 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NUBIA: NeUral Based Interchangeability Assessor for Text Generation
May 01, 2020
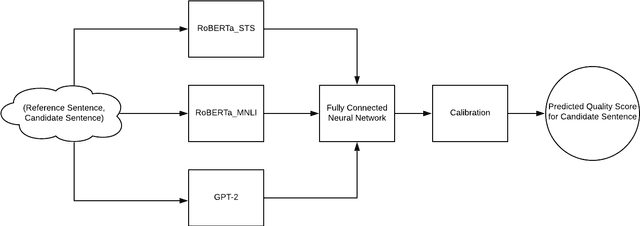

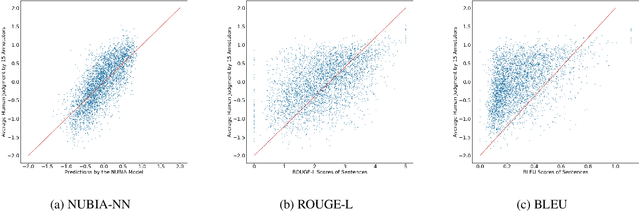
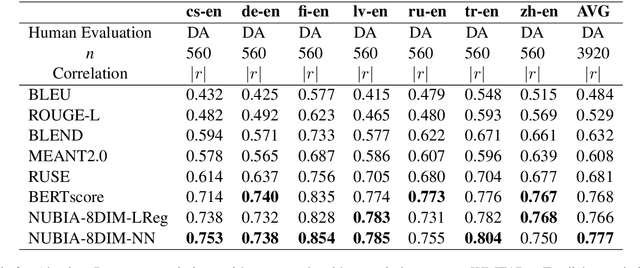
We present NUBIA, a methodology to build automatic evaluation metrics for text generation using only machine learning models as core components. A typical NUBIA model is composed of three modules: a neural feature extractor, an aggregator and a calibrator. We demonstrate an implementation of NUBIA which outperforms metrics currently used to evaluate machine translation, summaries and slightly exceeds/matches state of the art metrics on correlation with human judgement on the WMT segment-level Direct Assessment task, sentence-level ranking and image captioning evaluation. The model implemented is modular, explainable and set to continuously improve over time.
Automatic Image Filtering on Social Networks Using Deep Learning and Perceptual Hashing During Crises
Apr 09, 2017

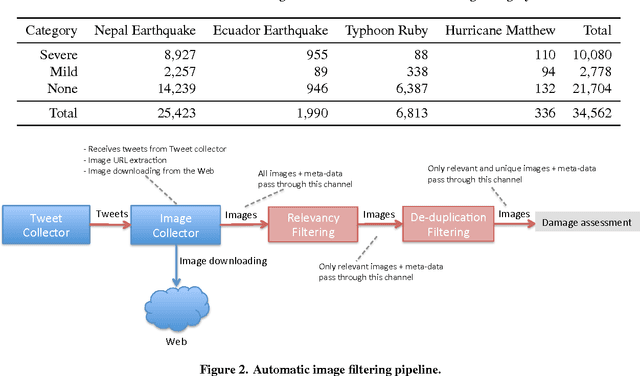

The extensive use of social media platforms, especially during disasters, creates unique opportunities for humanitarian organizations to gain situational awareness and launch relief operations accordingly. In addition to the textual content, people post overwhelming amounts of imagery data on social networks within minutes of a disaster hit. Studies point to the importance of this online imagery content for emergency response. Despite recent advances in the computer vision field, automatic processing of the crisis-related social media imagery data remains a challenging task. It is because a majority of which consists of redundant and irrelevant content. In this paper, we present an image processing pipeline that comprises de-duplication and relevancy filtering mechanisms to collect and filter social media image content in real-time during a crisis event. Results obtained from extensive experiments on real-world crisis datasets demonstrate the significance of the proposed pipeline for optimal utilization of both human and machine computing resources.
