 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image and Depth from a Single Defocused Image Using Coded Aperture Photography
Mar 13, 2016
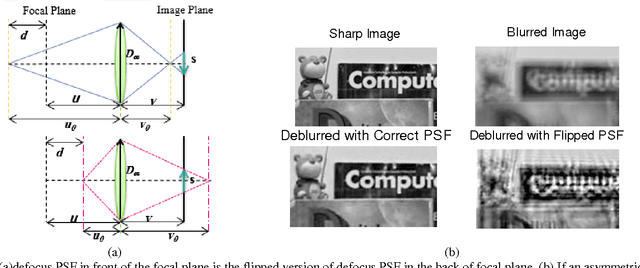
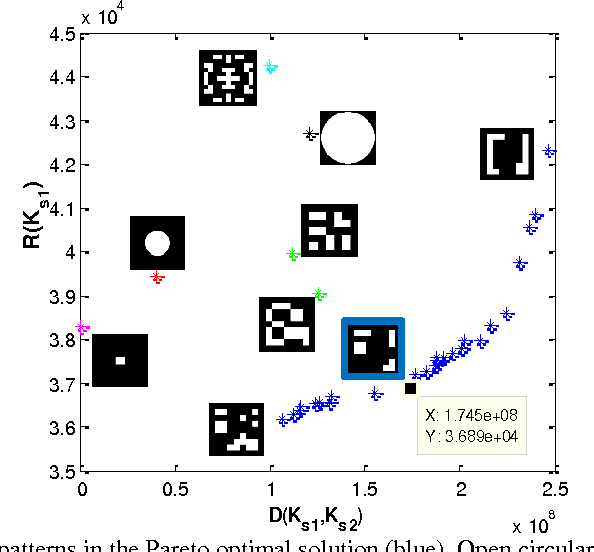
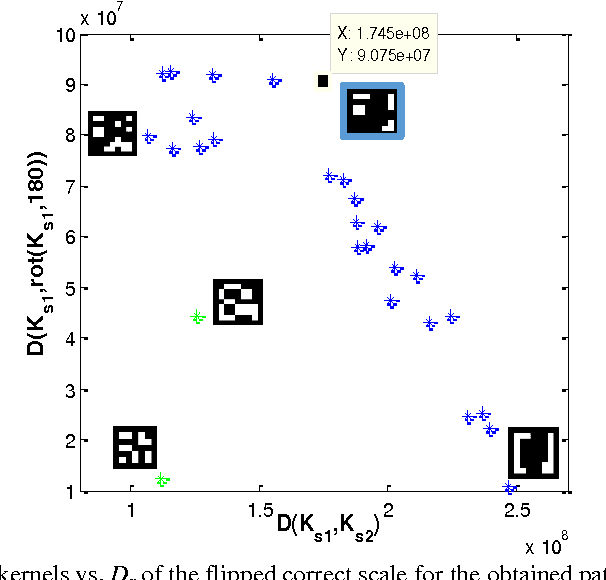
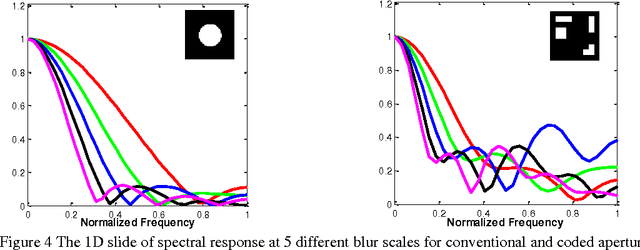
Depth from defocus and defocus deblurring from a single image are two challenging problems that are derived from the finite depth of field in conventional cameras. Coded aperture imaging is one of the techniques that is used for improving the results of these two problems. Up to now, different methods have been proposed for improving the results of either defocus deblurring or depth estimation. In this paper, a multi-objective function is proposed for evaluating and designing aperture patterns with the aim of improving the results of both depth from defocus and defocus deblurring. Pattern evaluation is performed by considering the scene illumination condition and camera system specification. Based on the proposed criteria, a single asymmetric pattern is designed that is used for restoring a sharp image and a depth map from a single input. Since the designed pattern is asymmetric, defocus objects on the two sides of the focal plane can be distinguished. Depth estimation is performed by using a new algorithm, which is based on image quality assessment criteria and can distinguish between blurred objects lying in front or behind the focal plane. Extensive simulations as well as experiments on a variety of real scenes are conducted to compare our aperture with previously proposed ones.
