 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive Label Smoothing
Sep 14, 2020

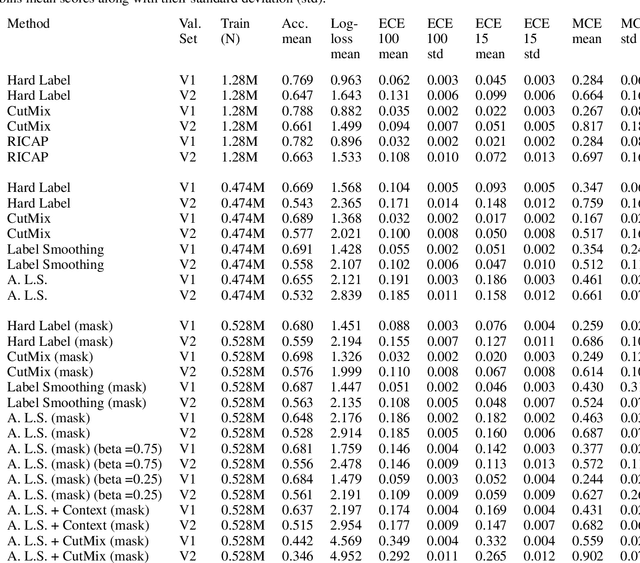
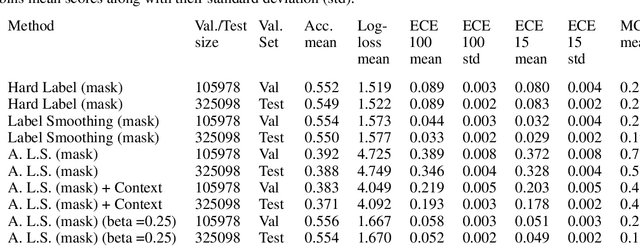
This paper concerns the use of objectness measures to improve the calibration performance of Convolutional Neural Networks (CNNs). Objectness is a measure of likelihood of an object from any class being present in a given image. CNNs have proven to be very good classifiers and generally localize objects well; however, the loss functions typically used to train classification CNNs do not penalize inability to localize an object, nor do they take into account an object's relative size in the given image. We present a novel approach to object localization that combines the ideas of objectness and label smoothing during training. Unlike previous methods, we compute a smoothing factor that is adaptive based on relative object size within an image. We present extensive results using ImageNet and OpenImages to demonstrate that CNNs trained using adaptive label smoothing are much less likely to be overconfident in their predictions, as compared to CNNs trained using hard targets. We also show qualitative results using class activation maps to illustrate the improvements.
LEED: Label-Free Expression Editing via Disentanglement
Jul 17, 2020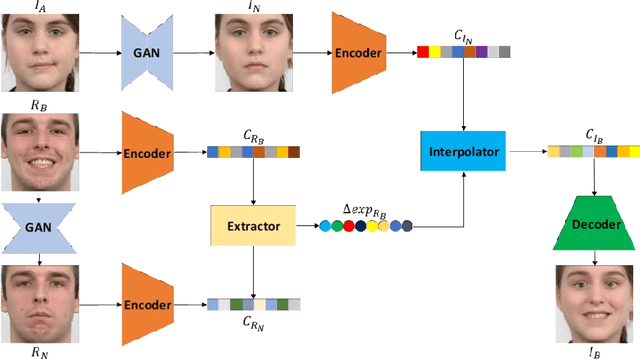

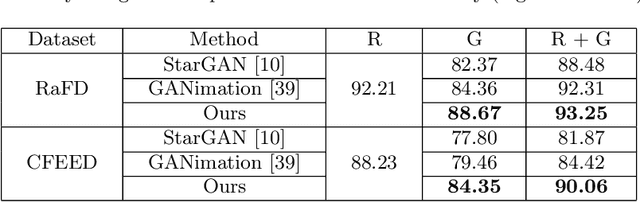

Recent studies on facial expression editing have obtained very promising progress. On the other hand, existing methods face the constraint of requiring a large amount of expression labels which are often expensive and time-consuming to collect. This paper presents an innovative label-free expression editing via disentanglement (LEED) framework that is capable of editing the expression of both frontal and profile facial images without requiring any expression label. The idea is to disentangle the identity and expression of a facial image in the expression manifold, where the neutral face captures the identity attribute and the displacement between the neutral image and the expressive image captures the expression attribute. Two novel losses are designed for optimal expression disentanglement and consistent synthesis, including a mutual expression information loss that aims to extract pure expression-related features and a siamese loss that aims to enhance the expression similarity between the synthesized image and the reference image. Extensive experiments over two public facial expression datasets show that LEED achieves superior facial expression editing qualitatively and quantitatively.
