 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMFace-DiT: A Dual-Stream Diffusion Transformer for High-Fidelity Multimodal Face Generation
Mar 30, 2026Recent multimodal face generation models address the spatial control limitations of text-to-image diffusion models by augmenting text-based conditioning with spatial priors such as segmentation masks, sketches, or edge maps. This multimodal fusion enables controllable synthesis aligned with both high-level semantic intent and low-level structural layout. However, most existing approaches typically extend pre-trained text-to-image pipelines by appending auxiliary control modules or stitching together separate uni-modal networks. These ad hoc designs inherit architectural constraints, duplicate parameters, and often fail under conflicting modalities or mismatched latent spaces, limiting their ability to perform synergistic fusion across semantic and spatial domains. We introduce MMFace-DiT, a unified dual-stream diffusion transformer engineered for synergistic multimodal face synthesis. Its core novelty lies in a dual-stream transformer block that processes spatial (mask/sketch) and semantic (text) tokens in parallel, deeply fusing them through a shared Rotary Position-Embedded (RoPE) Attention mechanism. This design prevents modal dominance and ensures strong adherence to both text and structural priors to achieve unprecedented spatial-semantic consistency for controllable face generation. Furthermore, a novel Modality Embedder enables a single cohesive model to dynamically adapt to varying spatial conditions without retraining. MMFace-DiT achieves a 40% improvement in visual fidelity and prompt alignment over six state-of-the-art multimodal face generation models, establishing a flexible new paradigm for end-to-end controllable generative modeling. The code and dataset are available on our project page: https://vcbsl.github.io/MMFace-DiT/
VoxMorph: Scalable Zero-shot Voice Identity Morphing via Disentangled Embeddings
Jan 27, 2026Morphing techniques generate artificial biometric samples that combine features from multiple individuals, allowing each contributor to be verified against a single enrolled template. While extensively studied in face recognition, this vulnerability remains largely unexplored in voice biometrics. Prior work on voice morphing is computationally expensive, non-scalable, and limited to acoustically similar identity pairs, constraining practical deployment. Moreover, existing sound-morphing methods target audio textures, music, or environmental sounds and are not transferable to voice identity manipulation. We propose VoxMorph, a zero-shot framework that produces high-fidelity voice morphs from as little as five seconds of audio per