 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Reinforcement Learning for Organ Localization in CT
May 11, 2020
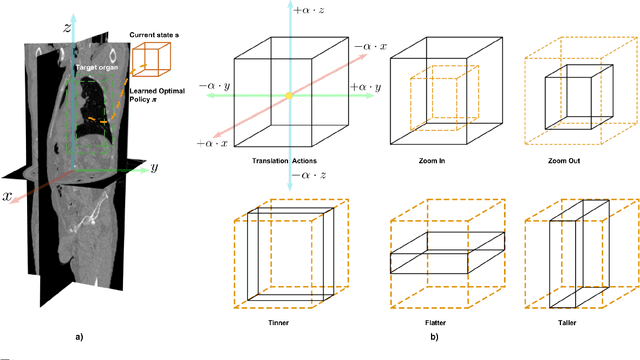
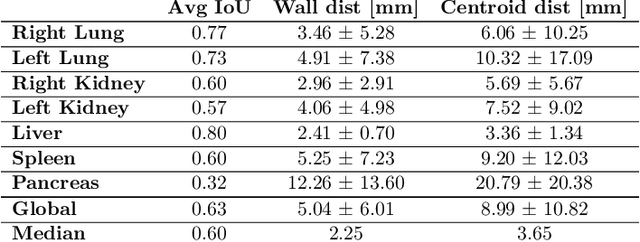
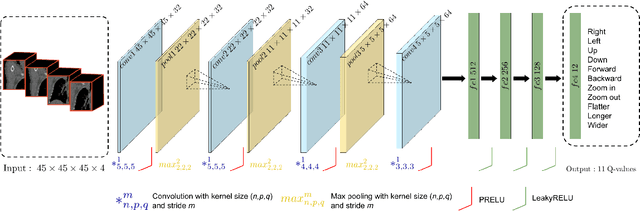
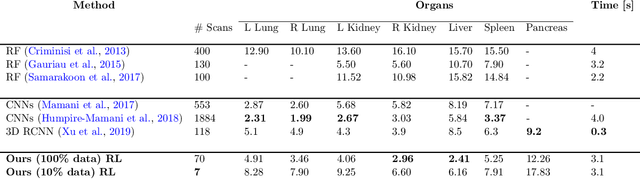
Robust localization of organs in computed tomography scans is a constant pre-processing requirement for organ-specific image retrieval, radiotherapy planning, and interventional image analysis. In contrast to current solutions based on exhaustive search or region proposals, which require large amounts of annotated data, we propose a deep reinforcement learning approach for organ localization in CT. In this work, an artificial agent is actively self-taught to localize organs in CT by learning from its asserts and mistakes. Within the context of reinforcement learning, we propose a novel set of actions tailored for organ localization in CT. Our method can use as a plug-and-play module for localizing any organ of interest. We evaluate the proposed solution on the public VISCERAL dataset containing CT scans with varying fields of view and multiple organs. We achieved an overall intersection over union of 0.63, an absolute median wall distance of 2.25 mm, and a median distance between centroids of 3.65 mm.
