 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Remix: Rebalanced Mixup
Jul 08, 2020
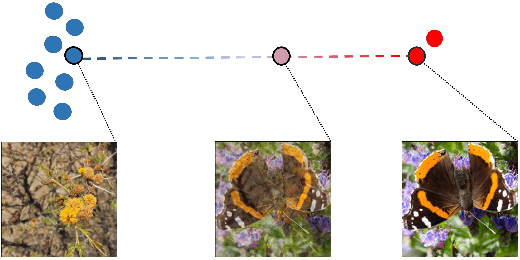
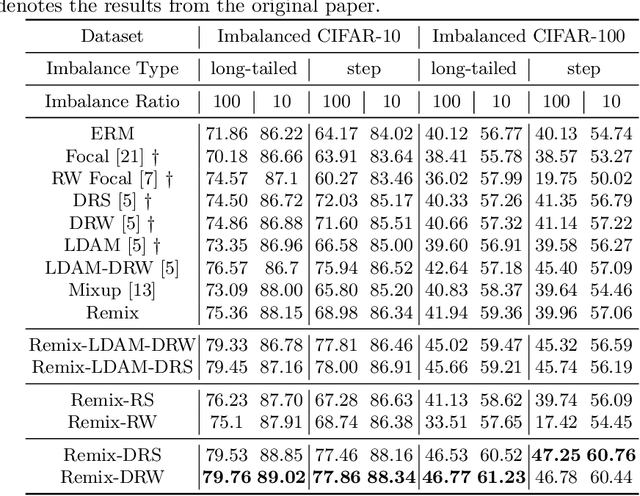
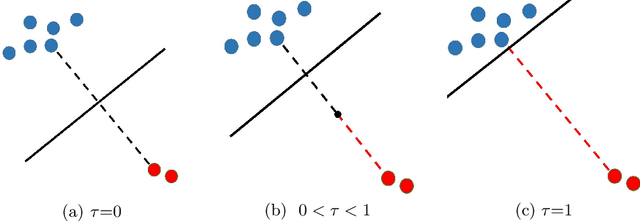
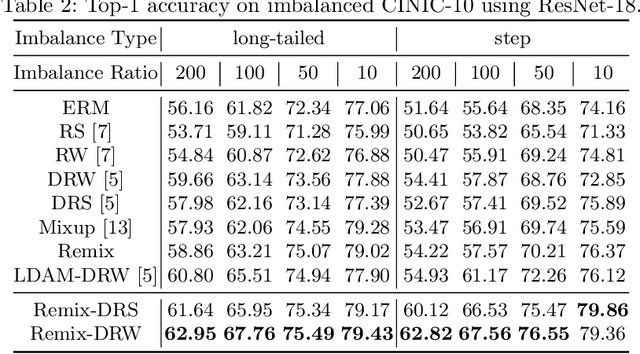
Deep image classifiers often perform poorly when training data are heavily class-imbalanced. In this work, we propose a new regularization technique, Remix, that relaxes Mixup's formulation and enables the mixing factors of features and labels to be disentangled. Specifically, when mixing two samples, while features are mixed up proportionally in the same fashion as Mixup methods, Remix assigns the label in favor of the minority class by providing a disproportionately higher weight to the minority class. By doing so, the classifier learns to push the decision boundaries towards the majority classes and balances the generalization error between majority and minority classes. We have studied the state of the art regularization techniques such as Mixup, Manifold Mixup and CutMix under class-imbalanced regime, and shown that the proposed Remix significantly outperforms these state-of-the-arts and several re-weighting and re-sampling techniques, on the imbalanced datasets constructed by CIFAR-10, CIFAR-100, and CINIC-10. We have also evaluated Remix on a real-world large-scale imbalanced dataset, iNaturalist 2018. The experimental results confirmed that Remix provides consistent and significant improvements over the previous state-of-the-arts.
