 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYeti: A compact protein structure tokenizer for reconstruction and multi-modal generation
May 11, 2026Multimodal models that jointly reason over protein sequences, structures, and function annotations within a unified representation hold immense potential for integrating multimodal data and generating new proteins with designed functional properties. To utilize transformer architectures, such models require a tokenizer that converts protein structure from continuous atomic coordinates into discrete representations suitable for scalable multimodal training. The quality of such models are fundamentally upper bounded by the fidelity and expressiveness of the underlying tokenized structure. However, existing tokenizers prioritize reconstruction over generative abilities. To address these gaps, we introduce Yeti, a simple and compact protein structure tokenizer based on lookup free quantization and trained end to end with a flow matching objective for multimodal learning. Compared to existing models, Yeti generally achieves the best codebook utilization and token diversity, and second best reconstruction accuracy (with 10x fewer parameters than ESM3) on diverse datasets. To validate Yeti's generative capability, we trained a compact multimodal model jointly over its structure tokens and amino acid sequence entirely from scratch, with no pretrained initialization. The resulting multimodal model generates plausible structures under unconditional cogeneration of protein sequence and structures, achieving comparable results to 10x larger models. Together, these results demonstrate that Yeti is a compact and expressive protein structure tokenizer suitable for training multimodal models that cogenerates highly plausible sequences and structures.
FAIR Universe Weak Lensing ML Uncertainty Challenge: Handling Uncertainties and Distribution Shifts for Precision Cosmology
Apr 15, 2026Weak gravitational lensing, the correlated distortion of background galaxy shapes by foreground structures, is a powerful probe of the matter distribution in our universe and allows accurate constraints on the cosmological model. In recent years, high-order statistics and machine learning (ML) techniques have been applied to weak lensing data to extract the nonlinear information beyond traditional two-point analysis. However, these methods typically rely on cosmological simulations, which poses several challenges: simulations are computationally expensive, limiting most realistic setups to a low training data regime; inaccurate modeling of systematics in the simulations create distribution shifts that can bias cosmological parameter constraints; and varying simulation setups across studies make method comparison difficult. To address these difficulties, we present the first weak lensing benchmark dataset with several realistic systematics and launch the FAIR Universe Weak Lensing Machine Learning Uncertainty Challenge. The challenge focuses on measuring the fundamental properties of the universe from weak lensing data with limited training set and potential distribution shifts, while providing a standardized benchmark for rigorous comparison across methods. Organized in two phases, the challenge will bring together the physics and ML communities to advance the methodologies for handling systematic uncertainties, data efficiency, and distribution shifts in weak lensing analysis with ML, ultimately facilitating the deployment of ML approaches into upcoming weak lensing survey analysis.
Zatom-1: A Multimodal Flow Foundation Model for 3D Molecules and Materials
Feb 24, 2026General-purpose 3D chemical modeling encompasses molecules and materials, requiring both generative and predictive capabilities. However, most existing AI approaches are optimized for a single domain (molecules or materials) and a single task (generation or prediction), which limits representation sharing and transfer. We introduce Zatom-1, the first foundation model that unifies generative and predictive learning of 3D molecules and materials. Zatom-1 is a Transformer trained with a multimodal flow matching objective that jointly models discrete atom types and continuous 3D geometries. This approach supports scalable pretraining with predictable gains as model capacity increases, while enabling fast and stable sampling. We use joint generative pretraining as a universal initialization for downstream multi-task prediction of properties, energies, and forces. Empirically, Zatom-1 matches or outperforms specialized baselines on both generative and predictive benchmarks, while reducing the generative inference time by more than an order of magnitude. Our experiments demonstrate positive predictive transfer between chemical domains from joint generative pretraining: modeling materials during pretraining improves molecular property prediction accuracy.
FAIR Universe HiggsML Uncertainty Challenge Competition
Oct 03, 2024



The FAIR Universe -- HiggsML Uncertainty Challenge focuses on measuring the physics properties of elementary particles with imperfect simulators due to differences in modelling systematic errors. Additionally, the challenge is leveraging a large-compute-scale AI platform for sharing datasets, training models, and hosting machine learning competitions. Our challenge brings together the physics and machine learning communities to advance our understanding and methodologies in handling systematic (epistemic) uncertainties within AI techniques.
