 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Discrete Flow Matching
Jul 22, 2024Despite Flow Matching and diffusion models having emerged as powerful generative paradigms for continuous variables such as images and videos, their application to high-dimensional discrete data, such as language, is still limited. In this work, we present Discrete Flow Matching, a novel discrete flow paradigm designed specifically for generating discrete data. Discrete Flow Matching offers several key contributions: (i) it works with a general family of probability paths interpolating between source and target distributions; (ii) it allows for a generic formula for sampling from these probability paths using learned posteriors such as the probability denoiser ($x$-prediction) and noise-prediction ($\epsilon$-prediction); (iii) practically, focusing on specific probability paths defined with different schedulers considerably improves generative perplexity compared to previous discrete diffusion and flow models; and (iv) by scaling Discrete Flow Matching models up to 1.7B parameters, we reach 6.7% Pass@1 and 13.4% Pass@10 on HumanEval and 6.7% Pass@1 and 20.6% Pass@10 on 1-shot MBPP coding benchmarks. Our approach is capable of generating high-quality discrete data in a non-autoregressive fashion, significantly closing the gap between autoregressive models and discrete flow models.
The Larger the Better? Improved LLM Code-Generation via Budget Reallocation
Mar 31, 2024



It is a common belief that large language models (LLMs) are better than smaller-sized ones. However, larger models also require significantly more time and compute during inference. This begs the question: what happens when both models operate under the same budget? (e.g., compute, run-time). To address this question, we analyze code generation LLMs of various sizes and make comparisons such as running a 70B model once vs. generating five outputs from a 13B model and selecting one. Our findings reveal that, in a standard unit-test setup, the repeated use of smaller models can yield consistent improvements, with gains of up to 15% across five tasks. On the other hand, in scenarios where unit-tests are unavailable, a ranking-based selection of candidates from the smaller model falls short of the performance of a single output from larger ones. Our results highlight the potential of using smaller models instead of larger ones, and the importance of studying approaches for ranking LLM outputs.
Masked Audio Generation using a Single Non-Autoregressive Transformer
Jan 09, 2024
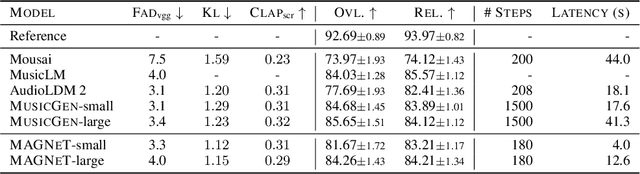


We introduce MAGNeT, a masked generative sequence modeling method that operates directly over several streams of audio tokens. Unlike prior work, MAGNeT is comprised of a single-stage, non-autoregressive transformer. During training, we predict spans of masked tokens obtained from a masking scheduler, while during inference we gradually construct the output sequence using several decoding steps. To further enhance the quality of the generated audio, we introduce a novel rescoring method in which, we leverage an external pre-trained model to rescore and rank predictions from MAGNeT, which will be then used for later decoding steps. Lastly, we explore a hybrid version of MAGNeT, in which we fuse between autoregressive and non-autoregressive models to generate the first few seconds in an autoregressive manner while the rest of the sequence is being decoded in parallel. We demonstrate the efficiency of MAGNeT for the task of text-to-music and text-to-audio generation and conduct an extensive empirical evaluation, considering both objective metrics and human studies. The proposed approach is comparable to the evaluated baselines, while being significantly faster (x7 faster than the autoregressive baseline). Through ablation studies and analysis, we shed light on the importance of each of the components comprising MAGNeT, together with pointing to the trade-offs between autoregressive and non-autoregressive modeling, considering latency, throughput, and generation quality. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/MAGNeT.
Code Llama: Open Foundation Models for Code
Aug 25, 2023



We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.
EXPRESSO: A Benchmark and Analysis of Discrete Expressive Speech Resynthesis
Aug 10, 2023



Recent work has shown that it is possible to resynthesize high-quality speech based, not on text, but on low bitrate discrete units that have been learned in a self-supervised fashion and can therefore capture expressive aspects of speech that are hard to transcribe (prosody, voice styles, non-verbal vocalization). The adoption of these methods is still limited by the fact that most speech synthesis datasets are read, severely limiting spontaneity and expressivity. Here, we introduce Expresso, a high-quality expressive speech dataset for textless speech synthesis that includes both read speech and improvised dialogues rendered in 26 spontaneous expressive styles. We illustrate the challenges and potentials of this dataset with an expressive resynthesis benchmark where the task is to encode the input in low-bitrate units and resynthesize it in a target voice while preserving content and style. We evaluate resynthesis quality with automatic metrics for different self-supervised discrete encoders, and explore tradeoffs between quality, bitrate and invariance to speaker and style. All the dataset, evaluation metrics and baseline models are open source
Simple and Controllable Music Generation
Jun 08, 2023We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark. Through ablation studies, we shed light over the importance of each of the components comprising MusicGen. Music samples, code, and models are available at https://github.com/facebookresearch/audiocraft.
Textually Pretrained Speech Language Models
May 22, 2023