Self-supervised Deformation Modeling for Facial Expression Editing
Nov 05, 2019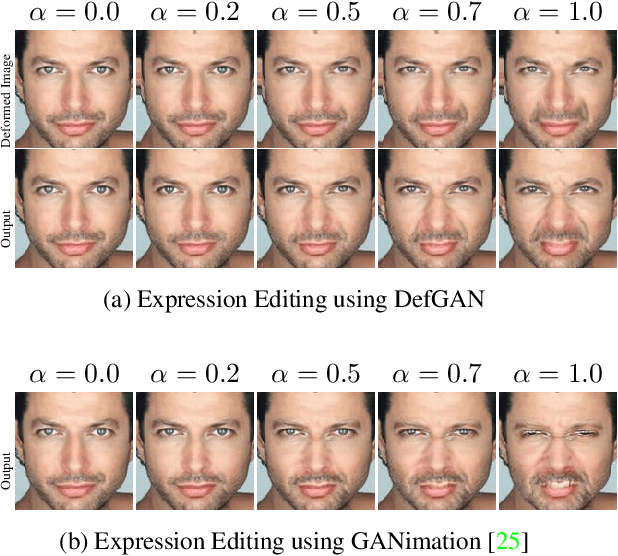

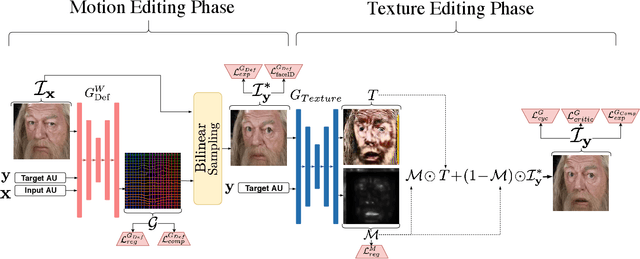
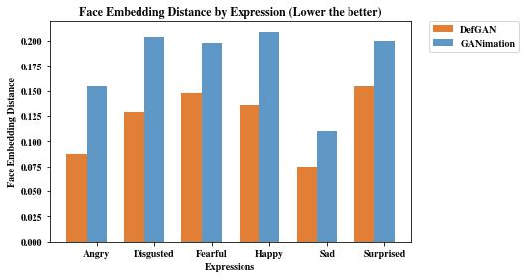
Recent advances in deep generative models have demonstrated impressive results in photo-realistic facial image synthesis and editing. Facial expressions are inherently the result of muscle movement. However, existing neural network-based approaches usually only rely on texture generation to edit expressions and largely neglect the motion information. In this work, we propose a novel end-to-end network that disentangles the task of facial editing into two steps: a " "motion-editing" step and a "texture-editing" step. In the "motion-editing" step, we explicitly model facial movement through image deformation, warping the image into the desired expression. In the "texture-editing" step, we generate necessary textures, such as teeth and shading effects, for a photo-realistic result. Our physically-based task-disentanglement system design allows each step to learn a focused task, removing the need of generating texture to hallucinate motion. Our system is trained in a self-supervised manner, requiring no ground truth deformation annotation. Using Action Units [8] as the representation for facial expression, our method improves the state-of-the-art facial expression editing performance in both qualitative and quantitative evaluations.
Removing Clouds and Recovering Ground Observations in Satellite Image Sequences via Temporally Contiguous Robust Matrix Completion
Apr 13, 2016


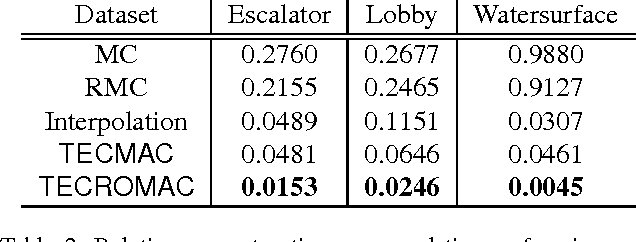
We consider the problem of removing and replacing clouds in satellite image sequences, which has a wide range of applications in remote sensing. Our approach first detects and removes the cloud-contaminated part of the image sequences. It then recovers the missing scenes from the clean parts using the proposed "TECROMAC" (TEmporally Contiguous RObust MAtrix Completion) objective. The objective function balances temporal smoothness with a low rank solution while staying close to the original observations. The matrix whose the rows are pixels and columnsare days corresponding to the image, has low-rank because the pixels reflect land-types such as vegetation, roads and lakes and there are relatively few variations as a result. We provide efficient optimization algorithms for TECROMAC, so we can exploit images containing millions of pixels. Empirical results on real satellite image sequences, as well as simulated data, demonstrate that our approach is able to recover underlying images from heavily cloud-contaminated observations.
