 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriPG-RL: Privileged Planner-Guided Reinforcement Learning for Partially Observable Systems with Anytime-Feasible MPC
Apr 09, 2026This paper addresses the problem of training a reinforcement learning (RL) policy under partial observability by exploiting a privileged, anytime-feasible planner agent available exclusively during training. We formalize this as a Partially Observable Markov Decision Process (POMDP) in which a planner agent with access to an approximate dynamical model and privileged state information guides a learning agent that observes only a lossy projection of the true state. To realize this framework, we introduce an anytime-feasible Model Predictive Control (MPC) algorithm that serves as the planner agent. For the learning agent, we propose Planner-to-Policy Soft Actor-Critic (P2P-SAC), a method that distills the planner agent's privileged knowledge to mitigate partial observability and thereby improve both sample efficiency and final policy performance. We support this framework with rigorous theoretical analysis. Finally, we validate our approach in simulation using NVIDIA Isaac Lab and successfully deploy it on a real-world Unitree Go2 quadruped navigating complex, obstacle-rich environments.
KITE: Keyframe-Indexed Tokenized Evidence for VLM-Based Robot Failure Analysis
Apr 08, 2026We present KITE, a training-free, keyframe-anchored, layout-grounded front-end that converts long robot-execution videos into compact, interpretable tokenized evidence for vision-language models (VLMs). KITE distills each trajectory into a small set of motion-salient keyframes with open-vocabulary detections and pairs each keyframe with a schematic bird's-eye-view (BEV) representation that encodes relative object layout, axes, timestamps, and detection confidence. These visual cues are serialized with robot-profile and scene-context tokens into a unified prompt, allowing the same front-end to support failure detection, identification, localization, explanation, and correction with an off-the-shelf VLM. On the RoboFAC benchmark, KITE with Qwen2.5-VL substantially improves over vanilla Qwen2.5-VL in the training-free setting, with especially large gains on simulation failure detection, identification, and localization, while remaining competitive with a RoboFAC-tuned baseline. A small QLoRA fine-tune further improves explanation and correction quality. We also report qualitative results on real dual-arm robots, demonstrating the practical applicability of KITE as a structured and interpretable front-end for robot failure analysis. Code and models are released on our project page: https://m80hz.github.io/kite/
A Physical Agentic Loop for Language-Guided Grasping with Execution-State Monitoring
Apr 08, 2026Robotic manipulation systems that follow language instructions often execute grasp primitives in a largely single-shot manner: a model proposes an action, the robot executes it, and failures such as empty grasps, slips, stalls, timeouts, or semantically wrong grasps are not surfaced to the decision layer in a structured way. Inspired by agentic loops in digital tool-using agents, we reformulate language-guided grasping as a bounded embodied agent operating over grounded execution states, where physical actions expose an explicit tool-state stream. We introduce a physical agentic loop that wraps an unmodified learned manipulation primitive (grasp-and-lift) with (i) an event-based interface and (ii) an execution monitoring layer, Watchdog, which converts noisy gripper telemetry into discrete outcome labels using contact-aware fusion and temporal stabilization. These outcome events, optionally combined with post-grasp semantic verification, are consumed by a deterministic bounded policy that finalizes, retries, or escalates to the user for clarification, guaranteeing finite termination. We validate the resulting loop on a mobile manipulator with an eye-in-hand D405 camera, keeping the underlying grasp model unchanged and evaluating representative scenarios involving visual ambiguity, distractors, and induced execution failures. Results show that explicit execution-state monitoring and bounded recovery enable more robust and interpretable behavior than open-loop execution, while adding minimal architectural overhead. For the source code and demo refer to our project page: https://wenzewwz123.github.io/Agentic-Loop/
Transcriptomic Models for Immunotherapy Response Prediction Show Limited Cross-cohort Generalisability
Apr 07, 2026Immune checkpoint inhibitors (ICIs) have transformed cancer therapy; yet substantial proportion of patients exhibit intrinsic or acquired resistance, making accurate pre-treatment response prediction a critical unmet need. Transcriptomics-based biomarkers derived from bulk and single-cell RNA sequencing (scRNA-seq) offer a promising avenue for capturing tumour-immune interactions, yet the cross-cohort generalisability of existing prediction models remains unclear.We systematically benchmark nine state-of-the-art transcriptomic ICI response predictors, five bulk RNA-seq-based models (COMPASS, IRNet, NetBio, IKCScore, and TNBC-ICI) and four scRNA-seq-based models (PRECISE, DeepGeneX, Tres and scCURE), using publicly available independent datasets unseen during model development. Overall, predictive performance was modest: bulk RNA-seq models performed at or near chance level across most cohorts, while scRNA-seq models showed only marginal improvements. Pathway-level analyses revealed sparse and inconsistent biomarker signals across models. Although scRNA-seq-based predictors converged on immune-related programs such as allograft rejection, bulk RNA-seq-based models exhibited little reproducible overlap. PRECISE and NetBio identified the most coherent immune-related themes, whereas IRNet predominantly captured metabolic pathways weakly aligned with ICI biology. Together, these findings demonstrate the limited cross-cohort robustness and biological consistency of current transcriptomic ICI prediction models, underscoring the need for improved domain adaptation, standardised preprocessing, and biologically grounded model design.