A Universal Deep Learning Framework for Real-Time Denoising of Ultrasound Images
Jan 22, 2021

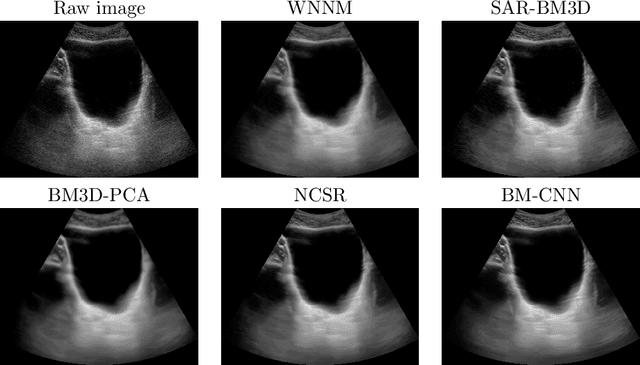
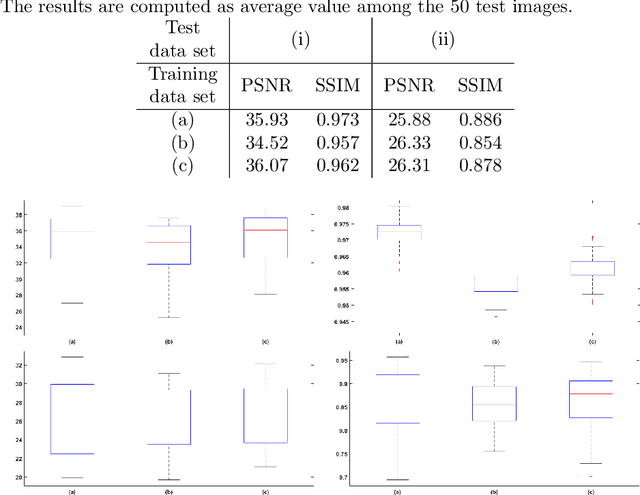
Ultrasound images are widespread in medical diagnosis for muscle-skeletal, cardiac, and obstetrical diseases, due to the efficiency and non-invasiveness of the acquisition methodology. However, ultrasound acquisition introduces a speckle noise in the signal, that corrupts the resulting image and affects further processing operations, and the visual analysis that medical experts conduct to estimate patient diseases. Our main goal is to define a universal deep learning framework for real-time denoising of ultrasound images. We analyse and compare state-of-the-art methods for the smoothing of ultrasound images (e.g., spectral, low-rank, and deep learning denoising algorithms), in order to select the best one in terms of accuracy, preservation of anatomical features, and computational cost. Then, we propose a tuned version of the selected state-of-the-art denoising methods (e.g., WNNM), to improve the quality of the denoised images, and extend its applicability to ultrasound images. To handle large data sets of ultrasound images with respect to applications and industrial requirements, we introduce a denoising framework that exploits deep learning and HPC tools, and allows us to replicate the results of state-of-the-art denoising methods in a real-time execution.