Improving the generalization of network based relative pose regression: dimension reduction as a regularizer
Oct 24, 2020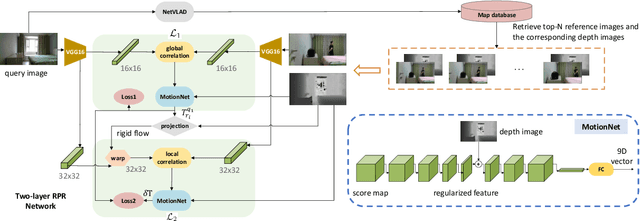
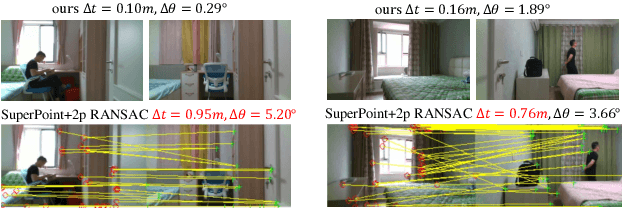
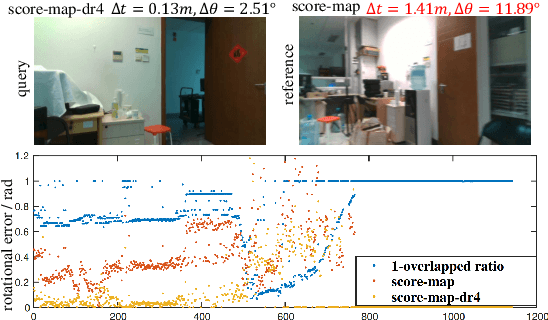
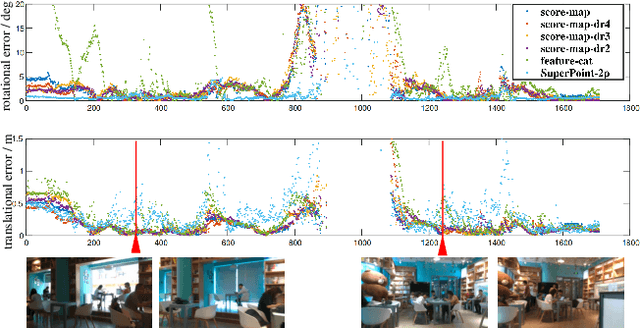
Visual localization occupies an important position in many areas such as Augmented Reality, robotics and 3D reconstruction. The state-of-the-art visual localization methods perform pose estimation using geometry based solver within the RANSAC framework. However, these methods require accurate pixel-level matching at high image resolution, which is hard to satisfy under significant changes from appearance, dynamics or perspective of view. End-to-end learning based regression networks provide a solution to circumvent the requirement for precise pixel-level correspondences, but demonstrate poor performance towards cross-scene generalization. In this paper, we explicitly add a learnable matching layer within the network to isolate the pose regression solver from the absolute image feature values, and apply dimension regularization on both the correlation feature channel and the image scale to further improve performance towards generalization and large viewpoint change. We implement this dimension regularization strategy within a two-layer pyramid based framework to regress the localization results from coarse to fine. In addition, the depth information is fused for absolute translational scale recovery. Through experiments on real world RGBD datasets we validate the effectiveness of our design in terms of improving both generalization performance and robustness towards viewpoint change, and also show the potential of regression based visual localization networks towards challenging occasions that are difficult for geometry based visual localization methods.
