 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning GPT-5 for GPU Kernel Generation
Feb 11, 2026Developing efficient GPU kernels is essential for scaling modern AI systems, yet it remains a complex task due to intricate hardware architectures and the need for specialized optimization expertise. Although Large Language Models (LLMs) demonstrate strong capabilities in general sequential code generation, they face significant challenges in GPU code generation because of the scarcity of high-quality labeled training data, compiler biases when generating synthetic solutions, and limited generalization across hardware generations. This precludes supervised fine-tuning (SFT) as a scalable methodology for improving current LLMs. In contrast, reinforcement learning (RL) offers a data-efficient and adaptive alternative but requires access to relevant tools, careful selection of training problems, and a robust evaluation environment. We present Makora's environment and tools for reinforcement learning finetuning of frontier models and report our results from fine-tuning GPT-5 for Triton code generation. In the single-attempt setting, our fine-tuned model improves kernel correctness from 43.7% to 77.0% (+33.3 percentage points) and increases the fraction of problems outperforming TorchInductor from 14.8% to 21.8% (+7 percentage points) compared to baseline GPT-5, while exceeding prior state-of-the-art models on KernelBench. When integrated into a full coding agent, it is able to solve up to 97.4% of problems in an expanded KernelBench suite, outperforming the PyTorch TorchInductor compiler on 72.9% of problems with a geometric mean speedup of 2.12x. Our work demonstrates that targeted post-training with reinforcement learning can unlock LLM capabilities in highly specialized technical domains where traditional supervised learning is limited by data availability, opening new pathways for AI-assisted accelerator programming.
MobileQuant: Mobile-friendly Quantization for On-device Language Models
Aug 25, 2024



Large language models (LLMs) have revolutionized language processing, delivering outstanding results across multiple applications. However, deploying LLMs on edge devices poses several challenges with respect to memory, energy, and compute costs, limiting their widespread use in devices such as mobile phones. A promising solution is to reduce the number of bits used to represent weights and activations. While existing works have found partial success at quantizing LLMs to lower bitwidths, e.g. 4-bit weights, quantizing activations beyond 16 bits often leads to large computational overheads due to poor on-device quantization support, or a considerable accuracy drop. Yet, 8-bit activations are very attractive for on-device deployment as they would enable LLMs to fully exploit mobile-friendly hardware, e.g. Neural Processing Units (NPUs). In this work, we make a first attempt to facilitate the on-device deployment of LLMs using integer-only quantization. We first investigate the limitations of existing quantization methods for on-device deployment, with a special focus on activation quantization. We then address these limitations by introducing a simple post-training quantization method, named MobileQuant, that extends previous weight equivalent transformation works by jointly optimizing the weight transformation and activation range parameters in an end-to-end manner. MobileQuant demonstrates superior capabilities over existing methods by 1) achieving near-lossless quantization on a wide range of LLM benchmarks, 2) reducing latency and energy consumption by 20\%-50\% compared to current on-device quantization strategies, 3) requiring limited compute budget, 4) being compatible with mobile-friendly compute units, e.g. NPU.
Recurrent Early Exits for Federated Learning with Heterogeneous Clients
May 23, 2024Federated learning (FL) has enabled distributed learning of a model across multiple clients in a privacy-preserving manner. One of the main challenges of FL is to accommodate clients with varying hardware capacities; clients have differing compute and memory requirements. To tackle this challenge, recent state-of-the-art approaches leverage the use of early exits. Nonetheless, these approaches fall short of mitigating the challenges of joint learning multiple exit classifiers, often relying on hand-picked heuristic solutions for knowledge distillation among classifiers and/or utilizing additional layers for weaker classifiers. In this work, instead of utilizing multiple classifiers, we propose a recurrent early exit approach named ReeFL that fuses features from different sub-models into a single shared classifier. Specifically, we use a transformer-based early-exit module shared among sub-models to i) better exploit multi-layer feature representations for task-specific prediction and ii) modulate the feature representation of the backbone model for subsequent predictions. We additionally present a per-client self-distillation approach where the best sub-model is automatically selected as the teacher of the other sub-models at each client. Our experiments on standard image and speech classification benchmarks across various emerging federated fine-tuning baselines demonstrate ReeFL's effectiveness over previous works.
Fast Inference Through The Reuse Of Attention Maps In Diffusion Models
Dec 13, 2023



