 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Treasure beneath Convolutional Layers: Cross-convolutional-layer Pooling for Image Classification
Nov 27, 2014
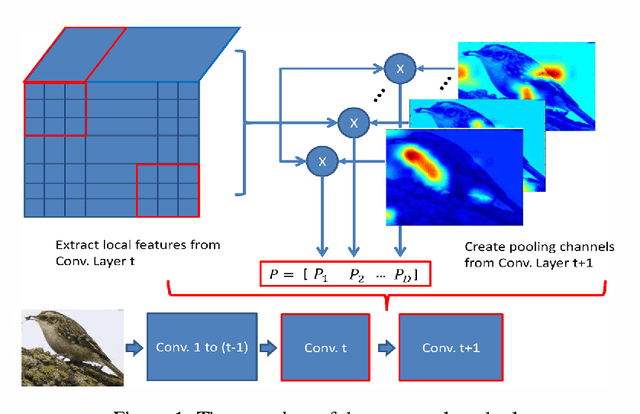
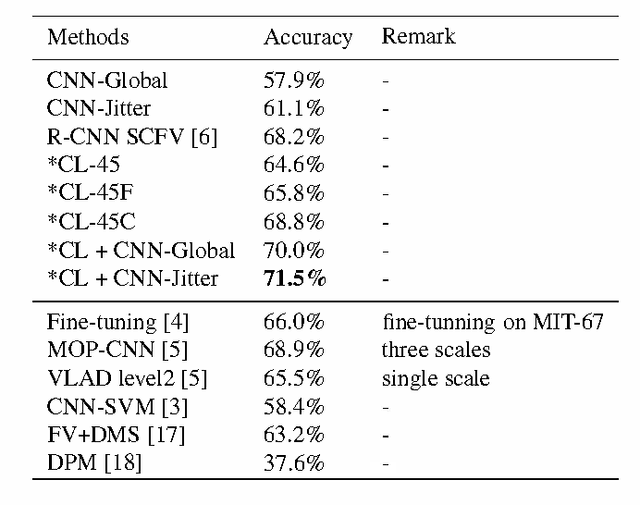

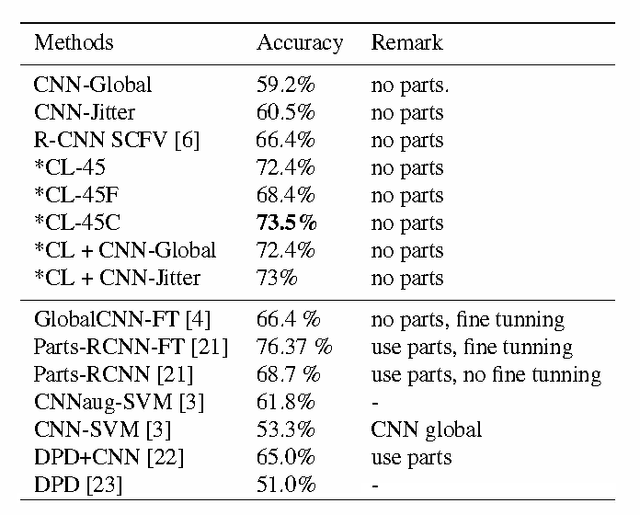
A number of recent studies have shown that a Deep Convolutional Neural Network (DCNN) pretrained on a large dataset can be adopted as a universal image description which leads to astounding performance in many visual classification tasks. Most of these studies, if not all, adopt activations of the fully-connected layer of a DCNN as the image or region representation and it is believed that convolutional layer activations are less discriminative. This paper, however, advocates that if used appropriately convolutional layer activations can be turned into a powerful image representation which enjoys many advantages over fully-connected layer activations. This is achieved by adopting a new technique proposed in this paper called cross-convolutional-layer pooling. More specifically, it extracts subarrays of feature maps of one convolutional layer as local features and pools the extracted features with the guidance of feature maps of the successive convolutional layer. Compared with exising methods that apply DCNNs in the local feature setting, the proposed method is significantly faster since it requires much fewer times of DCNN forward computation. Moreover, it avoids the domain mismatch issue which is usually encountered when applying fully connected layer activations to describe local regions. By applying our method to four popular visual classification tasks, it is demonstrated that the proposed method can achieve comparable or in some cases significantly better performance than existing fully-connected layer based image representations while incurring much lower computational cost.