Multi-scale Grouped Dense Network for VVC Intra Coding
May 16, 2020
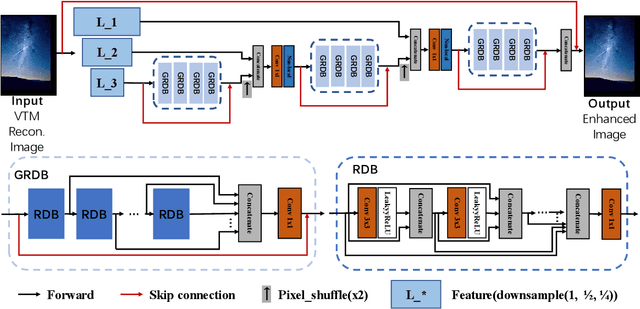
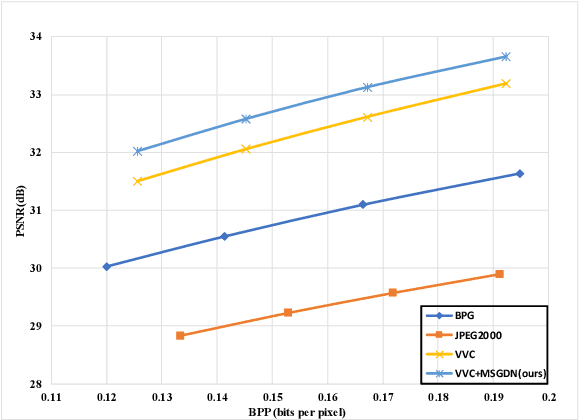

Versatile Video Coding (H.266/VVC) standard achieves better image quality when keeping the same bits than any other conventional image codec, such as BPG, JPEG, and etc. However, it is still attractive and challenging to improve the image quality with high compression ratio on the basis of traditional coding techniques. In this paper, we design the multi-scale grouped dense network (MSGDN) to further reduce the compression artifacts by combining the multi-scale and grouped dense block, which are integrated as the post-process network of VVC intra coding. Besides, to improve the subjective quality of compressed image, we also present a generative adversarial network (MSGDN-GAN) by utilizing our MSGDN as generator. Across the extensive experiments on validation set, our MSGDN trained by MSE losses yields the PSNR of 32.622 on average with teams IMC at the bit-rate of 0.15 in Lowrate track. Moreover, our MSGDN-GAN could achieve the better subjective performance.
Deep Models and Shortwave Infrared Information to Detect Face Presentation Attacks
Jul 22, 2020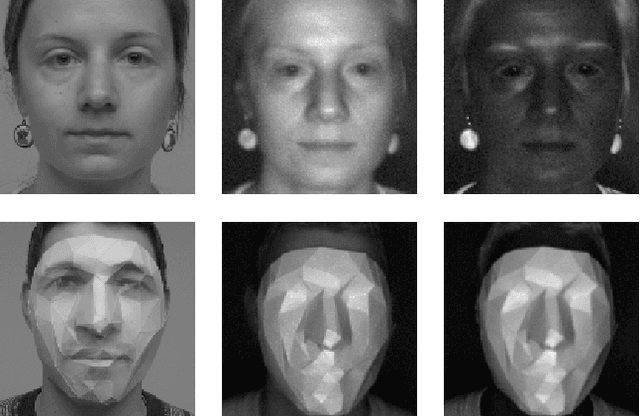
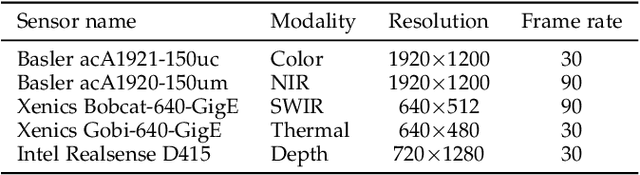
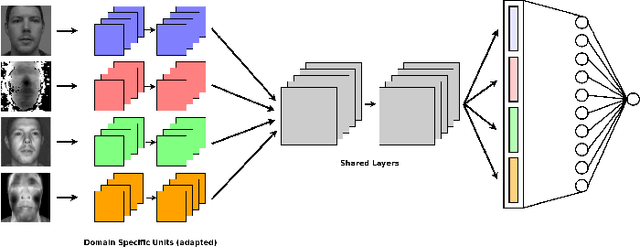
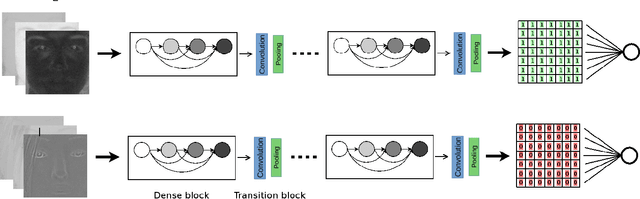
This paper addresses the problem of face presentation attack detection using different image modalities. In particular, the usage of short wave infrared (SWIR) imaging is considered. Face presentation attack detection is performed using recent models based on Convolutional Neural Networks using only carefully selected SWIR image differences as input. Conducted experiments show superior performance over similar models acting on either color images or on a combination of different modalities (visible, NIR, thermal and depth), as well as on a SVM-based classifier acting on SWIR image differences. Experiments have been carried on a new public and freely available database, containing a wide variety of attacks. Video sequences have been recorded thanks to several sensors resulting in 14 different streams in the visible, NIR, SWIR and thermal spectra, as well as depth data. The best proposed approach is able to almost perfectly detect all impersonation attacks while ensuring low bonafide classification errors. On the other hand, obtained results show that obfuscation attacks are more difficult to detect. We hope that the proposed database will foster research on this challenging problem. Finally, all the code and instructions to reproduce presented experiments is made available to the research community.