Text-to-image diffusion models have demonstrated unprecedented abilities at flexible and realistic image synthesis. However, the iterative process required to produce a single image is costly and incurs a high latency, prompting researchers to further investigate its efficiency. Typically, improvements in latency have been achieved in two ways: (1) training smaller models through knowledge distillation (KD); and (2) adopting techniques from ODE-theory to facilitate larger step sizes. In contrast, we propose a training-free approach that does not alter the step-size of the sampler. Specifically, we find the repeated calculation of attention maps to be both costly and redundant; therefore, we propose a structured reuse of attention maps during sampling. Our initial reuse policy is motivated by rudimentary ODE-theory, which suggests that reuse is most suitable late in the sampling procedure. After noting a number of limitations in this theoretical approach, we empirically search for a better policy. Unlike methods that rely on KD, our reuse policies can easily be adapted to a variety of setups in a plug-and-play manner. Furthermore, when applied to Stable Diffusion-1.5, our reuse policies reduce latency with minimal repercussions on sample quality.
How Much Is Hidden in the NAS Benchmarks? Few-Shot Adaptation of a NAS Predictor
Nov 30, 2023



Neural architecture search has proven to be a powerful approach to designing and refining neural networks, often boosting their performance and efficiency over manually-designed variations, but comes with computational overhead. While there has been a considerable amount of research focused on lowering the cost of NAS for mainstream tasks, such as image classification, a lot of those improvements stem from the fact that those tasks are well-studied in the broader context. Consequently, applicability of NAS to emerging and under-represented domains is still associated with a relatively high cost and/or uncertainty about the achievable gains. To address this issue, we turn our focus towards the recent growth of publicly available NAS benchmarks in an attempt to extract general NAS knowledge, transferable across different tasks and search spaces. We borrow from the rich field of meta-learning for few-shot adaptation and carefully study applicability of those methods to NAS, with a special focus on the relationship between task-level correlation (domain shift) and predictor transferability; which we deem critical for improving NAS on diverse tasks. In our experiments, we use 6 NAS benchmarks in conjunction, spanning in total 16 NAS settings -- our meta-learning approach not only shows superior (or matching) performance in the cross-validation experiments but also successful extrapolation to a new search space and tasks.
Neural Fine-Tuning Search for Few-Shot Learning
Jun 15, 2023



In few-shot recognition, a classifier that has been trained on one set of classes is required to rapidly adapt and generalize to a disjoint, novel set of classes. To that end, recent studies have shown the efficacy of fine-tuning with carefully crafted adaptation architectures. However this raises the question of: How can one design the optimal adaptation strategy? In this paper, we study this question through the lens of neural architecture search (NAS). Given a pre-trained neural network, our algorithm discovers the optimal arrangement of adapters, which layers to keep frozen and which to fine-tune. We demonstrate the generality of our NAS method by applying it to both residual networks and vision transformers and report state-of-the-art performance on Meta-Dataset and Meta-Album.
Federated Learning for Inference at Anytime and Anywhere
Dec 08, 2022



