 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Direct Algorithm for Multi-Gyroscope Infield Calibration
Mar 13, 2024



In this paper, we address the problem of estimating the rotational extrinsics, as well as the scale factors of two gyroscopes rigidly mounted on the same device. In particular, we formulate the problem as a least-squares minimization and introduce a direct algorithm that computes the estimated quantities without any iterations, hence avoiding local minima and improving efficiency. Furthermore, we show that the rotational extrinsics are observable while the scale factors can be determined up to global scale for general configurations of the gyroscopes. To this end, we also study special placements of the gyroscopes where a pair, or all, of their axes are parallel and analyze their impact on the scale factors' observability. Lastly, we evaluate our algorithm in simulations and real-world experiments to assess its performance as a function of key motion and sensor characteristics.
RISE-SLAM: A Resource-aware Inverse Schmidt Estimator for SLAM
Nov 23, 2020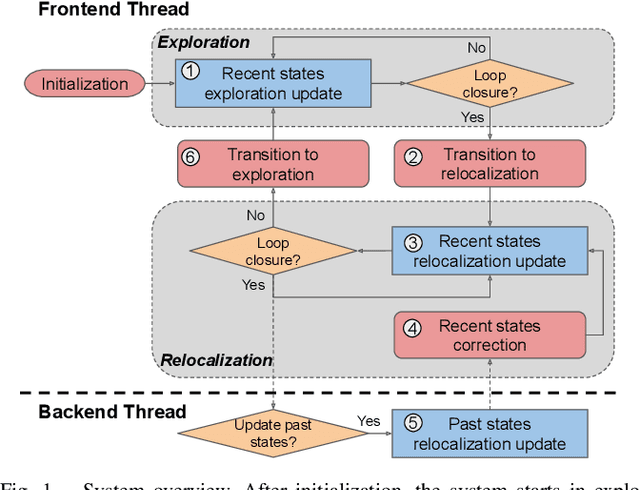
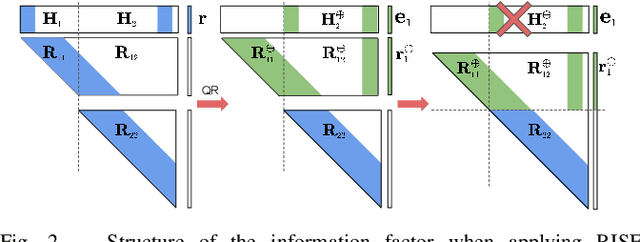
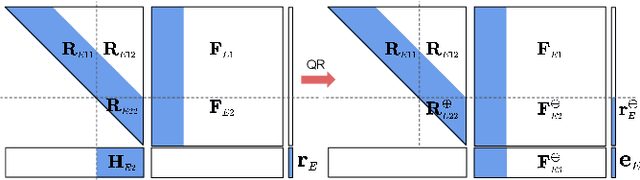
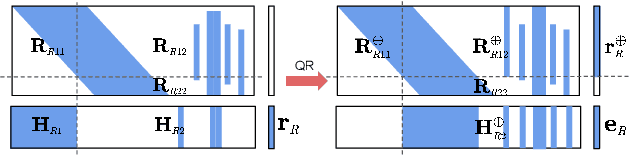
In this paper, we present the RISE-SLAM algorithm for performing visual-inertial simultaneous localization and mapping (SLAM), while improving estimation consistency. Specifically, in order to achieve real-time operation, existing approaches often assume previously-estimated states to be perfectly known, which leads to inconsistent estimates. Instead, based on the idea of the Schmidt-Kalman filter, which has processing cost linear in the size of the state vector but quadratic memory requirements, we derive a new consistent approximate method in the information domain, which has linear memory requirements and adjustable (constant to linear) processing cost. In particular, this method, the resource-aware inverse Schmidt estimator (RISE), allows trading estimation accuracy for computational efficiency. Furthermore, and in order to better address the requirements of a SLAM system during an exploration vs. a relocalization phase, we employ different configurations of RISE (in terms of the number and order of states updated) to maximize accuracy while preserving efficiency. Lastly, we evaluate the proposed RISE-SLAM algorithm on publicly-available datasets and demonstrate its superiority, both in terms of accuracy and efficiency, as compared to alternative visual-inertial SLAM systems.
