 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exposing Fake Images with Forensic Similarity Graphs
Dec 05, 2019
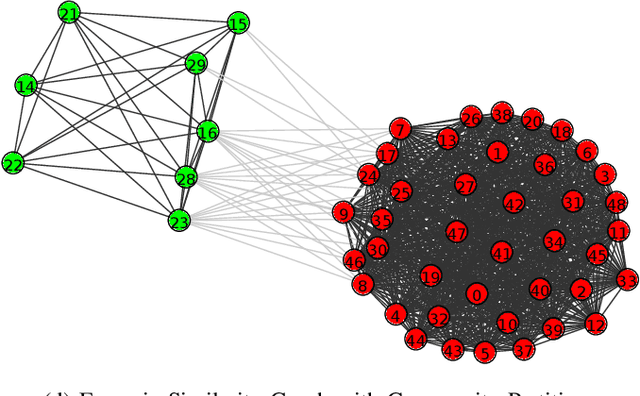

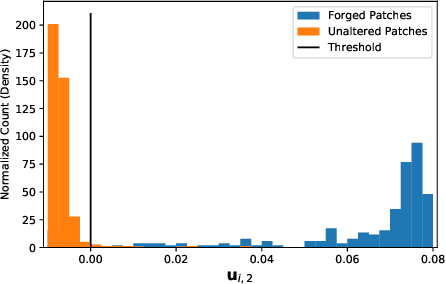
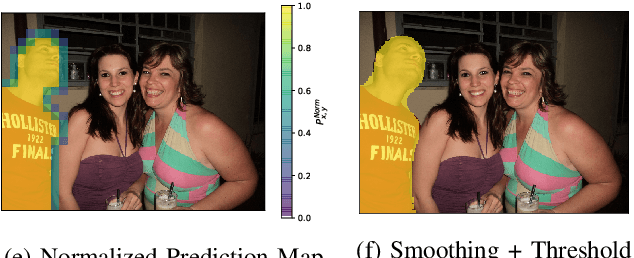
In this paper, we propose new image forgery detection and localization algorithms by recasting these problems as graph-based community detection problems. We define localized image tampering as any locally applied manipulation, including splicing and airbrushing, but not globally applied processes such as compression, whole-image resizing or contrast enhancement, etc. To show this, we propose an abstract, graph-based representation of an image, which we call the Forensic Similarity Graph. In this representation, small image patches are represented by graph vertices, and edges that connect pairs of vertices are assigned according to the forensic similarity between patches. Localized tampering introduces unique structure into this graph, which align with a concept called "communities" in graph-theory literature. A community is a subset of vertices that contain densely connected edges within the community, and relatively sparse edges to other communities. In the Forensic Similarity Graph, communities correspond to the tampered and unaltered regions in the image. As a result, forgery detection is performed by identifying whether multiple communities exist, and forgery localization is performed by partitioning these communities. In this paper, we additionally propose two community detection techniques, adapted from literature, to detect and localize image forgeries. We experimentally show that our proposed community detection methods outperform existing state-of-the-art forgery detection and localization methods.