Hyperspectral and Multispectral Image Fusion based on a Sparse Representation
Sep 19, 2014

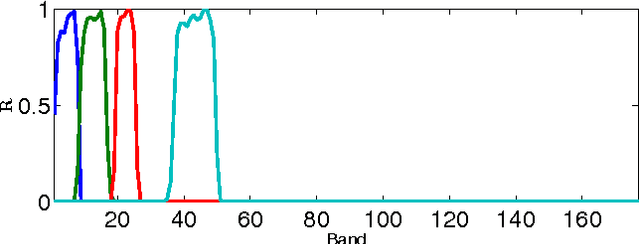

This paper presents a variational based approach to fusing hyperspectral and multispectral images. The fusion process is formulated as an inverse problem whose solution is the target image assumed to live in a much lower dimensional subspace. A sparse regularization term is carefully designed, relying on a decomposition of the scene on a set of dictionaries. The dictionary atoms and the corresponding supports of active coding coefficients are learned from the observed images. Then, conditionally on these dictionaries and supports, the fusion problem is solved via alternating optimization with respect to the target image (using the alternating direction method of multipliers) and the coding coefficients. Simulation results demonstrate the efficiency of the proposed algorithm when compared with the state-of-the-art fusion methods.
Label-Driven Reconstruction for Domain Adaptation in Semantic Segmentation
Mar 10, 2020
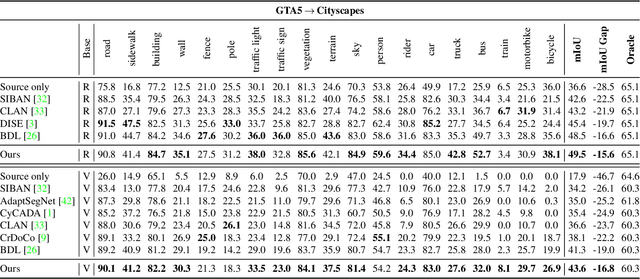
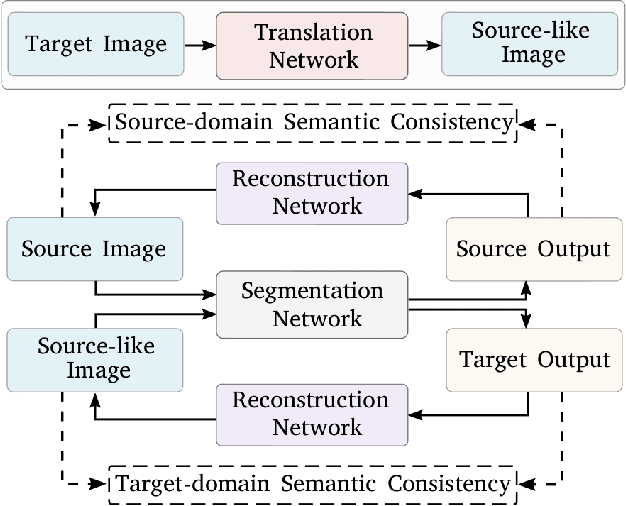
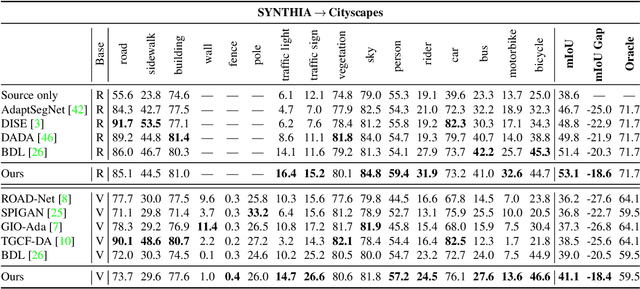
Unsupervised domain adaptation enables to alleviate the need for pixel-wise annotation in the semantic segmentation. One of the most common strategies is to translate images from the source domain to the target domain and then align their marginal distributions in the feature space using adversarial learning. However, source-to-target translation enlarges the bias in translated images, owing to the dominant data size of the source domain. Furthermore, consistency of the joint distribution in source and target domains cannot be guaranteed through global feature alignment. Here, we present an innovative framework, designed to mitigate the image translation bias and align cross-domain features with the same category. This is achieved by 1) performing the target-to-source translation and 2) reconstructing both source and target images from their predicted labels. Extensive experiments on adapting from synthetic to real urban scene understanding demonstrate that our framework competes favorably against existing state-of-the-art methods.
