 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Convolution: A Taxonomy of Structured Operators for Learning-Based Image Processing
Mar 12, 2026The convolution operator is the fundamental building block of modern convolutional neural networks (CNNs), owing to its simplicity, translational equivariance, and efficient implementation. However, its structure as a fixed, linear, locally-averaging operator limits its ability to capture structured signal properties such as low-rank decompositions, adaptive basis representations, and non-uniform spatial dependencies. This paper presents a systematic taxonomy of operators that extend or replace the standard convolution in learning-based image processing pipelines. We organise the landscape of alternative operators into five families: (i) decomposition-based operators, which separate structural and noise components through singular value or tensor decompositions; (ii) adaptive weighted operators, which modulate kernel contributions as a function of spatial position or signal content; (iii) basis-adaptive operators, which optimise the analysis bases together with the network weights; (iv) integral and kernel operators, which generalise the convolution to position-dependent and non-linear kernels; and (v) attention-based operators, which relax the locality assumption entirely. For each family, we provide a formal definition, a discussion of its structural properties with respect to the convolution, and a critical analysis of the tasks for which the operator is most appropriate. We further provide a comparative analysis of all families across relevant dimensions -- linearity, locality, equivariance, computational cost, and suitability for image-to-image and image-to-label tasks -- and outline the open challenges and future directions of this research area.
Framework of a multiscale data-driven digital twin of the muscle-skeletal system
Jun 13, 2025Musculoskeletal disorders (MSDs) are a leading cause of disability worldwide, requiring advanced diagnostic and therapeutic tools for personalised assessment and treatment. Effective management of MSDs involves the interaction of heterogeneous data sources, making the Digital Twin (DT) paradigm a valuable option. This paper introduces the Musculoskeletal Digital Twin (MS-DT), a novel framework that integrates multiscale biomechanical data with computational modelling to create a detailed, patient-specific representation of the musculoskeletal system. By combining motion capture, ultrasound imaging, electromyography, and medical imaging, the MS-DT enables the analysis of spinal kinematics, posture, and muscle function. An interactive visualisation platform provides clinicians and researchers with an intuitive interface for exploring biomechanical parameters and tracking patient-specific changes. Results demonstrate the effectiveness of MS-DT in extracting precise kinematic and dynamic tissue features, offering a comprehensive tool for monitoring spine biomechanics and rehabilitation. This framework provides high-fidelity modelling and real-time visualization to improve patient-specific diagnosis and intervention planning.
Optimal Density Functions for Weighted Convolution in Learning Models
May 30, 2025The paper introduces the weighted convolution, a novel approach to the convolution for signals defined on regular grids (e.g., 2D images) through the application of an optimal density function to scale the contribution of neighbouring pixels based on their distance from the central pixel. This choice differs from the traditional uniform convolution, which treats all neighbouring pixels equally. Our weighted convolution can be applied to convolutional neural network problems to improve the approximation accuracy. Given a convolutional network, we define a framework to compute the optimal density function through a minimisation model. The framework separates the optimisation of the convolutional kernel weights (using stochastic gradient descent) from the optimisation of the density function (using DIRECT-L). Experimental results on a learning model for an image-to-image task (e.g., image denoising) show that the weighted convolution significantly reduces the loss (up to 53% improvement) and increases the test accuracy compared to standard convolution. While this method increases execution time by 11%, it is robust across several hyperparameters of the learning model. Future work will apply the weighted convolution to real-case 2D and 3D image convolutional learning problems.
