 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial Cross-Domain Action Recognition with Co-Attention
Dec 22, 2019
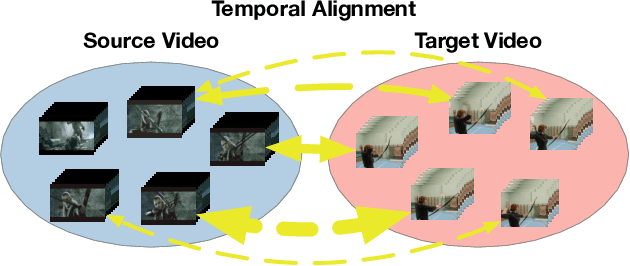

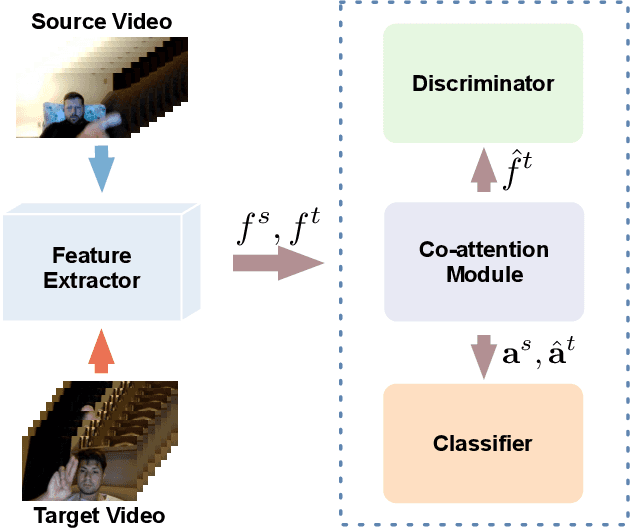

Action recognition has been a widely studied topic with a heavy focus on supervised learning involving sufficient labeled videos. However, the problem of cross-domain action recognition, where training and testing videos are drawn from different underlying distributions, remains largely under-explored. Previous methods directly employ techniques for cross-domain image recognition, which tend to suffer from the severe temporal misalignment problem. This paper proposes a Temporal Co-attention Network (TCoN), which matches the distributions of temporally aligned action features between source and target domains using a novel cross-domain co-attention mechanism. Experimental results on three cross-domain action recognition datasets demonstrate that TCoN improves both previous single-domain and cross-domain methods significantly under the cross-domain setting.
Deep Multi-task Prediction of Lung Cancer and Cancer-free Progression from Censored Heterogenous Clinical Imaging
Nov 12, 2019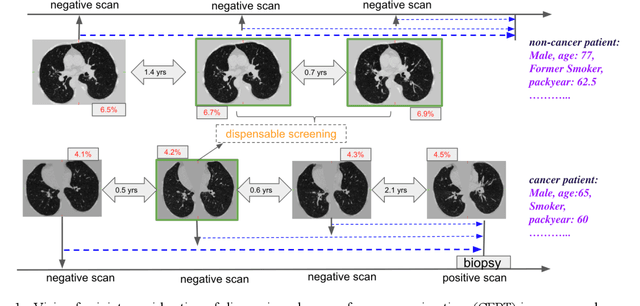
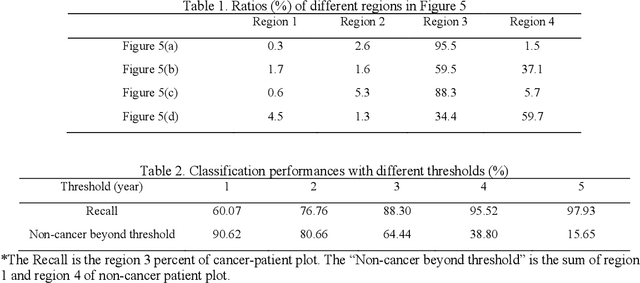
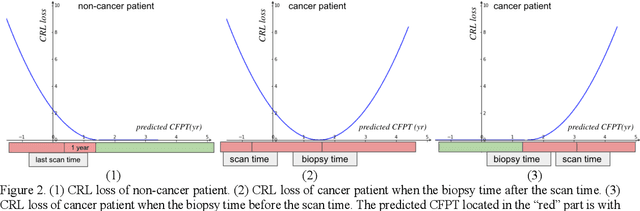
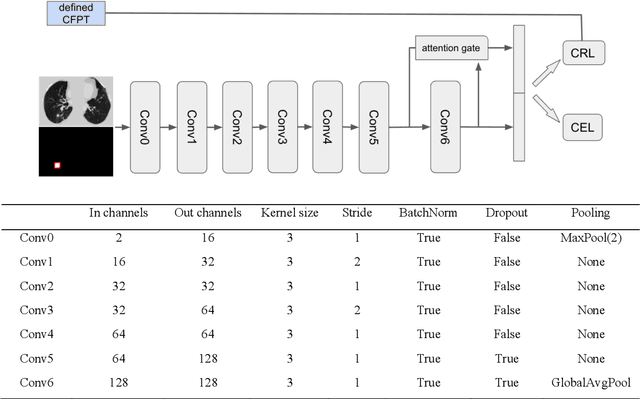
Annual low dose computed tomography (CT) lung screening is currently advised for individuals at high risk of lung cancer (e.g., heavy smokers between 55 and 80 years old). The recommended screening practice significantly reduces all-cause mortality, but the vast majority of screening results are negative for cancer. If patients at very low risk could be identified based on individualized, image-based biomarkers, the health care resources could be more efficiently allocated to higher risk patients and reduce overall exposure to ionizing radiation. In this work, we propose a multi-task (diagnosis and prognosis) deep convolutional neural network to improve the diagnostic accuracy over a baseline model while simultaneously estimating