 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Manipulation Localization
Apr 11, 2026Image Manipulation Localization (IML) aims to identify edited regions in an image. However, with the increasing use of modern image editing and generative models, many manipulations no longer exhibit obvious low-level artifacts. Instead, they often involve subtle but meaning-altering edits to an object's attributes, state, or relationships while remaining highly consistent with the surrounding content. This makes conventional IML methods less effective because they mainly rely on artifact detection rather than semantic sensitivity. To address this issue, we introduce Semantic Manipulation Localization (SML), a new task that focuses on localizing subtle semantic edits that significantly change image interpretation. We further construct a dedicated fine-grained benchmark for SML using a semantics-driven manipulation pipeline with pixel-level annotations. Based on this task, we propose TRACE (Targeted Reasoning of Attributed Cognitive Edits), an end-to-end framework that models semantic sensitivity through three progressively coupled components: semantic anchoring, semantic perturbation sensing, and semantic-constrained reasoning. Specifically, TRACE first identifies semantically meaningful regions that support image understanding, then injects perturbation-sensitive frequency cues to capture subtle edits under strong visual consistency, and finally verifies candidate regions through joint reasoning over semantic content and semantic scope. Extensive experiments show that TRACE consistently outperforms existing IML methods on our benchmark and produces more complete, compact, and semantically coherent localization results. These results demonstrate the necessity of moving beyond artifact-based localization and provide a new direction for image forensics in complex semantic editing scenarios.
Natural Adversarial Patch Generation Method Based on Latent Diffusion Model
Dec 27, 2023Recently, some research show that deep neural networks are vulnerable to the adversarial attacks, the well-trainned samples or patches could be used to trick the neural network detector or human visual perception. However, these adversarial patches, with their conspicuous and unusual patterns, lack camouflage and can easily raise suspicion in the real world. To solve this problem, this paper proposed a novel adversarial patch method called the Latent Diffusion Patch (LDP), in which, a pretrained encoder is first designed to compress the natural images into a feature space with key characteristics. Then trains the diffusion model using the above feature space. Finally, explore the latent space of the pretrained diffusion model using the image denoising technology. It polishes the patches and images through the powerful natural abilities of diffusion models, making them more acceptable to the human visual system. Experimental results, both digital and physical worlds, show that LDPs achieve a visual subjectivity score of 87.3%, while still maintaining effective attack capabilities.
Design and Implementation of a General Decision-making Model in RoboCup Simulation
Nov 08, 2004
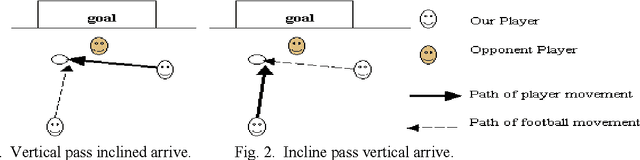
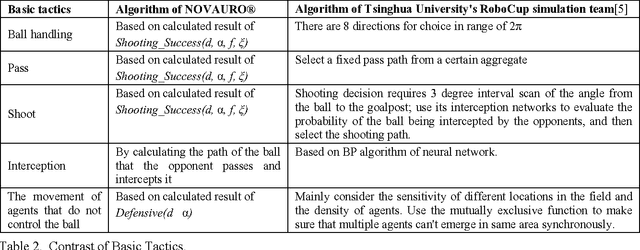
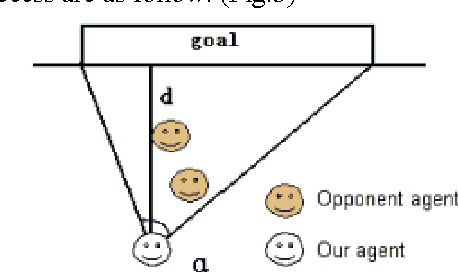
The study of the collaboration, coordination and negotiation among different agents in a multi-agent system (MAS) has always been the most challenging yet popular in the research of distributed artificial intelligence. In this paper, we will suggest for RoboCup simulation, a typical MAS, a general decision-making model, rather than define a different algorithm for each tactic (e.g. ball handling, pass, shoot and interception, etc.) in soccer games as most RoboCup simulation teams did. The general decision-making model is based on two critical factors in soccer games: the vertical distance to the goal line and the visual angle for the goalpost. We have used these two parameters to formalize the defensive and offensive decisions in RoboCup simulation and the results mentioned above had been applied in NOVAURO, original name is UJDB, a RoboCup simulation team of Jiangsu University, whose decision-making model, compared with that of Tsinghua University, the world champion team in 2001, is a universal model and easier to be implemented.