Image reconstruction from dense binary pixels
Dec 06, 2015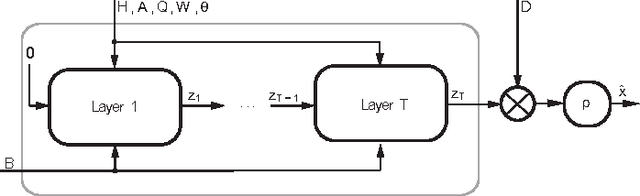


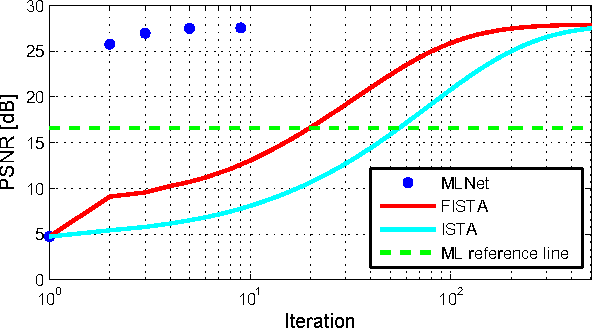
Recently, the dense binary pixel Gigavision camera had been introduced, emulating a digital version of the photographic film. While seems to be a promising solution for HDR imaging, its output is not directly usable and requires an image reconstruction process. In this work, we formulate this problem as the minimization of a convex objective combining a maximum-likelihood term with a sparse synthesis prior. We present MLNet - a novel feed-forward neural network, producing acceptable output quality at a fixed complexity and is two orders of magnitude faster than iterative algorithms. We present state of the art results in the abstract.
AQD: Towards Accurate Quantized Object Detection
Aug 03, 2020
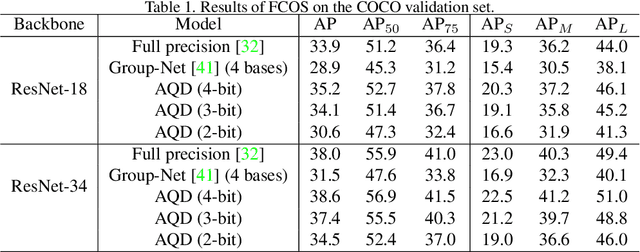
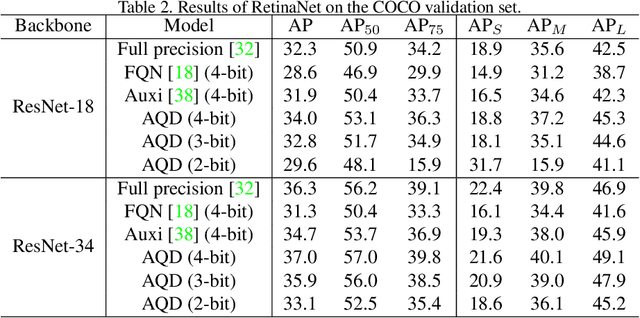

Network quantization aims to lower the bitwidth of weights and activations and hence reduce the model size and accelerate the inference of deep networks. Even though existing quantization methods have achieved promising performance on image classification, applying aggressively low bitwidth quantization on object detection while preserving the performance is still a challenge. In this paper, we demonstrate that the poor performance of the quantized network on object detection comes from the inaccurate batch statistics of batch normalization. To solve this, we propose an accurate quantized object detection (AQD) method. Specifically, we propose to employ multi-level batch normalization (multi-level BN) to estimate the batch statistics of each detection head separately. We further propose a learned interval quantization method to improve how the quantizer itself is configured. To evaluate the performance of the proposed methods, we apply AQD to two one-stage detectors (i.e., RetinaNet and FCOS). Experimental results on COCO show that our methods achieve near-lossless performance compared with the full-precision model by using extremely low bitwidth regimes such as 3-bit. In particular, we even outperform the full-precision counterpart by a large margin with a 4-bit detector, which is of great practical value.