a personalized cancer-free progression time (CFPT). A novel Censored Regression Loss (CRL) is proposed to perform weakly supervised regression so that even single negative screening scans can provide small incremental value. Herein, we study 2287 scans from 1433 de-identified patients from the Vanderbilt Lung Screening Program (VLSP) and Molecular Characterization Laboratories (MCL) cohorts. Using five-fold cross-validation, we train a 3D attention-based network under two scenarios: (1) single-task learning with only classification, and (2) multi-task learning with both classification and regression. The single-task learning leads to a higher AUC compared with the Kaggle challenge winner pre-trained model (0.878 v. 0.856), and multi-task learning significantly improves the single-task one (AUC 0.895, p<0.01, McNemar test). In summary, the image-based predicted CFPT can be used in follow-up year lung cancer prediction and data assessment.
VL-BERT: Pre-training of Generic Visual-Linguistic Representations
Aug 22, 2019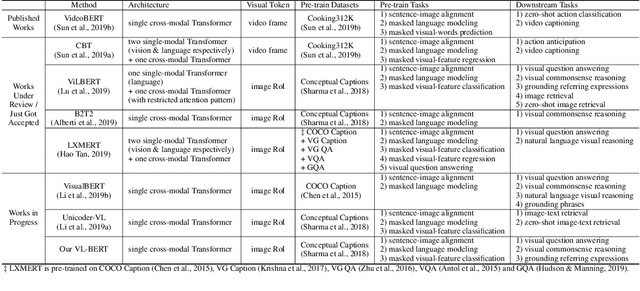
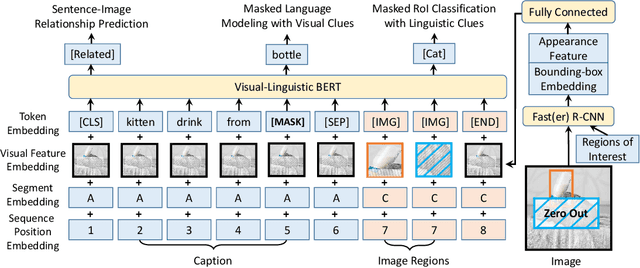
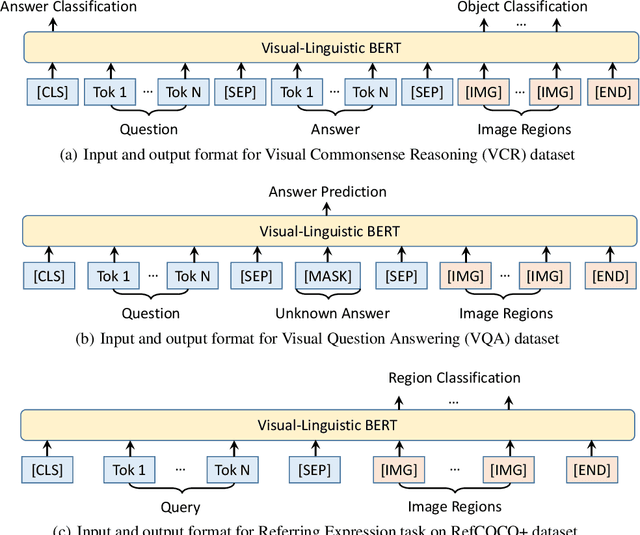
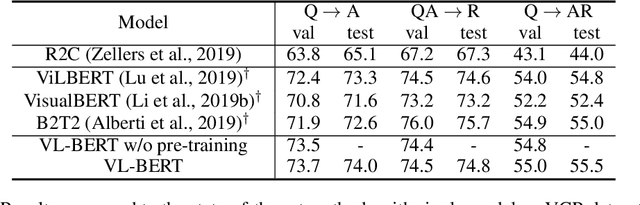
We introduce a new pre-trainable generic representation for visual-linguistic tasks, called Visual-Linguistic BERT (VL-BERT for short). VL-BERT adopts the simple yet powerful Transformer model as the backbone, and extends it to take both visual and linguistic embedded features as input. In it, each element of the input is either of a word from the input sentence, or a region-of-interest (RoI) from the input image. It is designed to fit for most of the vision-and-language downstream tasks. To better exploit the generic representation, we pre-train VL-BERT on massive-scale Conceptual Captions dataset with three tasks: masked language modeling with visual clues, masked RoI classification with linguistic clues, and sentence-image relationship prediction. Extensive empirical analysis demonstrates that the pre-training procedure can better align the visual-linguistic clues and benefit the downstream tasks, such as visual question answering, visual commonsense reasoning and referring expression comprehension. It is worth noting that VL-BERT achieved the first place of single model on the leaderboard of the VCR benchmark.
