 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ProMask: Probability Mask for Skeleton Detection
Dec 05, 2020
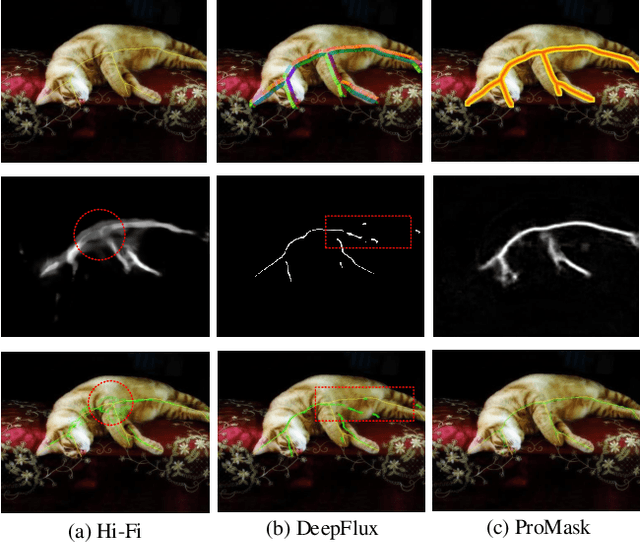
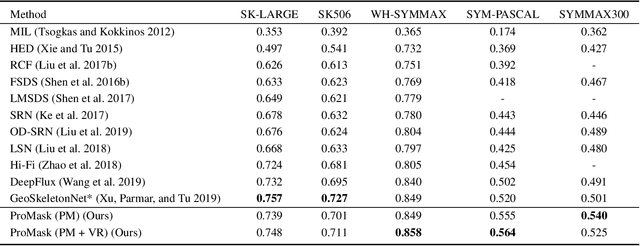
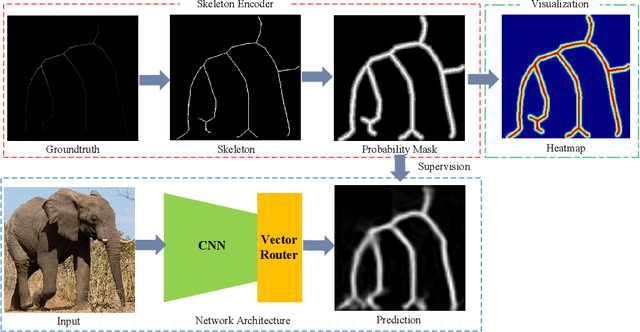
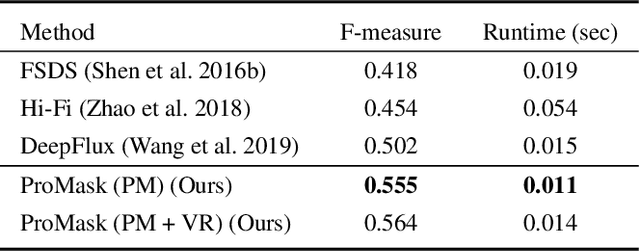
Detecting object skeletons in natural images presents challenging, due to varied object scales, the complexity of backgrounds and various noises. The skeleton is a highly compressing shape representation, which can bring some essential advantages but cause the difficulties of detection. This skeleton line occupies a rare proportion of an image and is overly sensitive to spatial position. Inspired by these issues, we propose the ProMask, which is a novel skeleton detection model. The ProMask includes the probability mask and vector router. The skeleton probability mask representation explicitly encodes skeletons with segmentation signals, which can provide more supervised information to learn and pay more attention to ground-truth skeleton pixels. Moreover, the vector router module possesses two sets of orthogonal basis vectors in a two-dimensional space, which can dynamically adjust the predicted skeleton position. We evaluate our method on the well-known skeleton datasets, realizing the better performance than state-of-the-art approaches. Especially, ProMask significantly outperforms the competitive DeepFlux by 6.2% on the challenging SYM-PASCAL dataset. We consider that our proposed skeleton probability mask could serve as a solid baseline for future skeleton detection, since it is very effective and it requires about 10 lines of code.