Federated learning has been predominantly concerned with collaborative training of deep networks from scratch, and especially the many challenges that arise, such as communication cost, robustness to heterogeneous data, and support for diverse device capabilities. However, there is no unified framework that addresses all these problems together. This paper studies the challenges and opportunities of exploiting pre-trained Transformer models in FL. In particular, we propose to efficiently adapt such pre-trained models by injecting a novel attention-based adapter module at each transformer block that both modulates the forward pass and makes an early prediction. Training only the lightweight adapter by FL leads to fast and communication-efficient learning even in the presence of heterogeneous data and devices. Extensive experiments on standard FL benchmarks, including CIFAR-100, FEMNIST and SpeechCommandsv2 demonstrate that this simple framework provides fast and accurate FL while supporting heterogenous device capabilities, efficient personalization, and scalable-cost anytime inference.
BLOX: Macro Neural Architecture Search Benchmark and Algorithms
Oct 13, 2022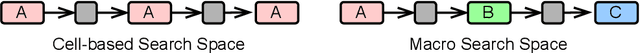
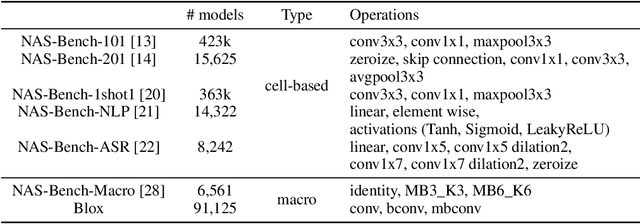
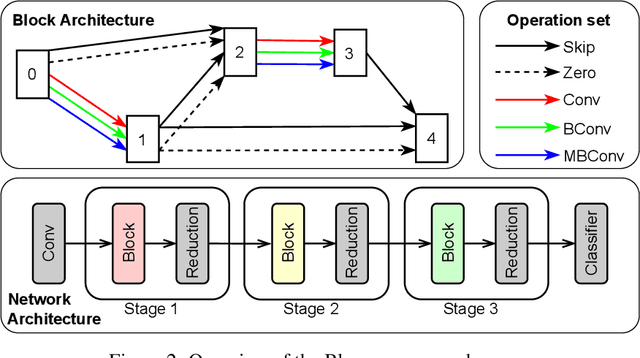
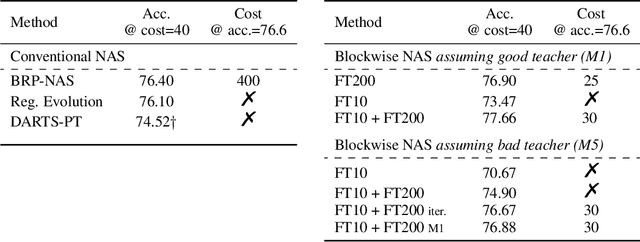
Neural architecture search (NAS) has been successfully used to design numerous high-performance neural networks. However, NAS is typically compute-intensive, so most existing approaches restrict the search to decide the operations and topological structure of a single block only, then the same block is stacked repeatedly to form an end-to-end model. Although such an approach reduces the size of search space, recent studies show that a macro search space, which allows blocks in a model to be different, can lead to better performance. To provide a systematic study of the performance of NAS algorithms on a macro search space, we release Blox - a benchmark that consists of 91k unique models trained on the CIFAR-100 dataset. The dataset also includes runtime measurements of all the models on a diverse set of hardware platforms. We perform extensive experiments to compare existing algorithms that are well studied on cell-based search spaces, with the emerging blockwise approaches that aim to make NAS scalable to much larger macro search spaces. The benchmark and code are available at https://github.com/SamsungLabs/blox.
Zero-Cost Proxies Meet Differentiable Architecture Search
Jun 12, 2021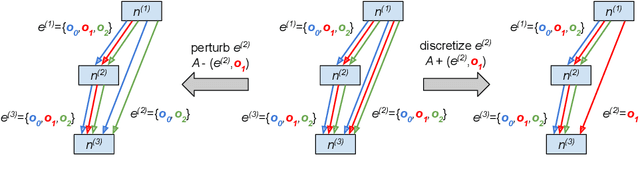