Robustness properties of Facebook's ResNeXt WSL models
Jul 25, 2019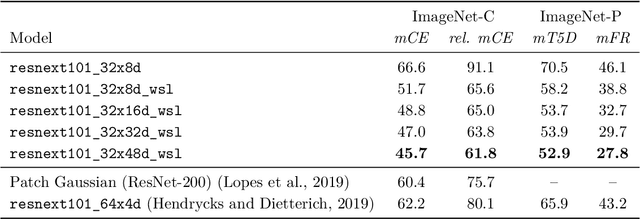
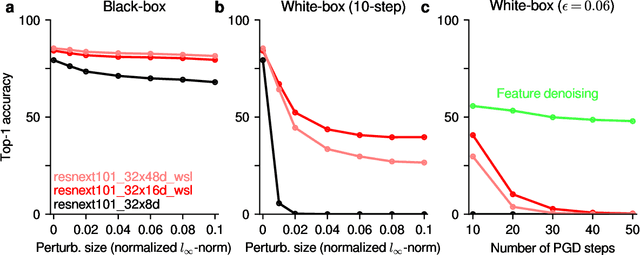
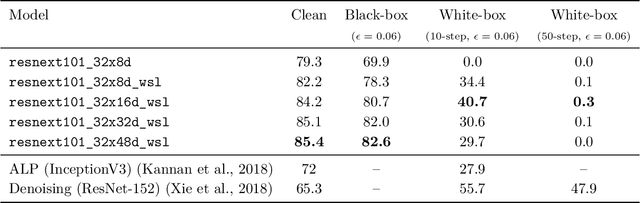

We investigate the robustness properties of ResNeXt image recognition models trained with billion scale weakly-supervised data (ResNeXt WSL models). These models, recently made public by Facebook AI, were trained on ~1B images from Instagram and fine-tuned on ImageNet. We show that these models display an unprecedented degree of robustness against common image corruptions and perturbations, as measured by the ImageNet-C and ImageNet-P benchmarks. The largest of the released models, in particular, achieves state-of-the-art results on both ImageNet-C and ImageNet-P by a large margin. The gains on ImageNet-C and ImageNet-P far outpace the gains on ImageNet validation accuracy, suggesting the former as more useful benchmarks to measure further progress in image recognition. Remarkably, the ResNeXt WSL models even achieve a limited degree of adversarial robustness against state-of-the-art white-box attacks (10-step PGD attacks). However, in contrast to adversarially trained models, the robustness of the ResNeXt WSL models rapidly declines with the number of PGD steps, suggesting that these models do not achieve genuine adversarial robustness. Visualization of the learned features also confirms this conclusion. Finally, we show that although the ResNeXt WSL models are more shape-biased than comparable ImageNet-trained models in a shape-texture cue conflict experiment, they still remain much more texture-biased than humans and their accuracy on the recently introduced "natural adversarial examples" (ImageNet-A) also remains low, suggesting that they share many of the underlying characteristics of ImageNet-trained models that make these benchmarks challenging.