Speech language models (SpeechLMs) process and generate acoustic data only, without textual supervision. In this work, we propose TWIST, a method for training SpeechLMs using a warm-start from a pretrained textual language models. We show using both automatic and human evaluations that TWIST outperforms a cold-start SpeechLM across the board. We empirically analyze the effect of different model design choices such as the speech tokenizer, the pretrained textual model, and the dataset size. We find that model and dataset scale both play an important role in constructing better-performing SpeechLMs. Based on our observations, we present the largest (to the best of our knowledge) SpeechLM both in terms of number of parameters and training data. We additionally introduce two spoken versions of the StoryCloze textual benchmark to further improve model evaluation and advance future research in the field. Speech samples can be found on our website: https://pages.cs.huji.ac.il/adiyoss-lab/twist/ .
ReVISE: Self-Supervised Speech Resynthesis with Visual Input for Universal and Generalized Speech Enhancement
Dec 21, 2022



Prior works on improving speech quality with visual input typically study each type of auditory distortion separately (e.g., separation, inpainting, video-to-speech) and present tailored algorithms. This paper proposes to unify these subjects and study Generalized Speech Enhancement, where the goal is not to reconstruct the exact reference clean signal, but to focus on improving certain aspects of speech. In particular, this paper concerns intelligibility, quality, and video synchronization. We cast the problem as audio-visual speech resynthesis, which is composed of two steps: pseudo audio-visual speech recognition (P-AVSR) and pseudo text-to-speech synthesis (P-TTS). P-AVSR and P-TTS are connected by discrete units derived from a self-supervised speech model. Moreover, we utilize self-supervised audio-visual speech model to initialize P-AVSR. The proposed model is coined ReVISE. ReVISE is the first high-quality model for in-the-wild video-to-speech synthesis and achieves superior performance on all LRS3 audio-visual enhancement tasks with a single model. To demonstrates its applicability in the real world, ReVISE is also evaluated on EasyCom, an audio-visual benchmark collected under challenging acoustic conditions with only 1.6 hours of training data. Similarly, ReVISE greatly suppresses noise and improves quality. Project page: https://wnhsu.github.io/ReVISE.
AudioScopeV2: Audio-Visual Attention Architectures for Calibrated Open-Domain On-Screen Sound Separation
Jul 20, 2022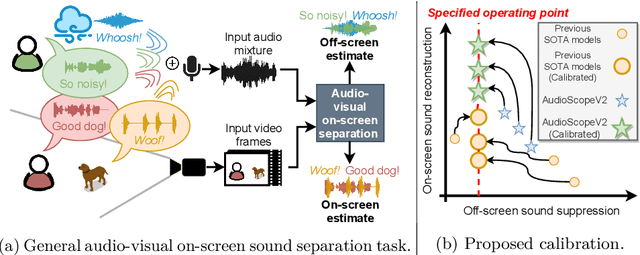
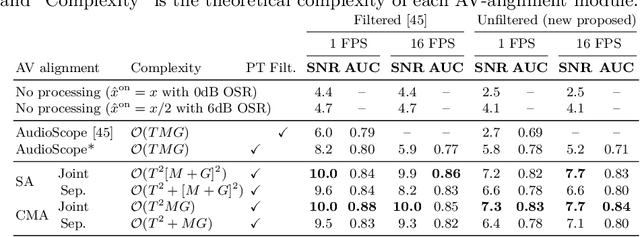
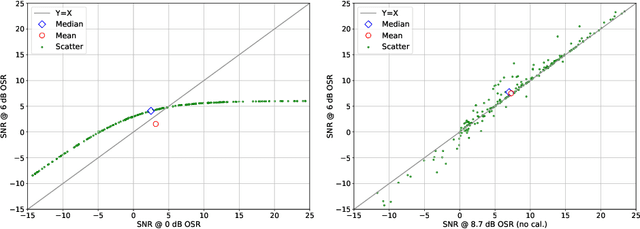
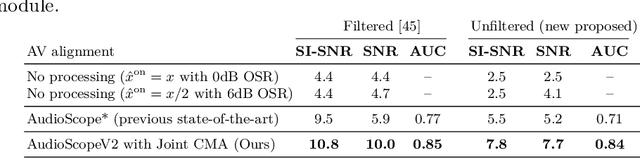
We introduce AudioScopeV2, a state-of-the-art universal audio-visual on-screen sound separation system which is capable of learning to separate sounds and associate them with on-screen objects by looking at in-the-wild videos. We identify several limitations of previous work on audio-visual on-screen sound separation, including the coarse resolution of spatio-temporal attention, poor convergence of the audio separation model, limited variety in training and evaluation data, and failure to account for the trade off between preservation of on-screen sounds and suppression of off-screen sounds. We provide solutions to all of these issues. Our proposed cross-modal and self-attention network architectures capture audio-visual dependencies at a finer resolution over time, and we also propose efficient separable variants that are capable of scaling to longer videos without sacrificing much performance. We also find that pre-training the separation model only on audio greatly improves results. For training and evaluation, we collected new human annotations of onscreen sounds from a large database of in-the-wild videos (YFCC100M). This new dataset is more diverse and challenging. Finally, we propose a calibration procedure that allows exact tuning of on-screen reconstruction versus off-screen suppression, which greatly simplifies comparing performance between models with different operating points. Overall, our experimental results show marked improvements in on-screen separation performance under much more general conditions than previous methods with minimal additional computational complexity.