Full Reference Screen Content Image Quality Assessment by Fusing Multi-level Structure Similarity
Aug 07, 2020
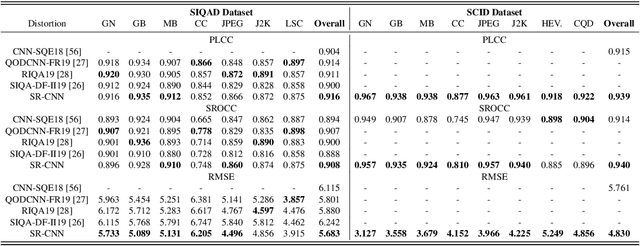
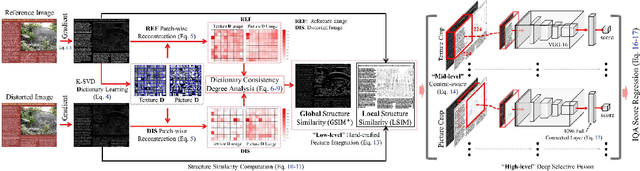
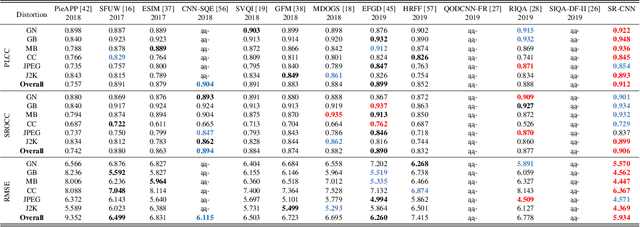
The screen content images (SCIs) usually comprise various content types with sharp edges, in which the artifacts or distortions can be well sensed by the vanilla structure similarity measurement in a full reference manner. Nonetheless, almost all of the current SOTA structure similarity metrics are "locally" formulated in a single-level manner, while the true human visual system (HVS) follows the multi-level manner, and such mismatch could eventually prevent these metrics from achieving trustworthy quality assessment. To ameliorate, this paper advocates a novel solution to measure structure similarity "globally" from the perspective of sparse representation. To perform multi-level quality assessment in accordance with the real HVS, the above-mentioned global metric will be integrated with the conventional local ones by resorting to the newly devised selective deep fusion network. To validate its efficacy and effectiveness, we have compared our method with 12 SOTA methods over two widely-used large-scale public SCI datasets, and the quantitative results indicate that our method yields significantly higher consistency with subjective quality score than the currently leading works. Both the source code and data are also publicly available to gain widespread acceptance and facilitate new advancement and its validation.