On Automation and Medical Image Interpretation, With Applications for Laryngeal Imaging
Jan 14, 2013

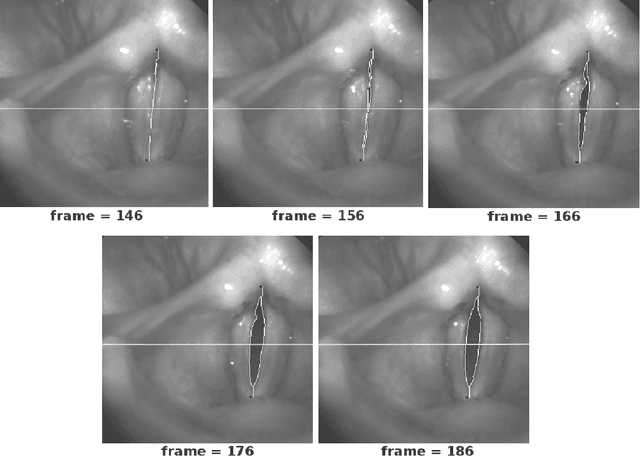
Indeed, these are exciting times. We are in the heart of a digital renaissance. Automation and computer technology allow engineers and scientists to fabricate processes that amalgamate quality of life. We anticipate much growth in medical image interpretation and understanding, due to the influx of computer technologies. This work should serve as a guide to introduce the reader to core themes in theoretical computer science, as well as imaging applications for understanding vocal-fold vibrations. In this work, we motivate the use of automation, review some mathematical models of computation. We present a proof of a classical problem in image analysis that cannot be automated by means of algorithms. Furthermore, discuss some applications for processing medical images of the vocal folds, and discuss some of the exhilarating directions the art of automation will take vocal-fold image interpretation and quite possibly other areas of biomedical image analysis.
Adversarial Pyramid Network for Video Domain Generalization
Dec 08, 2019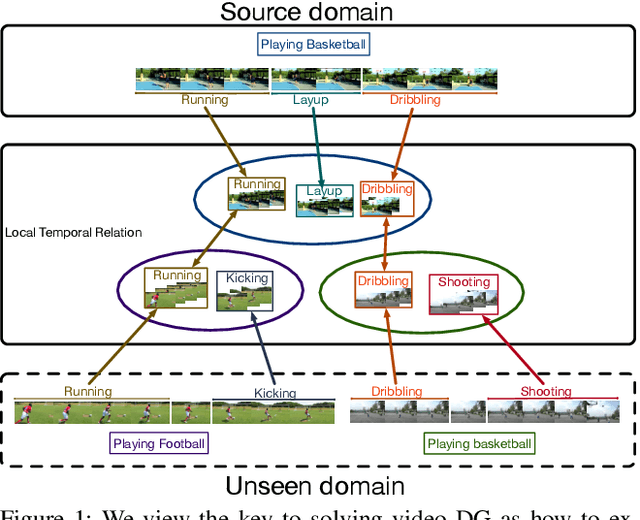
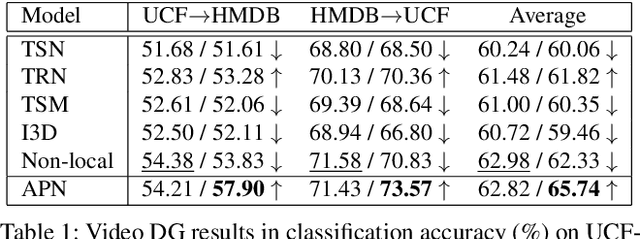
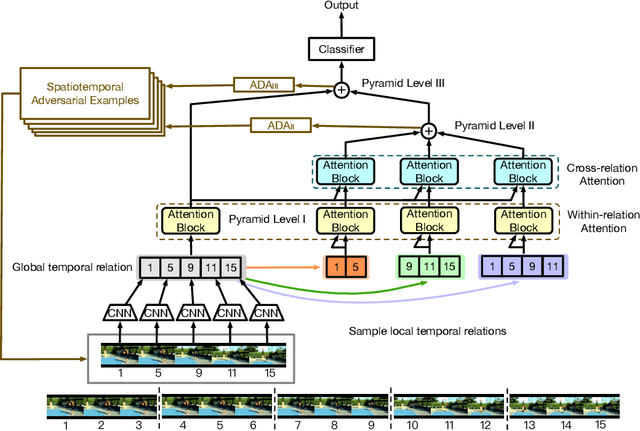

This paper introduces a new research problem of video domain generalization (video DG) where most state-of-the-art action recognition networks degenerate due to the lack of exposure to the target domains of divergent distributions. While recent advances in video understanding focus on capturing the temporal relations of the long-term video context, we observe that the global temporal features are less generalizable in the video DG settings. The reason is that videos from other unseen domains may have unexpected absence, misalignment, or scale transformation of the temporal relations, which is known as the temporal domain shift. Therefore, the video DG is even more challenging than the image DG, which is also under-explored, because