 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Driven Reconstruction for Domain Adaptation in Semantic Segmentation
Paper and Code
Mar 10, 2020
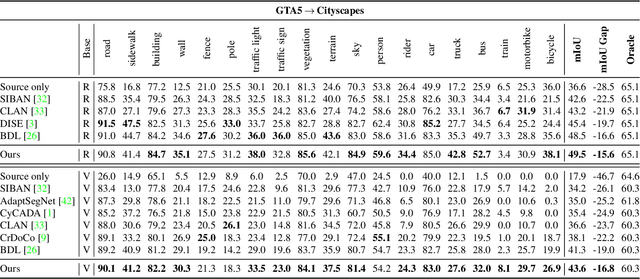
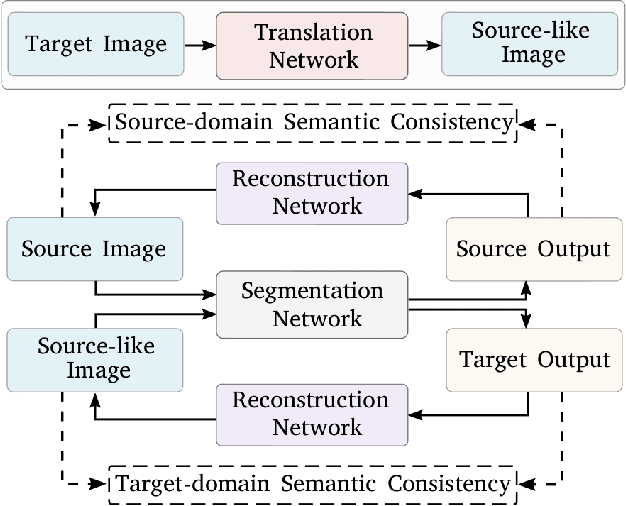
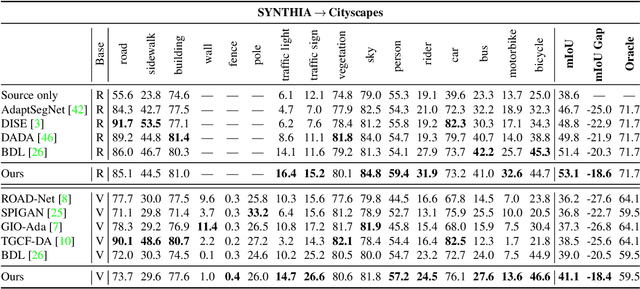
Unsupervised domain adaptation enables to alleviate the need for pixel-wise annotation in the semantic segmentation. One of the most common strategies is to translate images from the source domain to the target domain and then align their marginal distributions in the feature space using adversarial learning. However, source-to-target translation enlarges the bias in translated images, owing to the dominant data size of the source domain. Furthermore, consistency of the joint distribution in source and target domains cannot be guaranteed through global feature alignment. Here, we present an innovative framework, designed to mitigate the image translation bias and align cross-domain features with the same category. This is achieved by 1) performing the target-to-source translation and 2) reconstructing both source and target images from their predicted labels. Extensive experiments on adapting from synthetic to real urban scene understanding demonstrate that our framework competes favorably against existing state-of-the-art methods.