* Accepted paper in MIDL 2020
NCP-VAE: Variational Autoencoders with Noise Contrastive Priors
Oct 06, 2020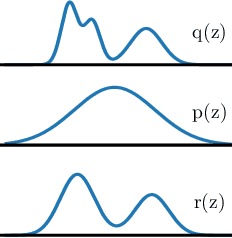
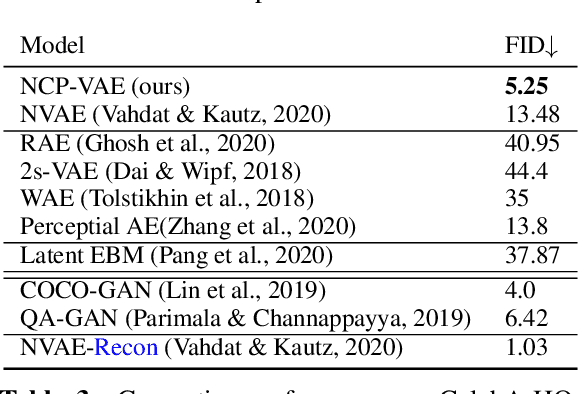
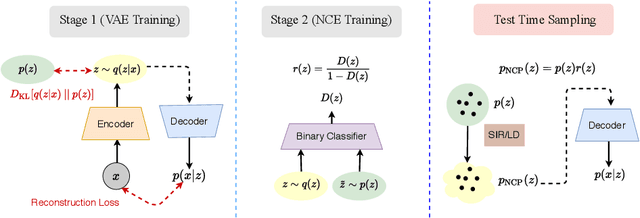

Variational autoencoders (VAEs) are one of the powerful likelihood-based generative models with applications in various domains. However, they struggle to generate high-quality images, especially when samples are obtained from the prior without any tempering. One explanation for VAEs' poor generative quality is the prior hole problem: the prior distribution fails to match the aggregate approximate posterior. Due to this mismatch, there exist areas in the latent space with high density under the prior that do not correspond to any encoded image. Samples from those areas are decoded to corrupted images. To tackle this issue, we propose an energy-based prior defined by the product of a base prior distribution and a reweighting factor, designed to bring the base closer to the aggregate posterior. We train the reweighting factor by noise contrastive estimation, and we generalize it to hierarchical VAEs with many latent variable groups. Our experiments confirm that the proposed noise contrastive priors improve the generative performance of state-of-the-art VAEs by a large margin on the MNIST, CIFAR-10, CelebA 64, and CelebA HQ 256 datasets.
CURI: A Benchmark for Productive Concept Learning Under Uncertainty
Oct 06, 2020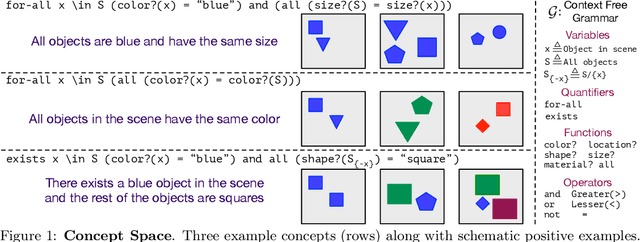
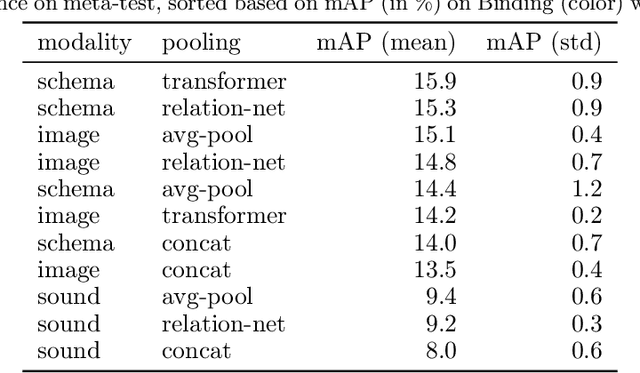
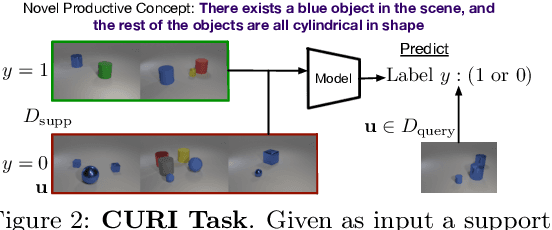
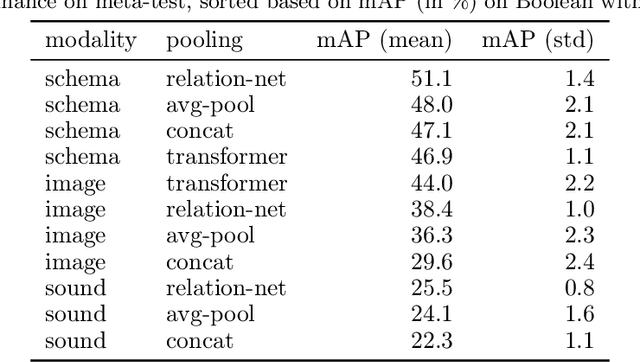
Humans can learn and reason under substantial uncertainty in a space of infinitely many concepts, including structured relational concepts ("a scene with objects that have the same color") and ad-hoc categories defined through goals ("objects that could fall on one's head"). In contrast, standard classification benchmarks: 1) consider only a fixed set of category labels, 2) do not evaluate compositional concept learning and 3) do not explicitly capture a notion of reasoning under uncertainty. We introduce a new few-shot, meta-learning benchmark, Compositional Reasoning Under Uncertainty (CURI) to bridge this gap. CURI evaluates different aspects of productive and systematic generalization, including abstract understandings of disentangling, productive generalization, learning boolean operations, variable binding, etc. Importantly, it also defines a model-independent "compositionality gap" to evaluate the difficulty of generalizing out-of-distribution along each of these axes. Extensive evaluations across a range of modeling choices spanning different modalities (image, schemas, and sounds), splits, privileged auxiliary concept information, and choices of negatives reveal substantial scope for modeling advances on the proposed task. All code and datasets will be available online.