Optimal Weighted Convolution for Classification and Denosing
May 30, 2025We introduce a novel weighted convolution operator that enhances traditional convolutional neural networks (CNNs) by integrating a spatial density function into the convolution operator. This extension enables the network to differentially weight neighbouring pixels based on their relative position to the reference pixel, improving spatial characterisation and feature extraction. The proposed operator maintains the same number of trainable parameters and is fully compatible with existing CNN architectures. Although developed for 2D image data, the framework is generalisable to signals on regular grids of arbitrary dimensions, such as 3D volumetric data or 1D time series. We propose an efficient implementation of the weighted convolution by pre-computing the density function and achieving execution times comparable to standard convolution layers. We evaluate our method on two deep learning tasks: image classification using the CIFAR-100 dataset [KH+09] and image denoising using the DIV2K dataset [AT17]. Experimental results with state-of-the-art classification (e.g., VGG [SZ15], ResNet [HZRS16]) and denoising (e.g., DnCNN [ZZC+17], NAFNet [CCZS22]) methods show that the weighted convolution improves performance with respect to standard convolution across different quantitative metrics. For example, VGG achieves an accuracy of 66.94% with weighted convolution versus 56.89% with standard convolution on the classification problem, while DnCNN improves the PSNR value from 20.17 to 22.63 on the denoising problem. All models were trained on the CINECA Leonardo cluster to reduce the execution time and improve the tuning of the density function values. The PyTorch implementation of the weighted convolution is publicly available at: https://github.com/cammarasana123/weightedConvolution2.0.
Learning-Based and Quality Preserving Super-Resolution of Noisy Images
Nov 03, 2023



Several applications require the super-resolution of noisy images and the preservation of geometrical and texture features. State-of-the-art super-resolution methods do not account for noise and generally enhance the output image's artefacts (e.g., aliasing, blurring). We propose a learning-based method that accounts for the presence of noise and preserves the properties of the input image, as measured by quantitative metrics (e.g., normalised crossed correlation, normalised mean squared error, peak-signal-to-noise-ration, structural similarity feature-based similarity, universal image quality). We train our network to up-sample a low-resolution noisy image while preserving its properties. We perform our tests on the Cineca Marconi100 cluster, at the 26th position in the top500 list. The experimental results show that our method outperforms learning-based methods, has comparable results with standard methods, preserves the properties of the input image as contours, brightness, and textures, and reduces the artefacts. As average quantitative metrics, our method has a PSNR value of 23.81 on the super-resolution of Gaussian noise images with a 2X up-sampling factor. In contrast, previous work has a PSNR value of 23.09 (standard method) and 21.78 (learning-based method). Our learning-based and quality-preserving super-resolution improves the high-resolution prediction of noisy images with respect to state-of-the-art methods with different noise types and up-sampling factors.
HPC-based Solvers of Minimisation Problems for Signal Processing
Nov 03, 2023



Several physics and engineering applications involve the solution of a minimisation problem to compute an approximation of the input signal. Modern computing hardware and software apply high-performance computing to solve and considerably reduce the execution time. We compare and analyse different minimisation methods in terms of functional computation, convergence, execution time, and scalability properties, for the solution of two minimisation problems (i.e., approximation and denoising) with different constraints that involve computationally expensive operations. These problems are attractive due to their numerical and analytical properties, and our general analysis can be extended to most signal-processing problems. We perform our tests on the Cineca Marconi100 cluster, at the 26th position in the top500 list. Our experimental results show that PRAXIS is the best optimiser in terms of minima computation: the efficiency of the approximation is 38% with 256 processes, while the denoising has 46% with 32 processes.