of the entanglement of the spatial and temporal domain shifts. This finding has led us to view the key to video DG as how to effectively learn the local-relation features of different time scales that are more generalizable, and how to exploit them along with the global-relation features to maintain the discriminability. This paper presents the Adversarial Pyramid Network (APN), which captures the local-relation, global-relation, and multilayer cross-relation features progressively. This pyramid network not only improves the feature transferability from the view of representation learning, but also enhances the diversity and quality of the new data points that can bridge different domains when it is integrated with an improved version of the image DG adversarial data augmentation method. We construct four video DG benchmarks: UCF-HMDB, Something-Something, PKU-MMD, and NTU, in which the source and target domains are divided according to different datasets, different consequences of actions, or different camera views. The APN consistently outperforms previous action recognition models over all benchmarks.
Meta Segmentation Network for Ultra-Resolution Medical Images
Feb 19, 2020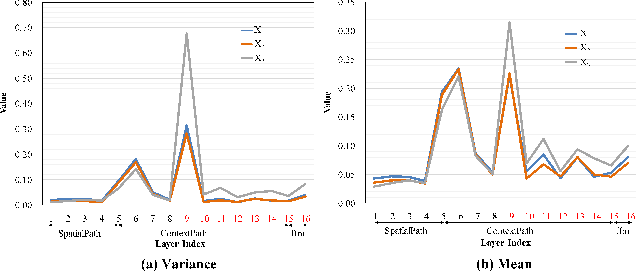
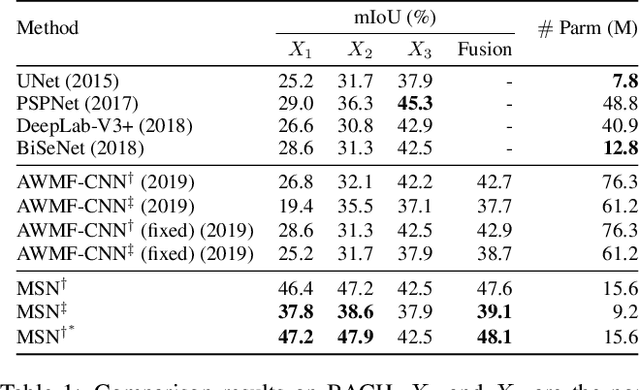
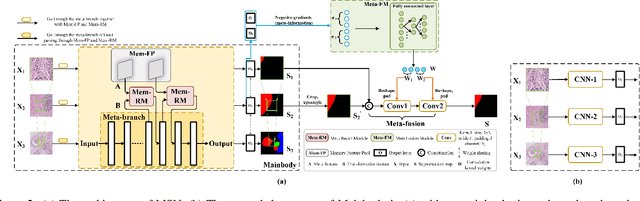
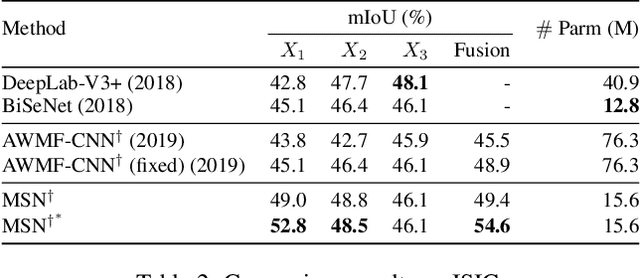
Despite recent progress on semantic segmentation, there still exist huge challenges in medical ultra-resolution image segmentation. The methods based on multi-branch structure can make a good balance between computational burdens and segmentation accuracy. However, the fusion structure in these methods require to be designed elaborately to achieve desirable result, which leads to model redundancy. In this paper, we propose Meta Segmentation Network (MSN) to solve this challenging problem. With the help of meta-learning, the fusion module of MSN is quite simple but effective. MSN can fast generate the weights of fusion layers through a simple meta-learner, requiring