 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Deep Music Generation: Multi-level Representations, Algorithms, Evaluations, and Future Directions
Paper and Code
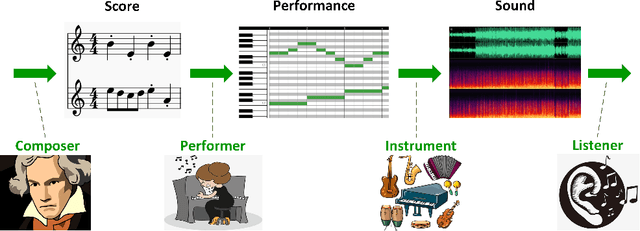
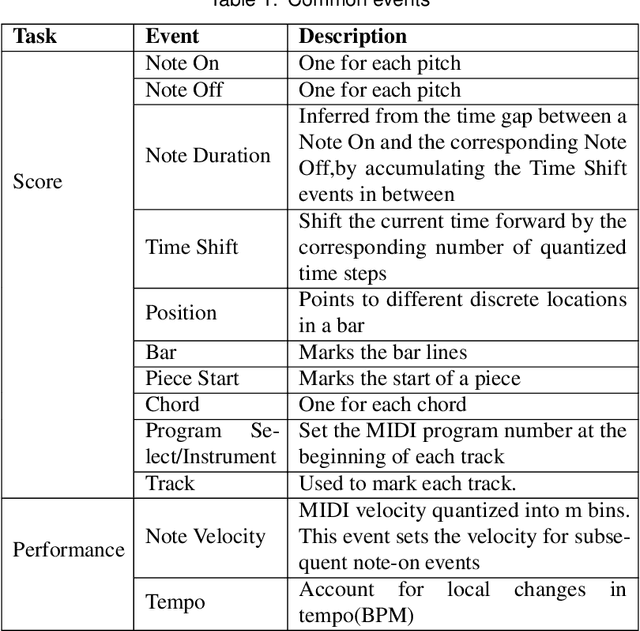
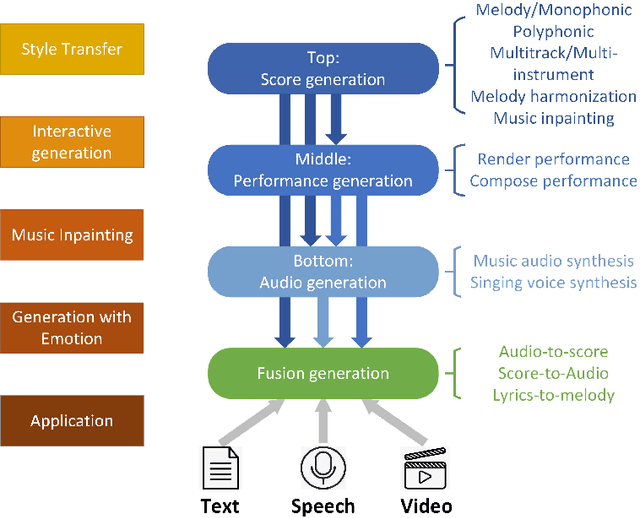

The utilization of deep learning techniques in generating various contents (such as image, text, etc.) has become a trend. Especially music, the topic of this paper, has attracted widespread attention of countless researchers.The whole process of producing music can be divided into three stages, corresponding to the three levels of music generation: score generation produces scores, performance generation adds performance characteristics to the scores, and audio generation converts scores with performance characteristics into audio by assigning timbre or generates music in audio format directly. Previous surveys have explored the network models employed in the field of automatic music generation. However, the development history, the model evolution, as well as the pros and cons of same music generation task have not been clearly illustrated. This paper attempts to provide an overview of various composition tasks under different music generation levels, covering most of the currently popular music generation tasks using deep learning. In addition, we summarize the datasets suitable for diverse tasks, discuss the music representations, the evaluation methods as well as the challenges under different levels, and finally point out several future directions.