Deep Depth Estimation from Visual-Inertial SLAM
Aug 14, 2020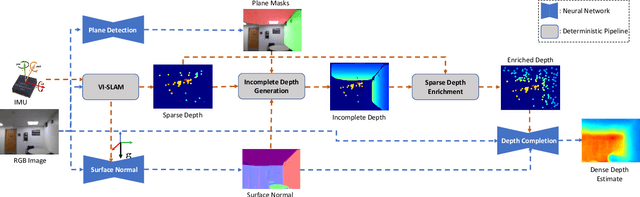
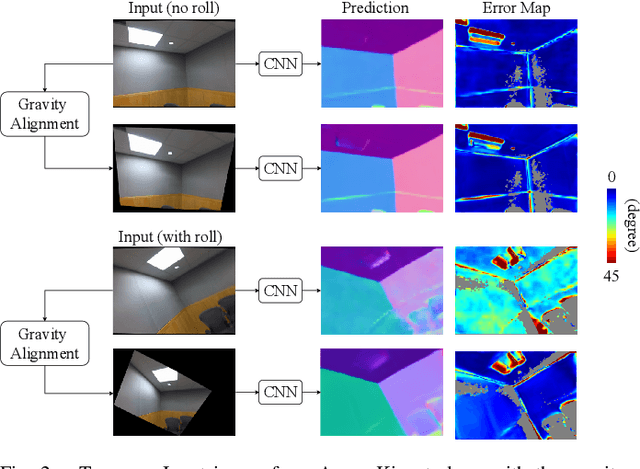

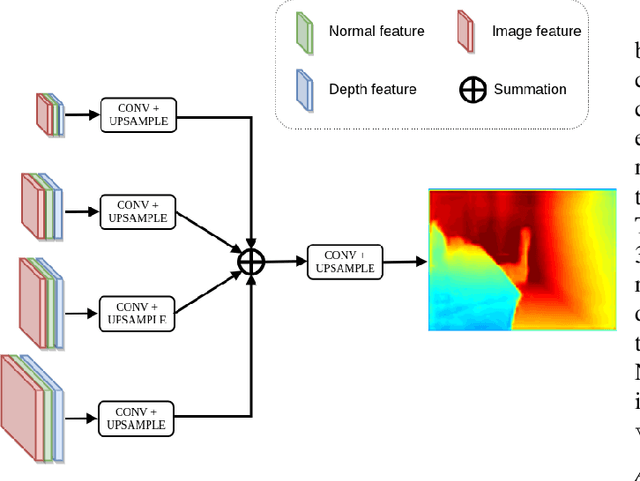
This paper addresses the problem of learning to complete a scene's depth from sparse depth points and images of indoor scenes. Specifically, we study the case in which the sparse depth is computed from a visual-inertial simultaneous localization and mapping (VI-SLAM) system. The resulting point cloud has low density, it is noisy, and has non-uniform spatial distribution, as compared to the input from active depth sensors, e.g., LiDAR or Kinect. Since the VI-SLAM produces point clouds only over textured areas, we compensate for the missing depth of the low-texture surfaces by leveraging their planar structures and their surface normals which is an important intermediate representation. The pre-trained surface normal network, however, suffers from large performance degradation when there is a significant difference in the viewing direction (especially the roll angle) of the test image as compared to the trained ones. To address this limitation, we use the available gravity estimate from the VI-SLAM to warp the input image to the orientation prevailing in the training dataset. This results in a significant performance gain for the surface normal estimate, and thus the dense depth estimates. Finally, we show that our method outperforms other state-of-the-art approaches both on training (ScanNet and NYUv2) and testing (collected with Azure Kinect) datasets.