Hierarchical Graph Neural Networks for Particle Track Reconstruction
Mar 03, 2023



We introduce a novel variant of GNN for particle tracking called Hierarchical Graph Neural Network (HGNN). The architecture creates a set of higher-level representations which correspond to tracks and assigns spacepoints to these tracks, allowing disconnected spacepoints to be assigned to the same track, as well as multiple tracks to share the same spacepoint. We propose a novel learnable pooling algorithm called GMPool to generate these higher-level representations called "super-nodes", as well as a new loss function designed for tracking problems and HGNN specifically. On a standard tracking problem, we show that, compared with previous ML-based tracking algorithms, the HGNN has better tracking efficiency performance, better robustness against inefficient input graphs, and better convergence compared with traditional GNNs.
MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021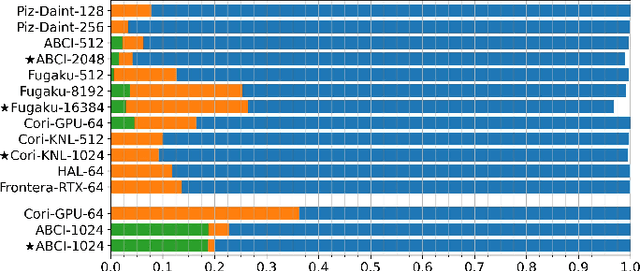
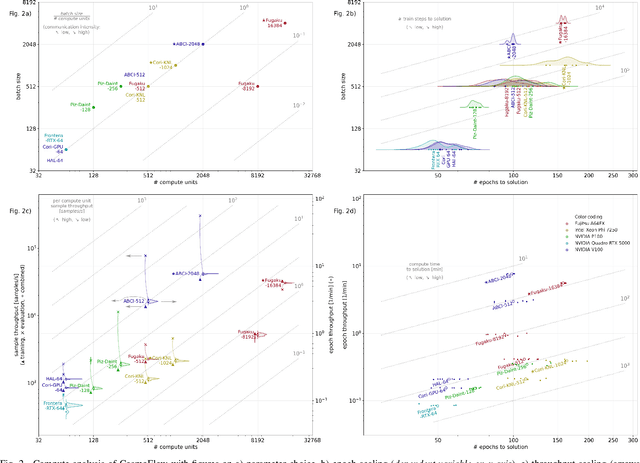
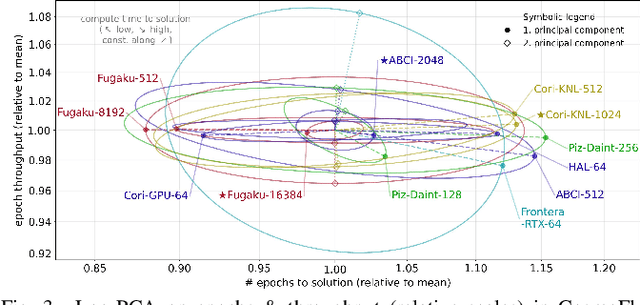
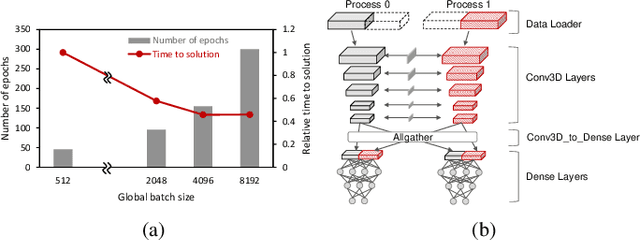
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
The Tracking Machine Learning challenge : Throughput phase
May 14, 2021
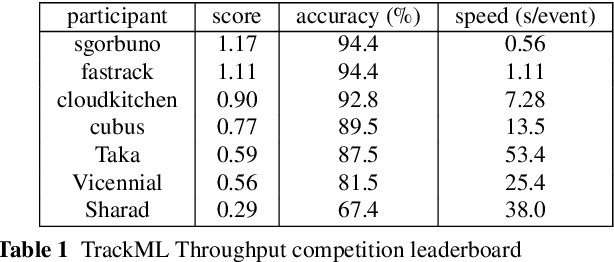
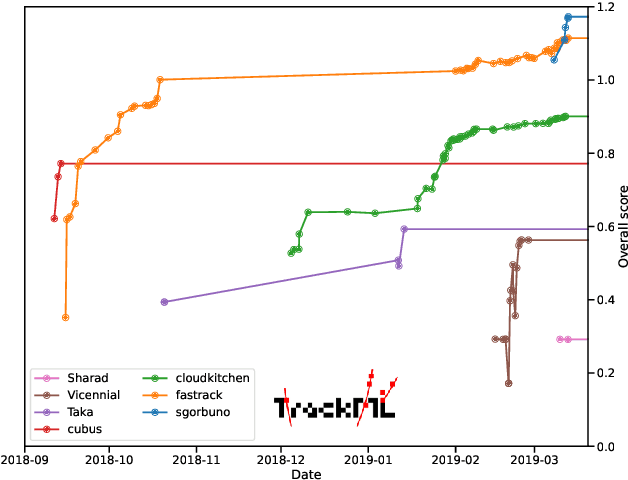
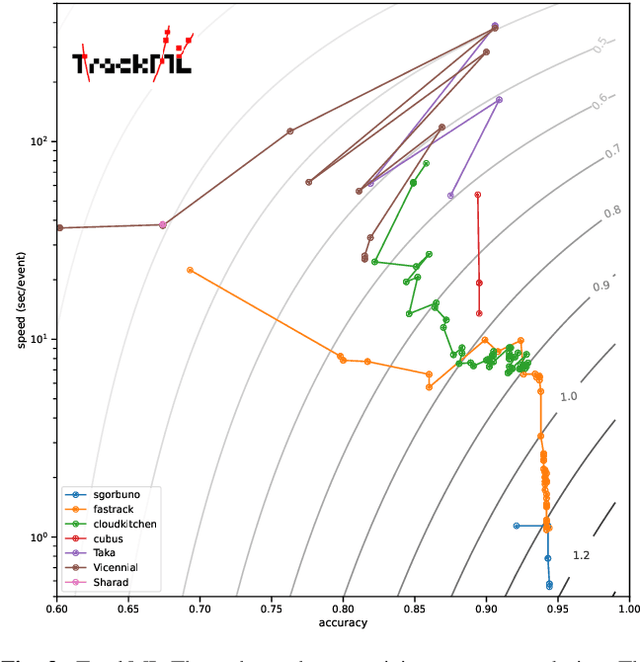
This paper reports on the second "Throughput" phase of the Tracking Machine Learning (TrackML) challenge on the Codalab platform. As in the first "Accuracy" phase, the participants had to solve a difficult experimental problem linked to tracking accurately the trajectory of particles as e.g. created at the Large Hadron Collider (LHC): given O($10^5$) points, the