FMT:Fusing Multi-task Convolutional Neural Network for Person Search
Mar 01, 2020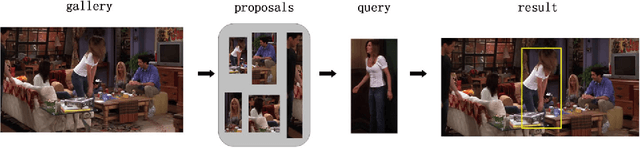
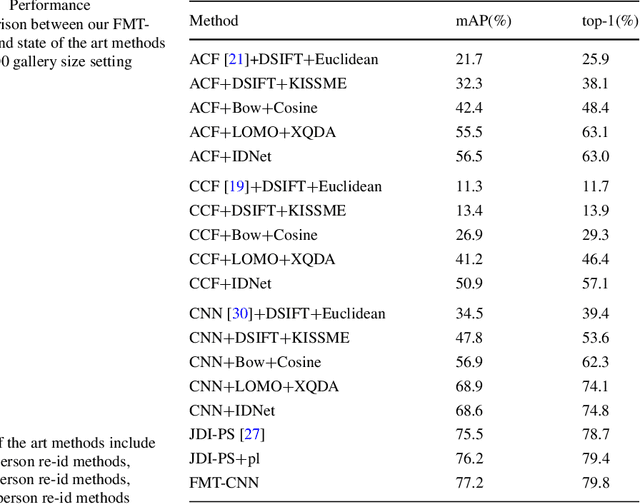
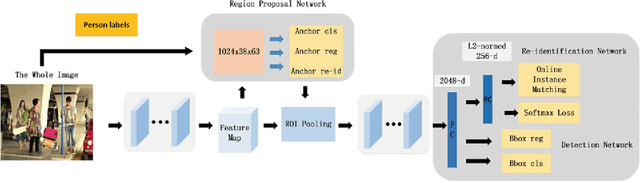
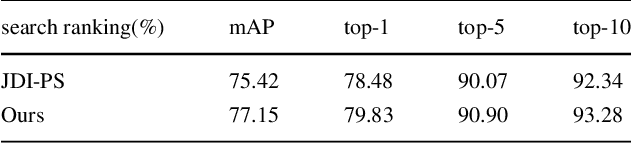
Person search is to detect all persons and identify the query persons from detected persons in the image without proposals and bounding boxes, which is different from person re-identification. In this paper, we propose a fusing multi-task convolutional neural network(FMT-CNN) to tackle the correlation and heterogeneity of detection and re-identification with a single convolutional neural network. We focus on how the interplay of person detection and person re-identification affects the overall performance. We employ person labels in region proposal network to produce features for person re-identification and person detection network, which can improve the accuracy of detection and re-identification simultaneously. We also use a multiple loss to train our re-identification network. Experiment results on CUHK-SYSU Person Search dataset show that the performance of our proposed method is superior to state-of-the-art approaches in both mAP and top-1.