Sparse-to-Dense Hypercolumn Matching for Long-Term Visual Localization
Jul 09, 2019
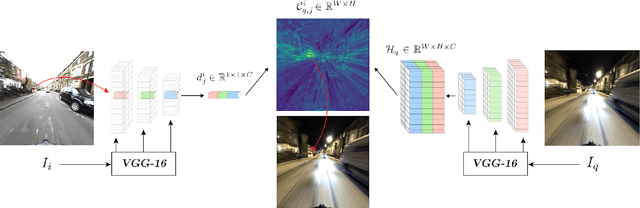
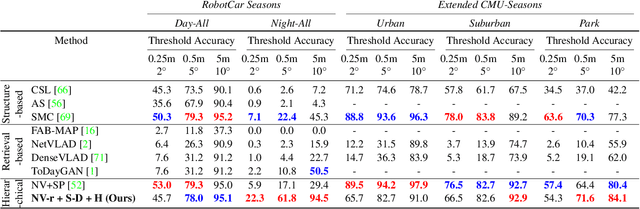
We propose a novel approach to feature point matching, suitable for robust and accurate outdoor visual localization in long-term scenarios. Given a query image, we first match it against a database of registered reference images, using recent retrieval techniques. This gives us a first estimate of the camera pose. To refine this estimate, like previous approaches, we match 2D points across the query image and the retrieved reference image. This step, however, is prone to fail as it is still very difficult to detect and match sparse feature points across images captured in potentially very different conditions. Our key contribution is to show that we need to extract sparse feature points only in the retrieved reference image: We then search for the corresponding 2D locations in the query image exhaustively. This search can be performed efficiently using convolutional operations, and robustly by using hypercolumn descriptors, i.e. image features computed for retrieval. We refer to this method as Sparse-to-Dense Hypercolumn Matching. Because we know the 3D locations of the sparse feature points in the reference images thanks to an offline reconstruction stage, it is then possible to accurately estimate the camera pose from these matches. Our experiments show that this method allows us to outperform the state-of-the-art on several challenging outdoor datasets.
Low-dimensional Manifold Constrained Disentanglement Network for Metal Artifact Reduction
Jul 08, 2020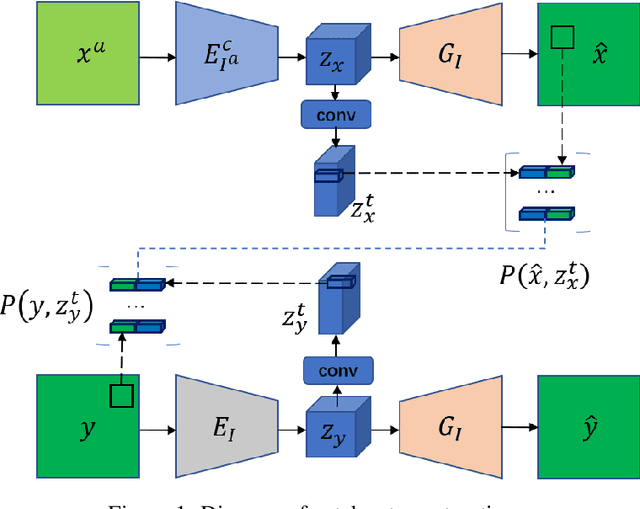
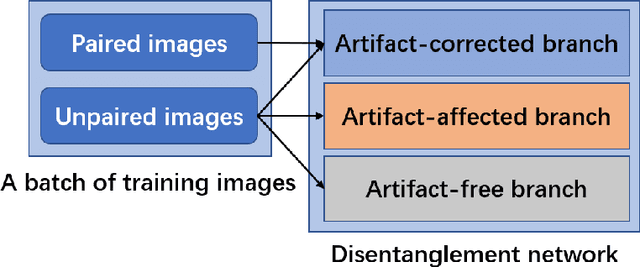
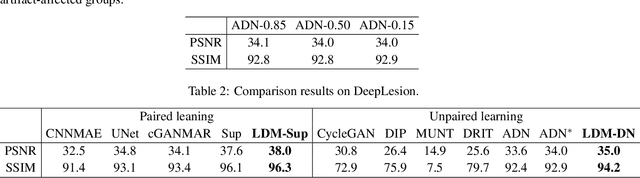
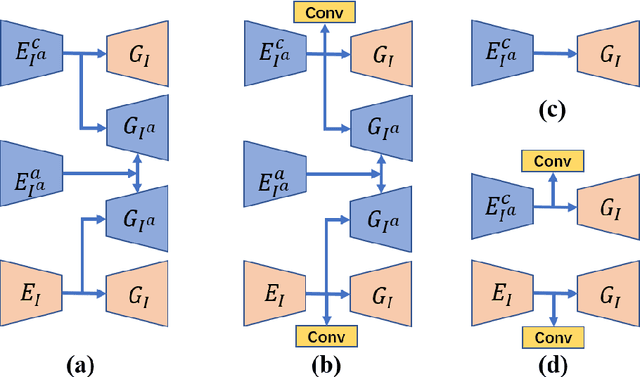
Deep neural network based methods have achieved promising results for CT metal artifact reduction (MAR), most of which use many synthesized paired images for training. As synthesized metal artifacts in CT images may not accurately reflect the clinical counterparts, an artifact disentanglement network (ADN) was proposed with unpaired clinical images directly, producing promising results on clinical datasets. However, without sufficient supervision, it is difficult for ADN to recover structural details of artifact-affected CT images based on adversarial losses only. To overcome these problems, here we propose a low-dimensional manifold (LDM) constrained disentanglement network (DN), leveraging the image characteristics that the patch manifold is generally low-dimensional. Specifically, we design an LDM-DN