Deep Multi-view Depth Estimation with Predicted Uncertainty
Nov 19, 2020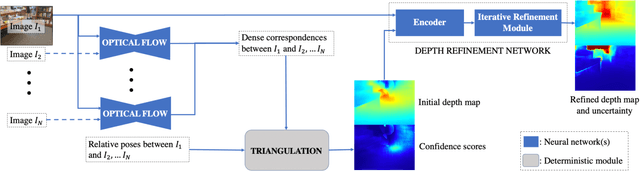
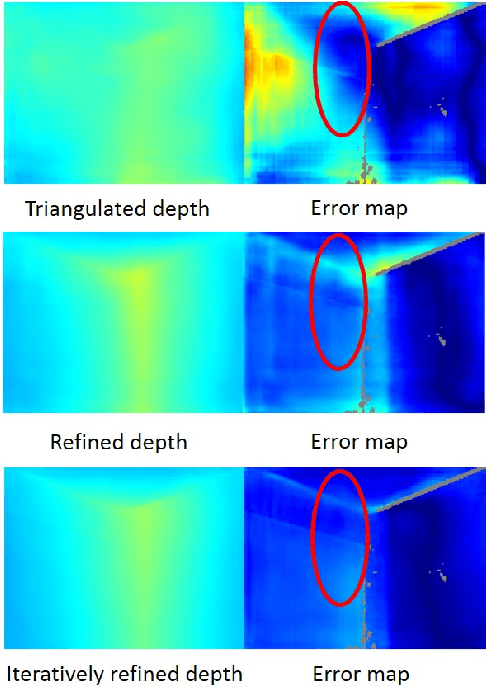


In this paper, we address the problem of estimating dense depth from a sequence of images using deep neural networks. Specifically, we employ a dense-optical-flow network to compute correspondences and then triangulate the point cloud to obtain an initial depth map. Parts of the point cloud, however, may be less accurate than others due to lack of common observations or small baseline-to-depth ratio. To further increase the triangulation accuracy, we introduce a depth-refinement network (DRN) that optimizes the initial depth map based on the image's contextual cues. In particular, the DRN contains an iterative refinement module (IRM) that improves the depth accuracy over iterations by refining the deep features. Lastly, the DRN also predicts the uncertainty in the refined depths, which is desirable in applications such as measurement selection for scene reconstruction. We show experimentally that our algorithm outperforms state-of-the-art approaches in terms of depth accuracy, and verify that our predicted uncertainty is highly correlated to the actual depth error.
Deep Depth Estimation from Visual-Inertial SLAM
Aug 14, 2020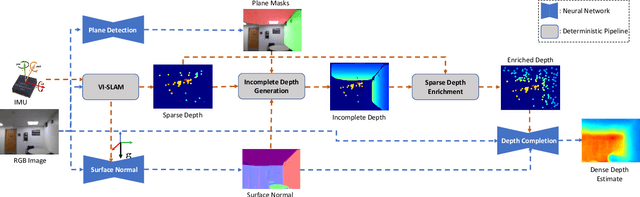
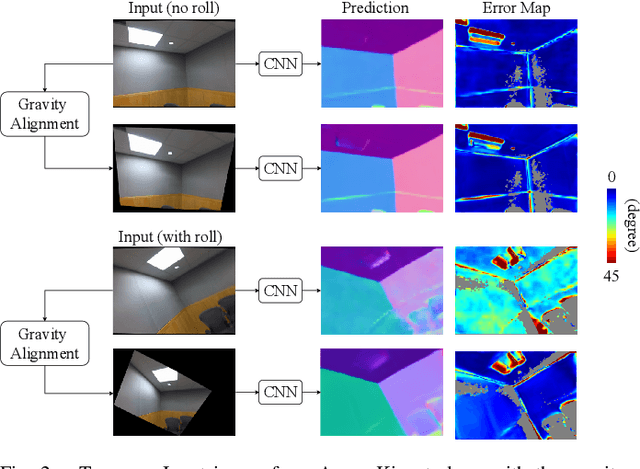

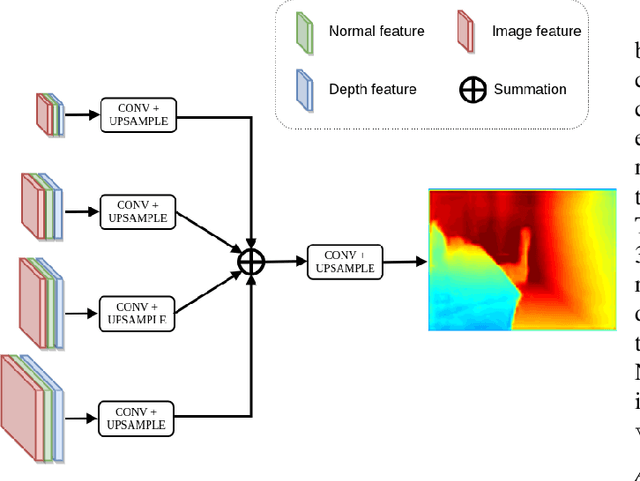
This paper addresses the problem of learning to complete a scene's depth from sparse depth points and images of indoor scenes. Specifically, we study the case in which the sparse depth is computed from a visual-inertial simultaneous localization and mapping (VI-SLAM) system. The resulting point cloud has low density, it is noisy, and has non-uniform spatial distribution, as compared to the input from active depth sensors, e.g., LiDAR or Kinect. Since the VI-SLAM produces point clouds only over textured areas, we compensate for the missing depth of the low-texture surfaces by leveraging their planar structures and their surface normals which is an important intermediate representation. The pre-trained surface normal network, however, suffers from large performance degradation when there is a significant difference in the viewing direction (especially the roll angle) of the test image as compared to the trained ones. To address this limitation, we use the available gravity estimate from the VI-SLAM to warp the input image to the orientation prevailing in the training dataset. This results in a significant performance gain for the surface normal estimate, and thus the dense depth estimates. Finally, we show that our method outperforms other state-of-the-art approaches both on training (ScanNet and NYUv2) and testing (collected with Azure Kinect) datasets.