Advanced Deep Convolutional Neural Network Approaches for Digital Pathology Image Analysis: a comprehensive evaluation with different use cases
Apr 19, 2019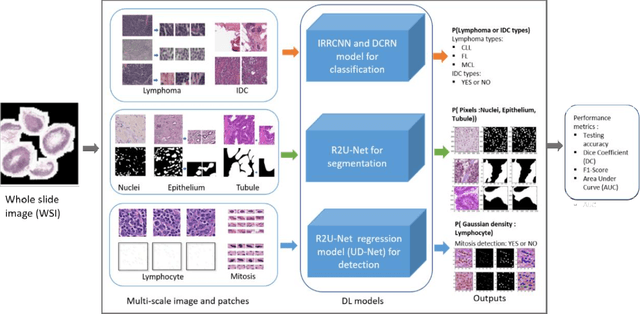

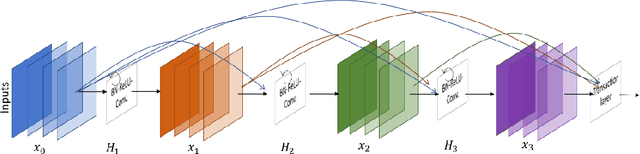

Deep Learning (DL) approaches have been providing state-of-the-art performance in different modalities in the field of medical imagining including Digital Pathology Image Analysis (DPIA). Out of many different DL approaches, Deep Convolutional Neural Network (DCNN) technique provides superior performance for classification, segmentation, and detection tasks. Most of the task in DPIA problems are somehow possible to solve with classification, segmentation, and detection approaches. In addition, sometimes pre and post-processing methods are applied for solving some specific type of problems. Recently, different DCNN models including Inception residual recurrent CNN (IRRCNN), Densely Connected Recurrent Convolution Network (DCRCN), Recurrent Residual U-Net (R2U-Net), and R2U-Net based regression model (UD-Net) have proposed and provide state-of-the-art performance for different computer vision and medical image analysis tasks. However, these advanced DCNN models have not been explored for solving different problems related to DPIA. In this study, we have applied these DCNN techniques for solving different DPIA problems and evaluated on different publicly available benchmark datasets for seven different tasks in digital pathology including lymphoma classification, Invasive Ductal Carcinoma (IDC) detection, nuclei segmentation, epithelium segmentation, tubule segmentation, lymphocyte detection, and mitosis detection. The experimental results are evaluated with different performance metrics such as sensitivity, specificity, accuracy, F1-score, Receiver Operating Characteristics (ROC) curve, dice coefficient (DC), and Means Squired Errors (MSE). The results demonstrate superior performance for classification, segmentation, and detection tasks compared to existing machine learning and DCNN based approaches.