learning algorithm to empower the disentanglement network through optimizing the synergistic network loss functions while constraining the recovered images to be on a low-dimensional patch manifold. Moreover, learning from both paired and unpaired data, an efficient hybrid optimization scheme is proposed to further improve the MAR performance on clinical datasets. Extensive experiments demonstrate that the proposed LDM-DN approach can consistently improve the MAR performance in paired and/or unpaired learning settings, outperforming competing methods on synthesized and clinical datasets.
COVIDNet-CT: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest CT Images
Sep 08, 2020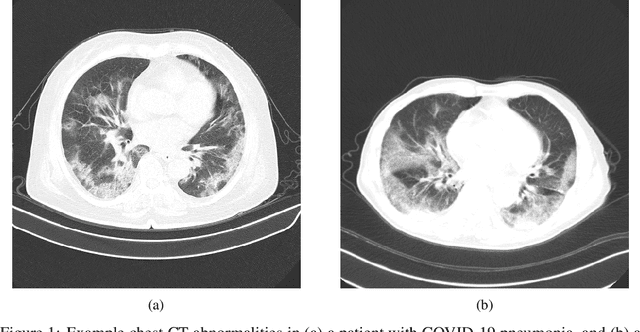

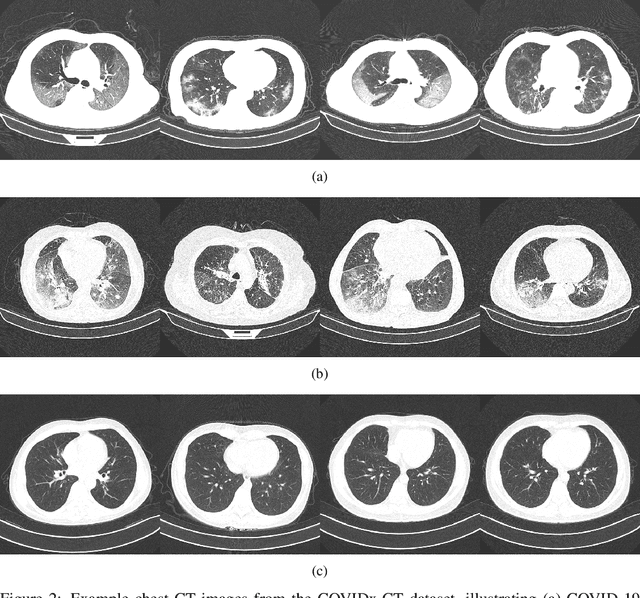
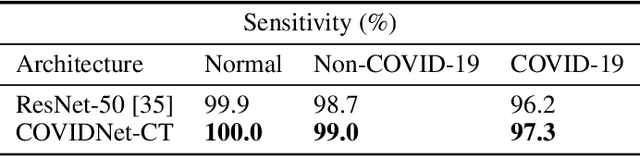
The coronavirus disease 2019 (COVID-19) pandemic continues to have a tremendous impact on patients and healthcare systems around the world. In the fight against this novel disease, there is a pressing need for rapid and effective screening tools to identify patients infected with COVID-19, and to this end CT imaging has been proposed as one of the key screening methods which may be used as a complement to RT-PCR testing, particularly in situations where patients undergo routine CT scans for non-COVID-19 related reasons, patients with worsening respiratory status or developing complications that require expedited care, and patients suspected to be COVID-19-positive but have negative RT-PCR test results. Motivated by this, in this study we introduce COVIDNet-CT, a deep convolutional neural network architecture that is tailored for detection of COVID-19 cases from chest CT images via a machine-driven design exploration approach. Additionally, we introduce COVIDx-CT, a benchmark CT image dataset derived from CT imaging data collected by the China National Center for Bioinformation comprising 104,009 images across 1,489 patient cases. Furthermore, in the interest of reliability and transparency, we leverage an explainability-driven performance validation strategy to investigate the decision-making behaviour of COVIDNet-CT, and in doing so ensure that COVIDNet-CT makes predictions based on relevant indicators in CT images. Both COVIDNet-CT and the COVIDx-CT dataset are available to the general public in an open-source and open access manner as part of the COVID-Net initiative. While COVIDNet-CT is not yet a production-ready screening solution, we hope that releasing the model and dataset will encourage researchers, clinicians, and citizen data scientists alike to leverage and build upon them.