Hierarchical Roofline Performance Analysis for Deep Learning Applications
Sep 22, 2020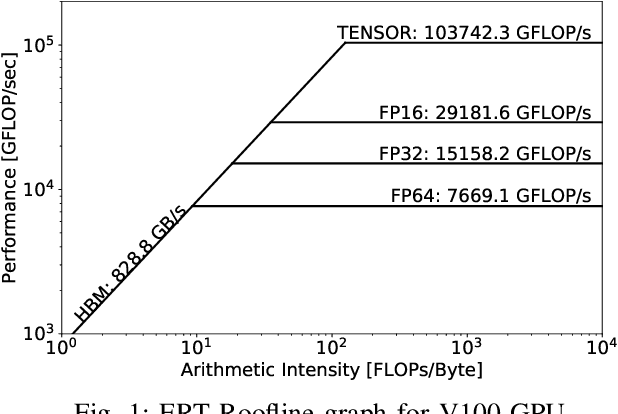
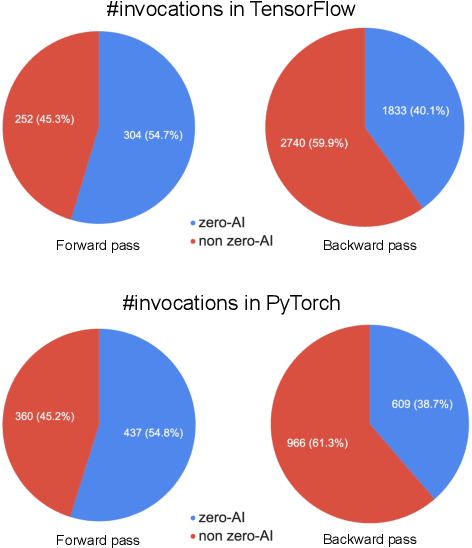
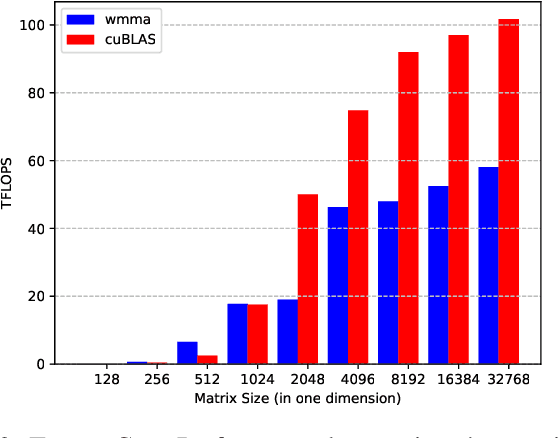
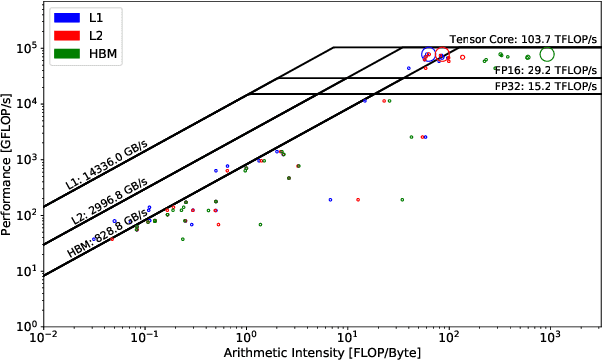
This paper presents a practical methodology for collecting performance data necessary to conduct hierarchical Roofline analysis on NVIDIA GPUs. It discusses the extension of the Empirical Roofline Toolkit for broader support of a range of data precisions and Tensor Core support and introduces a Nsight Compute based method to accurately collect application performance information. This methodology allows for automated machine characterization and application characterization for Roofline analysis across the entire memory hierarchy on NVIDIA GPUs, and it is validated by a complex deep learning application used for climate image segmentation. We use two versions of the code, in TensorFlow and PyTorch respectively, to demonstrate the use and effectiveness of this methodology. We highlight how the application utilizes the compute and memory capabilities on the GPU and how the implementation and performance differ in two deep learning frameworks.
ViNG: Learning Open-World Navigation with Visual Goals
Dec 17, 2020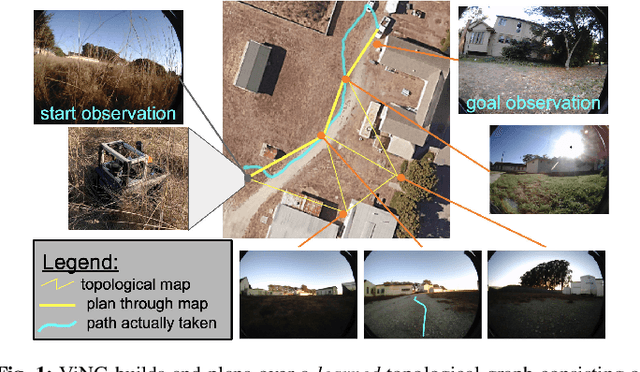

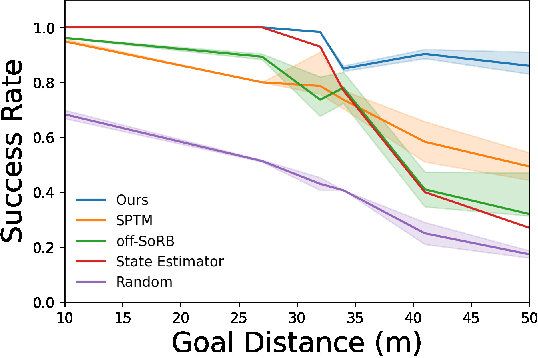
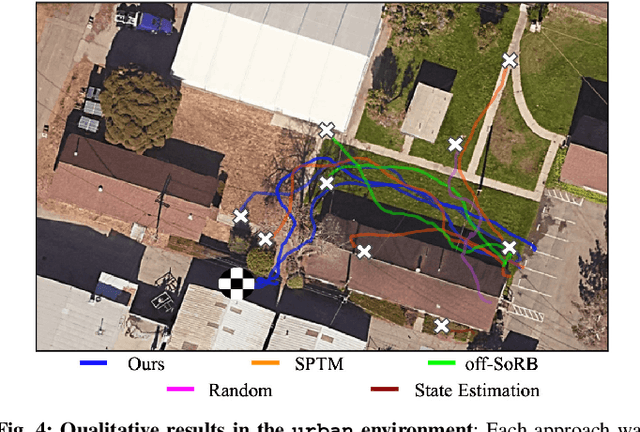
We propose a learning-based navigation system for reaching visually indicated goals and demonstrate this system on a real mobile robot platform. Learning provides an appealing alternative to conventional methods for robotic navigation: instead of reasoning about environments in terms of geometry and maps, learning can enable a robot to learn about navigational affordances, understand what types of obstacles are traversable (e.g., tall grass) or not (e.g., walls), and generalize over patterns in the environment. However, unlike conventional planning algorithms, it is harder to change the goal for a learned policy during deployment. We propose a method for learning to navigate towards a goal image of the desired destination. By combining a learned policy with a