 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recognition-Guided Diffusion Model for Scene Text Image Super-Resolution
Nov 22, 2023
Scene Text Image Super-Resolution (STISR) aims to enhance the resolution and legibility of text within low-resolution (LR) images, consequently elevating recognition accuracy in Scene Text Recognition (STR). Previous methods predominantly employ discriminative Convolutional Neural Networks (CNNs) augmented with diverse forms of text guidance to address this issue. Nevertheless, they remain deficient when confronted with severely blurred images, due to their insufficient generation capability when little structural or semantic information can be extracted from original images. Therefore, we introduce RGDiffSR, a Recognition-Guided Diffusion model for scene text image Super-Resolution, which exhibits great generative diversity and fidelity even in challenging scenarios. Moreover, we propose a Recognition-Guided Denoising Network, to guide the diffusion model generating LR-consistent results through succinct semantic guidance. Experiments on the TextZoom dataset demonstrate the superiority of RGDiffSR over prior state-of-the-art methods in both text recognition accuracy and image fidelity.
Improving Semantic Correspondence with Viewpoint-Guided Spherical Maps
Dec 20, 2023Recent progress in self-supervised representation learning has resulted in models that are capable of extracting image features that are not only effective at encoding image level, but also pixel-level, semantics. These features have been shown to be effective for dense visual semantic correspondence estimation, even outperforming fully-supervised methods. Nevertheless, current self-supervised approaches still fail in the presence of challenging image characteristics such as symmetries and repeated parts. To address these limitations, we propose a new approach for semantic correspondence estimation that supplements discriminative self-supervised features with 3D understanding via a weak geometric spherical prior. Compared to more involved 3D pipelines, our model only requires weak viewpoint information, and the simplicity of our spherical representation enables us to inject informative geometric priors into the model during training. We propose a new evaluation metric that better accounts for repeated part and symmetry-induced mistakes. We present results on the challenging SPair-71k dataset, where we show that our approach demonstrates is capable of distinguishing between symmetric views and repeated parts across many object categories, and also demonstrate that we can generalize to unseen classes on the AwA dataset.
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaption by Combining 3D GANs and Diffusion Priors
Dec 29, 2023Text-guided domain adaption and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaption and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaption. To enhance the diversity in domain adaption and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaption and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
Segment Change Model (SCM) for Unsupervised Change detection in VHR Remote Sensing Images: a Case Study of Buildings
Dec 27, 2023The field of Remote Sensing (RS) widely employs Change Detection (CD) on very-high-resolution (VHR) images. A majority of extant deep-learning-based methods hinge on annotated samples to complete the CD process. Recently, the emergence of Vision Foundation Model (VFM) enables zero-shot predictions in particular vision tasks. In this work, we propose an unsupervised CD method named Segment Change Model (SCM), built upon the Segment Anything Model (SAM) and Contrastive Language-Image Pre-training (CLIP). Our method recalibrates features extracted at different scales and integrates them in a top-down manner to enhance discriminative change edges. We further design an innovative Piecewise Semantic Attention (PSA) scheme, which can offer semantic representation without training, thereby minimize pseudo change phenomenon. Through conducting experiments on two public datasets, the proposed SCM increases the mIoU from 46.09% to 53.67% on the LEVIR-CD dataset, and from 47.56% to 52.14% on the WHU-CD dataset. Our codes are available at https://github.com/StephenApX/UCD-SCM.
Natural Adversarial Patch Generation Method Based on Latent Diffusion Model
Dec 27, 2023Recently, some research show that deep neural networks are vulnerable to the adversarial attacks, the well-trainned samples or patches could be used to trick the neural network detector or human visual perception. However, these adversarial patches, with their conspicuous and unusual patterns, lack camouflage and can easily raise suspicion in the real world. To solve this problem, this paper proposed a novel adversarial patch method called the Latent Diffusion Patch (LDP), in which, a pretrained encoder is first designed to compress the natural images into a feature space with key characteristics. Then trains the diffusion model using the above feature space. Finally, explore the latent space of the pretrained diffusion model using the image denoising technology. It polishes the patches and images through the powerful natural abilities of diffusion models, making them more acceptable to the human visual system. Experimental results, both digital and physical worlds, show that LDPs achieve a visual subjectivity score of 87.3%, while still maintaining effective attack capabilities.
Multi-scale Progressive Feature Embedding for Accurate NIR-to-RGB Spectral Domain Translation
Dec 26, 2023NIR-to-RGB spectral domain translation is a challenging task due to the mapping ambiguities, and existing methods show limited learning capacities. To address these challenges, we propose to colorize NIR images via a multi-scale progressive feature embedding network (MPFNet), with the guidance of grayscale image colorization. Specifically, we first introduce a domain translation module that translates NIR source images into the grayscale target domain. By incorporating a progressive training strategy, the statistical and semantic knowledge from both task domains are efficiently aligned with a series of pixel- and feature-level consistency constraints. Besides, a multi-scale progressive feature embedding network is designed to improve learning capabilities. Experiments show that our MPFNet outperforms state-of-the-art counterparts by 2.55 dB in the NIR-to-RGB spectral domain translation task in terms of PSNR.
