 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explainable Disease Classification via weakly-supervised segmentation
Aug 24, 2020

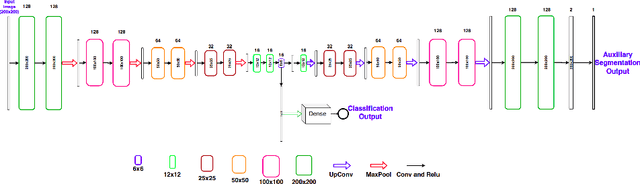
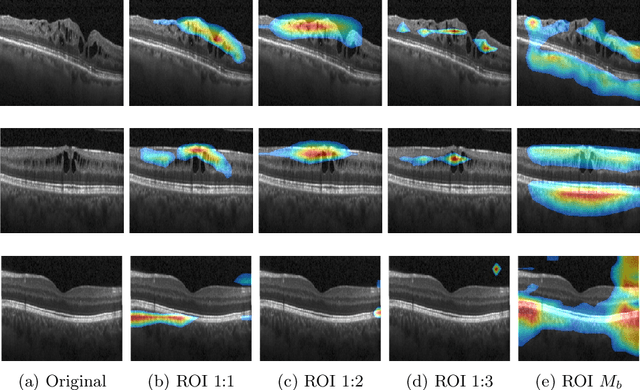
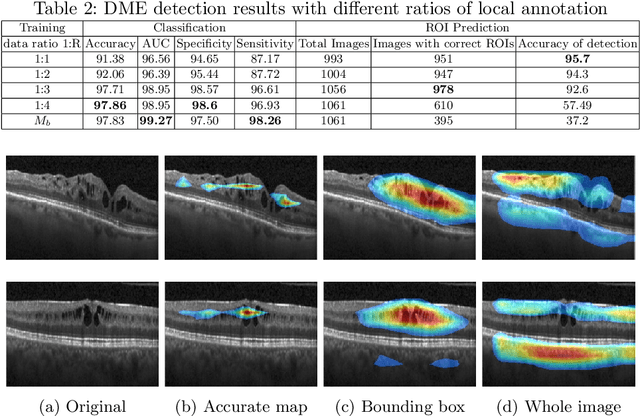
Deep learning based approaches to Computer Aided Diagnosis (CAD) typically pose the problem as an image classification (Normal or Abnormal) problem. These systems achieve high to very high accuracy in specific disease detection for which they are trained but lack in terms of an explanation for the provided decision/classification result. The activation maps which correspond to decisions do not correlate well with regions of interest for specific diseases. This paper examines this problem and proposes an approach which mimics the clinical practice of looking for an evidence prior to diagnosis. A CAD model is learnt using a mixed set of information: class labels for the entire training set of images plus a rough localisation of suspect regions as an extra input for a smaller subset of training images for guiding the learning. The proposed approach is illustrated with detection of diabetic macular edema (DME) from OCT slices. Results of testing on on a large public dataset show that with just a third of images with roughly segmented fluid filled regions, the classification accuracy is on par with state of the art methods while providing a good explanation in the form of anatomically accurate heatmap /region of interest. The proposed solution is then adapted to Breast Cancer detection from mammographic images. Good evaluation results on public datasets underscores the generalisability of the proposed solution.