G3Splat: Geometrically Consistent Generalizable Gaussian Splatting
Dec 19, 20253D Gaussians have recently emerged as an effective scene representation for real-time splatting and accurate novel-view synthesis, motivating several works to adapt multi-view structure prediction networks to regress per-pixel 3D Gaussians from images. However, most prior work extends these networks to predict additional Gaussian parameters -- orientation, scale, opacity, and appearance -- while relying almost exclusively on view-synthesis supervision. We show that a view-synthesis loss alone is insufficient to recover geometrically meaningful splats in this setting. We analyze and address the ambiguities of learning 3D Gaussian splats under self-supervision for pose-free generalizable splatting, and introduce G3Splat, which enforces geometric priors to obtain geometrically consistent 3D scene representations. Trained on RE10K, our approach achieves state-of-the-art performance in (i) geometrically consistent reconstruction, (ii) relative pose estimation, and (iii) novel-view synthesis. We further demonstrate strong zero-shot generalization on ScanNet, substantially outperforming prior work in both geometry recovery and relative pose estimation. Code and pretrained models are released on our project page (https://m80hz.github.io/g3splat/).
TANGO: Traversability-Aware Navigation with Local Metric Control for Topological Goals
Sep 10, 2025Visual navigation in robotics traditionally relies on globally-consistent 3D maps or learned controllers, which can be computationally expensive and difficult to generalize across diverse environments. In this work, we present a novel RGB-only, object-level topometric navigation pipeline that enables zero-shot, long-horizon robot navigation without requiring 3D maps or pre-trained controllers. Our approach integrates global topological path planning with local metric trajectory control, allowing the robot to navigate towards object-level sub-goals while avoiding obstacles. We address key limitations of previous methods by continuously predicting local trajectory using monocular depth and traversability estimation, and incorporating an auto-switching mechanism that falls back to a baseline controller when necessary. The system operates using foundational models, ensuring open-set applicability without the need for domain-specific fine-tuning. We demonstrate the effectiveness of our method in both simulated environments and real-world tests, highlighting its robustness and deployability. Our approach outperforms existing state-of-the-art methods, offering a more adaptable and effective solution for visual navigation in open-set environments. The source code is made publicly available: https://github.com/podgorki/TANGO.
A Guaranteed-Stable Neural Network Approach for Optimal Control of Nonlinear Systems
Jan 28, 2025



A promising approach to optimal control of nonlinear systems involves iteratively linearizing the system and solving an optimization problem at each time instant to determine the optimal control input. Since this approach relies on online optimization, it can be computationally expensive, and thus unrealistic for systems with limited computing resources. One potential solution to this issue is to incorporate a Neural Network (NN) into the control loop to emulate the behavior of the optimal control scheme. Ensuring stability and reference tracking in the resulting NN-based closed-loop system requires modifications to the primary optimization problem. These modifications often introduce non-convexity and nonlinearity with respect to the decision variables, which may surpass the capabilities of existing solvers and complicate the generation of the training dataset. To address this issue, this paper develops a Neural Optimization Machine (NOM) to solve the resulting optimization problems. The central concept of a NOM is to transform the optimization challenges into the problem of training a NN. Rigorous proofs demonstrate that when a NN trained on data generated by the NOM is used in the control loop, all signals remain bounded and the system states asymptotically converge to a neighborhood around the desired equilibrium point, with a tunable proximity threshold. Simulation and experimental studies are provided to illustrate the effectiveness of the proposed methodology.