topological graph constructed out of previously observed data, our system can determine how to reach this visually indicated goal even in the presence of variable appearance and lighting. Three key insights, waypoint proposal, graph pruning and negative mining, enable our method to learn to navigate in real-world environments using only offline data, a setting where prior methods struggle. We instantiate our method on a real outdoor ground robot and show that our system, which we call ViNG, outperforms previously-proposed methods for goal-conditioned reinforcement learning, including other methods that incorporate reinforcement learning and search. We also study how ViNG generalizes to unseen environments and evaluate its ability to adapt to such an environment with growing experience. Finally, we demonstrate ViNG on a number of real-world applications, such as last-mile delivery and warehouse inspection. We encourage the reader to check out the videos of our experiments and demonstrations at our project website https://sites.google.com/view/ving-robot
Adaptive Debanding Filter
Sep 22, 2020
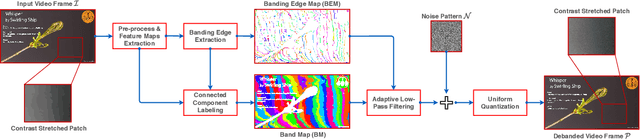
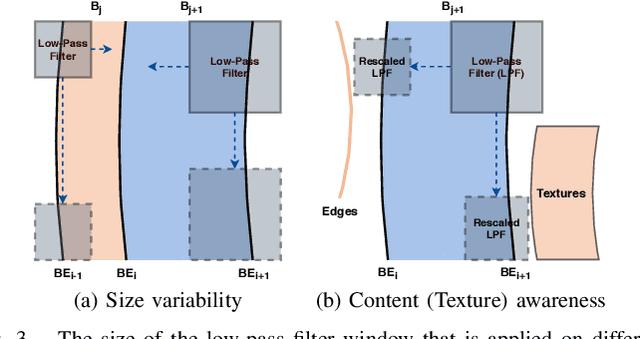
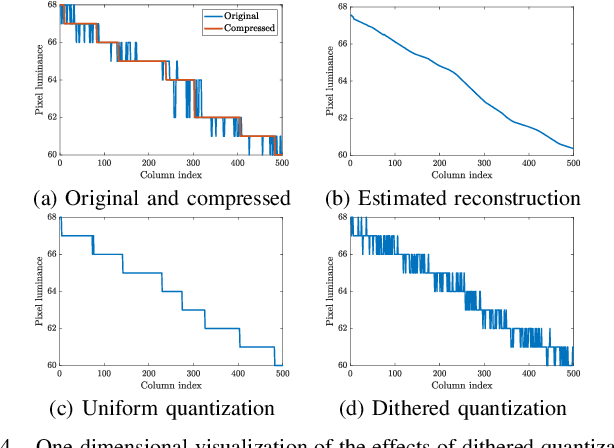
Banding artifacts, which manifest as staircase-like color bands on pictures or video frames, is a common distortion caused by compression of low-textured smooth regions. These false contours can be very noticeable even on high-quality videos, especially when displayed on high-definition screens. Yet, relatively little attention has been applied to this problem. Here we consider banding artifact removal as a visual enhancement problem, and accordingly, we solve it by applying a form of content-adaptive smoothing filtering followed by dithered quantization, as a post-processing module. The proposed debanding filter is able to adaptively smooth banded regions while preserving image edges and details, yielding perceptually enhanced gradient rendering with limited bit-depths. Experimental results show that our proposed debanding filter outperforms state-of-the-art false contour removing algorithms both visually and quantitatively.