Dual Attention-in-Attention Model for Joint Rain Streak and Raindrop Removal
Mar 12, 2021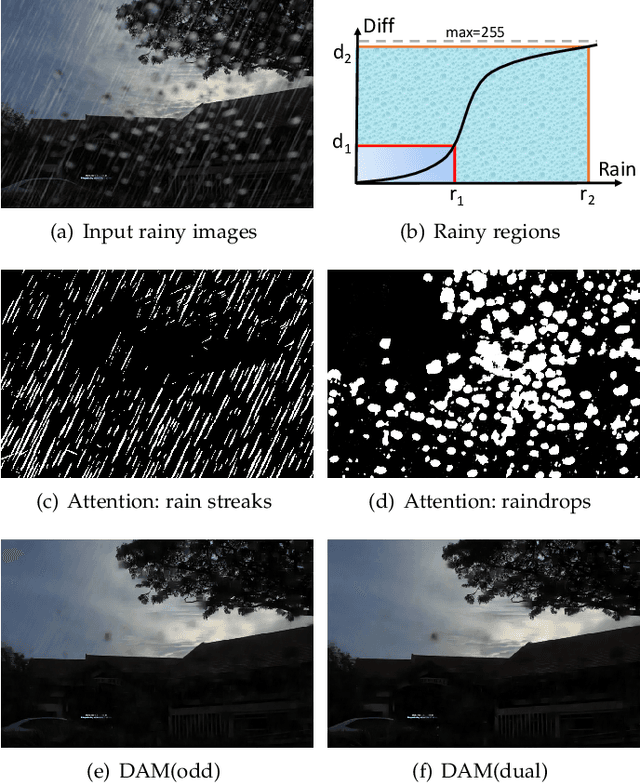
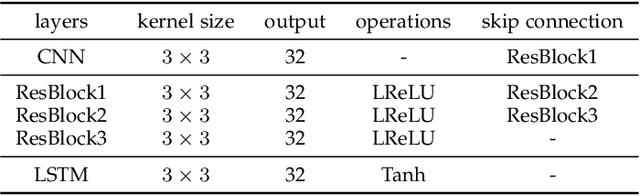
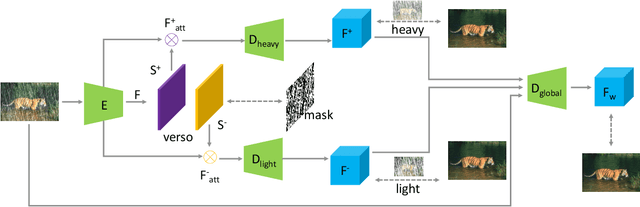
Rain streaks and rain drops are two natural phenomena, which degrade image capture in different ways. Currently, most existing deep deraining networks take them as two distinct problems and individually address one, and thus cannot deal adequately with both simultaneously. To address this, we propose a Dual Attention-in-Attention Model (DAiAM) which includes two DAMs for removing both rain streaks and raindrops. Inside the DAM, there are two attentive maps - each of which attends to the heavy and light rainy regions, respectively, to guide the deraining process differently for applicable regions. In addition, to further refine the result, a Differential-driven Dual Attention-in-Attention Model (D-DAiAM) is proposed with a "heavy-to-light" scheme to remove rain via addressing the unsatisfying deraining regions. Extensive experiments on one public raindrop dataset, one public rain streak and our synthesized joint rain streak and raindrop (JRSRD) dataset have demonstrated that the proposed method not only is capable of removing rain streaks and raindrops simultaneously, but also achieves the state-of-the-art performance on both tasks.