Learning-based Framework for US Signals Super-resolution
Apr 17, 2023



We propose a novel deep-learning framework for super-resolution ultrasound images and videos in terms of spatial resolution and line reconstruction. We up-sample the acquired low-resolution image through a vision-based interpolation method; then, we train a learning-based model to improve the quality of the up-sampling. We qualitatively and quantitatively test our model on different anatomical districts (e.g., cardiac, obstetric) images and with different up-sampling resolutions (i.e., 2X, 4X). Our method improves the PSNR median value with respect to SOTA methods of $1.7\%$ on obstetric 2X raw images, $6.1\%$ on cardiac 2X raw images, and $4.4\%$ on abdominal raw 4X images; it also improves the number of pixels with a low prediction error of $9.0\%$ on obstetric 4X raw images, $5.2\%$ on cardiac 4X raw images, and $6.2\%$ on abdominal 4X raw images. The proposed method is then applied to the spatial super-resolution of 2D videos, by optimising the sampling of lines acquired by the probe in terms of the acquisition frequency. Our method specialises trained networks to predict the high-resolution target through the design of the network architecture and the loss function, taking into account the anatomical district and the up-sampling factor and exploiting a large ultrasound data set. The use of deep learning on large data sets overcomes the limitations of vision-based algorithms that are general and do not encode the characteristics of the data. Furthermore, the data set can be enriched with images selected by medical experts to further specialise the individual networks. Through learning and high-performance computing, our super-resolution is specialised to different anatomical districts by training multiple networks. Furthermore, the computational demand is shifted to centralised hardware resources with a real-time execution of the network's prediction on local devices.
A Universal Deep Learning Framework for Real-Time Denoising of Ultrasound Images
Jan 22, 2021

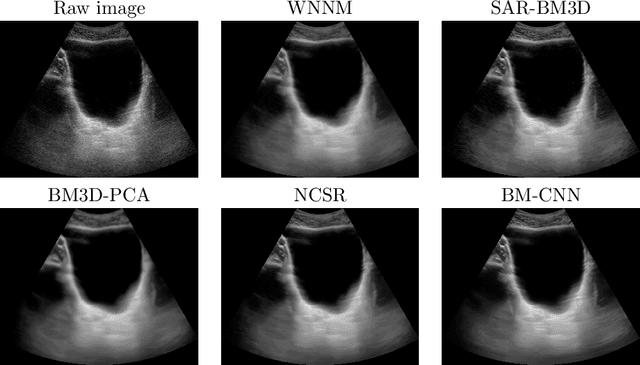
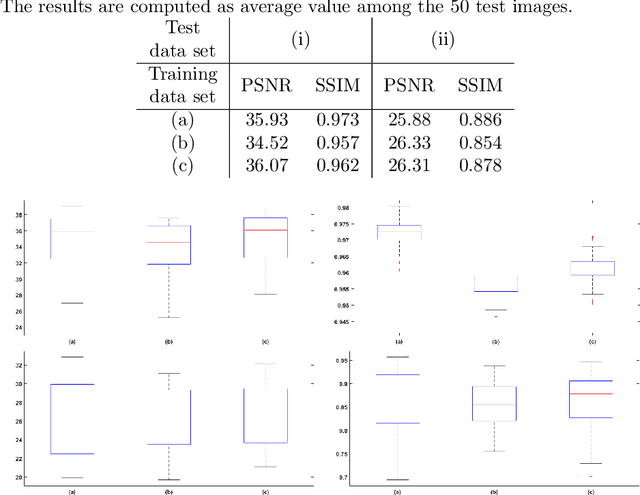
Ultrasound images are widespread in medical diagnosis for muscle-skeletal, cardiac, and obstetrical diseases, due to the efficiency and non-invasiveness of the acquisition methodology. However, ultrasound acquisition introduces a speckle noise in the signal, that corrupts the resulting image and affects further processing operations, and the visual analysis that medical experts conduct to estimate patient diseases. Our main goal is to define a universal deep learning framework for real-time denoising of ultrasound images. We analyse and compare state-of-the-art methods for the smoothing of ultrasound images (e.g., spectral, low-rank, and deep learning denoising algorithms), in order to select the best one in terms of accuracy, preservation of anatomical features, and computational cost. Then, we propose a tuned version of the selected state-of-the-art denoising methods (e.g., WNNM), to improve the quality of the denoised images, and extend its applicability to ultrasound images. To handle large data sets of ultrasound images with respect to applications and industrial requirements, we introduce a denoising framework that exploits deep learning and HPC tools, and allows us to replicate the results of state-of-the-art denoising methods in a real-time execution.