Unsupervised Part Discovery via Feature Alignment
Dec 01, 2020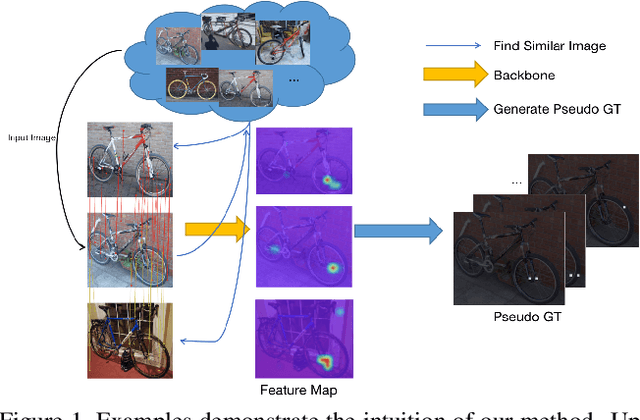
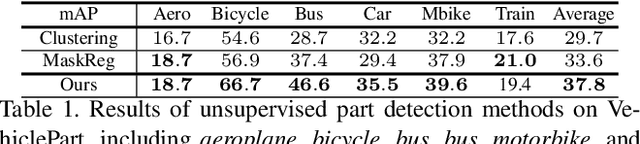
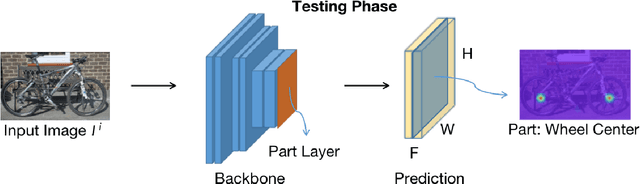

Understanding objects in terms of their individual parts is important, because it enables a precise understanding of the objects' geometrical structure, and enhances object recognition when the object is seen in a novel pose or under partial occlusion. However, the manual annotation of parts in large scale datasets is time consuming and expensive. In this paper, we aim at discovering object parts in an unsupervised manner, i.e., without ground-truth part or keypoint annotations. Our approach builds on the intuition that objects of the same class in a similar pose should have their parts aligned at similar spatial locations. We exploit the property that neural network features are largely invariant to nuisance variables and the main remaining source of variations between images of the same object category is the object pose. Specifically, given a training image, we find a set of similar images that show instances of the same object category in the same pose, through an affine alignment of their corresponding feature maps. The average of the aligned feature maps serves as pseudo ground-truth annotation for a supervised training of the deep network backbone. During inference, part detection is simple and fast, without any extra modules or overheads other than a feed-forward neural network. Our experiments on several datasets from different domains verify the effectiveness of the proposed method. For example, we achieve 37.8 mAP on VehiclePart, which is at least 4.2 better than previous methods.