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
Apr 28, 2020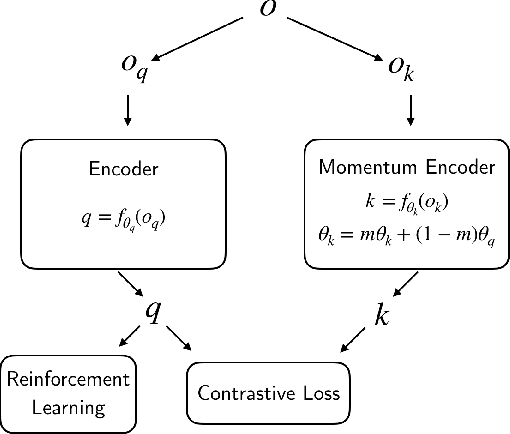
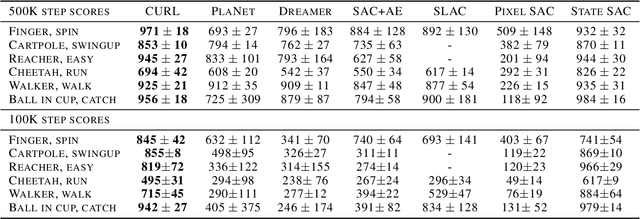
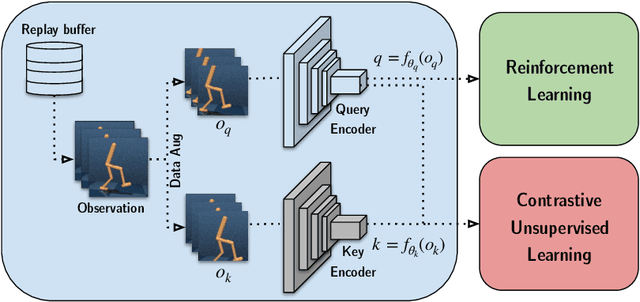
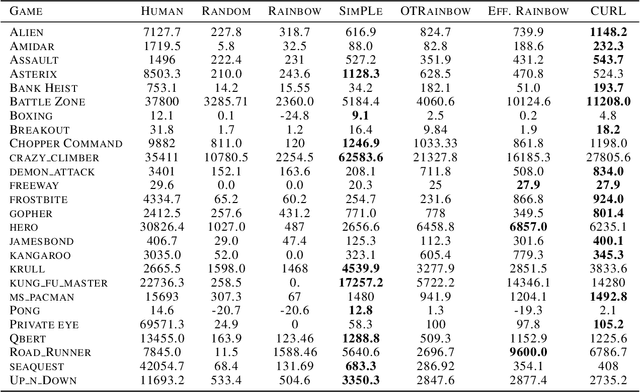
We present CURL: Contrastive Unsupervised Representations for Reinforcement Learning. CURL extracts high-level features from raw pixels using contrastive learning and performs off-policy control on top of the extracted features. CURL outperforms prior pixel-based methods, both model-based and model-free, on complex tasks in the DeepMind Control Suite and Atari Games showing 1.9x and 1.6x performance gains at the 100K environment and interaction steps benchmarks respectively. On the DeepMind Control Suite, CURL is the first image-based algorithm to nearly match the sample-efficiency and performance of methods that use state-based features.
TransCut: Transparent Object Segmentation from a Light-Field Image
Nov 21, 2015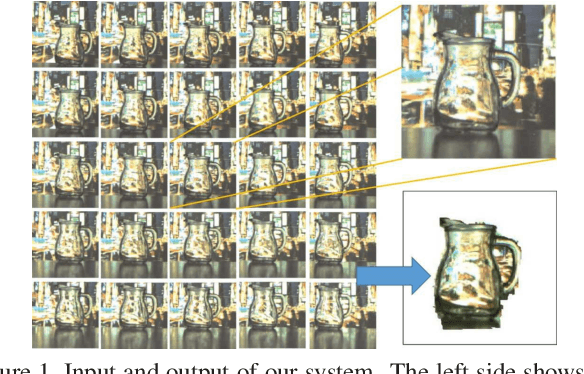
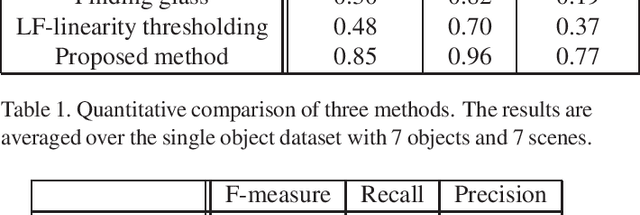
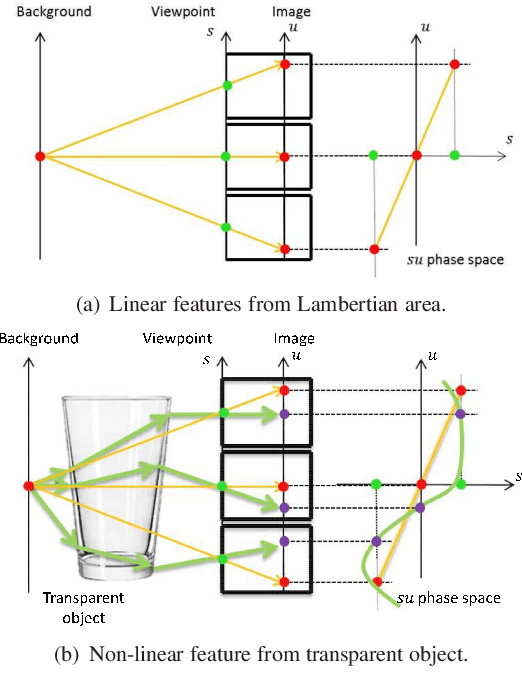
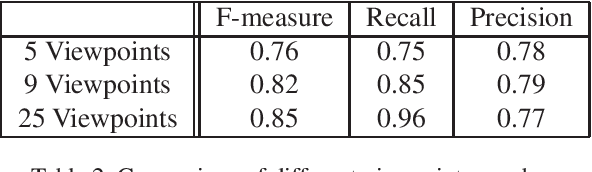
The segmentation of transparent objects can be very useful in computer vision applications. However, because they borrow texture from their background and have a similar appearance to their surroundings, transparent objects are not handled well by regular image segmentation methods. We propose a method that overcomes these problems using the consistency and distortion properties of a light-field image. Graph-cut optimization is applied for the pixel labeling problem. The light-field linearity