Efficient Integer-Arithmetic-Only Convolutional Neural Networks
Jun 21, 2020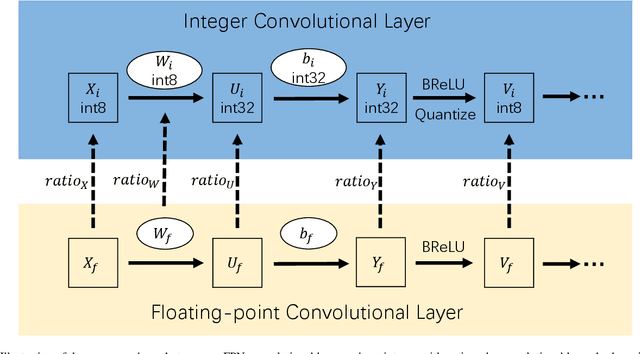
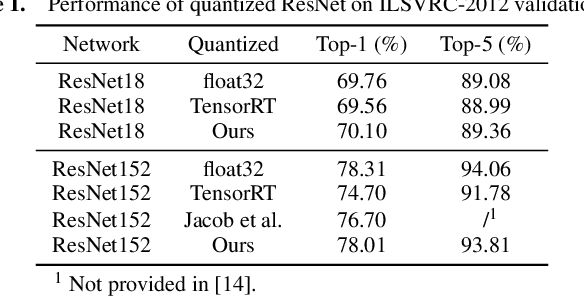
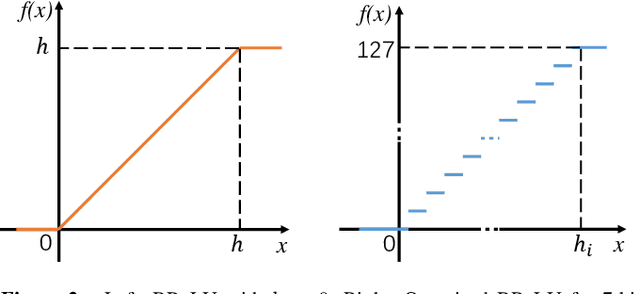
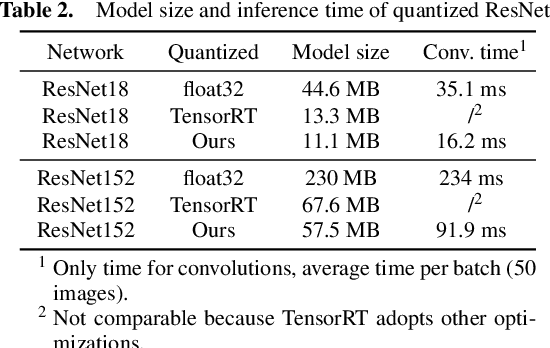
Integer-arithmetic-only networks have been demonstrated effective to reduce computational cost and to ensure cross-platform consistency. However, previous works usually report a decline in the inference accuracy when converting well-trained floating-point-number (FPN) networks into integer networks. We analyze this phonomenon and find that the decline is due to activation quantization. Specifically, when we replace conventional ReLU with Bounded ReLU, how to set the bound for each neuron is a key problem. Considering the tradeoff between activation quantization error and network learning ability, we set an empirical rule to tune the bound of each Bounded ReLU. We also design a mechanism to handle the cases of feature map addition and feature map concatenation. Based on the proposed method, our trained 8-bit integer ResNet outperforms the 8-bit networks of Google's TensorFlow and NVIDIA's TensorRT for image recognition. We also experiment on VDSR for image super-resolution and on VRCNN for compression artifact reduction, both of which serve for regression tasks that natively require high inference accuracy. Our integer networks achieve equivalent performance as the corresponding FPN networks, but have only 1/4 memory cost and run 2x faster on modern GPUs. Our code and models can be found at github.com/HengRuiZ/brelu.