Facial Attribute Capsules for Noise Face Super Resolution
Feb 16, 2020
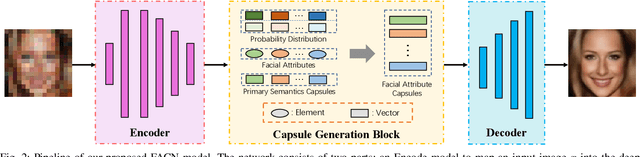
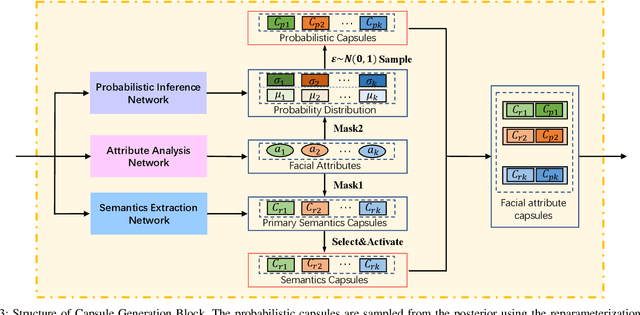

Existing face super-resolution (SR) methods mainly assume the input image to be noise-free. Their performance degrades drastically when applied to real-world scenarios where the input image is always contaminated by noise. In this paper, we propose a Facial Attribute Capsules Network (FACN) to deal with the problem of high-scale super-resolution of noisy face image. Capsule is a group of neurons whose activity vector models different properties of the same entity. Inspired by the concept of capsule, we propose an integrated representation model of facial information, which named Facial Attribute Capsule (FAC). In the SR processing, we first generated a group of FACs from the input LR face, and then reconstructed the HR face from this group of FACs. Aiming to effectively improve the robustness of FAC to noise, we generate FAC in semantic, probabilistic and facial attributes manners by means of integrated learning strategy. Each FAC can be divided into two sub-capsules: Semantic Capsule (SC) and Probabilistic Capsule (PC). Them describe an explicit facial attribute in detail from two aspects of semantic representation and probability distribution. The group of FACs model an image as a combination of facial attribute information in the semantic space and probabilistic space by an attribute-disentangling way. The diverse FACs could better combine the face prior information to generate the face images with fine-grained semantic attributes. Extensive benchmark experiments show that our method achieves superior hallucination results and outperforms state-of-the-art for very low resolution (LR) noise face image super resolution.
CovidCTNet: An Open-Source Deep Learning Approach to Identify Covid-19 Using CT Image
May 16, 2020Coronavirus disease 2019 (Covid-19) is highly contagious with limited treatment options. Early and accurate diagnosis of Covid-19 is crucial in reducing the spread of the disease and its accompanied mortality. Currently, detection by reverse transcriptase polymerase chain reaction (RT-PCR) is the gold standard of outpatient and inpatient detection of Covid-19. RT-PCR is a rapid method, however, its accuracy in detection is only ~70-75%. Another approved strategy is computed tomography (CT) imaging. CT imaging has a much higher sensitivity of ~80-98%, but similar accuracy of 70%. To enhance the accuracy of CT imaging detection, we developed an open-source set of algorithms called CovidCTNet that successfully differentiates Covid-19 from community-acquired pneumonia (CAP) and other lung diseases. CovidCTNet increases the accuracy of CT imaging detection to 90% compared to radiologists (70%). The model is designed to work with heterogeneous and small sample sizes independent of the CT imaging hardware. In order to facilitate the detection of Covid-19 globally and assist radiologists and physicians in the screening process, we are releasing all algorithms and parametric details in an open-source format. Open-source sharing of our CovidCTNet enables developers to rapidly improve and optimize services, while preserving user privacy and data ownership.