Deep-learning coupled with novel classification method to classify the urban environment of the developing world
Nov 25, 2020
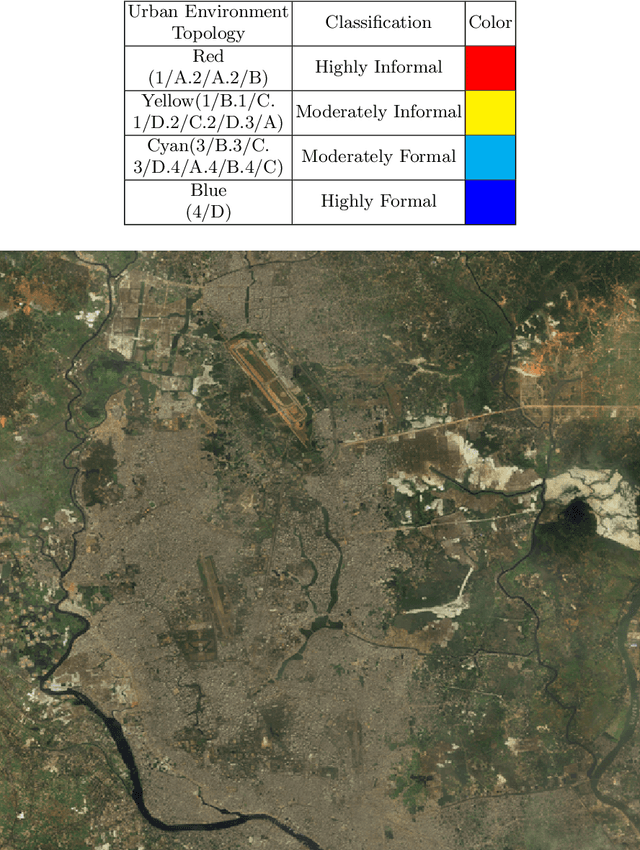
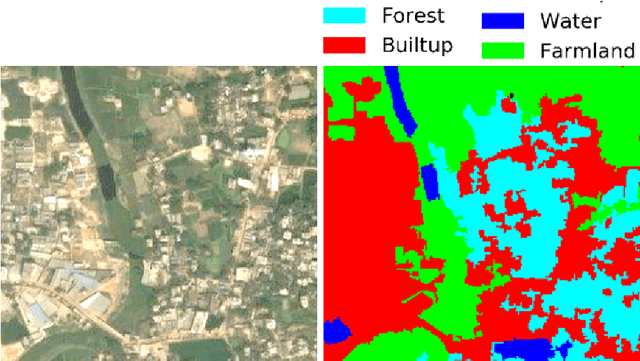
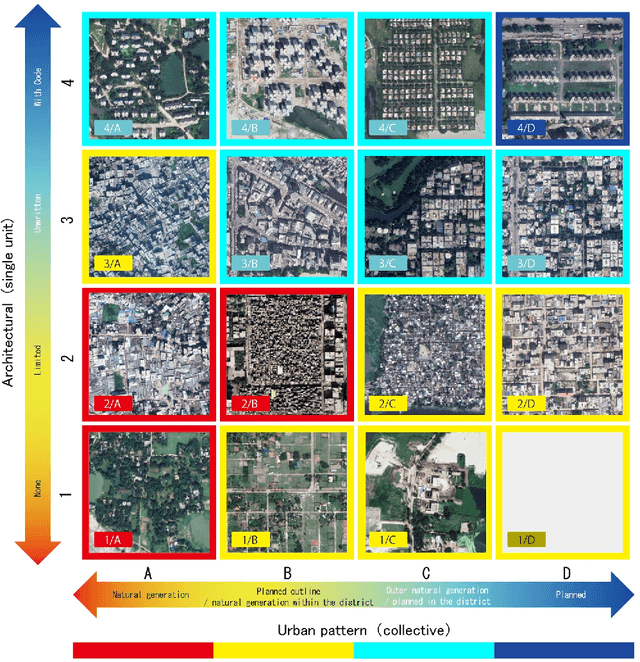
Rapid globalization and the interdependence of humanity that engender tremendous in-flow of human migration towards the urban spaces. With advent of high definition satellite images, high resolution data, computational methods such as deep neural network, capable hardware; urban planning is seeing a paradigm shift. Legacy data on urban environments are now being complemented with high-volume, high-frequency data. In this paper we propose a novel classification method that is readily usable for machine analysis and show applicability of the methodology on a developing world setting. The state-of-the-art is mostly dominated by classification of building structures, building types etc. and largely represents the developed world which are insufficient for developing countries such as Bangladesh where the surrounding is crucial for the classification. Moreover, the traditional methods propose small-scale classifications, which give limited information with poor scalability and are slow to compute. We categorize the urban area in terms of informal and formal spaces taking the surroundings into account. 50 km x 50 km Google Earth image of Dhaka, Bangladesh was visually annotated and categorized by an expert. The classification is based broadly on two dimensions: urbanization and the architectural form of urban environment. Consequently, the urban space is divided into four classes: 1) highly informal; 2) moderately informal; 3) moderately formal; and 4) highly formal areas. In total 16 sub-classes were identified. For semantic segmentation, Google's DeeplabV3+ model was used which increases the field of view of the filters to incorporate larger context. Image encompassing 70% of the urban space was used for training and the remaining 30% was used for testing and validation. The model is able to segment with 75% accuracy and 60% Mean IoU.