InstaHide: Instance-hiding Schemes for Private Distributed Learning
Oct 06, 2020

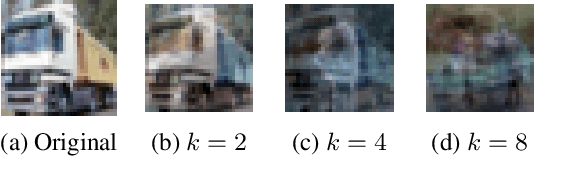
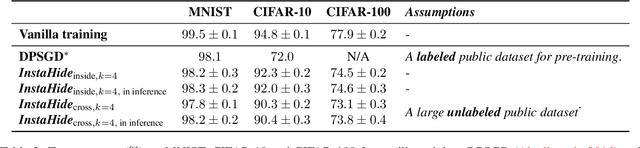
How can multiple distributed entities collaboratively train a shared deep net on their private data while preserving privacy? This paper introduces InstaHide, a simple encryption of training images, which can be plugged into existing distributed deep learning pipelines. The encryption is efficient and applying it during training has minor effect on test accuracy. InstaHide encrypts each training image with a "one-time secret key" which consists of mixing a number of randomly chosen images and applying a random pixel-wise mask. Other contributions of this paper include: (a) Using a large public dataset (e.g. ImageNet) for mixing during its encryption, which improves security. (b) Experimental results to show effectiveness in preserving privacy against known attacks with only minor effects on accuracy. (c) Theoretical analysis showing that successfully attacking privacy requires attackers to solve a difficult computational problem. (d) Demonstrating that use of the pixel-wise mask is important for security, since Mixup alone is shown to be insecure to some some efficient attacks. (e) Release of a challenge dataset https://github.com/Hazelsuko07/InstaHide_Challenge Our code is available at https://github.com/Hazelsuko07/InstaHide
Learning Canonical Representations for Scene Graph to Image Generation
Dec 16, 2019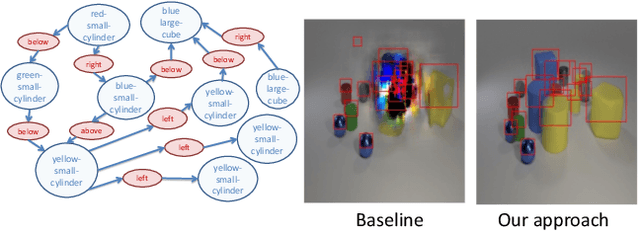
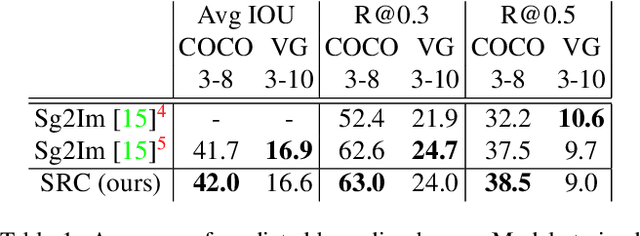
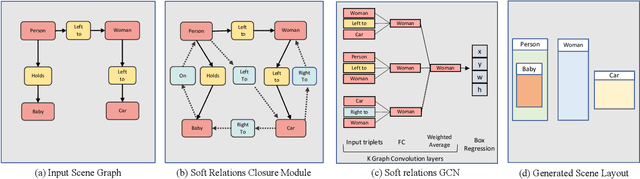
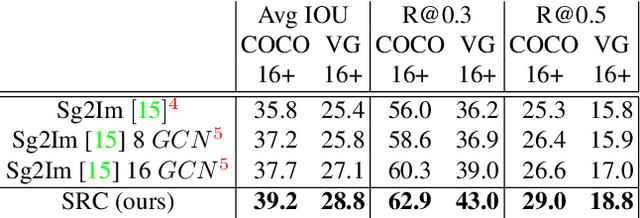