subject without model retraining. Our method disentangles vocal traits into prosody and timbre embeddings, enabling fine-grained interpolation of speaking style and identity. These embeddings are fused via Spherical Linear Interpolation (Slerp) and synthesized using an autoregressive language model coupled with a Conditional Flow Matching network. VoxMorph achieves state-of-the-art performance, delivering a 2.6x gain in audio quality, a 73% reduction in intelligibility errors, and a 67.8% morphing attack success rate on automated speaker verification systems under strict security thresholds. This work establishes a practical and scalable paradigm for voice morphing with significant implications for biometric security. The code and dataset are available on our project page: https://vcbsl.github.io/VoxMorph/
DAO-GP Drift Aware Online Non-Linear Regression Gaussian-Process
Dec 09, 2025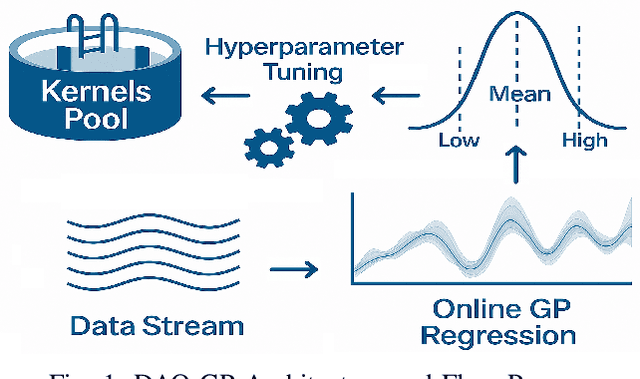
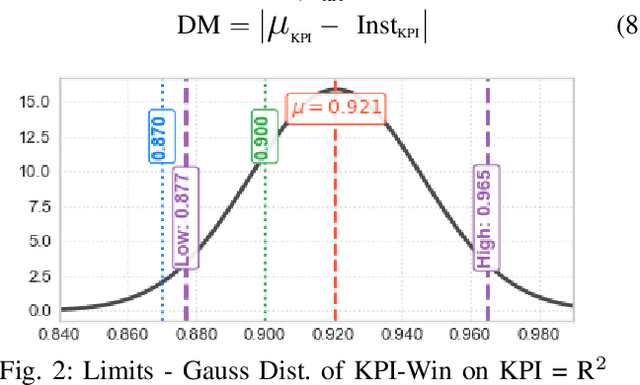
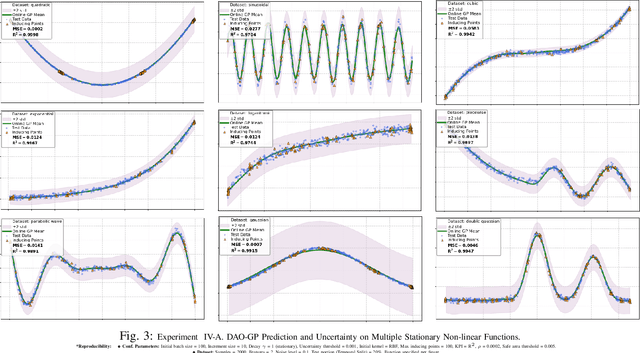
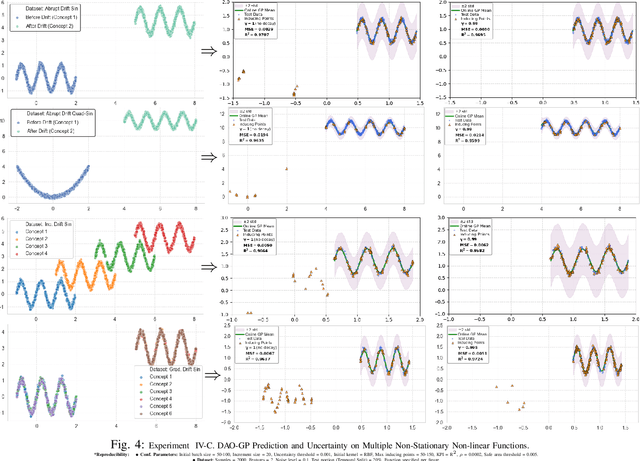
Real-world datasets often exhibit temporal dynamics characterized by evolving data distributions. Disregarding this phenomenon, commonly referred to as concept drift, can significantly diminish a model's predictive accuracy. Furthermore, the presence of hyperparameters in online models exacerbates this issue. These parameters are typically fixed and cannot be dynamically adjusted by the user in response to the evolving data distribution. Gaussian Process (GP) models offer powerful non-parametric regression capabilities with uncertainty quantification, making them ideal for modeling complex data relationships in an online setting. However, conventional online GP methods face several critical limitations, including a lack of drift-awareness, reliance on fixed hyperparameters, vulnerability to data snooping, absence of a principled decay mechanism, and memory inefficiencies. In response, we propose DAO-GP (Drift-Aware Online Gaussian Process), a novel, fully adaptive, hyperparameter-free, decayed, and sparse non-linear regression model. DAO-GP features a built-in drift detection and adaptation mechanism that dynamically adjusts model behavior based on the severity of drift. Extensive empirical evaluations confirm DAO-GP's robustness across stationary conditions, diverse drift types (abrupt, incremental, gradual), and varied data characteristics. Analyses demonstrate its dynamic adaptation, efficient in-memory and decay-based management, and evolving inducing points. Compared with state-of-the-art parametric and non-parametric models, DAO-GP consistently achieves superior or competitive performance, establishing it as a drift-resilient solution for online non-linear regression.