Towards Accurate Scene Text Recognition with Semantic Reasoning Networks
Mar 27, 2020
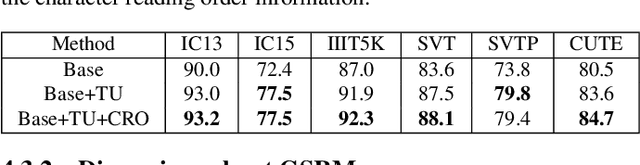
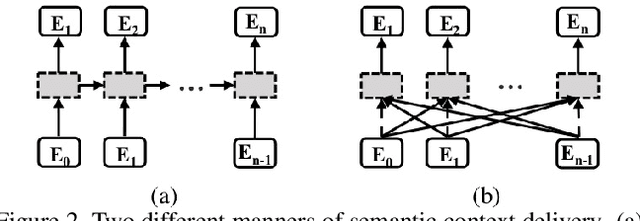
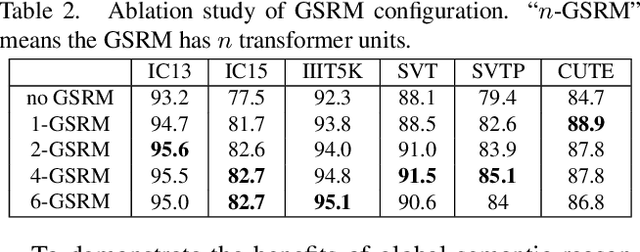
Scene text image contains two levels of contents: visual texture and semantic information. Although the previous scene text recognition methods have made great progress over the past few years, the research on mining semantic information to assist text recognition attracts less attention, only RNN-like structures are explored to implicitly model semantic information. However, we observe that RNN based methods have some obvious shortcomings, such as time-dependent decoding manner and one-way serial transmission of semantic context, which greatly limit the help of semantic information and the computation efficiency. To mitigate these limitations, we propose a novel end-to-end trainable framework named semantic reasoning network (SRN) for accurate scene text recognition, where a global semantic reasoning module (GSRM) is introduced to capture global semantic context through multi-way parallel transmission. The state-of-the-art results on 7 public benchmarks, including regular text, irregular text and non-Latin long text, verify the effectiveness and robustness of the proposed method. In addition, the speed of SRN has significant advantages over the RNN based methods, demonstrating its value in practical use.
Recent Developments Combining Ensemble Smoother and Deep Generative Networks for Facies History Matching
May 08, 2020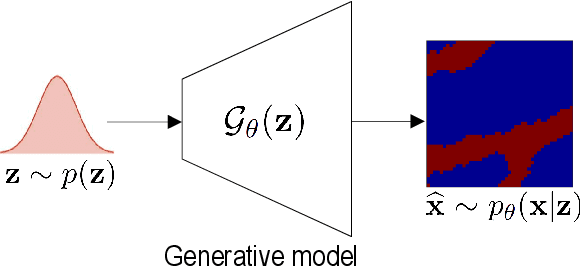
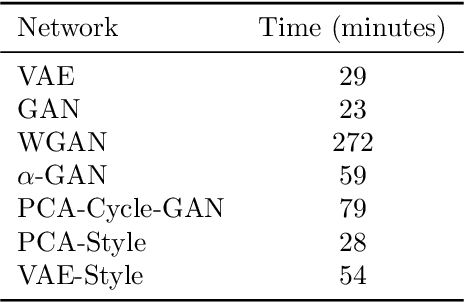
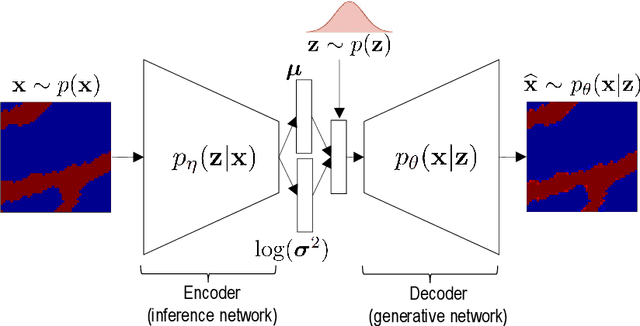
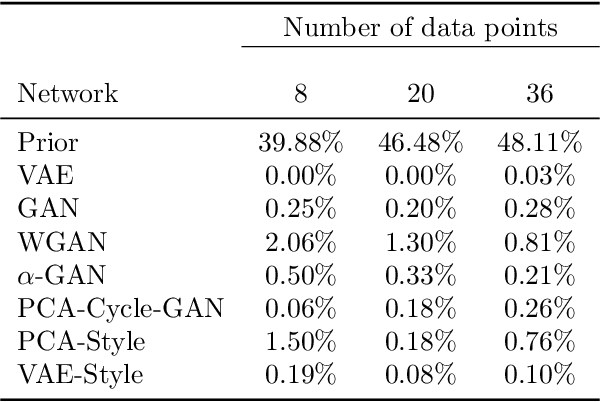
Ensemble smoothers are among the most successful and efficient techniques currently available for history matching. However, because these methods rely on Gaussian assumptions, their performance is severely degraded when the prior geology is described in terms of complex facies distributions. Inspired by the impressive results obtained by deep generative networks in areas such as image and video generation, we started an investigation focused on the use of autoencoders networks to construct a continuous parameterization for facies models. In