is used to estimate the likelihood of a pixel belonging to the transparent object or Lambertian background, and the occlusion detector is used to find the occlusion boundary. We acquire a light field dataset for the transparent object, and use this dataset to evaluate our method. The results demonstrate that the proposed method successfully segments transparent objects from the background.
Robust Submodular Minimization with Applications to Cooperative Modeling
Jan 25, 2020

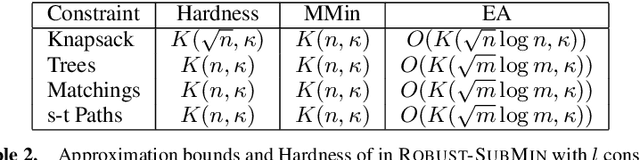
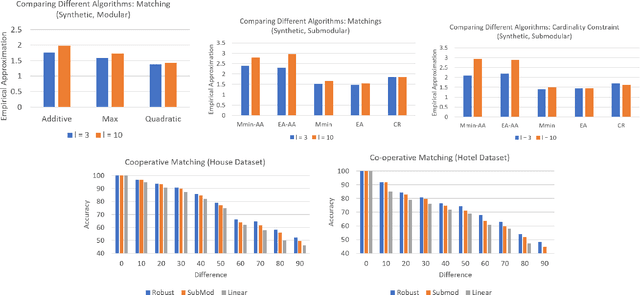
Robust Optimization is becoming increasingly important in machine learning applications. This paper studies the problem of robust submodular minimization subject to combinatorial constraints. Constrained Submodular Minimization arises in several applications such as co-operative cuts in image segmentation, co-operative matchings in image correspondence, etc. Many of these models are defined over clusterings of data points (for example pixels in images), and it is important for these models to be robust to perturbations and uncertainty in the data. While several existing papers have studied robust submodular maximization, ours is the first work to study the minimization version under a broad range of combinatorial constraints including cardinality, knapsack, matroid as well as graph-based constraints such as cuts, paths, matchings, and trees. In each case, we provide scalable approximation algorithms and also study hardness bounds. Finally, we empirically demonstrate the utility of our algorithms on synthetic and real-world datasets.