Generating realistic images of complex visual scenes becomes very challenging when one wishes to control the structure of the generated images. Previous approaches showed that scenes with few entities can be controlled using scene graphs, but this approach struggles as the complexity of the graph (number of objects and edges) increases. Moreover, current approaches fail to generalize conditioned on the number of objects or when given different input graphs which are semantic equivalent. In this work, we propose a novel approach to mitigate these issues. We present a novel model which can inherently learn canonical graph representations, thus ensuring that semantically similar scene graphs will result in similar predictions. In addition, the proposed model can better capture object representation independently of the number of objects in the graph. We show improved performance of the model on three different benchmarks: Visual Genome, COCO and CLEVR.
Comparison of camera-based and 3D LiDAR-based loop closures across weather conditions
Sep 08, 2020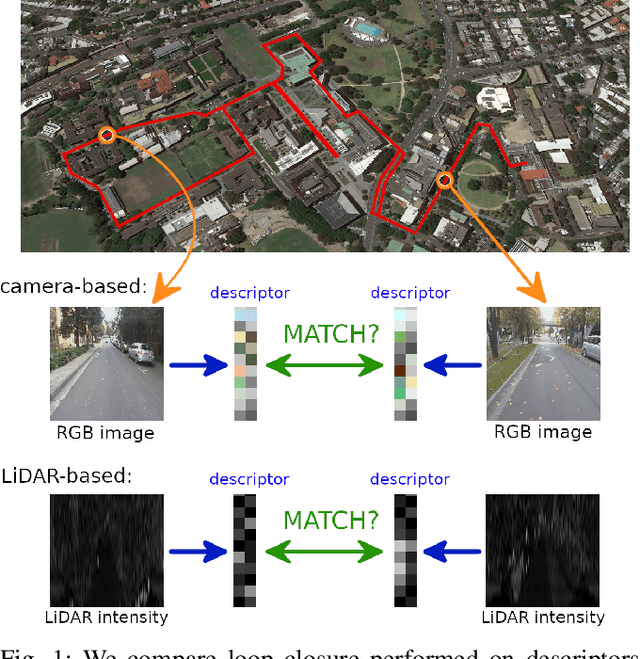
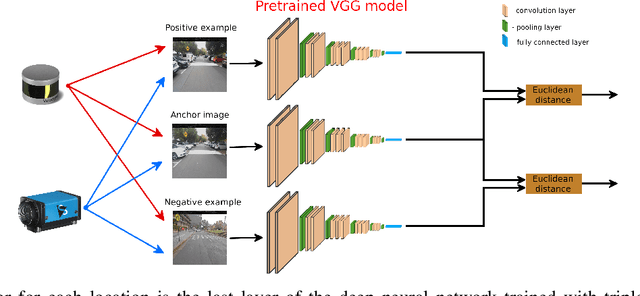
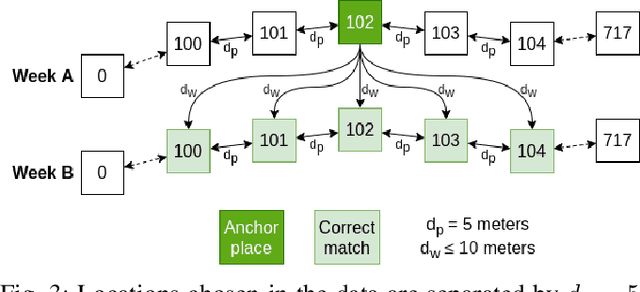

Loop closure based on camera images provides excellent results on benchmarking datasets, but might struggle in real-world adverse weather conditions like direct sun, rain, fog, or just darkness at night. In automotive applications, the sensory setups include 3D LiDARs that provide information complementary to cameras. The presented article focuses on the evaluation of camera-based, LiDAR-based, and joint camera-LiDAR-based loop closures applying a similar processing pipeline consisting of a neural network under varying weather conditions using the newly available USyd dataset. The experiments performed on the same trajectories in diverse weather conditions over 50 weeks prove that a 16-line 3D LiDAR can be used to supplement image-based loop closure to increase loop closure performance. This proves that there is a need for more research into loop closures performed with multi-sensory setups.