Physics-Guided Spoof Trace Disentanglement for Generic Face Anti-Spoofing
Dec 09, 2020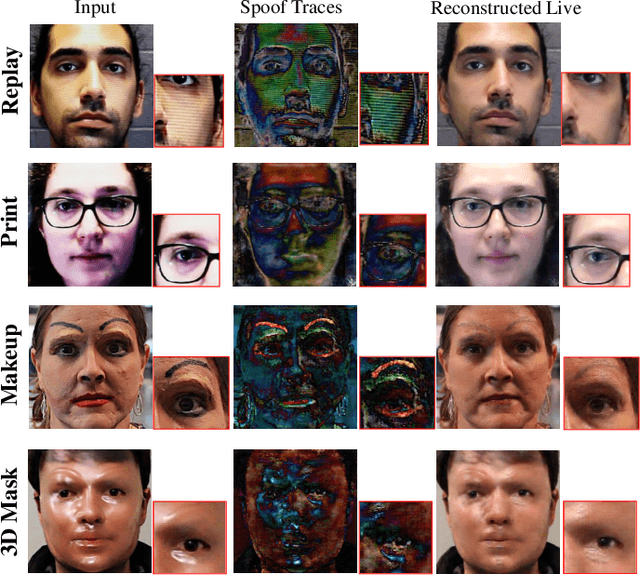
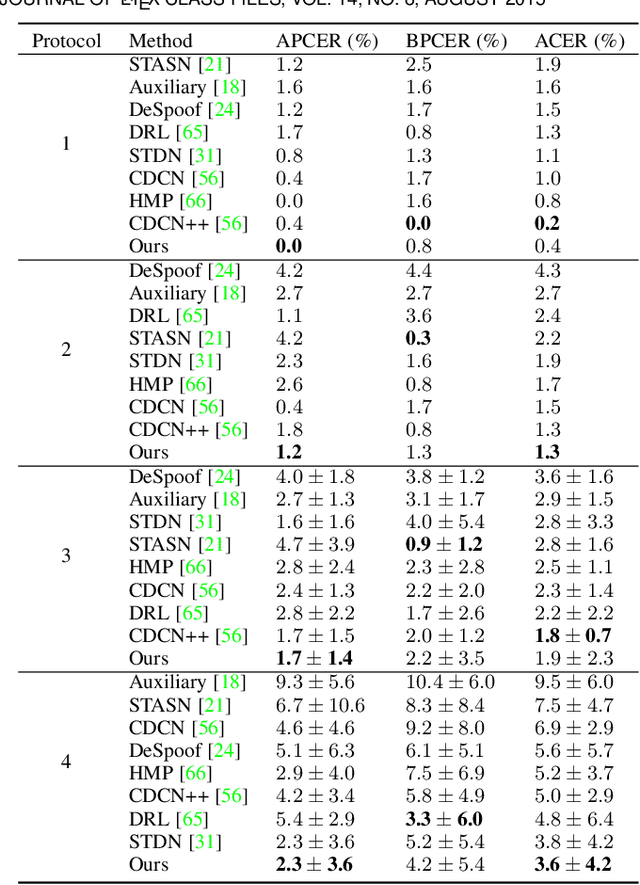
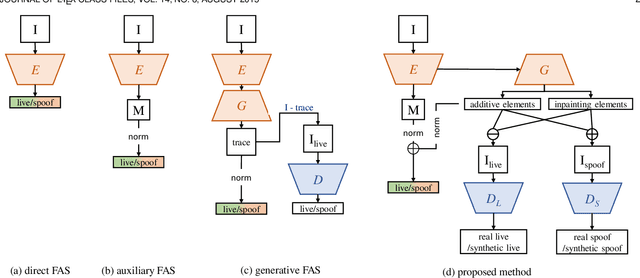
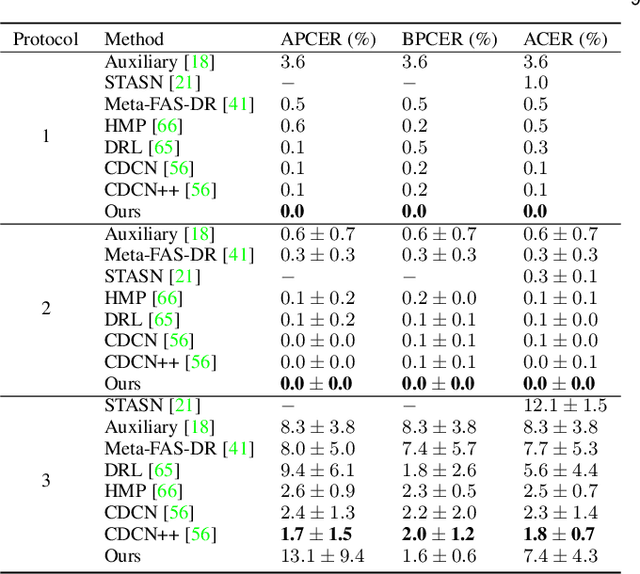
Prior studies show that the key to face anti-spoofing lies in the subtle image pattern, termed "spoof trace", e.g., color distortion, 3D mask edge, Moire pattern, and many others. Designing a generic face anti-spoofing model to estimate those spoof traces can improve not only the generalization of the spoof detection, but also the interpretability of the model's decision. Yet, this is a challenging task due to the diversity of spoof types and the lack of ground truth in spoof traces. In this work, we design a novel adversarial learning framework to disentangle spoof faces into the spoof traces and the live counterparts. Guided by physical properties, the spoof generation is represented as a combination of additive process and inpainting process. Additive process describes spoofing as spoof material introducing extra patterns (e.g., moire pattern), where the live counterpart can be recovered by removing those patterns. Inpainting process describes spoofing as spoof material fully covering certain regions, where the live counterpart of those regions has to be "guessed". We use 3 additive components and 1 inpainting component to represent traces at different frequency bands. The disentangled spoof traces can be utilized to synthesize realistic new spoof faces after proper geometric correction, and the synthesized spoof can be used for training and improve the generalization of spoof detection. Our approach demonstrates superior spoof detection performance on 3 testing scenarios: known attacks, unknown attacks, and open-set attacks. Meanwhile, it provides a visually-convincing estimation of the spoof traces. Source code and pre-trained models will be publicly available upon publication.
Extreme Consistency: Overcoming Annotation Scarcity and Domain Shifts