Deep Generalization of Structured Low Rank Algorithms (Deep-SLR)
Dec 07, 2019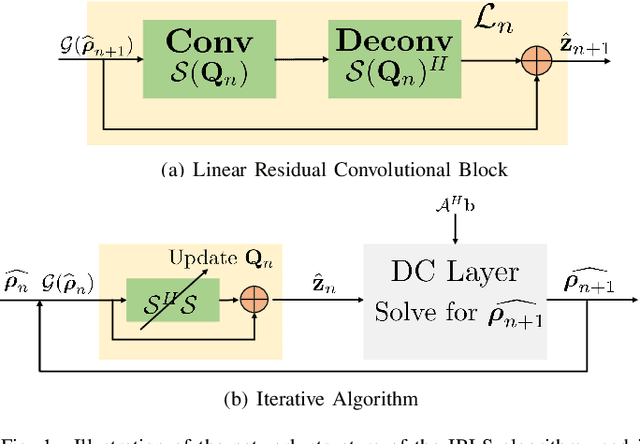
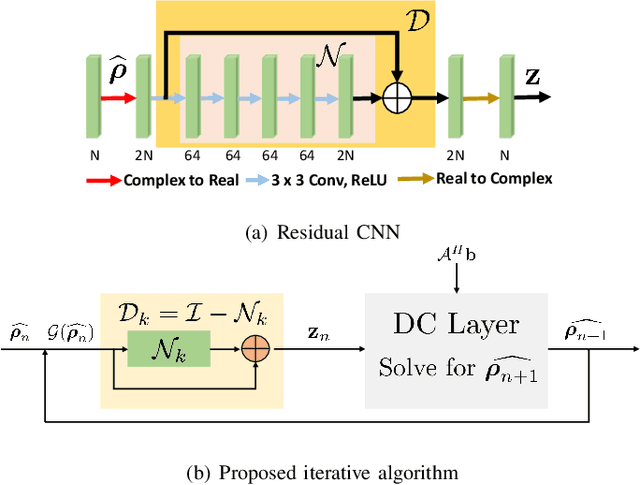
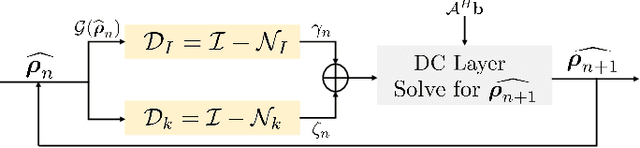
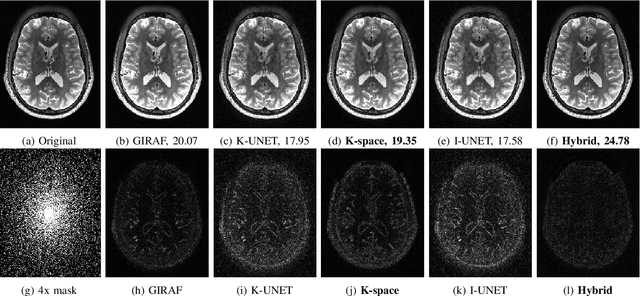
Structured low-rank (SLR) algorithms are emerging as powerful image reconstruction approaches because they can capitalize on several signal properties, which conventional image-based approaches have difficulty in exploiting. The main challenge with this scheme that self learns an annihilation convolutional filterbank from the undersampled data is its high computational complexity. We introduce a deep-learning approach to quite significantly reduce the computational complexity of SLR schemes. Specifically, we pre-learn a CNN-based annihilation filterbank from exemplar data, which is used as a prior in a model-based reconstruction scheme. The CNN parameters are learned in an end-to-end fashion by un-rolling the iterative algorithm. The main difference of the proposed scheme with current model-based deep learning strategies is the learning of non-linear annihilation relations in Fourier space using a modelbased framework. The experimental comparisons show that the proposed scheme can offer similar performance as SLR schemes in the calibrationless parallel MRI setting, while reducing the run-time by around three orders of magnitude. We also combine the proposed scheme with image domain priors, which are complementary, thus further improving the performance over SLR schemes.