From two rolling shutters to one global shutter
Jun 02, 2020

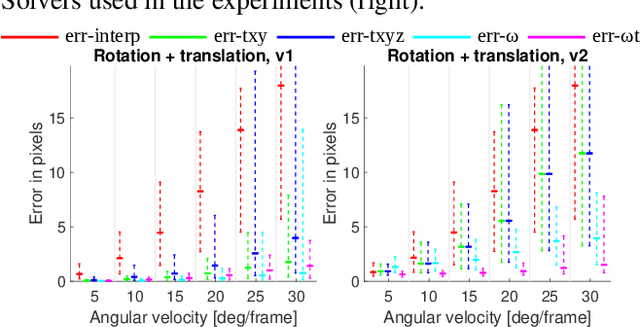
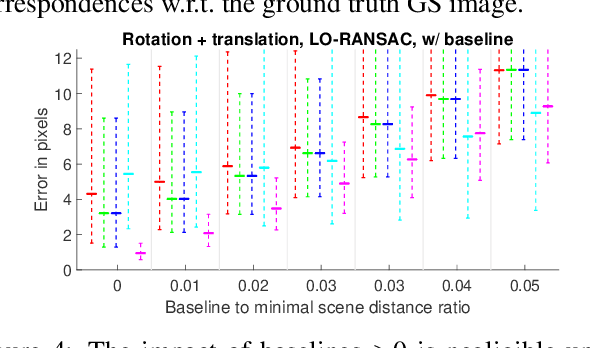
Most consumer cameras are equipped with electronic rolling shutter, leading to image distortions when the camera moves during image capture. We explore a surprisingly simple camera configuration that makes it possible to undo the rolling shutter distortion: two cameras mounted to have different rolling shutter directions. Such a setup is easy and cheap to build and it possesses the geometric constraints needed to correct rolling shutter distortion using only a sparse set of point correspondences between the two images. We derive equations that describe the underlying geometry for general and special motions and present an efficient method for finding their solutions. Our synthetic and real experiments demonstrate that our approach is able to remove large rolling shutter distortions of all types without relying on any specific scene structure.
A Comprehensive Survey on Deep Music Generation: Multi-level Representations, Algorithms, Evaluations, and Future Directions
Nov 13, 2020
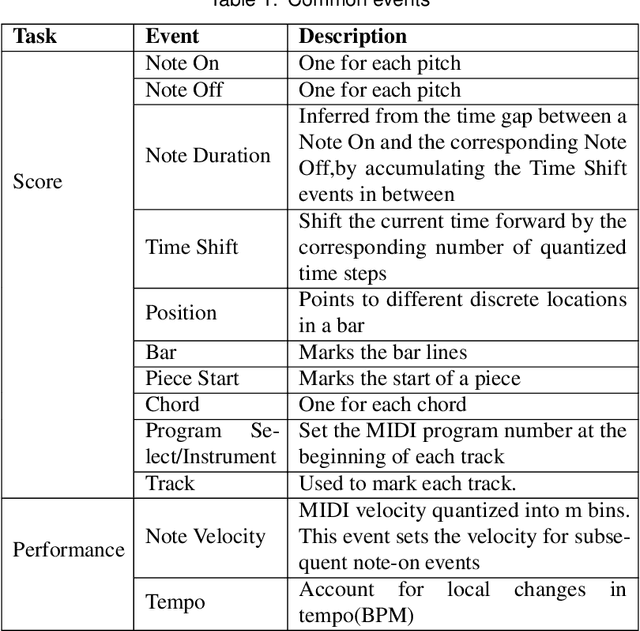
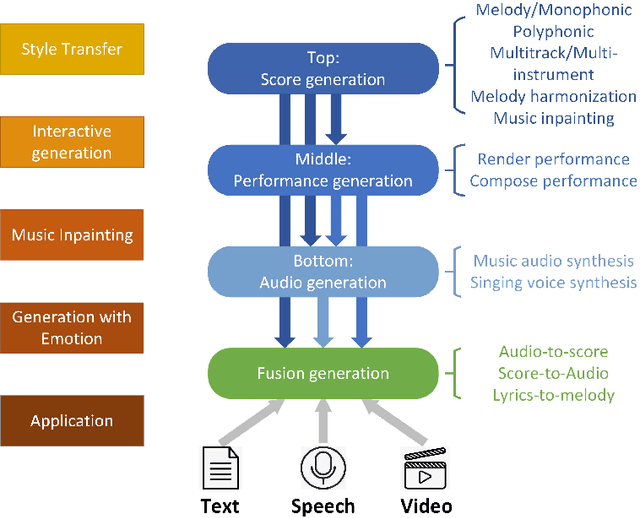

The utilization of deep learning techniques in generating various contents (such as image, text, etc.) has become a trend. Especially music, the topic of this paper, has attracted widespread attention of countless researchers.The whole process of producing music can be divided into three stages, corresponding to the three levels of music generation: score generation produces scores, performance generation adds performance characteristics to the scores, and audio generation converts scores with performance characteristics into audio by assigning timbre or generates music in audio format directly. Previous surveys have explored the network models employed in the field of automatic music generation. However, the development history, the model evolution, as well as the pros and cons of same music generation task have not been clearly illustrated. This paper attempts to provide an overview of various composition tasks under different music generation levels, covering most of the currently popular music generation tasks using deep learning. In addition, we summarize the datasets suitable for diverse tasks, discuss the music representations, the evaluation methods as well as the challenges under different levels, and finally point out several future directions.