Lesion Mask-based Simultaneous Synthesis of Anatomic and MolecularMR Images using a GAN
Jul 05, 2020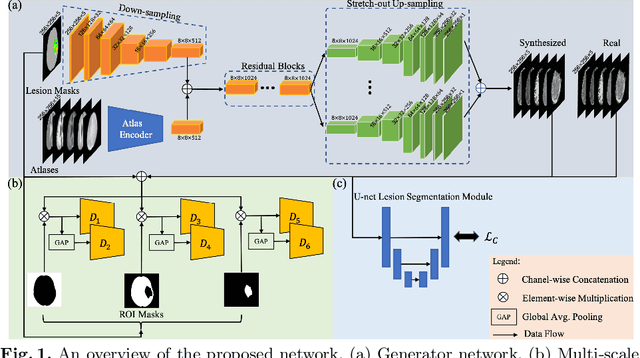

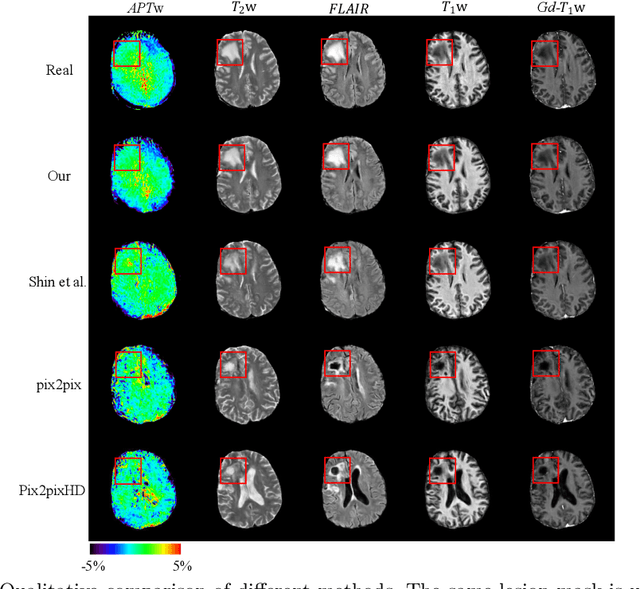
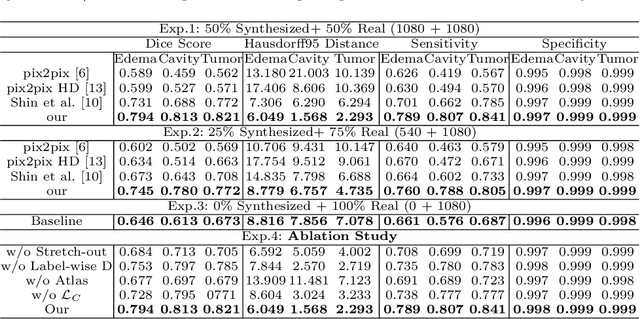
Data-driven automatic approaches have demonstrated their great potential in resolving various clinical diagnostic dilemmas for patients with malignant gliomas in neuro-oncology with the help of conventional and advanced molecular MR images. However, the lack of sufficient annotated MRI data has vastly impeded the development of such automatic methods. Conventional data augmentation approaches, including flipping, scaling, rotation, and distortion are not capable of generating data with diverse image content. In this paper, we propose a generative adversarial network (GAN), which can simultaneously synthesize data from arbitrary manipulated lesion information on multiple anatomic and molecular MRI sequences, including T1-weighted (T1w), gadolinium enhanced T1w (Gd-T1w), T2-weighted (T2w), fluid-attenuated inversion recovery (FLAIR), and amide proton transfer-weighted (APTw). The proposed framework consists of a stretch-out up-sampling module, a brain atlas encoder, a segmentation consistency module, and multi-scale labelwise discriminators. Extensive experiments on real clinical data demonstrate that the proposed model can perform significantly better than the state-of-the-art synthesis methods.
Fast Glare Detection in Document Images
Oct 24, 2019
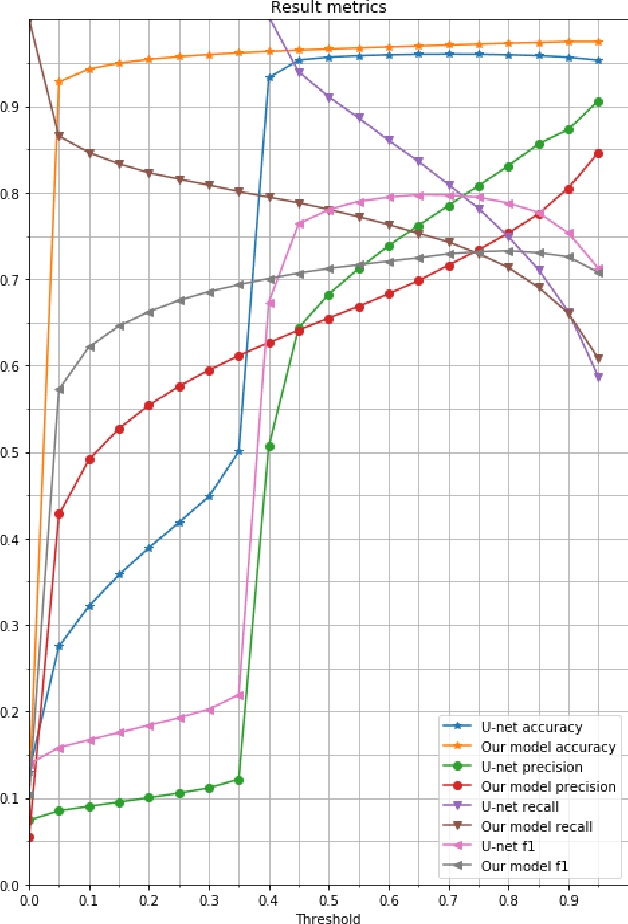
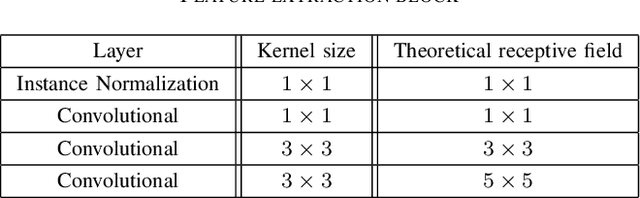