Differentiable neural architecture search (NAS) has attracted significant attention in recent years due to its ability to quickly discover promising architectures of deep neural networks even in very large search spaces. Despite its success, DARTS lacks robustness in certain cases, e.g. it may degenerate to trivial architectures with excessive parametric-free operations such as skip connection or random noise, leading to inferior performance. In particular, operation selection based on the magnitude of architectural parameters was recently proven to be fundamentally wrong showcasing the need to rethink this aspect. On the other hand, zero-cost proxies have been recently studied in the context of sample-based NAS showing promising results -- speeding up the search process drastically in some cases but also failing on some of the large search spaces typical for differentiable NAS. In this work we propose a novel operation selection paradigm in the context of differentiable NAS which utilises zero-cost proxies. Our perturbation-based zero-cost operation selection (Zero-Cost-PT) improves searching time and, in many cases, accuracy compared to the best available differentiable architecture search, regardless of the search space size. Specifically, we are able to find comparable architectures to DARTS-PT on the DARTS CNN search space while being over 40x faster (total searching time 25 minutes on a single GPU).
Zero-Cost Proxies for Lightweight NAS
Jan 20, 2021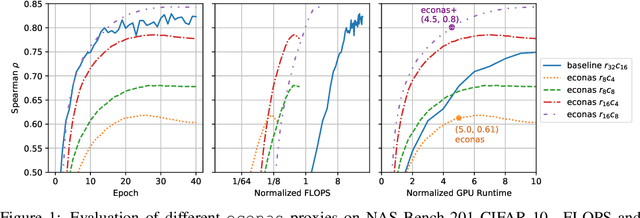

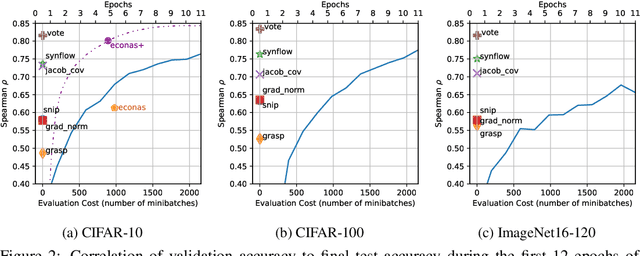

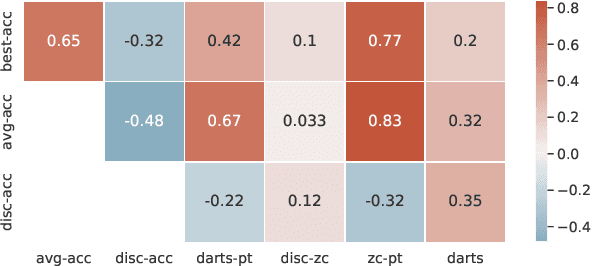
Neural Architecture Search (NAS) is quickly becoming the standard methodology to design neural network models. However, NAS is typically compute-intensive because multiple models need to be evaluated before choosing the best one. To reduce the computational power and time needed, a proxy task is often used for evaluating each model instead of full training. In this paper, we evaluate conventional reduced-training proxies and quantify how well they preserve ranking between multiple models during search when compared with the rankings produced by final trained accuracy. We propose a series of zero-cost proxies, based on recent pruning literature, that use just a single minibatch of training data to compute a model's score. Our zero-cost proxies use 3 orders of magnitude less computation but can match and even outperform conventional proxies. For example, Spearman's rank correlation coefficient between final validation accuracy and our best zero-cost proxy on NAS-Bench-201 is 0.82, compared to 0.61 for EcoNAS (a recently proposed reduced-training proxy). Finally, we use these zero-cost proxies to enhance existing NAS search algorithms such as random search, reinforcement learning, evolutionary search and predictor-based search. For all search methodologies and across three different NAS datasets, we are able to significantly improve sample efficiency, and thereby decrease computation, by using our zero-cost proxies. For example on NAS-Bench-101, we achieved the same accuracy 4$\times$ quicker than the best previous result.