Neural Topological SLAM for Visual Navigation
May 25, 2020
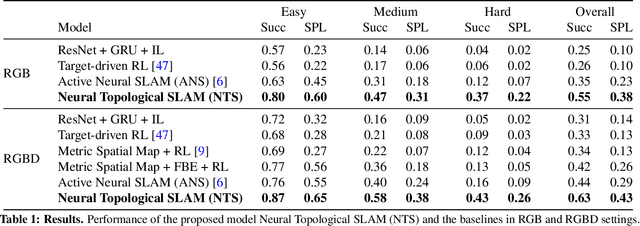

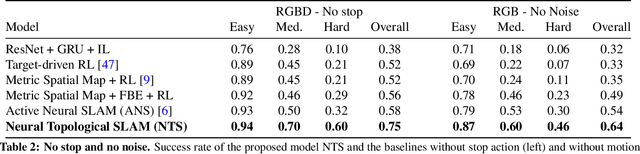
This paper studies the problem of image-goal navigation which involves navigating to the location indicated by a goal image in a novel previously unseen environment. To tackle this problem, we design topological representations for space that effectively leverage semantics and afford approximate geometric reasoning. At the heart of our representations are nodes with associated semantic features, that are interconnected using coarse geometric information. We describe supervised learning-based algorithms that can build, maintain and use such representations under noisy actuation. Experimental study in visually and physically realistic simulation suggests that our method builds effective representations that capture structural regularities and efficiently solve long-horizon navigation problems. We observe a relative improvement of more than 50% over existing methods that study this task.
FireSRnet: Geoscience-Driven Super-Resolution of Future Fire Risk from Climate Change
Nov 24, 2020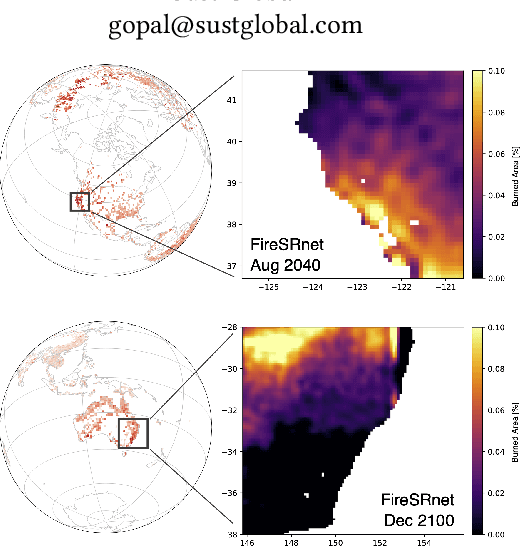
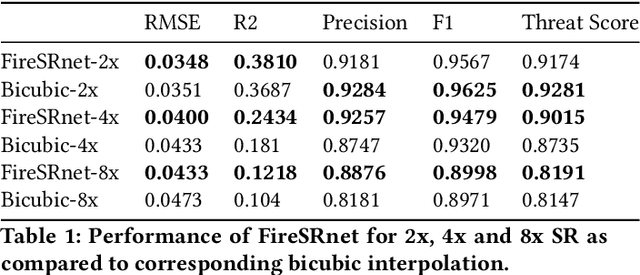
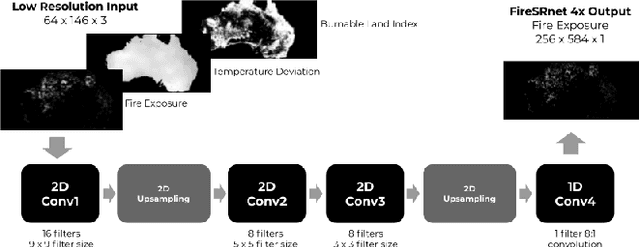
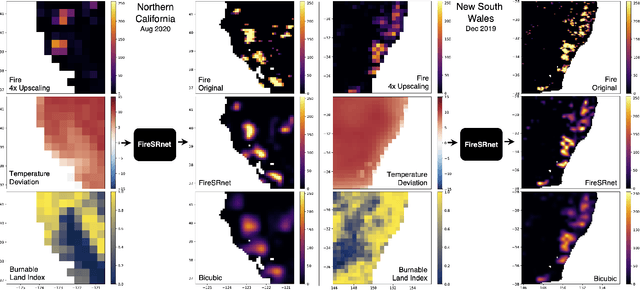
With fires becoming increasingly frequent and severe across the globe in recent years, understanding climate change's role in fire behavior is critical for quantifying current and future fire risk. However, global climate models typically simulate fire behavior at spatial scales too coarse for local risk assessments. Therefore, we propose a novel approach towards super-resolution (SR) enhancement of fire risk exposure maps that incorporates not only 2000 to 2020 monthly satellite observations of active fires but also local information on land cover and temperature. Inspired by SR architectures, we propose an efficient deep learning model trained for SR on fire