Adversarial Attacks and Defense on Texts: A Survey
May 31, 2020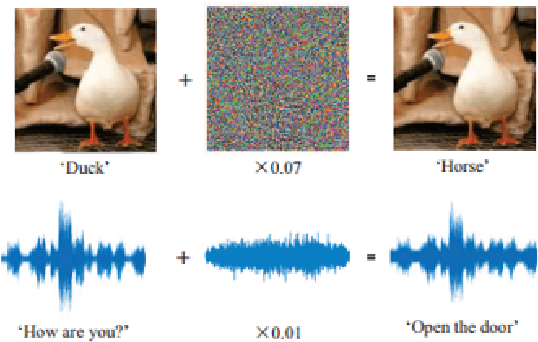
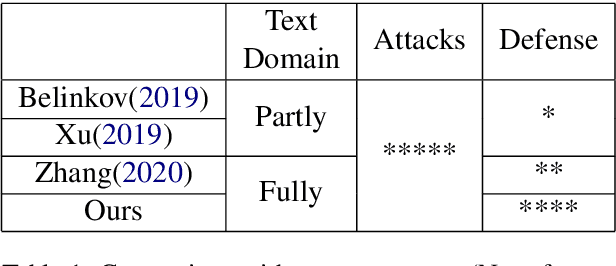
Deep leaning models have been used widely for various purposes in recent years in object recognition, self-driving cars, face recognition, speech recognition, sentiment analysis and many others. However, in recent years it has been shown that these models possess weakness to noises which forces the model to misclassify. This issue has been studied profoundly in image and audio domain. Very little has been studied on this issue with respect to textual data. Even less survey on this topic has been performed to understand different types of attacks and defense techniques. In this manuscript we accumulated and analyzed different attacking techniques, various defense models on how to overcome this issue in order to provide a more comprehensive idea. Later we point out some of the interesting findings of all papers and challenges that need to be overcome in order to move forward in this field.
Fast Dictionary Matching for Content-based Image Retrieval
Apr 26, 2015

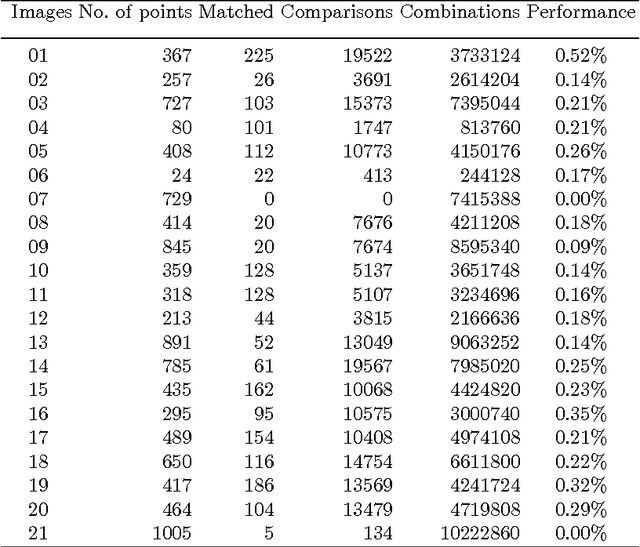
This paper describes a method for searching for common sets of descriptors between collections of images. The presented method operates on local interest keypoints, which are generated using the SURF algorithm. The use of a dictionary of descriptors allowed achieving good performance of the content-based image retrieval. The method can be used to initially determine a set of similar pairs of keypoints between images. For this purpose, we use a certain level of tolerance between values of descriptors, as values of feature descriptors are almost never equal but similar between different images. After that, the method compares the structure of rotation and location of interest points in one image with the point structure in other images. Thus, we were able to find similar areas in images and determine the level of similarity between them, even when images contain different scenes.