participants had to connect them into O($10^4$) individual groups that represent the particle trajectories which are approximated helical. While in the first phase only the accuracy mattered, the goal of this second phase was a compromise between the accuracy and the speed of inference. Both were measured on the Codalab platform where the participants had to upload their software. The best three participants had solutions with good accuracy and speed an order of magnitude faster than the state of the art when the challenge was designed. Although the core algorithms were less diverse than in the first phase, a diversity of techniques have been used and are described in this paper. The performance of the algorithms are analysed in depth and lessons derived.
Hierarchical Roofline Performance Analysis for Deep Learning Applications
Sep 22, 2020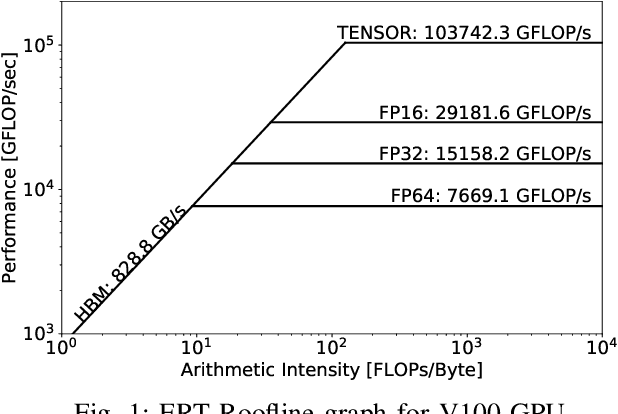
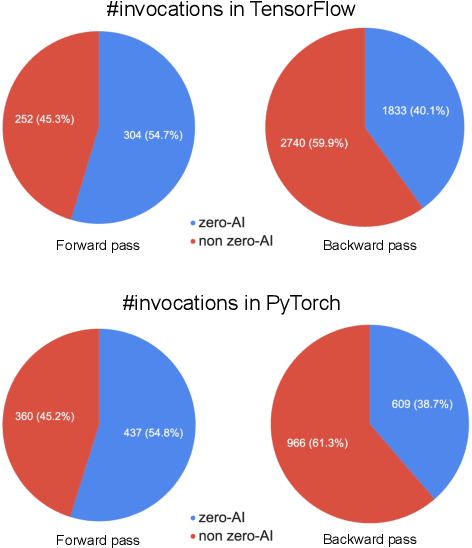
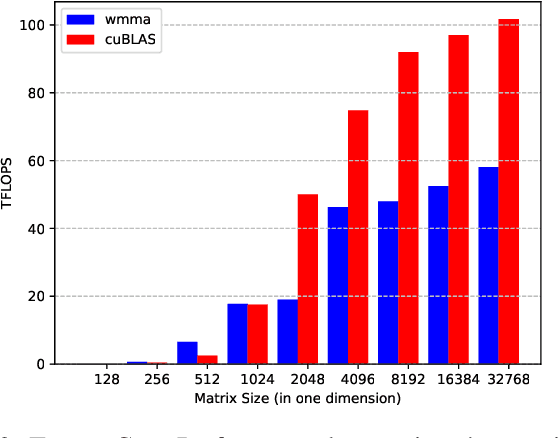
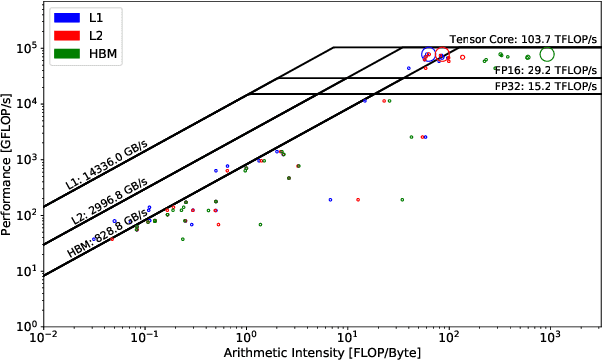
This paper presents a practical methodology for collecting performance data necessary to conduct hierarchical Roofline analysis on NVIDIA GPUs. It discusses the extension of the Empirical Roofline Toolkit for broader support of a range of data precisions and Tensor Core support and introduces a Nsight Compute based method to accurately collect application performance information. This methodology allows for automated machine characterization and application characterization for Roofline analysis across the entire memory hierarchy on NVIDIA GPUs, and it is validated by a complex deep learning application used for climate image segmentation. We use two versions of the code, in TensorFlow and PyTorch respectively, to demonstrate the use and effectiveness of this methodology. We highlight how the application utilizes the compute and memory capabilities on the GPU and how the implementation and performance differ in two deep learning frameworks.