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
Apr 15, 2020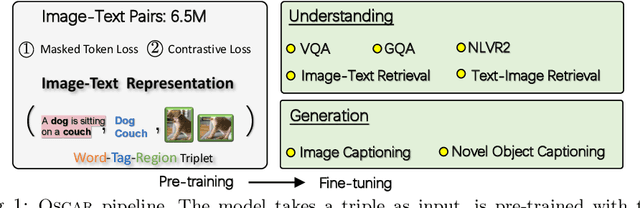

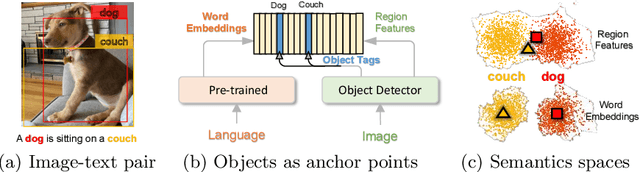
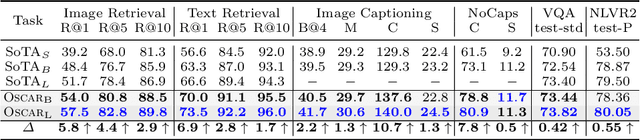
Large-scale pre-training methods of learning cross-modal representations on image-text pairs are becoming popular for vision-language tasks. While existing methods simply concatenate image region features and text features as input to the model to be pre-trained and use self-attention to learn image-text semantic alignments in a brute force manner, in this paper, we propose a new learning method Oscar (Object-Semantics Aligned Pre-training), which uses object tags detected in images as anchor points to significantly ease the learning of alignments. Our method is motivated by the observation that the salient objects in an image can be accurately detected, and are often mentioned in the paired text. We pre-train an Oscar model on the public corpus of 6.5 million text-image pairs, and fine-tune it on downstream tasks, creating new state-of-the-arts on six well-established vision-language understanding and generation tasks.
Scale-covariant and scale-invariant Gaussian derivative networks
Dec 18, 2020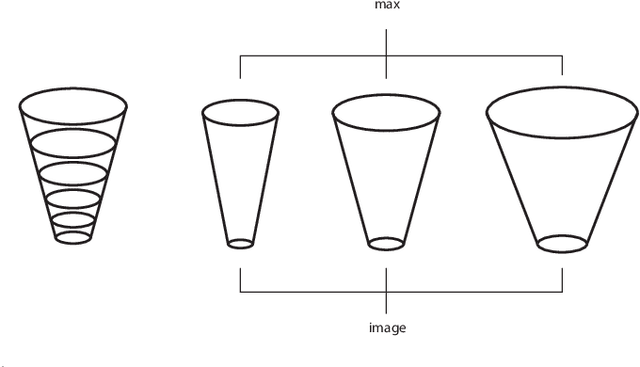

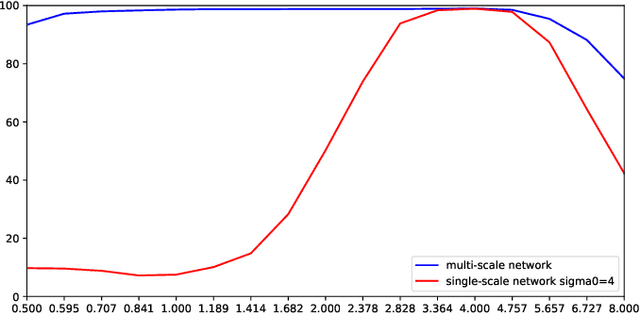
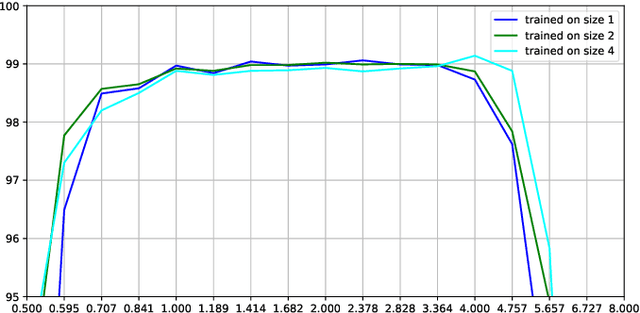
This paper presents a hybrid approach between scale-space theory and deep learning, where a deep learning architecture is constructed by coupling parameterized scale-space operations in cascade. By sharing the learnt parameters between multiple scale channels, and by using the transformation properties of the scale-space primitives under scaling transformations, the resulting network becomes provably scale covariant. By in addition performing max pooling over the multiple scale channels, a resulting network architecture for image classification also becomes provably scale invariant. We investigate the performance of such networks on the MNISTLargeScale dataset, which contains rescaled images from original MNIST over a factor 4 concerning training data and over a factor of 16 concerning testing data. It is demonstrated that the resulting approach allows for scale generalization, enabling good performance for classifying patterns at scales not present in the training data.