Apr 15, 2020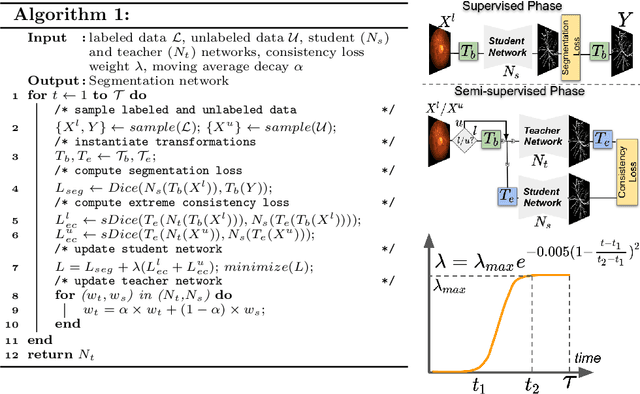
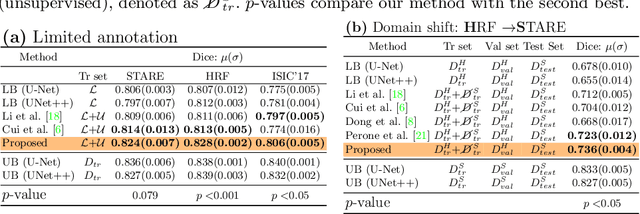
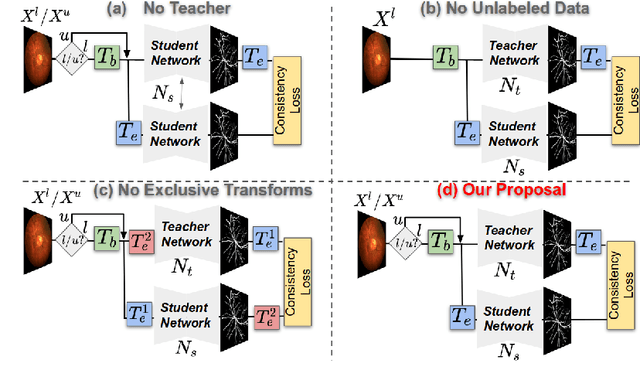
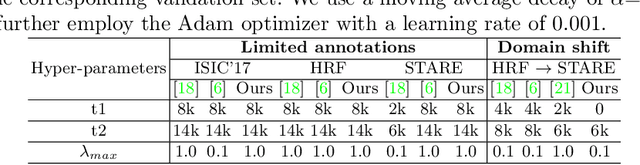
Supervised learning has proved effective for medical image analysis. However, it can utilize only the small labeled portion of data; it fails to leverage the large amounts of unlabeled data that is often available in medical image datasets. Supervised models are further handicapped by domain shifts, when the labeled dataset, despite being large enough, fails to cover different protocols or ethnicities. In this paper, we introduce \emph{extreme consistency}, which overcomes the above limitations, by maximally leveraging unlabeled data from the same or a different domain in a teacher-student semi-supervised paradigm. Extreme consistency is the process of sending an extreme transformation of a given image to the student network and then constraining its prediction to be consistent with the teacher network's prediction for the untransformed image. The extreme nature of our consistency loss distinguishes our method from related works that yield suboptimal performance by exercising only mild prediction consistency. Our method is 1) auto-didactic, as it requires no extra expert annotations; 2) versatile, as it handles both domain shift and limited annotation problems; 3) generic, as it is readily applicable to classification, segmentation, and detection tasks; and 4) simple to implement, as it requires no adversarial training. We evaluate our method for the tasks of lesion and retinal vessel segmentation in skin and fundus images. Our experiments demonstrate a significant performance gain over both modern supervised networks and recent semi-supervised models. This performance is attributed to the strong regularization enforced by extreme consistency, which enables the student network to learn how to handle extreme variants of both labeled and unlabeled images. This enhances the network's ability to tackle the inevitable same- and cross-domain data variability during inference.