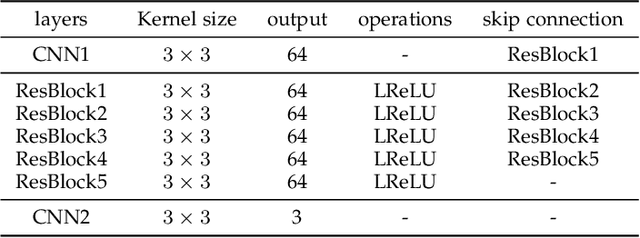
Variational Autoencoders with a Structural Similarity Loss in Time of Flight MRAs
Jan 20, 2021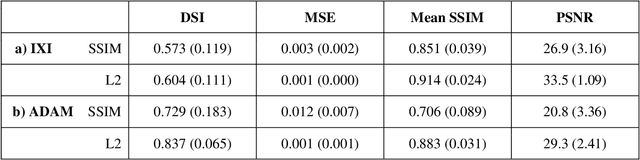
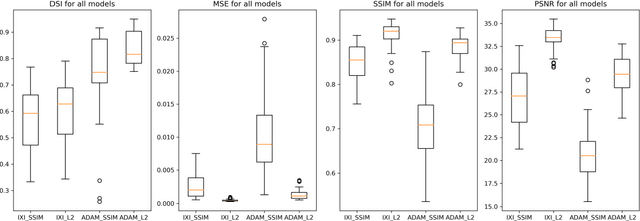
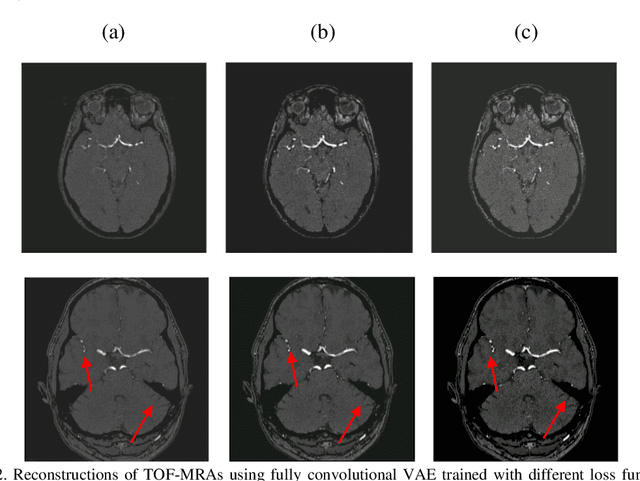
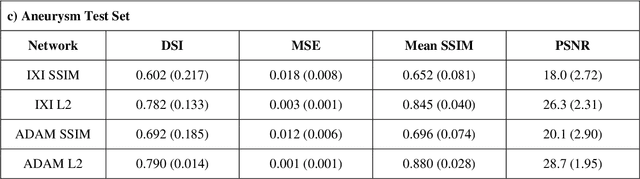
Time-of-Flight Magnetic Resonance Angiographs (TOF-MRAs) enable visualization and analysis of cerebral arteries. This analysis may indicate normal variation of the configuration of the cerebrovascular system or vessel abnormalities, such as aneurysms. A model would be useful to represent normal cerebrovascular structure and variabilities in a healthy population and to differentiate from abnormalities. Current anomaly detection using autoencoding convolutional neural networks usually use a voxelwise mean-error for optimization. We propose optimizing a variational-autoencoder (VAE) with structural similarity loss (SSIM) for TOF-MRA reconstruction. A patch-trained 2D fully-convolutional VAE was optimized for TOF-MRA reconstruction by comparing vessel segmentations of original and reconstructed MRAs. The method was trained and tested on two datasets: the IXI dataset, and a subset from the ADAM challenge. Both trained networks were tested on a dataset including subjects with aneurysms. We compared VAE optimization with L2-loss and SSIM-loss. Performance was evaluated between original and reconstructed MRAs using mean square error, mean-SSIM, peak-signal-to-noise-ratio and dice similarity index (DSI) of segmented vessels. The L2-optimized VAE outperforms SSIM, with improved reconstruction metrics and DSIs for both datasets. Optimization using SSIM performed best for visual image quality, but with discrepancy in quantitative reconstruction and vascular segmentation. The larger, more diverse IXI dataset had overall better performance. Reconstruction metrics, including SSIM, were lower for MRAs including aneurysms. A SSIM-optimized VAE improved the visual perceptive image quality of TOF-MRA reconstructions. A L2-optimized VAE performed best for TOF-MRA reconstruction, where the vascular segmentation is important. SSIM is a potential metric for anomaly detection of MRAs.