BEVPose: Unveiling Scene Semantics through Pose-Guided Multi-Modal BEV Alignment
Oct 28, 2024



In the field of autonomous driving and mobile robotics, there has been a significant shift in the methods used to create Bird's Eye View (BEV) representations. This shift is characterised by using transformers and learning to fuse measurements from disparate vision sensors, mainly lidar and cameras, into a 2D planar ground-based representation. However, these learning-based methods for creating such maps often rely heavily on extensive annotated data, presenting notable challenges, particularly in diverse or non-urban environments where large-scale datasets are scarce. In this work, we present BEVPose, a framework that integrates BEV representations from camera and lidar data, using sensor pose as a guiding supervisory signal. This method notably reduces the dependence on costly annotated data. By leveraging pose information, we align and fuse multi-modal sensory inputs, facilitating the learning of latent BEV embeddings that capture both geometric and semantic aspects of the environment. Our pretraining approach demonstrates promising performance in BEV map segmentation tasks, outperforming fully-supervised state-of-the-art methods, while necessitating only a minimal amount of annotated data. This development not only confronts the challenge of data efficiency in BEV representation learning but also broadens the potential for such techniques in a variety of domains, including off-road and indoor environments.
Enhanced Classification of Heart Sounds Using Mel Frequency Cepstral Coefficients: A Comparative Study of Single and Ensemble Classifier Strategies
Jun 02, 2024



This paper explores the efficacy of Mel Frequency Cepstral Coefficients (MFCCs) in detecting abnormal phonocardiograms using two classification strategies: a single-classifier and an ensemble-classifier approach. Phonocardiograms were segmented into S1, systole, S2, and diastole intervals, with thirteen MFCCs estimated from each segment, yielding 52 MFCCs per beat. In the single-classifier strategy, the MFCCs from nine consecutive beats were averaged to classify phonocardiograms. Conversely, the ensemble-classifier strategy employed nine classifiers to individually assess beats as normal or abnormal, with the overall classification based on the majority vote. Both methods were tested on a publicly available phonocardiogram database. Results demonstrated that the ensemble-classifier strategy achieved higher accuracy compared to the single-classifier approach, establishing MFCCs as more effective than other features, including time, time-frequency, and statistical features, evaluated in similar studies.
RoboHop: Segment-based Topological Map Representation for Open-World Visual Navigation
May 09, 2024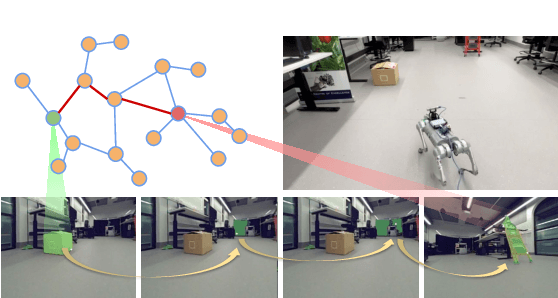
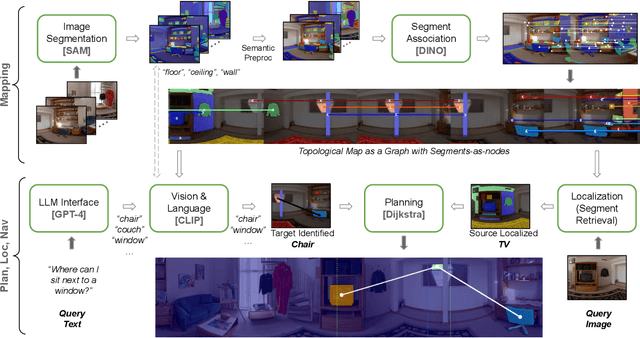
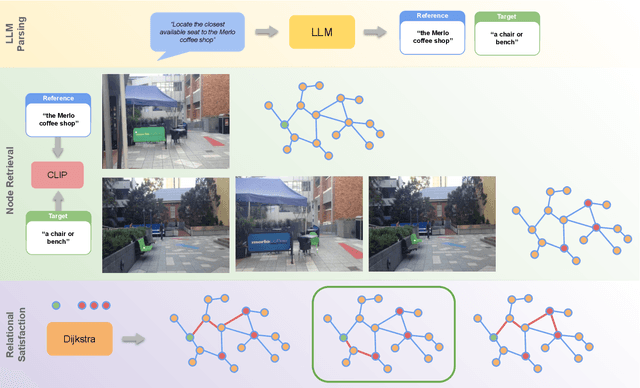

Mapping is crucial for spatial reasoning, planning and robot navigation. Existing approaches range from metric, which require precise geometry-based optimization, to purely topological, where image-as-node based graphs lack explicit object-level reasoning and interconnectivity. In this paper, we propose a novel topological representation of an environment based on "image segments", which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a "continuous sense of a place", defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval. Using real-world data, we show how our proposed map representation can be used to i) generate navigation plans in the form of "hops over segments" and ii) search for target objects using natural language queries describing spatial relations of objects. Furthermore, we quantitatively analyze data association at the segment level, which underpins inter-image connectivity during mapping and segment-level localization when revisiting the same place. Finally, we show preliminary trials on segment-level `hopping' based zero-shot real-world navigation. Project page with supplementary details: oravus.github.io/RoboHop/