Amodal Ground Truth and Completion in the Wild
Dec 28, 2023The problem we study in this paper is amodal image segmentation: predicting entire object segmentation masks including both visible and invisible (occluded) parts. In previous work, the amodal segmentation ground truth on real images is usually predicted by manual annotaton and thus is subjective. In contrast, we use 3D data to establish an automatic pipeline to determine authentic ground truth amodal masks for partially occluded objects in real images. This pipeline is used to construct an amodal completion evaluation benchmark, MP3D-Amodal, consisting of a variety of object categories and labels. To better handle the amodal completion task in the wild, we explore two architecture variants: a two-stage model that first infers the occluder, followed by amodal mask completion; and a one-stage model that exploits the representation power of Stable Diffusion for amodal segmentation across many categories. Without bells and whistles, our method achieves a new state-of-the-art performance on Amodal segmentation datasets that cover a large variety of objects, including COCOA and our new MP3D-Amodal dataset. The dataset, model, and code are available at https://www.robots.ox.ac.uk/~vgg/research/amodal/.
Generalized Mask-aware IoU for Anchor Assignment for Real-time Instance Segmentation
Dec 28, 2023This paper introduces Generalized Mask-aware Intersection-over-Union (GmaIoU) as a new measure for positive-negative assignment of anchor boxes during training of instance segmentation methods. Unlike conventional IoU measure or its variants, which only consider the proximity of anchor and ground-truth boxes; GmaIoU additionally takes into account the segmentation mask. This enables GmaIoU to provide more accurate supervision during training. We demonstrate the effectiveness of GmaIoU by replacing IoU with our GmaIoU in ATSS, a state-of-the-art (SOTA) assigner. Then, we train YOLACT, a real-time instance segmentation method, using our GmaIoU-based ATSS assigner. The resulting YOLACT based on the GmaIoU assigner outperforms (i) ATSS with IoU by $\sim 1.0-1.5$ mask AP, (ii) YOLACT with a fixed IoU threshold assigner by $\sim 1.5-2$ mask AP over different image sizes and (iii) decreases the inference time by $25 \%$ owing to using less anchors. Taking advantage of this efficiency, we further devise GmaYOLACT, a faster and $+7$ mask AP points more accurate detector than YOLACT. Our best model achieves $38.7$ mask AP at $26$ fps on COCO test-dev establishing a new state-of-the-art for real-time instance segmentation.
Promise:Prompt-driven 3D Medical Image Segmentation Using Pretrained Image Foundation Models
Nov 13, 2023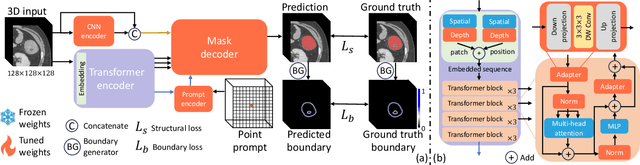

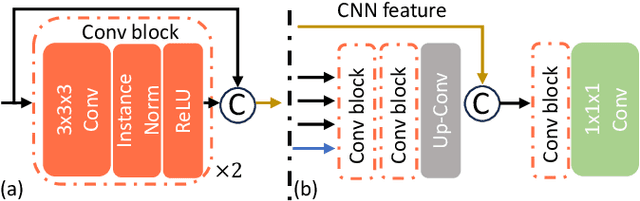
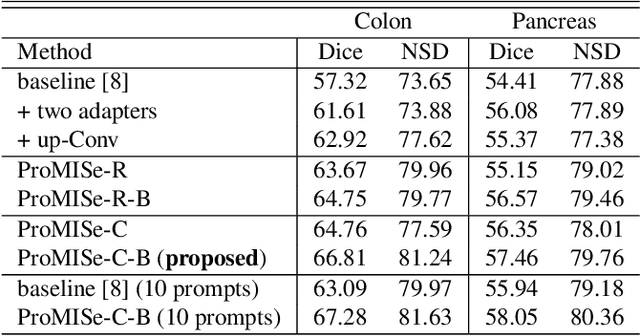
To address prevalent issues in medical imaging, such as data acquisition challenges and label availability, transfer learning from natural to medical image domains serves as a viable strategy to produce reliable segmentation results. However, several existing barriers between domains need to be broken down, including addressing contrast discrepancies, managing anatomical variability, and adapting 2D pretrained models for 3D segmentation tasks. In this paper, we propose ProMISe,a prompt-driven 3D medical image segmentation model using only a single point prompt to leverage knowledge from a pretrained 2D image foundation model. In particular, we use the pretrained vision transformer from the Segment Anything Model (SAM) and integrate lightweight adapters to extract depth-related (3D) spatial context without updating the pretrained weights. For robust results, a hybrid network with complementary encoders is designed, and a boundary-aware loss is proposed to achieve precise boundaries. We evaluate our model on two public datasets for colon and pancreas tumor segmentations, respectively. Compared to the state-of-the-art segmentation methods with and without prompt engineering, our proposed method achieves superior performance. The code is publicly available at https://github.com/MedICL-VU/ProMISe.
RTQ: Rethinking Video-language Understanding Based on Image-text Model
Dec 01, 2023Recent advancements in video-language understanding have been established on the foundation of image-text models, resulting in promising outcomes due to the shared knowledge between images and videos. However, video-language understanding presents unique challenges due to the inclusion of highly complex semantic details, which result in information redundancy, temporal dependency, and scene complexity. Current techniques have only partially tackled these issues, and our quantitative analysis indicates that some of these methods are complementary. In light of this, we propose a novel framework called RTQ (Refine, Temporal model, and Query), which addresses these challenges simultaneously. The approach involves refining redundant information within frames, modeling temporal relations among frames, and querying task-specific information from the videos. Remarkably, our model demonstrates outstanding performance even in the absence of video-language pre-training, and the results are comparable with or superior to those achieved by state-of-the-art pre-training methods.
* Accepted by ACM MM 2023 as Oral representation