Enhancing Label-Driven Deep Deformable Image Registration with Local Distance Metrics for State-of-the-Art Cardiac Motion Tracking
Dec 05, 2018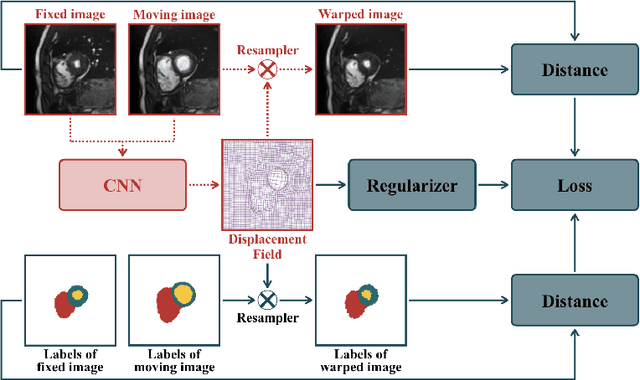
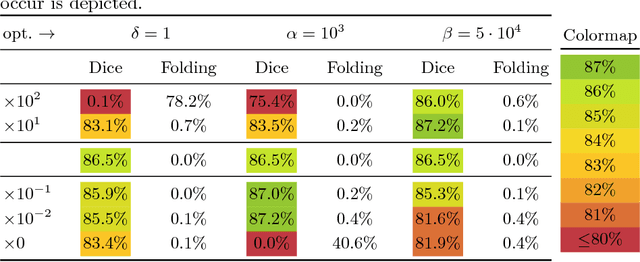
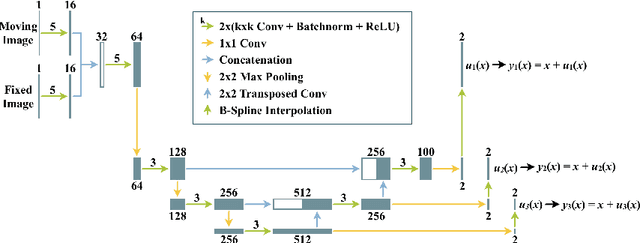
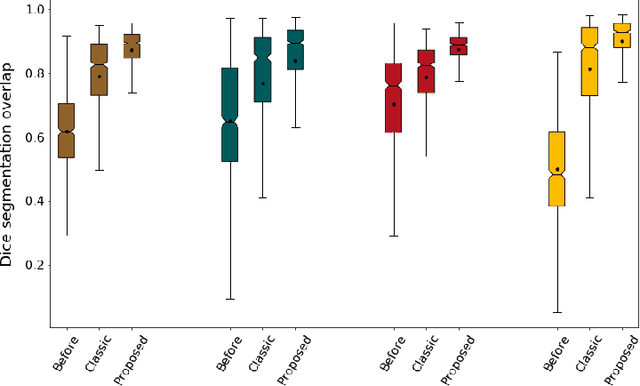
While deep learning has achieved significant advances in accuracy for medical image segmentation, its benefits for deformable image registration have so far remained limited to reduced computation times. Previous work has either focused on replacing the iterative optimization of distance and smoothness terms with CNN-layers or using supervised approaches driven by labels. Our method is the first to combine the complementary strengths of global semantic information (represented by segmentation labels) and local distance metrics that help align surrounding structures. We demonstrate significant higher Dice scores (of 86.5\%) for deformable cardiac image registration compared to classic registration (79.0\%) as well as label-driven deep learning frameworks (83.4\%).
Active Boundary Loss for Semantic Segmentation
Feb 04, 2021
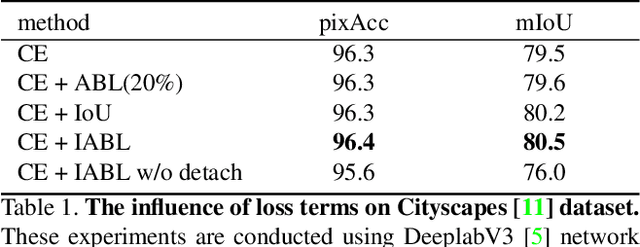

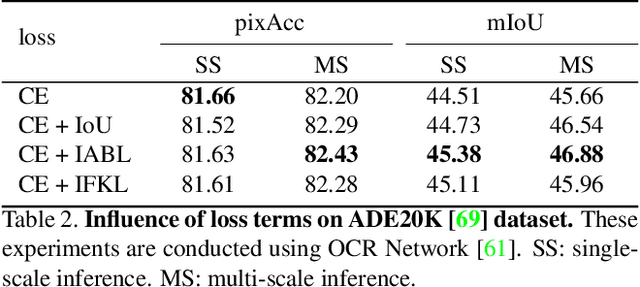
This paper proposes a novel active boundary loss for semantic segmentation. It can progressively encourage the alignment between predicted boundaries and ground-truth boundaries during end-to-end training, which is not explicitly enforced in commonly used cross-entropy loss. Based on the predicted boundaries detected from the segmentation results using current network parameters, we formulate the boundary alignment problem as a differentiable direction vector prediction problem to guide the movement of predicted boundaries in each iteration. Our loss is model-agnostic and can be plugged into the training of segmentation networks to improve the boundary details. Experimental results show that training with the active boundary loss can effectively improve the boundary F-score and mean Intersection-over-Union on challenging image and video object segmentation datasets.