only a few training samples and epochs to converge. In addition, to avoid learning all branches from scratch, we further introduce a particular weight sharing mechanism to realize a fast knowledge adaptation and share the weights among multiple branches, resulting in the performance improvement and significant parameters reduction. The experimental results on two challenging ultra-resolution medical datasets BACH and ISIC show that MSN achieves the best performance compared with the state-of-the-art methods.
Best of Both Worlds: AutoML Codesign of a CNN and its Hardware Accelerator
Mar 06, 2020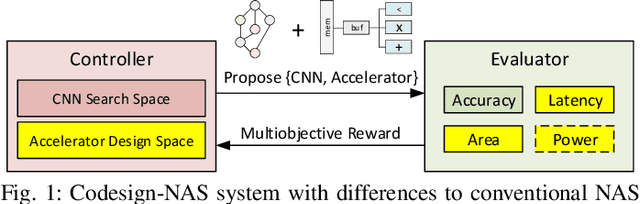
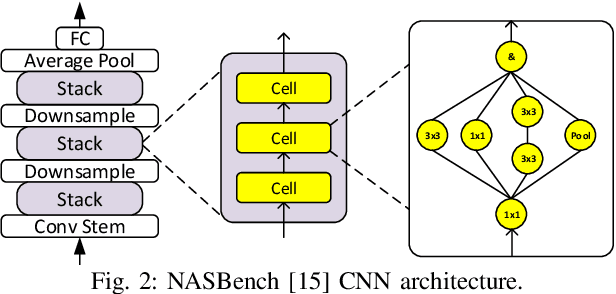
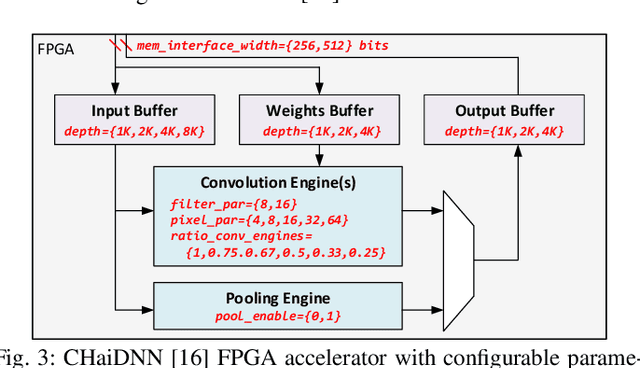
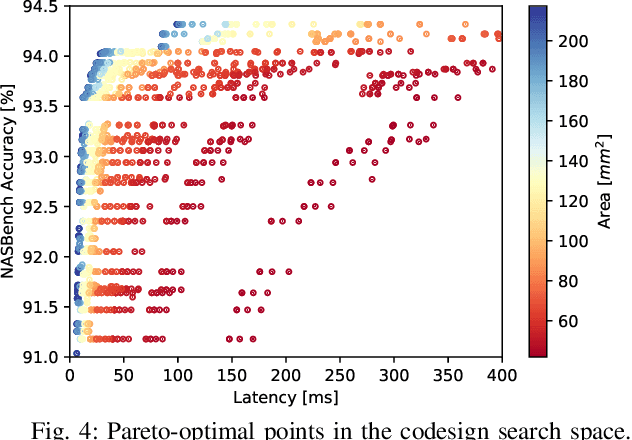
Neural architecture search (NAS) has been very successful at outperforming human-designed convolutional neural networks (CNN) in accuracy, and when hardware information is present, latency as well. However, NAS-designed CNNs typically have a complicated topology, therefore, it may be difficult to design a custom hardware (HW) accelerator for such CNNs. We automate HW-CNN codesign using NAS by including parameters from both the CNN model and the HW accelerator, and we jointly search for the best model-accelerator pair that boosts accuracy and efficiency. We call this Codesign-NAS. In this paper we focus on defining the Codesign-NAS multiobjective optimization problem, demonstrating its effectiveness, and exploring different ways of navigating the codesign search space. For CIFAR-10 image classification, we enumerate close to 4 billion model-accelerator pairs, and find the Pareto frontier within that large search space. This allows us to evaluate three different reinforcement-learning-based search strategies. Finally, compared to ResNet on its most optimal HW accelerator from within our HW design space, we improve on CIFAR-100 classification accuracy by 1.3% while simultaneously increasing performance/area by 41% in just~1000 GPU-hours of running Codesign-NAS.