risk exposure maps. We evaluate this model on resolution enhancement and find it outperforms standard image interpolation techniques at both 4x and 8x enhancement while having comparable performance at 2x enhancement. We then demonstrate the generalizability of this SR model over northern California and New South Wales, Australia. We conclude with a discussion and application of our proposed model to climate model simulations of fire risk in 2040 and 2100, illustrating the potential for SR enhancement of fire risk maps from the latest state-of-the-art climate models.
Lesion2Vec: Deep Metric Learning for Few-Shot Multiple Lesions Recognition in Wireless Capsule Endoscopy Video
Jan 15, 2021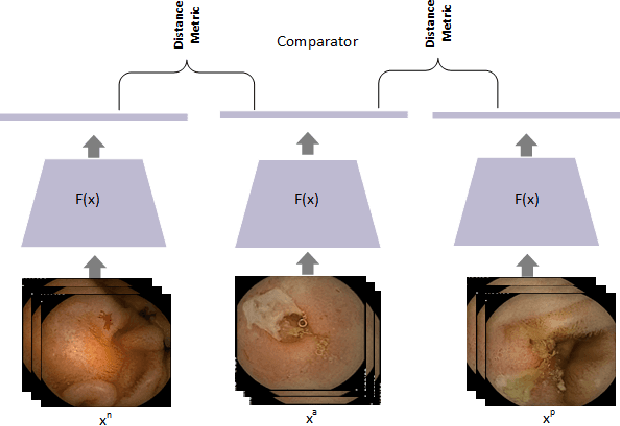
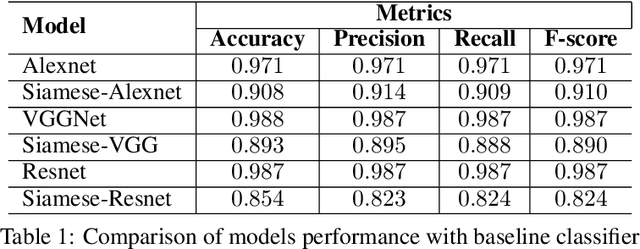
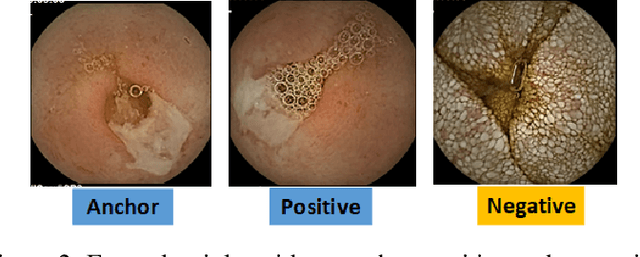
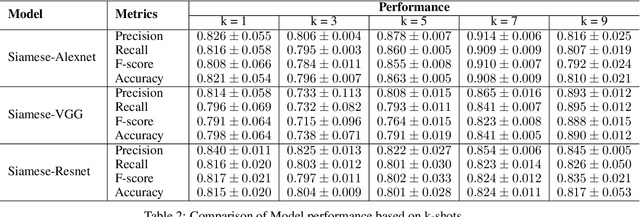
Effective and rapid detection of lesions in the Gastrointestinal tract is critical to gastroenterologist's response to some life-threatening diseases. Wireless Capsule Endoscopy (WCE) has revolutionized traditional endoscopy procedure by allowing gastroenterologists visualize the entire GI tract non-invasively. Once the tiny capsule is swallowed, it sequentially capture images of the GI tract at about 2 to 6 frames per second (fps). A single video can last up to 8 hours producing between 30,000 to 100,000 images. Automating the detection of frames containing specific lesion in WCE video would relieve gastroenterologists the arduous task of reviewing the entire video before making diagnosis. While the WCE produces large volume of images, only about 5\% of the frames contain lesions that aid the diagnosis process. Convolutional Neural Network (CNN) based models have been very successful in various image classification tasks. However, they suffer excessive parameters, are sample inefficient and rely on very large amount of training data. Deploying a CNN classifier for lesion detection task will