DOOMGAN:High-Fidelity Dynamic Identity Obfuscation Ocular Generative Morphing
Jul 23, 2025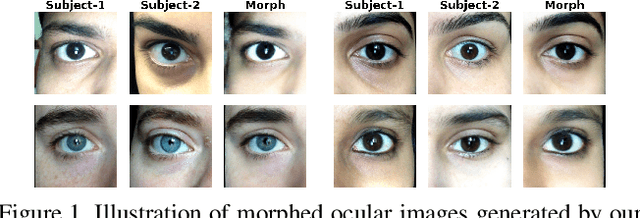
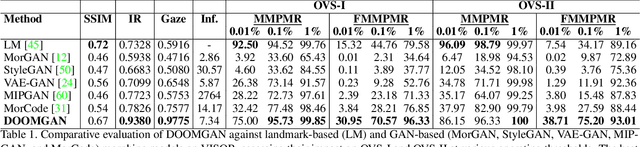
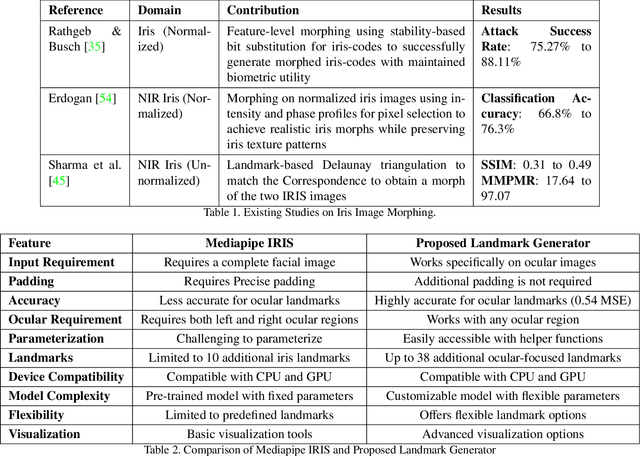
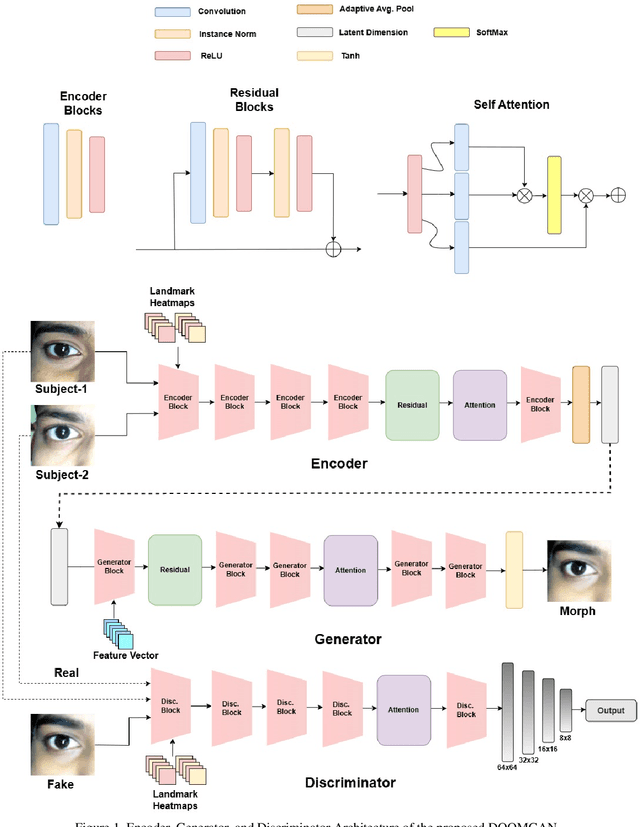
Ocular biometrics in the visible spectrum have emerged as a prominent modality due to their high accuracy, resistance to spoofing, and non-invasive nature. However, morphing attacks, synthetic biometric traits created by blending features from multiple individuals, threaten biometric system integrity. While extensively studied for near-infrared iris and face biometrics, morphing in visible-spectrum ocular data remains underexplored. Simulating such attacks demands advanced generation models that handle uncontrolled conditions while preserving detailed ocular features like iris boundaries and periocular textures. To address this gap, we introduce DOOMGAN, that encompasses landmark-driven encoding of visible ocular anatomy, attention-guided generation for realistic morph synthesis, and dynamic weighting of multi-faceted losses for optimized convergence. DOOMGAN achieves over 20% higher attack success rates than baseline methods under stringent thresholds, along with 20% better elliptical iris structure generation and 30% improved gaze consistency. We also release the first comprehensive ocular morphing dataset to support further research in this domain.