Surface Normal Estimation of Tilted Images via Spatial Rectifier
Jul 17, 2020
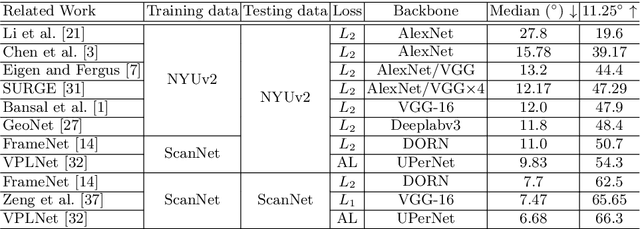
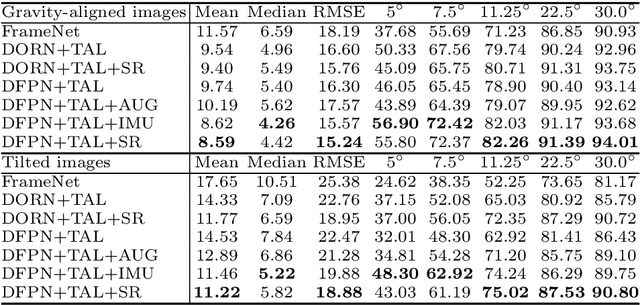
In this paper, we present a spatial rectifier to estimate surface normals of tilted images. Tilted images are of particular interest as more visual data are captured by arbitrarily oriented sensors such as body-/robot-mounted cameras. Existing approaches exhibit bounded performance on predicting surface normals because they were trained using gravity-aligned images. Our two main hypotheses are: (1) visual scene layout is indicative of the gravity direction; and (2) not all surfaces are equally represented by a learned estimator due to the structured distribution of the training data, thus, there exists a transformation for each tilted image that is more responsive to the learned estimator than others. We design a spatial rectifier that is learned to transform the surface normal distribution of a tilted image to the rectified one that matches the gravity-aligned training data distribution. Along with the spatial rectifier, we propose a novel truncated angular loss that offers a stronger gradient at smaller angular errors and robustness to outliers. The resulting estimator outperforms the state-of-the-art methods including data augmentation baselines not only on ScanNet and NYUv2 but also on a new dataset called Tilt-RGBD that includes considerable roll and pitch camera motion.