our previous publication, we combined a convolutional variational autoencoder (VAE) with the ensemble smoother with multiple data assimilation (ES-MDA) for history matching production data in models generated with multiple-point geostatistics. Despite the good results reported in our previous publication, a major limitation of the designed parameterization is the fact that it does not allow applying distance-based localization during the ensemble smoother update, which limits its application in large-scale problems. The present work is a continuation of this research project focusing in two aspects: firstly, we benchmark seven different formulations, including VAE, generative adversarial network (GAN), Wasserstein GAN, variational auto-encoding GAN, principal component analysis (PCA) with cycle GAN, PCA with transfer style network and VAE with style loss. These formulations are tested in a synthetic history matching problem with channelized facies. Secondly, we propose two strategies to allow the use of distance-based localization with the deep learning parameterizations.
Deep End-to-End Alignment and Refinement for Time-of-Flight RGB-D Module
Sep 17, 2019
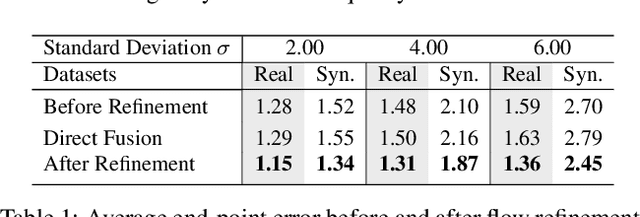
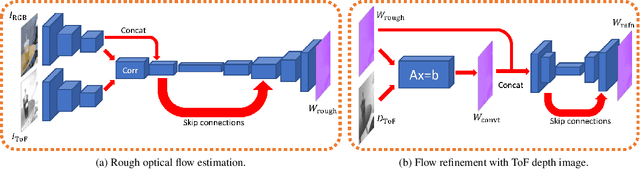
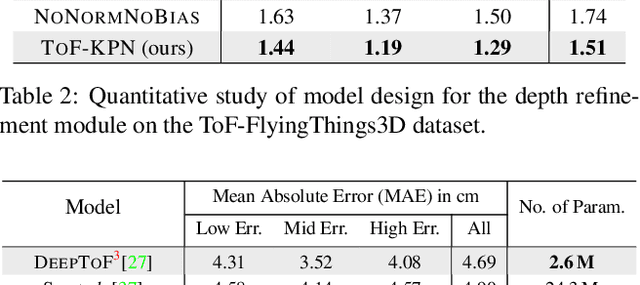
Recently, it is increasingly popular to equip mobile RGB cameras with Time-of-Flight (ToF) sensors for active depth sensing. However, for off-the-shelf ToF sensors, one must tackle two problems in order to obtain high-quality depth with respect to the RGB camera, namely 1) online calibration and alignment; and 2) complicated error correction for ToF depth sensing. In this work, we propose a framework for jointly alignment and refinement via deep learning. First, a cross-modal optical flow between the RGB image and the ToF amplitude image is estimated for alignment. The aligned depth is then refined via an improved kernel predicting network that performs kernel normalization and applies the bias prior to the dynamic convolution. To enrich our data for end-to-end training, we have also synthesized a dataset using tools from computer graphics. Experimental results demonstrate the effectiveness of our approach, achieving state-of-the-art for ToF refinement.