ODE-CNN: Omnidirectional Depth Extension Networks
Jul 03, 2020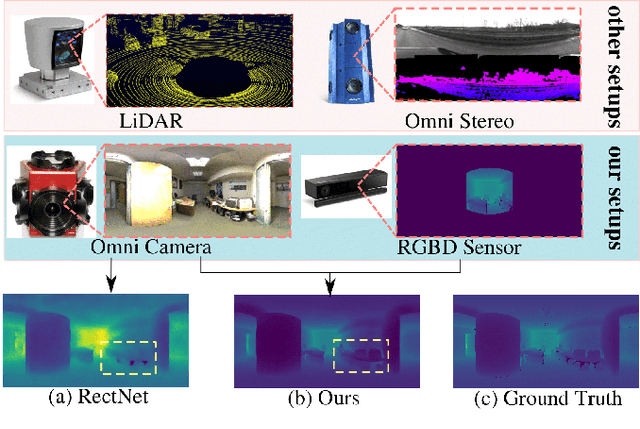
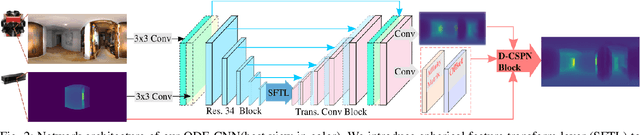
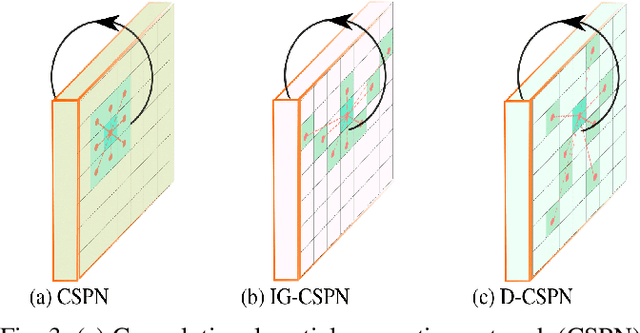

Omnidirectional 360{\deg} camera proliferates rapidly for autonomous robots since it significantly enhances the perception ability by widening the field of view(FoV). However, corresponding 360{\deg} depth sensors, which are also critical for the perception system, are still difficult or expensive to have. In this paper, we propose a low-cost 3D sensing system that combines an omnidirectional camera with a calibrated projective depth camera, where the depth from the limited FoV can be automatically extended to the rest of the recorded omnidirectional image. To accurately recover the missing depths, we design an omnidirectional depth extension convolutional neural network(ODE-CNN), in which a spherical feature transform layer(SFTL) is embedded at the end of feature encoding layers, and a deformable convolutional spatial propagation network(D-CSPN) is appended at the end of feature decoding layers. The former resamples the neighborhood of each pixel in the omnidirectional coordination to the projective coordination, which reduces the difficulty of feature learning, and the later automatically finds a proper context to well align the structures in the estimated depths via CNN w.r.t. the reference image, which significantly improves the visual quality. Finally, we demonstrate the effectiveness of proposed ODE-CNN over the popular 360D dataset and show that ODE-CNN significantly outperforms (relatively 33% reduction in-depth error) other state-of-the-art (SoTA) methods.
Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks
Oct 29, 2020



Compressing large neural networks is an important step for their deployment in resource-constrained computational platforms. In this context, vector quantization is an appealing framework that expresses multiple parameters using a single code, and has recently achieved state-of-the-art network compression on a range of core vision and natural language processing tasks. Key to the success of vector quantization is deciding which parameter groups should be compressed together. Previous work has relied on heuristics that group the spatial dimension of individual convolutional filters, but a general solution remains unaddressed. This is desirable for pointwise convolutions (which dominate modern architectures), linear layers (which have no notion of spatial dimension), and convolutions (when more than one filter is compressed to the same codeword). In this paper we make the observation that the weights of two adjacent layers can be permuted while expressing the same function. We then establish a connection to rate-distortion theory and search for permutations that result in networks that are easier to compress. Finally, we rely on an annealed quantization algorithm to better compress the network and achieve higher final accuracy. We show results on image classification, object detection, and segmentation, reducing the gap with the uncompressed model by 40 to 70% with respect to the current state of the art.
Constrained Labeling for Weakly Supervised Learning
Sep 15, 2020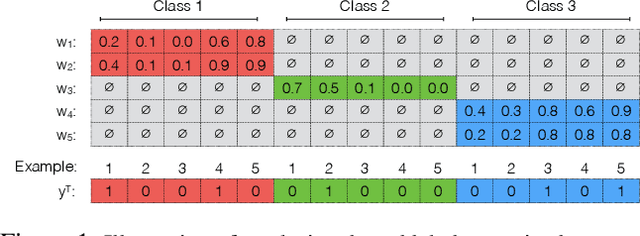
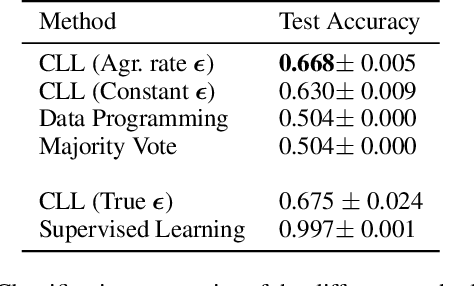
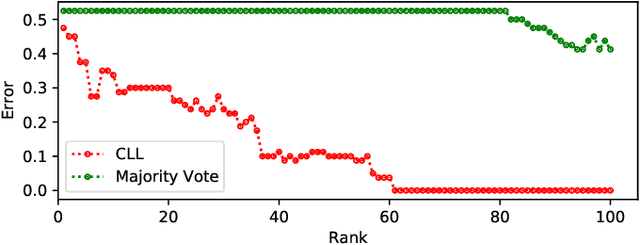
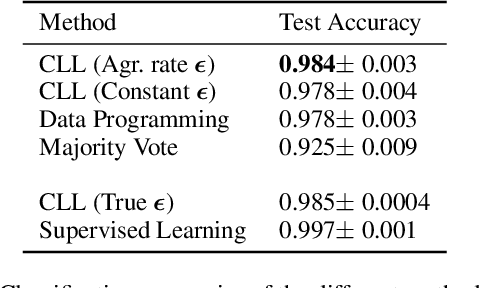
Curation of large fully supervised datasets has become one of the major roadblocks for machine learning. Weak supervision provides an alternative to supervised learning by training with cheap, noisy, and possibly correlated labeling functions from varying sources. The key challenge in weakly supervised learning is combining the different weak supervision signals while navigating misleading correlations in their errors. In this paper, we propose a simple data-free approach for combining weak supervision signals by defining a constrained space for the possible labels of the weak signals and training with a random labeling within this constrained space. Our method is efficient and stable, converging after a few iterations of gradient descent. We prove theoretical conditions under which the worst-case error of the randomized label decreases with the rank of the linear constraints. We show experimentally that our method outperforms other weak supervision methods on various text- and image-classification tasks.