Time-Based Roofline for Deep Learning Performance Analysis
Sep 22, 2020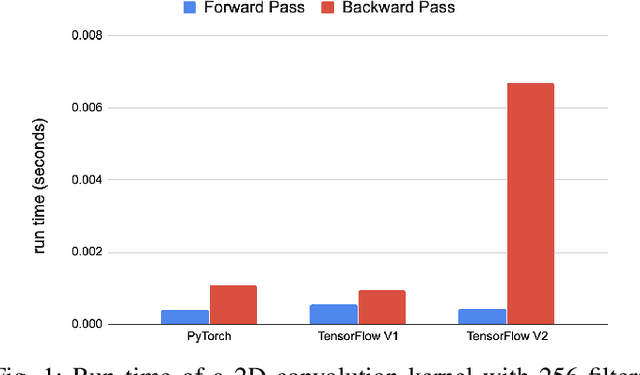
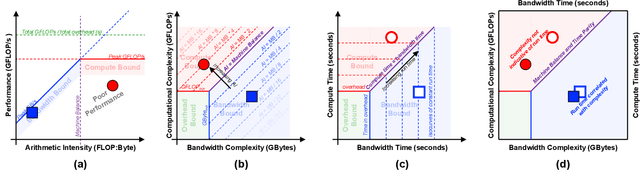
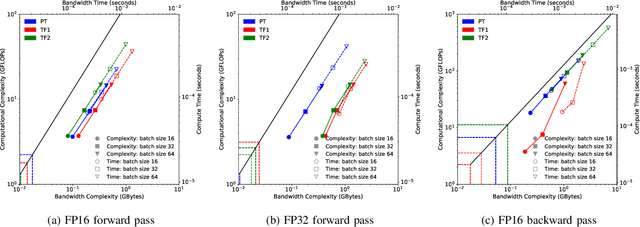
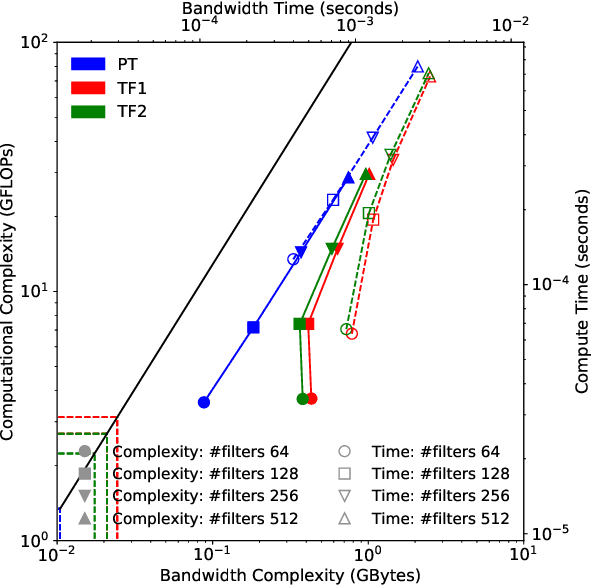
Deep learning applications are usually very compute-intensive and require a long run time for training and inference. This has been tackled by researchers from both hardware and software sides, and in this paper, we propose a Roofline-based approach to performance analysis to facilitate the optimization of these applications. This approach is an extension of the Roofline model widely used in traditional high-performance computing applications, and it incorporates both compute/bandwidth complexity and run time in its formulae to provide insights into deep learning-specific characteristics. We take two sets of representative kernels, 2D convolution and long short-term memory, to validate and demonstrate the use of this new approach, and investigate how arithmetic intensity, cache locality, auto-tuning, kernel launch overhead, and Tensor Core usage can affect performance. Compared to the common ad-hoc approach, this study helps form a more systematic way to analyze code performance and identify optimization opportunities for deep learning applications.
Track Seeding and Labelling with Embedded-space Graph Neural Networks
Jun 30, 2020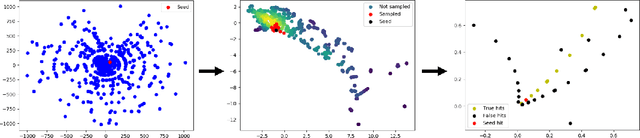
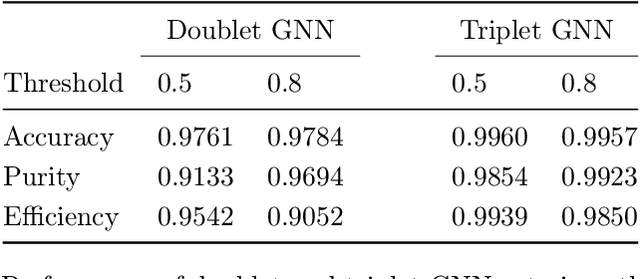

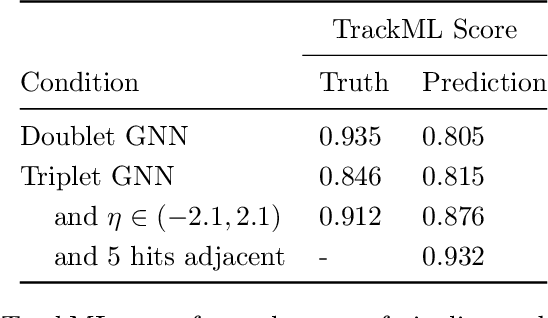