Semantics-Driven Unsupervised Learning for Monocular Depth and Ego-Motion Estimation
Jun 08, 2020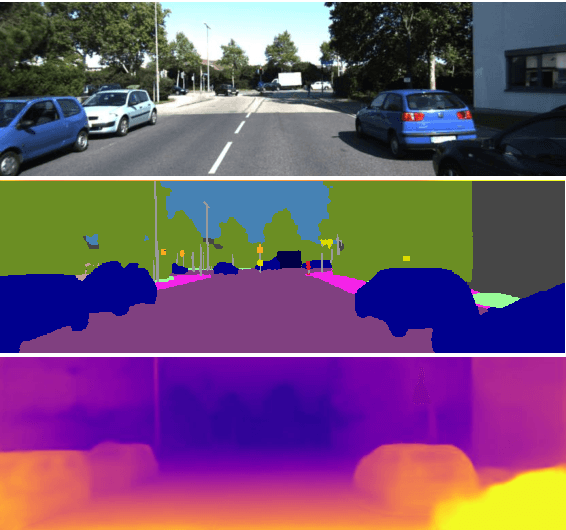
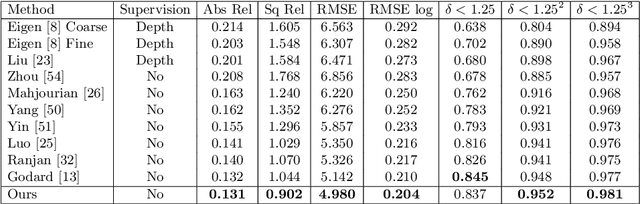
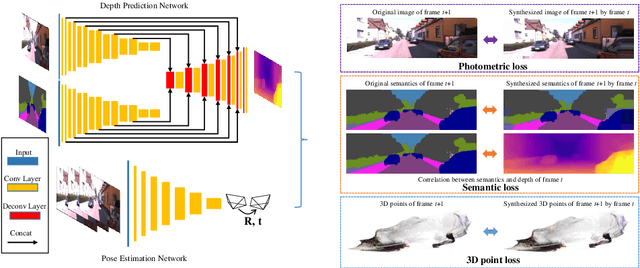
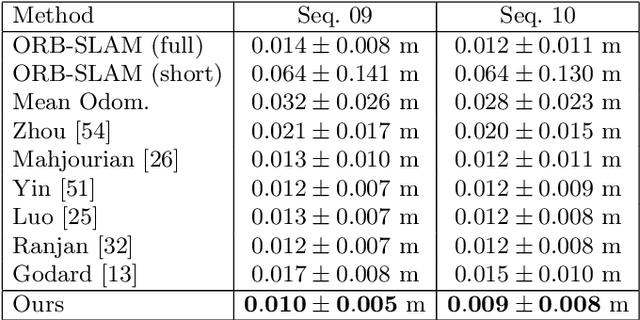
We propose a semantics-driven unsupervised learning approach for monocular depth and ego-motion estimation from videos in this paper. Recent unsupervised learning methods employ photometric errors between synthetic view and actual image as a supervision signal for training. In our method, we exploit semantic segmentation information to mitigate the effects of dynamic objects and occlusions in the scene, and to improve depth prediction performance by considering the correlation between depth and semantics. To avoid costly labeling process, we use noisy semantic segmentation results obtained by a pre-trained semantic segmentation network. In addition, we minimize the position error between the corresponding points of adjacent frames to utilize 3D spatial information. Experimental results on the KITTI dataset show that our method achieves good performance in both depth and ego-motion estimation tasks.
