusion priors to enhance the capability of obtaining unambiguous 3D consistent geometric structures without sacrificing diversity or fidelity. Specifically, we first utilize a multi-view diffusion model to generate posed images and then construct cost volume from the predicted image, which serves as native 3D geometric priors, ensuring spatial consistency in 3D space. Subsequently, we further propose to harness 3D geometric priors to unlock the great potential of 3D awareness in 2D diffusion priors via a disentangled design. Notably, disentangling 2D and 3D priors allows us to refine 3D geometric priors further. We justify that the refined 3D geometric priors aid in the 3D-aware capability of 2D diffusion priors, which in turn provides superior guidance for the refinement of 3D geometric priors. Our numerical and visual comparisons demonstrate that GeoDream generates more 3D consistent textured meshes with high-resolution realistic renderings (i.e., 1024 $\times$ 1024) and adheres more closely to semantic coherence.
Towards Top-Down Reasoning: An Explainable Multi-Agent Approach for Visual Question Answering
Nov 29, 2023Recently, Vision Language Models (VLMs) have gained significant attention, exhibiting notable advancements across various tasks by leveraging extensive image-text paired data. However, prevailing VLMs often treat Visual Question Answering (VQA) as perception tasks, employing black-box models that overlook explicit modeling of relationships between different questions within the same visual scene. Moreover, the existing VQA methods that rely on Knowledge Bases (KBs) might frequently encounter biases from limited data and face challenges in relevant information indexing. Attempt to overcome these limitations, this paper introduces an explainable multi-agent collaboration framework by tapping into knowledge embedded in Large Language Models (LLMs) trained on extensive corpora. Inspired by human cognition, our framework uncovers latent information within the given question by employing three agents, i.e., Seeker, Responder, and Integrator, to perform a top-down reasoning process. The Seeker agent generates relevant issues related to the original question. The Responder agent, based on VLM, handles simple VQA tasks and provides candidate answers. The Integrator agent combines information from the Seeker agent and the Responder agent to produce the final VQA answer. Through the above collaboration mechanism, our framework explicitly constructs a multi-view knowledge base for a specific image scene, reasoning answers in a top-down processing manner. We extensively evaluate our method on diverse VQA datasets and VLMs, demonstrating its broad applicability and interpretability with comprehensive experimental results.
Explaining CLIP's performance disparities on data from blind/low vision users
Nov 29, 2023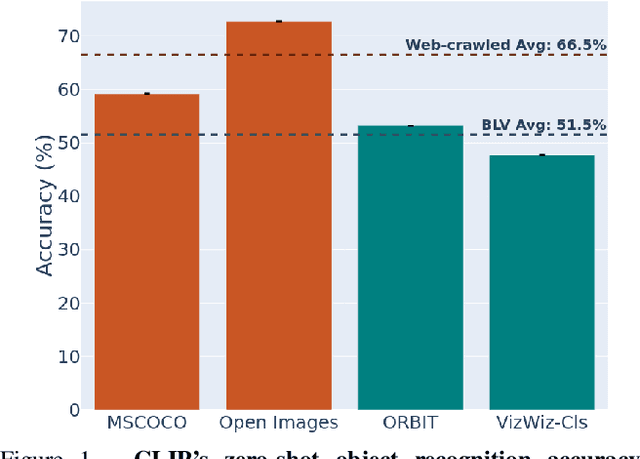
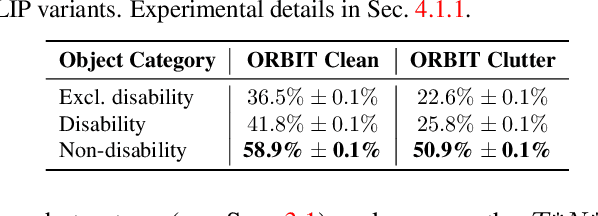
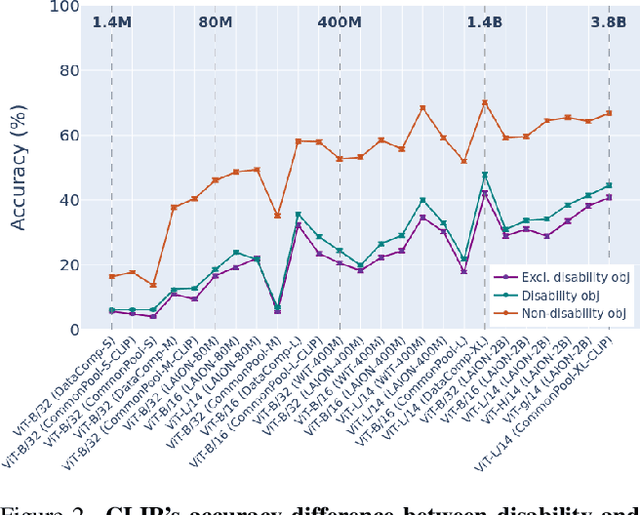
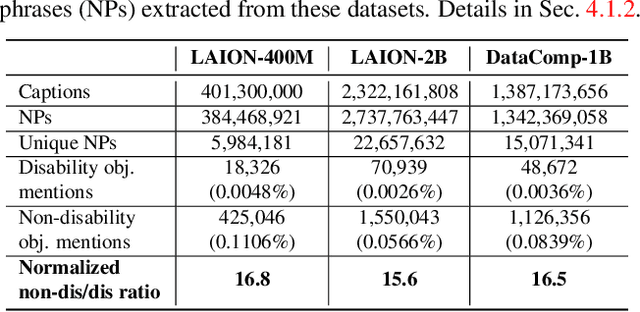
Large multi-modal models (LMMs) hold the potential to usher in a new era of automated visual assistance for people who are blind or low vision (BLV). Yet, these models have not been systematically evaluated on data captured by BLV users. We address this by empirically assessing CLIP, a widely-used LMM likely to underpin many assistive technologies. Testing 25 CLIP variants in a zero-shot classification task, we find that their accuracy is 15 percentage points lower on average for images captured by BLV users than web-crawled images. This disparity stems from CLIP's sensitivities to 1) image content (e.g. not recognizing disability objects as well as other objects); 2) image quality (e.g. not being robust to lighting variation); and 3) text content (e.g. not recognizing objects described by tactile adjectives as well as visual ones). We delve deeper with a textual analysis of three common pre-training datasets: LAION-400M, LAION-2B and DataComp-1B, showing that disability content is rarely mentioned. We then provide three examples that illustrate how the performance disparities extend to three downstream models underpinned by CLIP: OWL-ViT, CLIPSeg and DALL-E2. We find that few-shot learning with as few as 5 images can mitigate CLIP's quality-of-service disparities for BLV users in some scenarios, which we discuss alongside a set of other possible mitigations.