Glare is a phenomenon that occurs when the scene has a reflection of a light source or has one in it. This luminescence can hide useful information from the image, making text recognition virtually impossible. In this paper, we propose an approach to detect glare in images taken by users via mobile devices. Our method divides the document into blocks and collects luminance features from the original image and black-white strokes histograms of the binarized image. Finally, glare is detected using a convolutional neural network on the aforementioned histograms and luminance features. The network consists of several feature extraction blocks, one for each type of input, and the detection block, which calculates the resulting glare heatmap based on the output of the extraction part. The proposed solution detects glare with high recall and f-score.
Novel min-max reformulations of Linear Inverse Problems
Jul 05, 2020

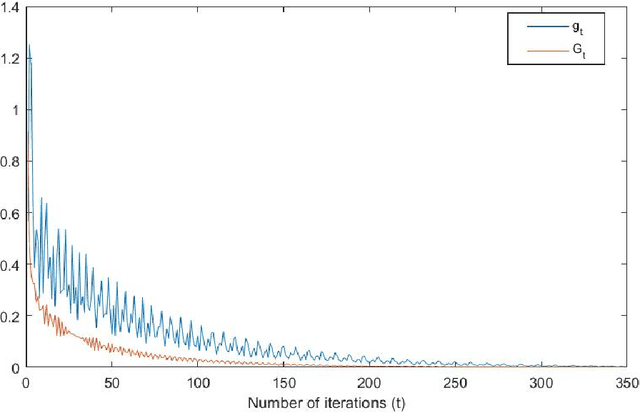
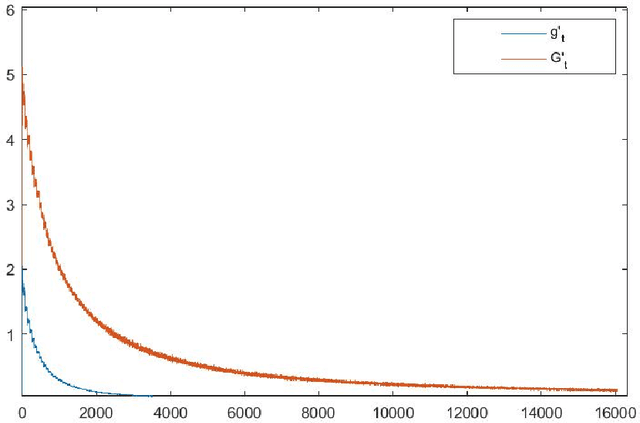
In this article, we dwell into the class of so-called ill-posed Linear Inverse Problems (LIP) which simply refers to the task of recovering the entire signal from its relatively few random linear measurements. Such problems arise in a variety of settings with applications ranging from medical image processing, recommender systems, etc. We propose a slightly generalized version of the error constrained linear inverse problem and obtain a novel and equivalent convex-concave min-max reformulation by providing an exposition to its convex geometry. Saddle points of the min-max problem are completely characterized in terms of a solution to the LIP, and vice versa. Applying simple saddle point seeking ascend-descent type algorithms to solve the min-max problems provides novel and simple algorithms to find a solution to the LIP. Moreover, the reformulation of an LIP as the min-max problem provided in this article is crucial in developing methods to solve the dictionary learning problem with almost sure recovery constraints.