Learning Joint Representations of Videos and Sentences with Web Image Search
Aug 08, 2016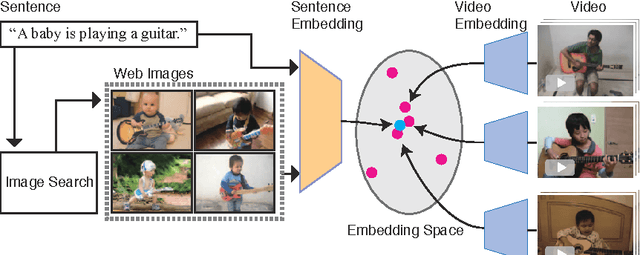
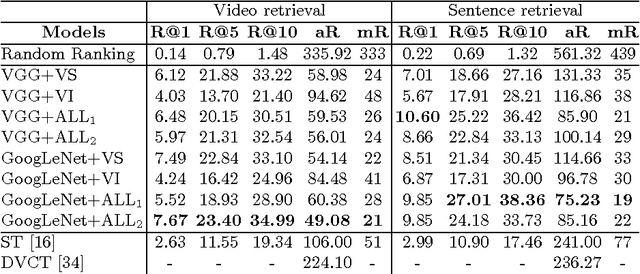
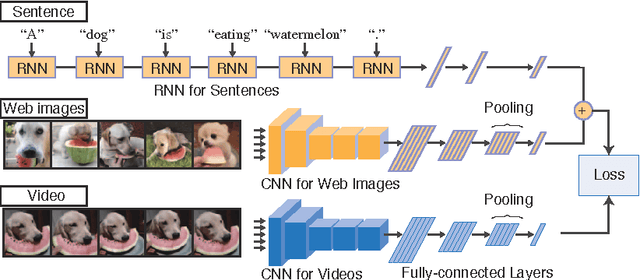
Our objective is video retrieval based on natural language queries. In addition, we consider the analogous problem of retrieving sentences or generating descriptions given an input video. Recent work has addressed the problem by embedding visual and textual inputs into a common space where semantic similarities correlate to distances. We also adopt the embedding approach, and make the following contributions: First, we utilize web image search in sentence embedding process to disambiguate fine-grained visual concepts. Second, we propose embedding models for sentence, image, and video inputs whose parameters are learned simultaneously. Finally, we show how the proposed model can be applied to description generation. Overall, we observe a clear improvement over the state-of-the-art methods in the video and sentence retrieval tasks. In description generation, the performance level is comparable to the current state-of-the-art, although our embeddings were trained for the retrieval tasks.
PointTrack++ for Effective Online Multi-Object Tracking and Segmentation
Jul 03, 2020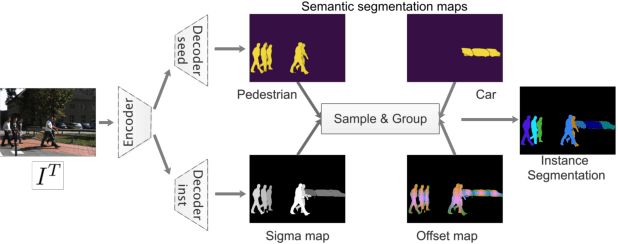
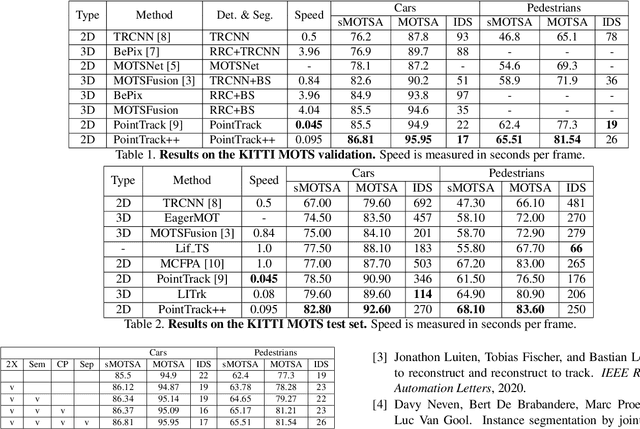
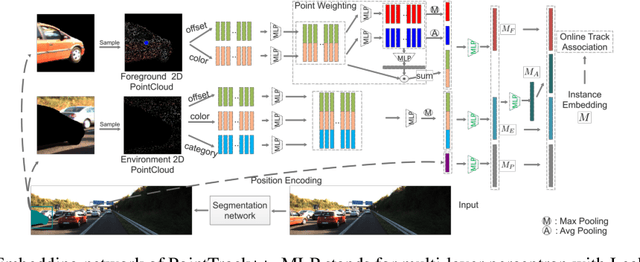
Multiple-object tracking and segmentation (MOTS) is a novel computer vision task that aims to jointly perform multiple object tracking (MOT) and instance segmentation. In this work, we present PointTrack++, an effective on-line framework for MOTS, which remarkably extends our recently proposed PointTrack framework. To begin with, PointTrack adopts an efficient one-stage framework for instance segmentation, and learns instance embeddings by converting compact image representations to un-ordered 2D point cloud. Compared with PointTrack, our proposed PointTrack++ offers three major improvements. Firstly, in the instance segmentation stage, we adopt a semantic segmentation decoder trained with focal loss to improve the instance selection quality. Secondly, to further boost the segmentation performance, we propose a data augmentation strategy by copy-and-paste instances into training images. Finally, we introduce a better training strategy in the instance association stage to improve the distinguishability of learned instance embeddings. The resulting framework achieves the state-of-the-art performance on the 5th BMTT MOTChallenge.