PatchBMI-Net: Lightweight Facial Patch-based Ensemble for BMI Prediction
Nov 29, 2023Due to an alarming trend related to obesity affecting 93.3 million adults in the United States alone, body mass index (BMI) and body weight have drawn significant interest in various health monitoring applications. Consequently, several studies have proposed self-diagnostic facial image-based BMI prediction methods for healthy weight monitoring. These methods have mostly used convolutional neural network (CNN) based regression baselines, such as VGG19, ResNet50, and Efficient-NetB0, for BMI prediction from facial images. However, the high computational requirement of these heavy-weight CNN models limits their deployment to resource-constrained mobile devices, thus deterring weight monitoring using smartphones. This paper aims to develop a lightweight facial patch-based ensemble (PatchBMI-Net) for BMI prediction to facilitate the deployment and weight monitoring using smartphones. Extensive experiments on BMI-annotated facial image datasets suggest that our proposed PatchBMI-Net model can obtain Mean Absolute Error (MAE) in the range [3.58, 6.51] with a size of about 3.3 million parameters. On cross-comparison with heavyweight models, such as ResNet-50 and Xception, trained for BMI prediction from facial images, our proposed PatchBMI-Net obtains equivalent MAE along with the model size reduction of about 5.4x and the average inference time reduction of about 3x when deployed on Apple-14 smartphone. Thus, demonstrating performance efficiency as well as low latency for on-device deployment and weight monitoring using smartphone applications.
Image super-resolution via dynamic network
Oct 16, 2023Convolutional neural networks (CNNs) depend on deep network architectures to extract accurate information for image super-resolution. However, obtained information of these CNNs cannot completely express predicted high-quality images for complex scenes. In this paper, we present a dynamic network for image super-resolution (DSRNet), which contains a residual enhancement block, wide enhancement block, feature refinement block and construction block. The residual enhancement block is composed of a residual enhanced architecture to facilitate hierarchical features for image super-resolution. To enhance robustness of obtained super-resolution model for complex scenes, a wide enhancement block achieves a dynamic architecture to learn more robust information to enhance applicability of an obtained super-resolution model for varying scenes. To prevent interference of components in a wide enhancement block, a refinement block utilizes a stacked architecture to accurately learn obtained features. Also, a residual learning operation is embedded in the refinement block to prevent long-term dependency problem. Finally, a construction block is responsible for reconstructing high-quality images. Designed heterogeneous architecture can not only facilitate richer structural information, but also be lightweight, which is suitable for mobile digital devices. Experimental results shows that our method is more competitive in terms of performance and recovering time of image super-resolution and complexity. The code of DSRNet can be obtained at https://github.com/hellloxiaotian/DSRNet.