require time-to-time fine-tuning to generalize to any unforeseen category. In this paper, we propose a metric-based learning framework followed by a few-shot lesion recognition in WCE data. Metric-based learning is a meta-learning framework designed to establish similarity or dissimilarity between concepts while few-shot learning (FSL) aims to identify new concepts from only a small number of examples. We train a feature extractor to learn a representation for different small bowel lesions using metric-based learning. At the testing stage, the category of an unseen sample is predicted from only a few support examples, thereby allowing the model to generalize to a new category that has never been seen before. We demonstrated the efficacy of this method on real patient capsule endoscopy data.
Object Boundary Detection and Classification with Image-level Labels
Jun 25, 2017



Semantic boundary and edge detection aims at simultaneously detecting object edge pixels in images and assigning class labels to them. Systematic training of predictors for this task requires the labeling of edges in images which is a particularly tedious task. We propose a novel strategy for solving this task, when pixel-level annotations are not available, performing it in an almost zero-shot manner by relying on conventional whole image neural net classifiers that were trained using large bounding boxes. Our method performs the following two steps at test time. Firstly it predicts the class labels by applying the trained whole image network to the test images. Secondly, it computes pixel-wise scores from the obtained predictions by applying backprop gradients as well as recent visualization algorithms such as deconvolution and layer-wise relevance propagation. We show that high pixel-wise scores are indicative for the location of semantic boundaries, which suggests that the semantic boundary problem can be approached without using edge labels during the training phase.