Learning from Extrinsic and Intrinsic Supervisions for Domain Generalization
Jul 18, 2020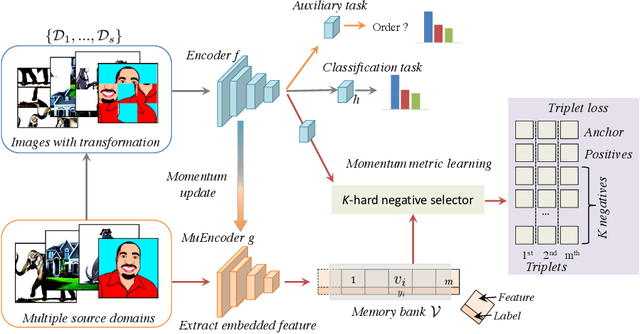
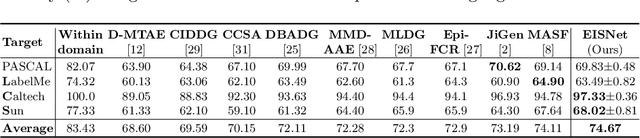
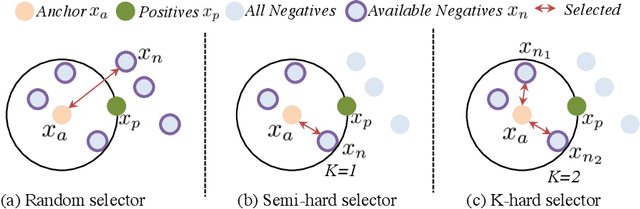
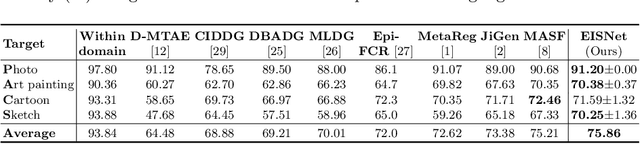
The generalization capability of neural networks across domains is crucial for real-world applications. We argue that a generalized object recognition system should well understand the relationships among different images and also the images themselves at the same time. To this end, we present a new domain generalization framework that learns how to generalize across domains simultaneously from extrinsic relationship supervision and intrinsic self-supervision for images from multi-source domains. To be specific, we formulate our framework with feature embedding using a multi-task learning paradigm. Besides conducting the common supervised recognition task, we seamlessly integrate a momentum metric learning task and a self-supervised auxiliary task to collectively utilize the extrinsic supervision and intrinsic supervision. Also, we develop an effective momentum metric learning scheme with K-hard negative mining to boost the network to capture image relationship for domain generalization. We demonstrate the effectiveness of our approach on two standard object recognition benchmarks VLCS and PACS, and show that our methods achieve state-of-the-art performance.
Superaccurate Camera Calibration via Inverse Rendering
Mar 20, 2020The most prevalent routine for camera calibration is based on the detection of well-defined feature points on a purpose-made calibration artifact. These could be checkerboard saddle points, circles, rings or triangles, often printed on a planar structure. The feature points are first detected and then used in a nonlinear optimization to estimate the internal camera parameters.We propose a new method for camera calibration using the principle of inverse rendering. Instead of relying solely on detected feature points, we use an estimate of the internal parameters and the pose of the calibration object to implicitly render a non-photorealistic equivalent of the optical features. This enables us to compute pixel-wise differences in the image domain without interpolation artifacts. We can then improve our estimate of the internal parameters by minimizing pixel-wise least-squares differences. In this way, our model optimizes a meaningful metric in the image space assuming normally distributed noise characteristic for camera sensors.We demonstrate using synthetic and real camera images that our method improves the accuracy of estimated camera parameters as compared with current state-of-the-art calibration routines. Our method also estimates these parameters more robustly in the presence of noise and in situations where the number of calibration images is limited.