LION : Empowering Multimodal Large Language Model with Dual-Level Visual Knowledge
Nov 26, 2023Multimodal Large Language Models (MLLMs) have endowed LLMs with the ability to perceive and understand multi-modal signals. However, most of the existing MLLMs mainly adopt vision encoders pretrained on coarsely aligned image-text pairs, leading to insufficient extraction and reasoning of visual knowledge. To address this issue, we devise a dual-Level vIsual knOwledge eNhanced Multimodal Large Language Model (LION), which empowers the MLLM by injecting visual knowledge in two levels. 1) Progressive incorporation of fine-grained spatial-aware visual knowledge. We design a vision aggregator cooperated with region-level vision-language (VL) tasks to incorporate fine-grained spatial-aware visual knowledge into the MLLM. To alleviate the conflict between image-level and region-level VL tasks during incorporation, we devise a dedicated stage-wise instruction-tuning strategy with mixture-of-adapters. This progressive incorporation scheme contributes to the mutual promotion between these two kinds of VL tasks. 2) Soft prompting of high-level semantic visual evidence. We facilitate the MLLM with high-level semantic visual evidence by leveraging diverse image tags. To mitigate the potential influence caused by imperfect predicted tags, we propose a soft prompting method by embedding a learnable token into the tailored text instruction. Comprehensive experiments on several multi-modal benchmarks demonstrate the superiority of our model (e.g., improvement of 5% accuracy on VSR and 3% CIDEr on TextCaps over InstructBLIP, 5% accuracy on RefCOCOg over Kosmos-2).
Calibrated Uncertainties for Neural Radiance Fields
Dec 04, 2023Neural Radiance Fields have achieved remarkable results for novel view synthesis but still lack a crucial component: precise measurement of uncertainty in their predictions. Probabilistic NeRF methods have tried to address this, but their output probabilities are not typically accurately calibrated, and therefore do not capture the true confidence levels of the model. Calibration is a particularly challenging problem in the sparse-view setting, where additional held-out data is unavailable for fitting a calibrator that generalizes to the test distribution. In this paper, we introduce the first method for obtaining calibrated uncertainties from NeRF models. Our method is based on a robust and efficient metric to calculate per-pixel uncertainties from the predictive posterior distribution. We propose two techniques that eliminate the need for held-out data. The first, based on patch sampling, involves training two NeRF models for each scene. The second is a novel meta-calibrator that only requires the training of one NeRF model. Our proposed approach for obtaining calibrated uncertainties achieves state-of-the-art uncertainty in the sparse-view setting while maintaining image quality. We further demonstrate our method's effectiveness in applications such as view enhancement and next-best view selection.
Diversify, Don't Fine-Tune: Scaling Up Visual Recognition Training with Synthetic Images
Dec 04, 2023Recent advances in generative deep learning have enabled the creation of high-quality synthetic images in text-to-image generation. Prior work shows that fine-tuning a pretrained diffusion model on ImageNet and generating synthetic training images from the finetuned model can enhance an ImageNet classifier's performance. However, performance degrades as synthetic images outnumber real ones. In this paper, we explore whether generative fine-tuning is essential for this improvement and whether it is possible to further scale up training using more synthetic data. We present a new framework leveraging off-the-shelf generative models to generate synthetic training images, addressing multiple challenges: class name ambiguity, lack of diversity in naive prompts, and domain shifts. Specifically, we leverage large language models (LLMs) and CLIP to resolve class name ambiguity. To diversify images, we propose contextualized diversification (CD) and stylized diversification (SD) methods, also prompted by LLMs. Finally, to mitigate domain shifts, we leverage domain adaptation techniques with auxiliary batch normalization for synthetic images. Our framework consistently enhances recognition model performance with more synthetic data, up to 6x of original ImageNet size showcasing the potential of synthetic data for improved recognition models and strong out-of-domain generalization.