Light Field Spatial Super-resolution via Deep Combinatorial Geometry Embedding and Structural Consistency Regularization
Apr 05, 2020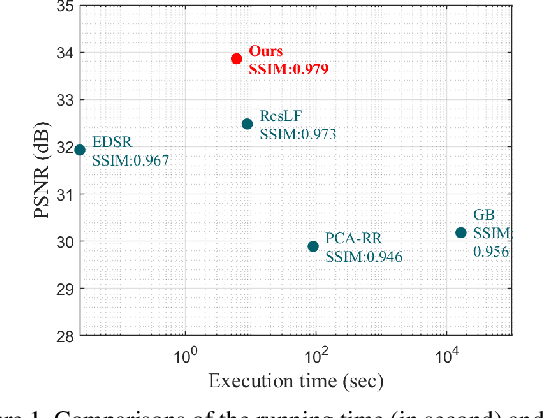
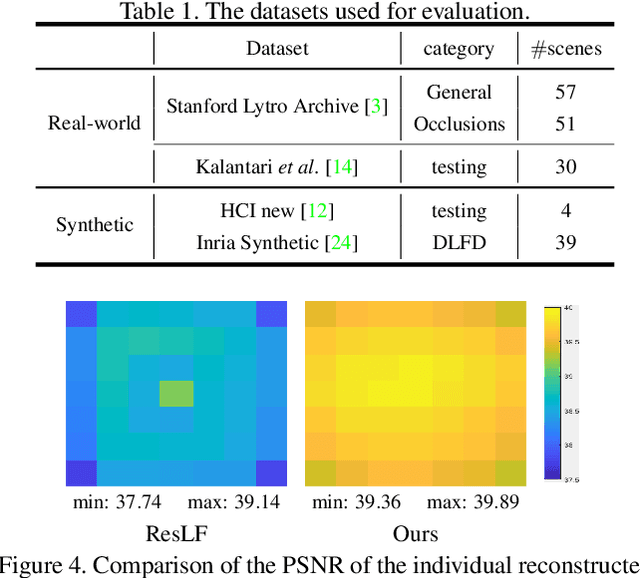
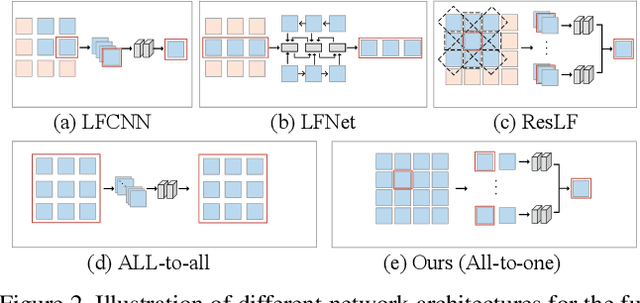
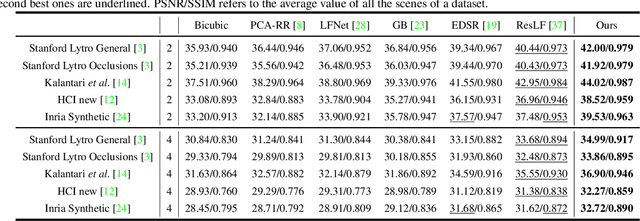
Light field (LF) images acquired by hand-held devices usually suffer from low spatial resolution as the limited sampling resources have to be shared with the angular dimension. LF spatial super-resolution (SR) thus becomes an indispensable part of the LF camera processing pipeline. The high-dimensionality characteristic and complex geometrical structure of LF images make the problem more challenging than traditional single-image SR. The performance of existing methods is still limited as they fail to thoroughly explore the coherence among LF views and are insufficient in accurately preserving the parallax structure of the scene. In this paper, we propose a novel learning-based LF spatial SR framework, in which each view of an LF image is first individually super-resolved by exploring the complementary information among views with combinatorial geometry embedding. For accurate preservation of the parallax structure among the reconstructed views, a regularization network trained over a structure-aware loss function is subsequently appended to enforce correct parallax relationships over the intermediate estimation. Our proposed approach is evaluated over datasets with a large number of testing images including both synthetic and real-world scenes. Experimental results demonstrate the advantage of our approach over state-of-the-art methods, i.e., our method not only improves the average PSNR by more than 1.0 dB but also preserves more accurate parallax details, at a lower computational cost.