Deep High-Resolution Network for Low Dose X-ray CT Denoising
Feb 01, 2021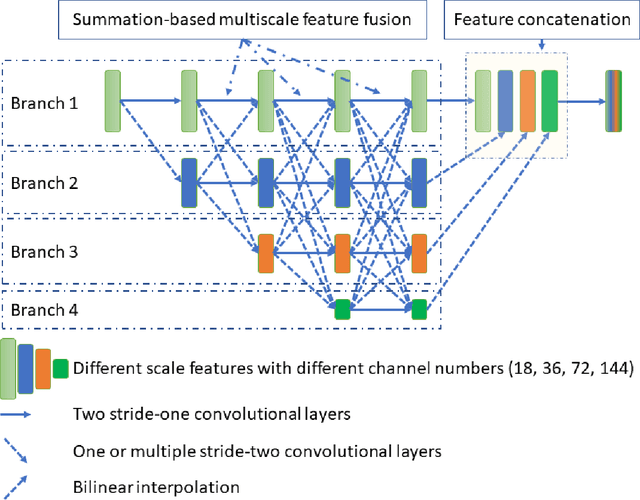
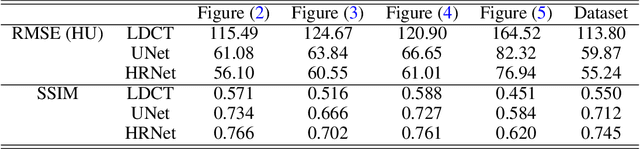
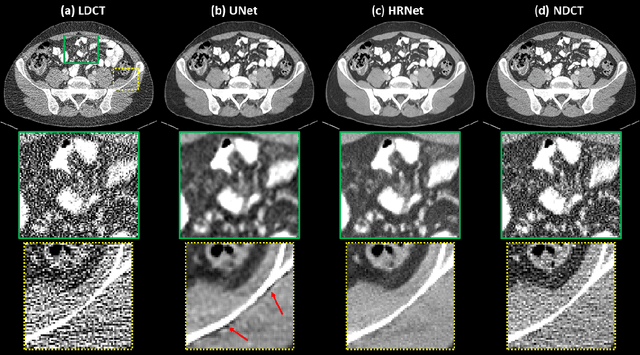
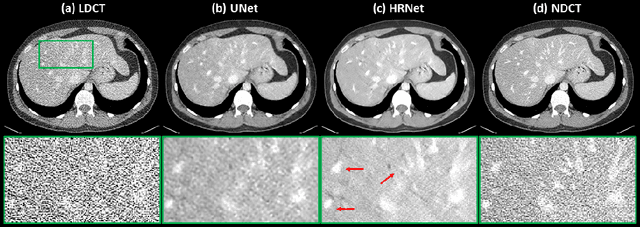
Low Dose Computed Tomography (LDCT) is clinically desirable due to the reduced radiation to patients. However, the quality of LDCT images is often sub-optimal because of the inevitable strong quantum noise. Inspired by their unprecedent success in computer vision, deep learning (DL)-based techniques have been used for LDCT denoising. Despite the promising noise removal ability of DL models, people have observed that the resolution of the DL-denoised images is compromised, decreasing their clinical value. Aiming at relieving this problem, in this work, we developed a more effective denoiser by introducing a high-resolution network (HRNet). Since HRNet consists of multiple branches of subnetworks to extract multiscale features which are later fused together, the quality of the generated features can be substantially enhanced, leading to improved denoising performance. Experimental results demonstrated that the introduced HRNet-based denoiser outperforms the benchmarked UNet-based denoiser in terms of superior image resolution preservation ability while comparable, if not better, noise suppression ability. Quantitative metrics in terms of root-mean-squared-errors (RMSE)/structure similarity index (SSIM) showed that the HRNet-based denoiser can improve the values from 113.80/0.550 (LDCT) to 55.24/0.745 (HRNet), in comparison to 59.87/0.712 for the UNet-based denoiser.