Using Transfer Learning for Image-Based Cassava Disease Detection
Aug 01, 2017

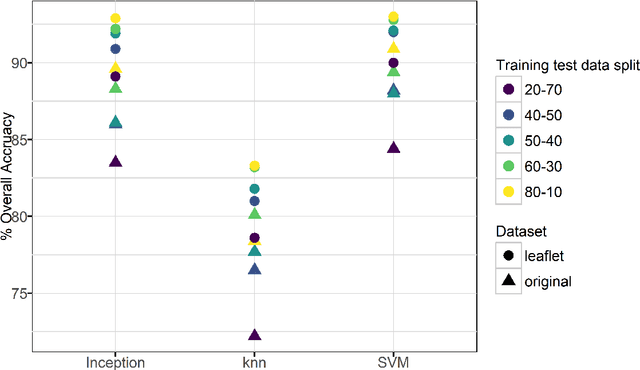

Cassava is the third largest source of carbohydrates for human food in the world but is vulnerable to virus diseases, which threaten to destabilize food security in sub-Saharan Africa. Novel methods of cassava disease detection are needed to support improved control which will prevent this crisis. Image recognition offers both a cost effective and scalable technology for disease detection. New transfer learning methods offer an avenue for this technology to be easily deployed on mobile devices. Using a dataset of cassava disease images taken in the field in Tanzania, we applied transfer learning to train a deep convolutional neural network to identify three diseases and two types of pest damage (or lack thereof). The best trained model accuracies were 98% for brown leaf spot (BLS), 96% for red mite damage (RMD), 95% for green mite damage (GMD), 98% for cassava brown streak disease (CBSD), and 96% for cassava mosaic disease (CMD). The best model achieved an overall accuracy of 93% for data not used in the training process. Our results show that the transfer learning approach for image recognition of field images offers a fast, affordable, and easily deployable strategy for digital plant disease detection.
* 10 pages, 4 figures
Discovering Hidden Physics Behind Transport Dynamics
Nov 24, 2020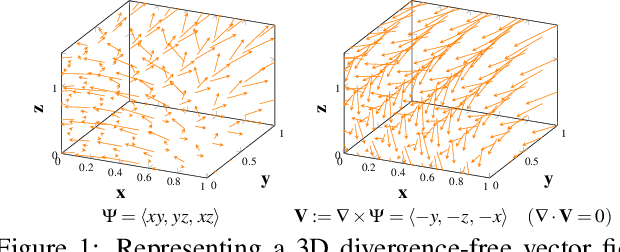
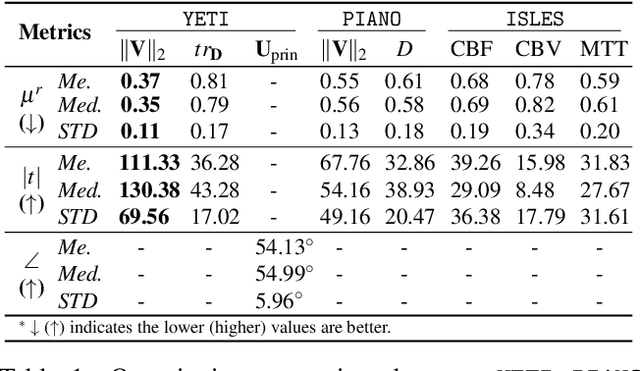

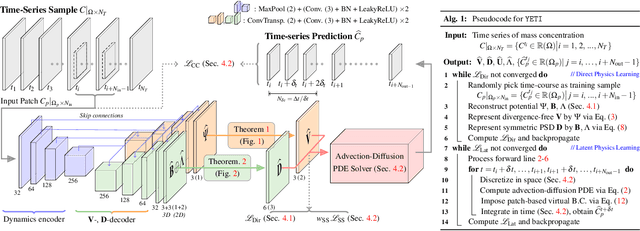
Transport processes are ubiquitous. They are, for example, at the heart of optical flow approaches; or of perfusion imaging, where blood transport is assessed, most commonly by injecting a tracer. An advection-diffusion equation is widely used to describe these transport phenomena. Our goal is estimating the underlying physics of advection-diffusion equations, expressed as velocity and diffusion tensor fields. We propose a learning framework (YETI) building on an auto-encoder structure between 2D and 3D image time-series, which incorporates the advection-diffusion model. To help with identifiability, we develop an advection-diffusion simulator which allows pre-training of our model by supervised learning using the velocity and diffusion tensor fields. Instead of directly learning these velocity and diffusion tensor fields, we introduce representations that assure incompressible flow and symmetric positive semi-definite diffusion fields and demonstrate the additional benefits of these representations on improving estimation accuracy. We further use transfer learning to apply YETI on a public brain magnetic resonance (MR) perfusion dataset of stroke patients and show its ability to successfully distinguish stroke lesions from normal brain regions via the estimated velocity and diffusion tensor fields.