Online Invariance Selection for Local Feature Descriptors
Jul 20, 2020
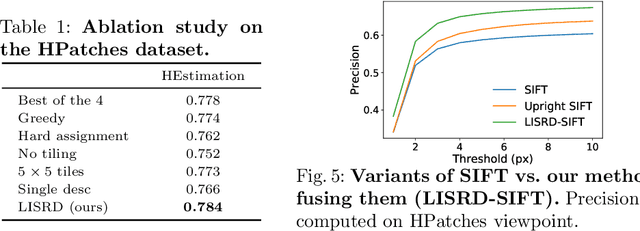
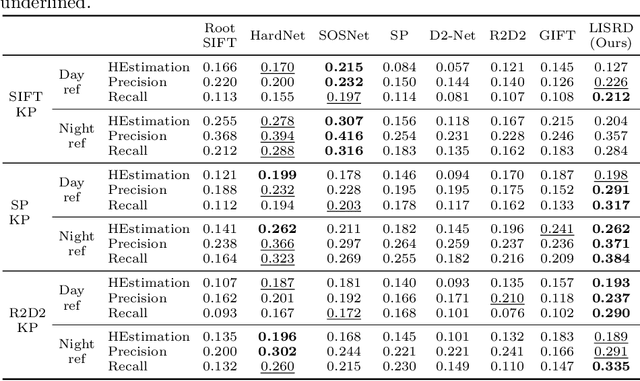
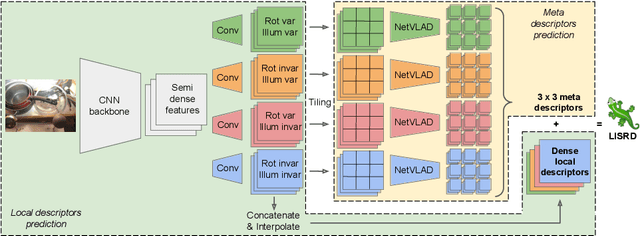
To be invariant, or not to be invariant: that is the question formulated in this work about local descriptors. A limitation of current feature descriptors is the trade-off between generalization and discriminative power: more invariance means less informative descriptors. We propose to overcome this limitation with a disentanglement of invariance in local descriptors and with an online selection of the most appropriate invariance given the context. Our framework consists in a joint learning of multiple local descriptors with different levels of invariance and of meta descriptors encoding the regional variations of an image. The similarity of these meta descriptors across images is used to select the right invariance when matching the local descriptors. Our approach, named Local Invariance Selection at Runtime for Descriptors (LISRD), enables descriptors to adapt to adverse changes in images, while remaining discriminative when invariance is not required. We demonstrate that our method can boost the performance of current descriptors and outperforms state-of-the-art descriptors in several matching tasks, when evaluated on challenging datasets with day-night illumination as well as viewpoint changes.
Learning from Multiple Datasets with Heterogeneous and Partial Labels for Universal Lesion Detection in CT
Sep 05, 2020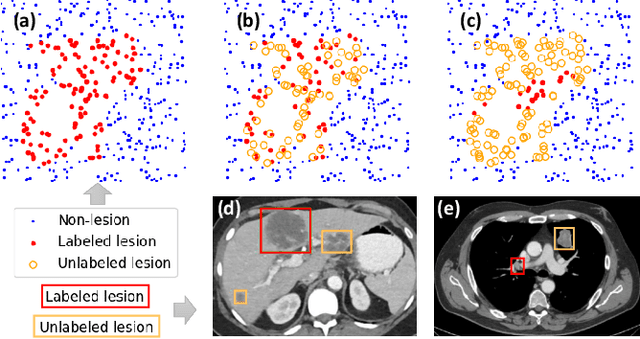
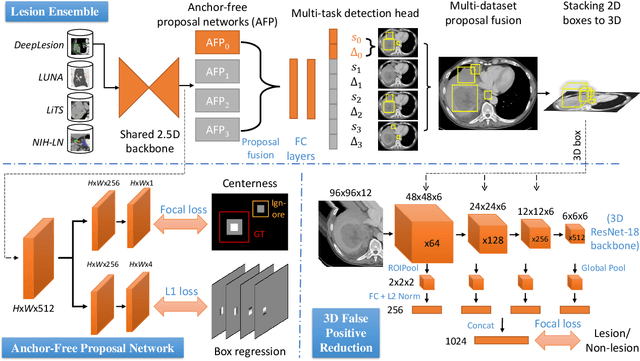
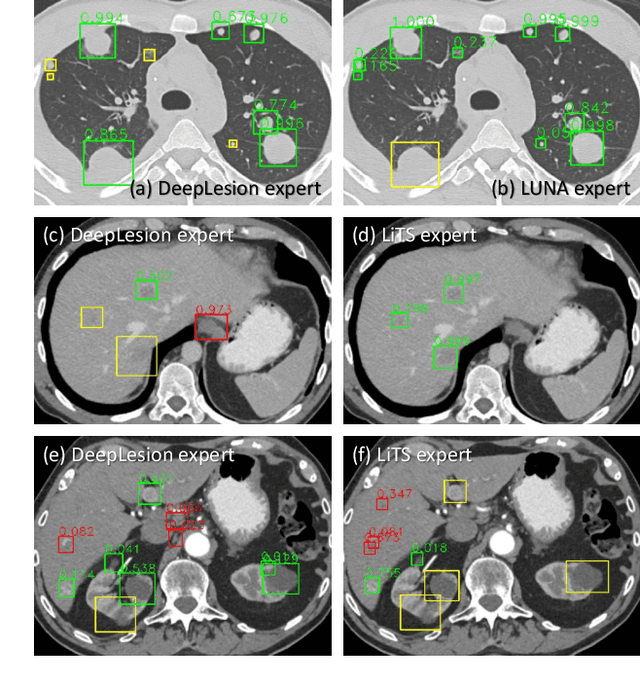