Neuromorphic Eye-in-Hand Visual Servoing
Apr 15, 2020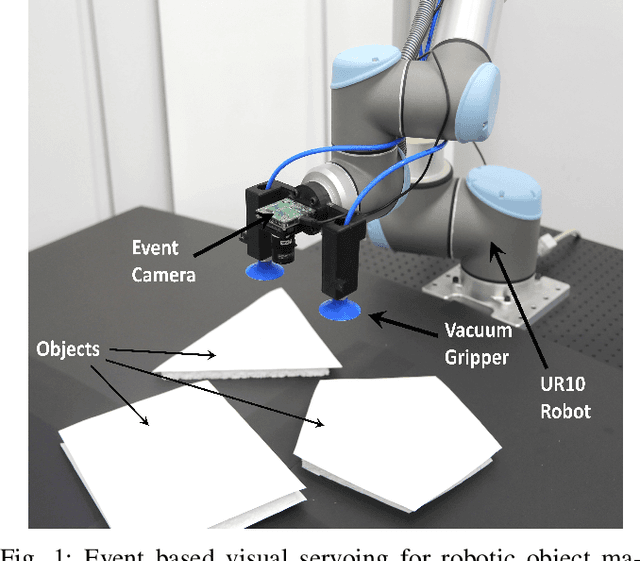
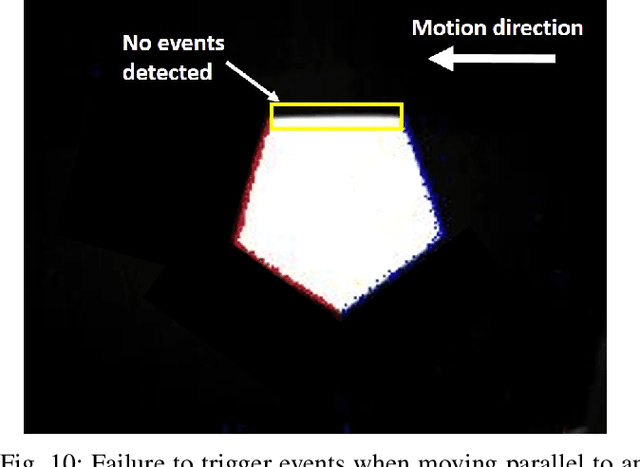
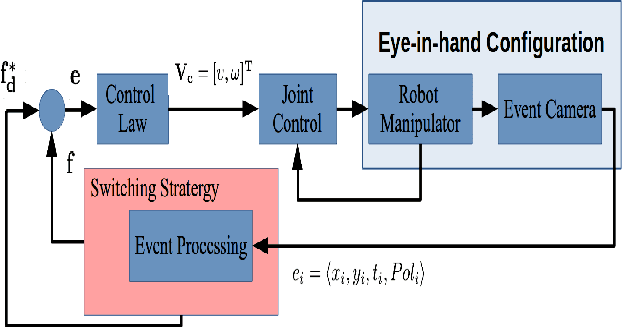
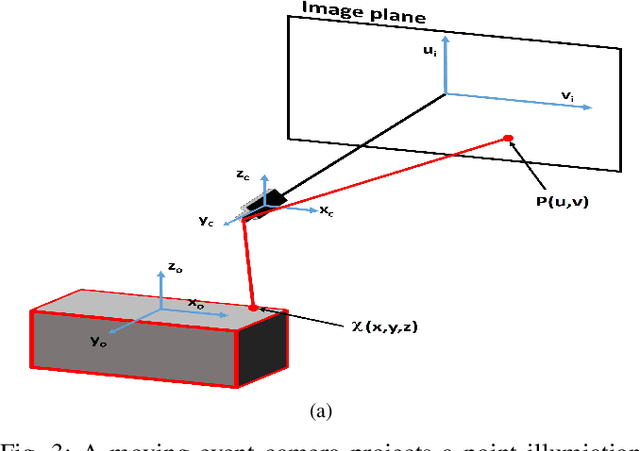
Robotic vision plays a major role in factory automation to service robot applications. However, the traditional use of frame-based camera sets a limitation on continuous visual feedback due to their low sampling rate and redundant data in real-time image processing, especially in the case of high-speed tasks. Event cameras give human-like vision capabilities such as observing the dynamic changes asynchronously at a high temporal resolution ($1\mu s$) with low latency and wide dynamic range. In this paper, we present a visual servoing method using an event camera and a switching control strategy to explore, reach and grasp to achieve a manipulation task. We devise three surface layers of active events to directly process stream of events from relative motion. A purely event based approach is adopted to extract corner features, localize them robustly using heat maps and generate virtual features for tracking and alignment. Based on the visual feedback, the motion of the robot is controlled to make the temporal upcoming event features converge to the desired event in spatio-temporal space. The controller switches its strategy based on the sequence of operation to establish a stable grasp. The event based visual servoing (EVBS) method is validated experimentally using a commercial robot manipulator in an eye-in-hand configuration. Experiments prove the effectiveness of the EBVS method to track and grasp objects of different shapes without the need for re-tuning.
Shoestring: Graph-Based Semi-Supervised Learning with Severely Limited Labeled Data