To address the unprecedented scale of HL-LHC data, the Exa.TrkX project is investigating a variety of machine learning approaches to particle track reconstruction. The most promising of these solutions, graph neural networks (GNN), process the event as a graph that connects track measurements (detector hits corresponding to nodes) with candidate line segments between the hits (corresponding to edges). Detector information can be associated with nodes and edges, enabling a GNN to propagate the embedded parameters around the graph and predict node-, edge- and graph-level observables. Previously, message-passing GNNs have shown success in predicting doublet likelihood, and we here report updates on the state-of-the-art architectures for this task. In addition, the Exa.TrkX project has investigated innovations in both graph construction, and embedded representations, in an effort to achieve fully learned end-to-end track finding. Hence, we present a suite of extensions to the original model, with encouraging results for hitgraph classification. In addition, we explore increased performance by constructing graphs from learned representations which contain non-linear metric structure, allowing for efficient clustering and neighborhood queries of data points. We demonstrate how this framework fits in with both traditional clustering pipelines, and GNN approaches. The embedded graphs feed into high-accuracy doublet and triplet classifiers, or can be used as an end-to-end track classifier by clustering in an embedded space. A set of post-processing methods improve performance with knowledge of the detector physics. Finally, we present numerical results on the TrackML particle tracking challenge dataset, where our framework shows favorable results in both seeding and track finding.