Learned Proximal Networks for Quantitative Susceptibility Mapping
Aug 11, 2020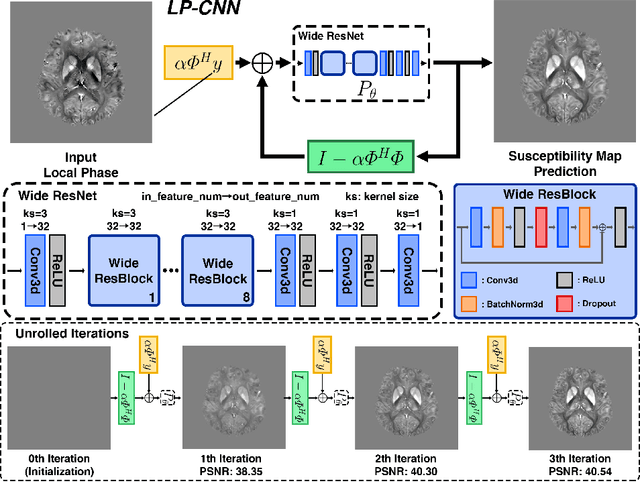
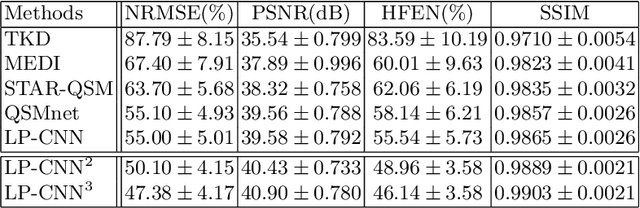
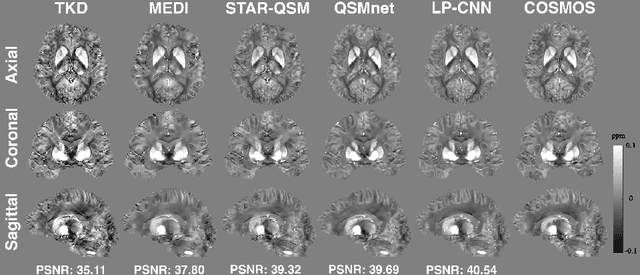

Quantitative Susceptibility Mapping (QSM) estimates tissue magnetic susceptibility distributions from Magnetic Resonance (MR) phase measurements by solving an ill-posed dipole inversion problem. Conventional single orientation QSM methods usually employ regularization strategies to stabilize such inversion, but may suffer from streaking artifacts or over-smoothing. Multiple orientation QSM such as calculation of susceptibility through multiple orientation sampling (COSMOS) can give well-conditioned inversion and an artifact free solution but has expensive acquisition costs. On the other hand, Convolutional Neural Networks (CNN) show great potential for medical image reconstruction, albeit often with limited interpretability. Here, we present a Learned Proximal Convolutional Neural Network (LP-CNN) for solving the ill-posed QSM dipole inversion problem in an iterative proximal gradient descent fashion. This approach combines the strengths of data-driven restoration priors and the clear interpretability of iterative solvers that can take into account the physical model of dipole convolution. During training, our LP-CNN learns an implicit regularizer via its proximal, enabling the decoupling between the forward operator and the data-driven parameters in the reconstruction algorithm. More importantly, this framework is believed to be the first deep learning QSM approach that can naturally handle an arbitrary number of phase input measurements without the need for any ad-hoc rotation or re-training. We demonstrate that the LP-CNN provides state-of-the-art reconstruction results compared to both traditional and deep learning methods while allowing for more flexibility in the reconstruction process.