Oct 28, 2019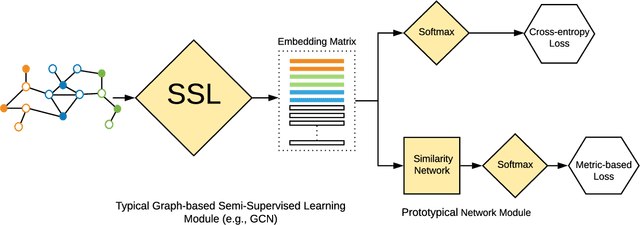

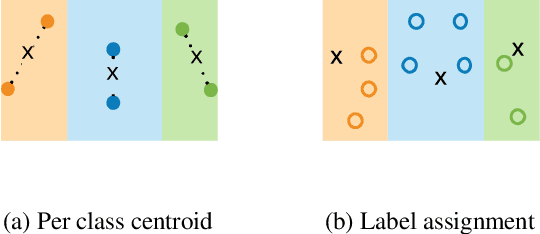
Graph-based semi-supervised learning has been shown to be one of the most effective approaches for classification tasks from a wide range of domains, such as image classification and text classification, as they can exploit the connectivity patterns between labeled and unlabeled samples to improve learning performance. In this work, we advance this effective learning paradigm towards a scenario where labeled data are severely limited. More specifically, we address the problem of graph-based semi-supervised learning in the presence of severely limited labeled samples, and propose a new framework, called {\em Shoestring}, that improves the learning performance through semantic transfer from these very few labeled samples to large numbers of unlabeled samples. In particular, our framework learns a metric space in which classification can be performed by computing the similarity to centroid embedding of each class. {\em Shoestring} is trained in an end-to-end fashion to learn to leverage the semantic knowledge of limited labeled samples as well as their connectivity patterns with large numbers of unlabeled samples simultaneously. By combining {\em Shoestring} with graph convolutional networks, label propagation and their recent label-efficient variations (IGCN and GLP), we are able to achieve state-of-the-art node classification performance in the presence of very few labeled samples. In addition, we demonstrate the effectiveness of our framework on image classification tasks in the few-shot learning regime, with significant gains on miniImageNet ($2.57\%\sim3.59\%$) and tieredImageNet ($1.05\%\sim2.70\%$).