Time Frequency Analysis of EMG Signal for Gesture Recognition using Fine grained Features
Apr 20, 2025Electromyography (EMG) based hand gesture recognition converts forearm muscle activity into control commands for prosthetics, rehabilitation, and human computer interaction. This paper proposes a novel approach to EMG-based hand gesture recognition that uses fine-grained classification and presents XMANet, which unifies low-level local and high level semantic cues through cross layer mutual attention among shallow to deep CNN experts. Using stacked spectrograms and scalograms derived from the Short Time Fourier Transform (STFT) and Wavelet Transform (WT), we benchmark XMANet against ResNet50, DenseNet-121, MobileNetV3, and EfficientNetB0. Experimental results on the Grabmyo dataset indicate that, using STFT, the proposed XMANet model outperforms the baseline ResNet50, EfficientNetB0, MobileNetV3, and DenseNet121 models with improvement of approximately 1.72%, 4.38%, 5.10%, and 2.53%, respectively. When employing the WT approach, improvements of around 1.57%, 1.88%, 1.46%, and 2.05% are observed over the same baselines. Similarly, on the FORS EMG dataset, the XMANet(ResNet50) model using STFT shows an improvement of about 5.04% over the baseline ResNet50. In comparison, the XMANet(DenseNet121) and XMANet(MobileNetV3) models yield enhancements of approximately 4.11% and 2.81%, respectively. Moreover, when using WT, the proposed XMANet achieves gains of around 4.26%, 9.36%, 5.72%, and 6.09% over the baseline ResNet50, DenseNet121, MobileNetV3, and EfficientNetB0 models, respectively. These results confirm that XMANet consistently improves performance across various architectures and signal processing techniques, demonstrating the strong potential of fine grained features for accurate and robust EMG classification.
Unified Face Matching and Physical-Digital Spoofing Attack Detection
Jan 16, 2025



Face recognition technology has dramatically transformed the landscape of security, surveillance, and authentication systems, offering a user-friendly and non-invasive biometric solution. However, despite its significant advantages, face recognition systems face increasing threats from physical and digital spoofing attacks. Current research typically treats face recognition and attack detection as distinct classification challenges. This approach necessitates the implementation of separate models for each task, leading to considerable computational complexity, particularly on devices with limited resources. Such inefficiencies can stifle scalability and hinder performance. In response to these challenges, this paper introduces an innovative unified model designed for face recognition and detection of physical and digital attacks. By leveraging the advanced Swin Transformer backbone and incorporating HiLo attention in a convolutional neural network framework, we address unified face recognition and spoof attack detection more effectively. Moreover, we introduce augmentation techniques that replicate the traits of physical and digital spoofing cues, significantly enhancing our model robustness. Through comprehensive experimental evaluation across various datasets, we showcase the effectiveness of our model in unified face recognition and spoof detection. Additionally, we confirm its resilience against unseen physical and digital spoofing attacks, underscoring its potential for real-world applications.
Machine Learning-based sEMG Signal Classification for Hand Gesture Recognition
Nov 23, 2024



EMG-based hand gesture recognition uses electromyographic~(EMG) signals to interpret and classify hand movements by analyzing electrical activity generated by muscle contractions. It has wide applications in prosthesis control, rehabilitation training, and human-computer interaction. Using electrodes placed on the skin, the EMG sensor captures muscle signals, which are processed and filtered to reduce noise. Numerous feature extraction and machine learning algorithms have been proposed to extract and classify muscle signals to distinguish between various hand gestures. This paper aims to benchmark the performance of EMG-based hand gesture recognition using novel feature extraction methods, namely, fused time-domain descriptors, temporal-spatial descriptors, and wavelet transform-based features, combined with the state-of-the-art machine and deep learning models. Experimental investigations on the Grabmyo dataset demonstrate that the 1D Dilated CNN performed the best with an accuracy of $97\%$ using fused time-domain descriptors such as power spectral moments, sparsity, irregularity factor and waveform length ratio. Similarly, on the FORS-EMG dataset, random forest performed the best with an accuracy of $94.95\%$ using temporal-spatial descriptors (which include time domain features along with additional features such as coefficient of variation (COV), and Teager-Kaiser energy operator (TKEO)).