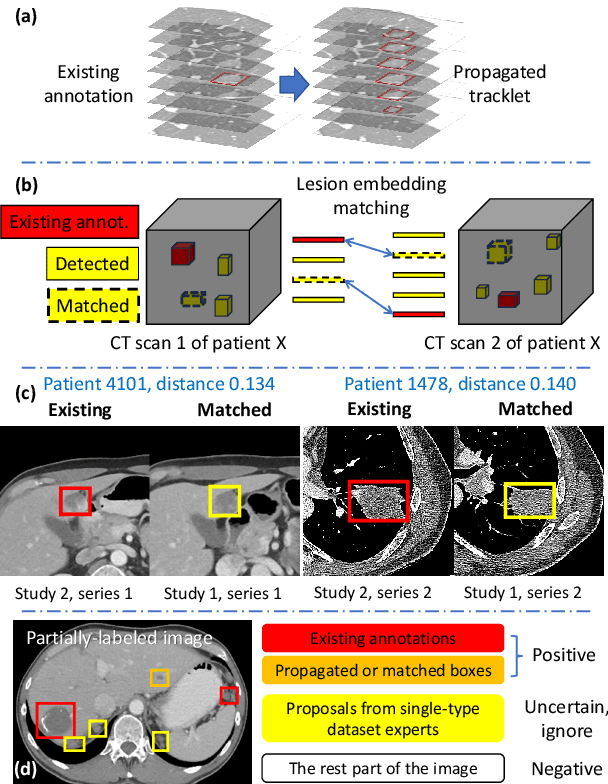
Large-scale datasets with high-quality labels are desired for training accurate deep learning models. However, due to annotation costs, medical imaging datasets are often either partially-labeled or small. For example, DeepLesion is a large-scale CT image dataset with lesions of various types, but it also has many unlabeled lesions (missing annotations). When training a lesion detector on a partially-labeled dataset, the missing annotations will generate incorrect negative signals and degrade performance. Besides DeepLesion, there are several small single-type datasets, such as LUNA for lung nodules and LiTS for liver tumors. Such datasets have heterogeneous label scopes, i.e., different lesion types are labeled in different datasets with other types ignored. In this work, we aim to tackle the problem of heterogeneous and partial labels, and develop a universal lesion detection algorithm to detect a comprehensive variety of lesions. First, we build a simple yet effective lesion detection framework named Lesion ENSemble (LENS). LENS can efficiently learn from multiple heterogeneous lesion datasets in a multi-task fashion and leverage their synergy by feature sharing and proposal fusion. Next, we propose strategies to mine missing annotations from partially-labeled datasets by exploiting clinical prior knowledge and cross-dataset knowledge transfer. Finally, we train our framework on four public lesion datasets and evaluate it on 800 manually-labeled sub-volumes in DeepLesion. On this challenging task, our method brings a relative improvement of 49% compared to the current state-of-the-art approach.