Deep Set Prediction Networks
Jun 15, 2019
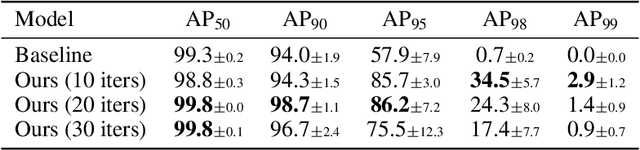
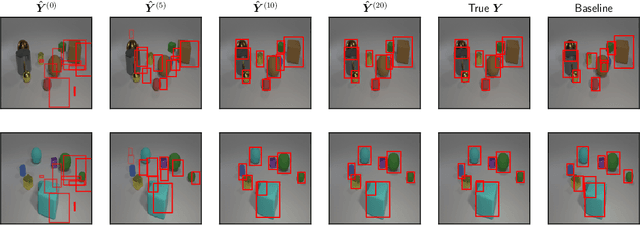
We study the problem of predicting a set from a feature vector with a deep neural network. Existing approaches ignore the set structure of the problem and suffer from discontinuity issues as a result. We propose a general model for predicting sets that properly respects the structure of sets and avoids this problem. With a single feature vector as input, we show that our model is able to auto-encode point sets, predict bounding boxes of the set of objects in an image, and predict the attributes of these objects in an image.
Efficient Splitting-based Method for Global Image Smoothing
Apr 26, 2016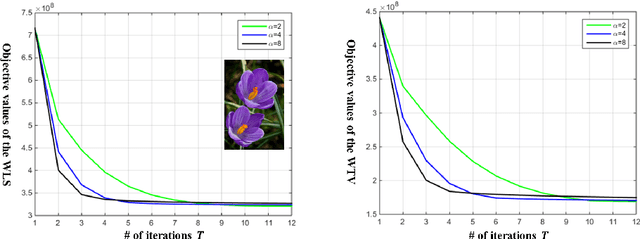

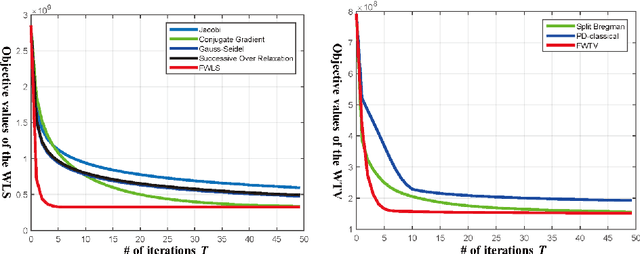
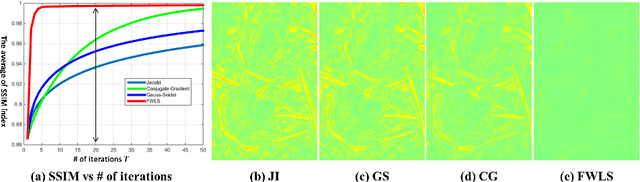
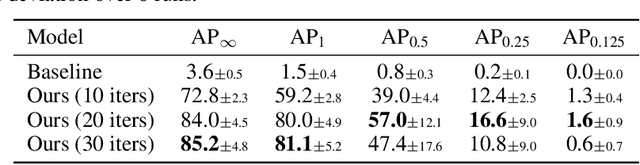
Edge-preserving smoothing (EPS) can be formulated as minimizing an objective function that consists of data and prior terms. This global EPS approach shows better smoothing performance than a local one that typically has a form of weighted averaging, at the price of high computational cost. In this paper, we introduce a highly efficient splitting-based method for global EPS that minimizes the objective function of ${l_2}$ data and prior terms (possibly non-smooth and non-convex) in linear time. Different from previous splitting-based methods that require solving a large linear system, our approach solves an equivalent constrained optimization problem, resulting in a sequence of 1D sub-problems. This enables linear time solvers for weighted-least squares and -total variation problems. Our solver converges quickly, and its runtime is even comparable to state-of-the-art local EPS approaches. We also propose a family of fast iteratively re-weighted algorithms using a non-convex prior term. Experimental results demonstrate the effectiveness and flexibility of our approach in a range of computer vision and image processing tasks.