Social Media Authentication and Combating Deepfakes using Semi-fragile Invisible Image Watermarking
Oct 02, 2024With the significant advances in deep generative models for image and video synthesis, Deepfakes and manipulated media have raised severe societal concerns. Conventional machine learning classifiers for deepfake detection often fail to cope with evolving deepfake generation technology and are susceptible to adversarial attacks. Alternatively, invisible image watermarking is being researched as a proactive defense technique that allows media authentication by verifying an invisible secret message embedded in the image pixels. A handful of invisible image watermarking techniques introduced for media authentication have proven vulnerable to basic image processing operations and watermark removal attacks. In response, we have proposed a semi-fragile image watermarking technique that embeds an invisible secret message into real images for media authentication. Our proposed watermarking framework is designed to be fragile to facial manipulations or tampering while being robust to benign image-processing operations and watermark removal attacks. This is facilitated through a unique architecture of our proposed technique consisting of critic and adversarial networks that enforce high image quality and resiliency to watermark removal efforts, respectively, along with the backbone encoder-decoder and the discriminator networks. Thorough experimental investigations on SOTA facial Deepfake datasets demonstrate that our proposed model can embed a $64$-bit secret as an imperceptible image watermark that can be recovered with a high-bit recovery accuracy when benign image processing operations are applied while being non-recoverable when unseen Deepfake manipulations are applied. In addition, our proposed watermarking technique demonstrates high resilience to several white-box and black-box watermark removal attacks. Thus, obtaining state-of-the-art performance.
FineFACE: Fair Facial Attribute Classification Leveraging Fine-grained Features
Aug 29, 2024



Published research highlights the presence of demographic bias in automated facial attribute classification algorithms, particularly impacting women and individuals with darker skin tones. Existing bias mitigation techniques typically require demographic annotations and often obtain a trade-off between fairness and accuracy, i.e., Pareto inefficiency. Facial attributes, whether common ones like gender or others such as "chubby" or "high cheekbones", exhibit high interclass similarity and intraclass variation across demographics leading to unequal accuracy. This requires the use of local and subtle cues using fine-grained analysis for differentiation. This paper proposes a novel approach to fair facial attribute classification by framing it as a fine-grained classification problem. Our approach effectively integrates both low-level local features (like edges and color) and high-level semantic features (like shapes and structures) through cross-layer mutual attention learning. Here, shallow to deep CNN layers function as experts, offering category predictions and attention regions. An exhaustive evaluation on facial attribute annotated datasets demonstrates that our FineFACE model improves accuracy by 1.32% to 1.74% and fairness by 67% to 83.6%, over the SOTA bias mitigation techniques. Importantly, our approach obtains a Pareto-efficient balance between accuracy and fairness between demographic groups. In addition, our approach does not require demographic annotations and is applicable to diverse downstream classification tasks. To facilitate reproducibility, the code and dataset information is available at https://github.com/VCBSL-Fairness/FineFACE.
Contextual Cross-Modal Attention for Audio-Visual Deepfake Detection and Localization
Aug 06, 2024In the digital age, the emergence of deepfakes and synthetic media presents a significant threat to societal and political integrity. Deepfakes based on multi-modal manipulation, such as audio-visual, are more realistic and pose a greater threat. Current multi-modal deepfake detectors are often based on the attention-based fusion of heterogeneous data streams from multiple modalities. However, the heterogeneous nature of the data (such as audio and visual signals) creates a distributional modality gap and poses a significant challenge in effective fusion and hence multi-modal deepfake detection. In this paper, we propose a novel multi-modal attention framework based on recurrent neural networks (RNNs) that leverages contextual information for audio-visual deepfake detection. The proposed approach applies attention to multi-modal multi-sequence representations and learns the contributing features among them for deepfake detection and localization. Thorough experimental validations on audio-visual deepfake datasets, namely FakeAVCeleb, AV-Deepfake1M, TVIL, and LAV-DF datasets, demonstrate the efficacy of our approach. Cross-comparison with the published studies demonstrates superior performance of our approach with an improved accuracy and precision by 3.47% and 2.05% in deepfake detection and localization, respectively. Thus, obtaining state-of-the-art performance. To facilitate reproducibility, the code and the datasets information is available at https://github.com/vcbsl/audiovisual-deepfake/.