FakeLocator: Robust Localization of GAN-Based Face Manipulations via Semantic Segmentation Networks with Bells and Whistles
Feb 21, 2020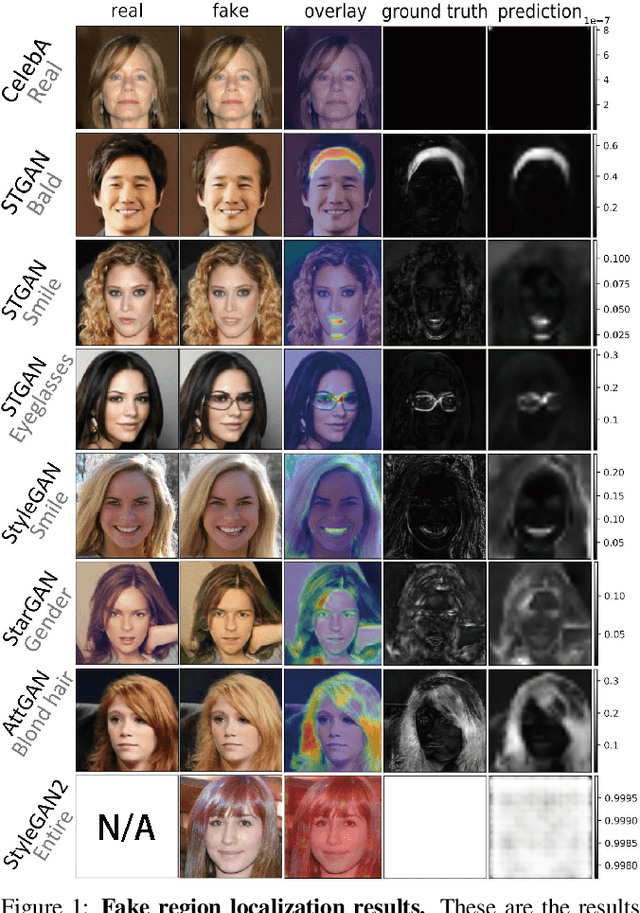
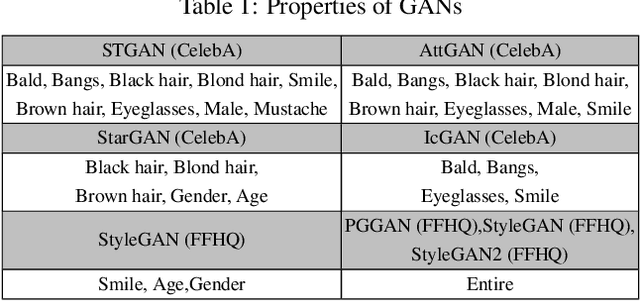
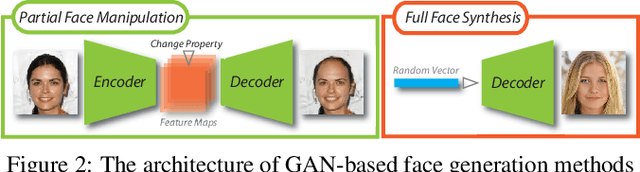
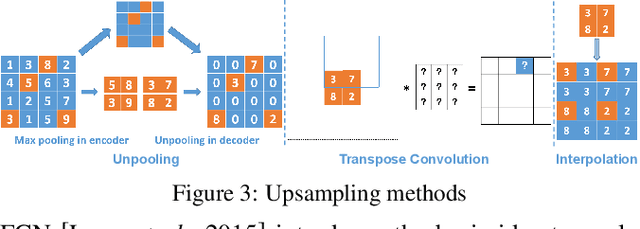
Nowadays, full face synthesis and partial face manipulation by virtue of the generative adversarial networks (GANs) have raised wide public concern. In the digital media forensics area, detecting and ultimately locating the image forgery have become imperative. Although many methods focus on fake detection, only a few put emphasis on the localization of the fake regions. Through analyzing the imperfection in the upsampling procedures of the GAN-based methods and recasting the fake localization problem as a modified semantic segmentation one, our proposed FakeLocator can obtain high localization accuracy, at full resolution, on manipulated facial images. To the best of our knowledge, this is the very first attempt to solve the GAN-based fake localization problem with a semantic segmentation map. As an improvement, the real-numbered segmentation map proposed by us preserves more information of fake regions. For this new type segmentation map, we also find suitable loss functions for it. Experimental results on the CelebA and FFHQ databases with seven different SOTA GAN-based face generation methods show the effectiveness of our method. Compared with the baseline, our method performs several times better on various metrics. Moreover, the proposed method is robust against various real-world facial image degradations such as JPEG compression, low-resolution, noise, and blur.