Deep N-ary Error Correcting Output Codes
Oct 20, 2020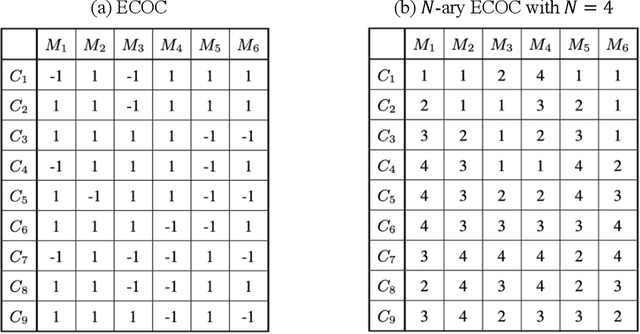
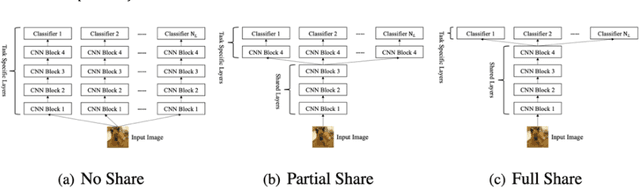
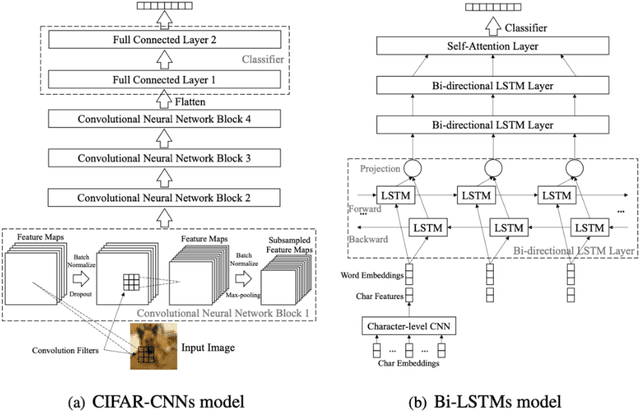
Ensemble learning consistently improves the performance of multi-class classification through aggregating a series of base classifiers. To this end, data-independent ensemble methods like Error Correcting Output Codes (ECOC) attract increasing attention due to its easiness of implementation and parallelization. Specifically, traditional ECOCs and its general extension N-ary ECOC decompose the original multi-class classification problem into a series of independent simpler classification subproblems. Unfortunately, integrating ECOCs, especially N-ary ECOC with deep neural networks, termed as deep N-ary ECOC, is not straightforward and yet fully exploited in the literature, due to the high expense of training base learners. To facilitate the training of N-ary ECOC with deep learning base learners, we further propose three different variants of parameter sharing architectures for deep N-ary ECOC. To verify the generalization ability of deep N-ary ECOC, we conduct experiments by varying the backbone with different deep neural network architectures for both image and text classification tasks. Furthermore, extensive ablation studies on deep N-ary ECOC show its superior performance over other deep data-independent ensemble methods.