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
May 15, 2019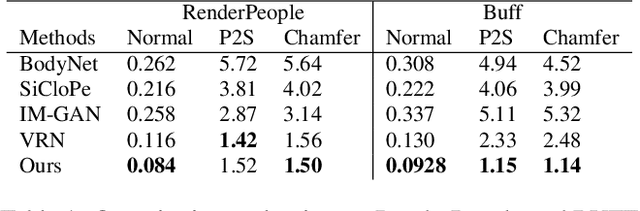
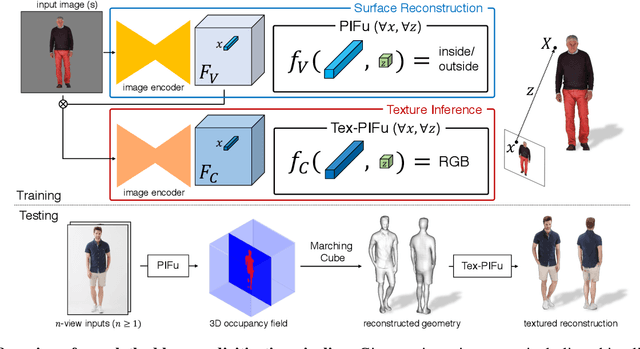

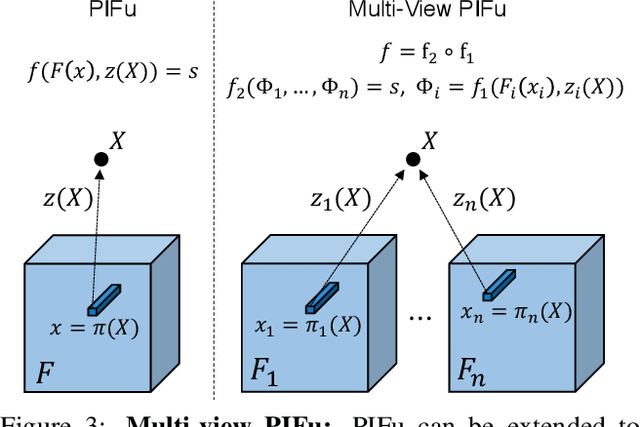
We introduce Pixel-aligned Implicit Function (PIFu), a highly effective implicit representation that locally aligns pixels of 2D images with the global context of their corresponding 3D object. Using PIFu, we propose an end-to-end deep learning method for digitizing highly detailed clothed humans that can infer both 3D surface and texture from a single image, and optionally, multiple input images. Highly intricate shapes, such as hairstyles, clothing, as well as their variations and deformations can be digitized in a unified way. Compared to existing representations used for 3D deep learning, PIFu can produce high-resolution surfaces including largely unseen regions such as the back of a person. In particular, it is memory efficient unlike the voxel representation, can handle arbitrary topology, and the resulting surface is spatially aligned with the input image. Furthermore, while previous techniques are designed to process either a single image or multiple views, PIFu extends naturally to arbitrary number of views. We demonstrate high-resolution and robust reconstructions on real world images from the DeepFashion dataset, which contains a variety of challenging clothing types. Our method achieves state-of-the-art performance on a public benchmark and outperforms the prior work for clothed human digitization from a single image.