Consistent Map-based 3D Localization on Mobile Devices
Apr 27, 2016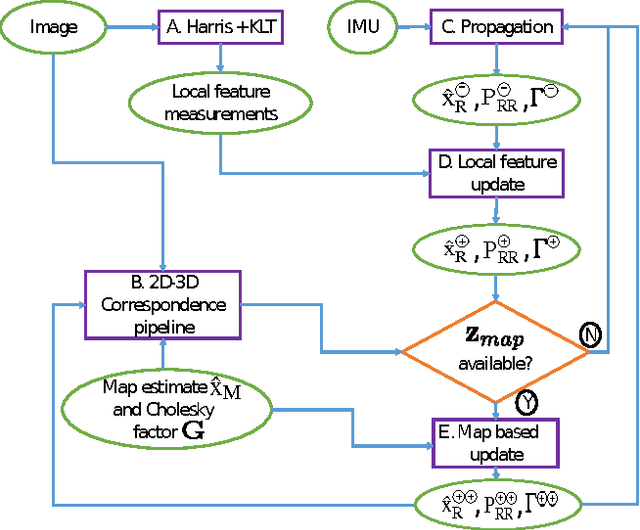
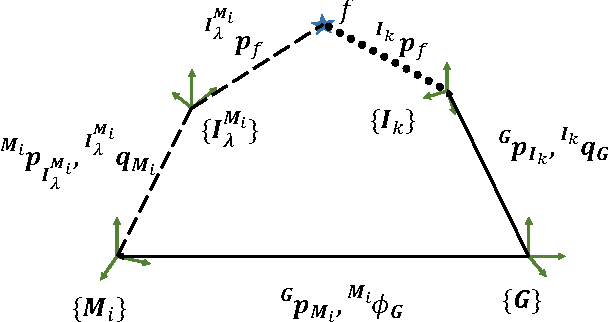
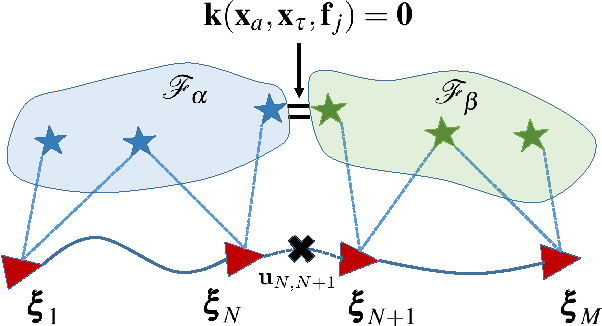
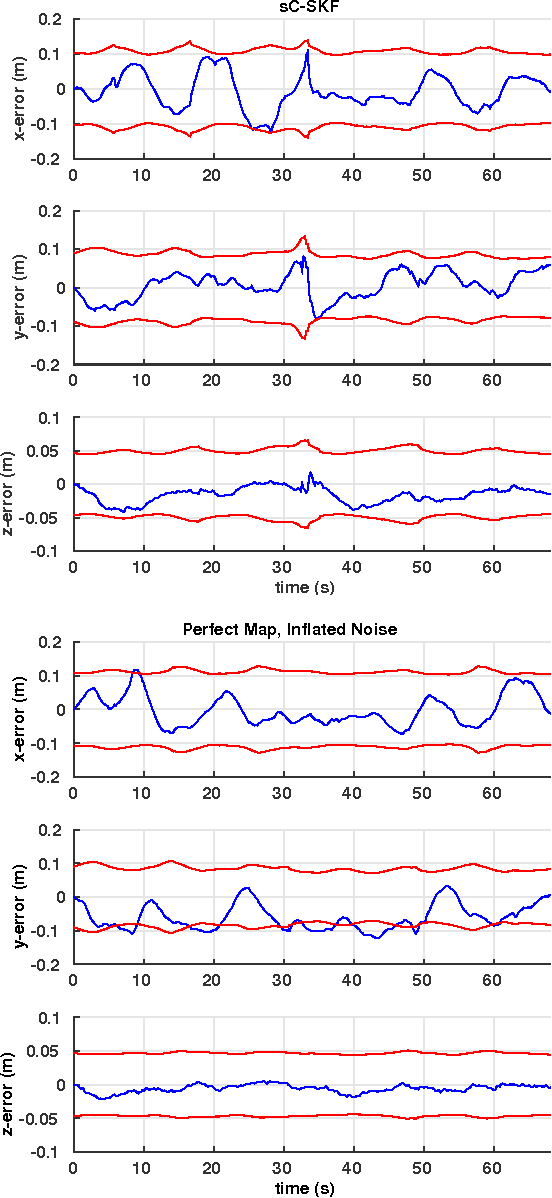
The objective of this paper is to provide consistent, real-time 3D localization capabilities to mobile devices navigating within previously mapped areas. To this end, we introduce the Cholesky-Schmidt-Kalman filter (C-SKF), which explicitly considers the uncertainty of the prior map, by employing the sparse Cholesky factor of the map's Hessian, instead of its dense covariance--as is the case for the Schmidt-Kalman filter (SKF). By doing so, the C-SKF has memory requirements typically linear in the size of the map, as opposed to quadratic for storing the map's covariance. Moreover, and in order to bound the processing needs of the C-SKF (between linear and quadratic in the size of the map), we introduce a relaxation of the C-SKF algorithm, the sC-SKF, which operates on the Cholesky factors of independent sub-maps resulting from dividing the trajectory and observations used for constructing the map into overlapping segments. Lastly, we assess the processing and memory requirements of the proposed C-SKF and sC-SKF algorithms, and compare their positioning accuracy against other approximate map-based localization approaches that employ measurement-noise-covariance inflation to compensate for the map's uncertainty.