A Novel Neuron Model of Visual Processor
Apr 15, 2021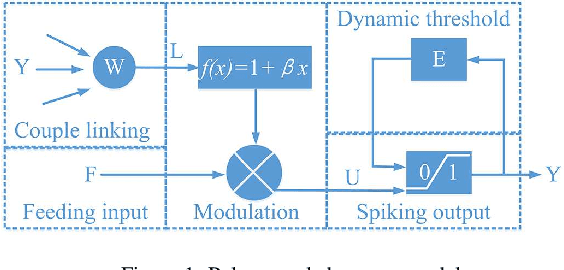
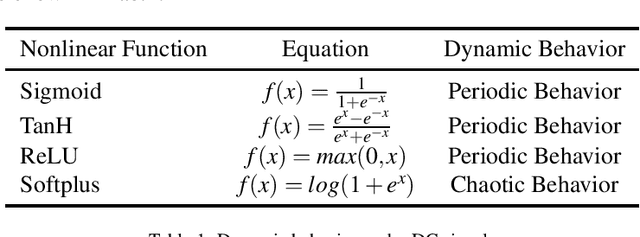
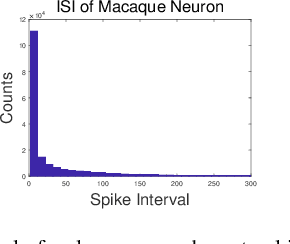
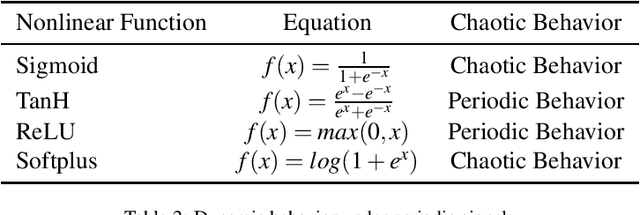
Simulating and imitating the neuronal network of humans or mammals is a popular topic that has been explored for many years in the fields of pattern recognition and computer vision. Inspired by neuronal conduction characteristics in the primary visual cortex of cats, pulse-coupled neural networks (PCNNs) can exhibit synchronous oscillation behavior, which can process digital images without training. However, according to the study of single cells in the cat primary visual cortex, when a neuron is stimulated by an external periodic signal, the interspike-interval (ISI) distributions represent a multimodal distribution. This phenomenon cannot be explained by all PCNN models. By analyzing the working mechanism of the PCNN, we present a novel neuron model of the primary visual cortex consisting of a continuous-coupled neural network (CCNN). Our model inherited the threshold exponential decay and synchronous pulse oscillation property of the original PCNN model, and it can exhibit chaotic behavior consistent with the testing results of cat primary visual cortex neurons. Therefore, our CCNN model is closer to real visual neural networks. For image segmentation tasks, the algorithm based on CCNN model has better performance than the state-of-art of visual cortex neural network model. The strength of our approach is that it helps neurophysiologists further understand how the primary visual cortex works and can be used to quantitatively predict the temporal-spatial behavior of real neural networks. CCNN may also inspire engineers to create brain-inspired deep learning networks for artificial intelligence purposes.
Whole-Slide Image Focus Quality: Automatic Assessment and Impact on AI Cancer Detection
Jan 15, 2019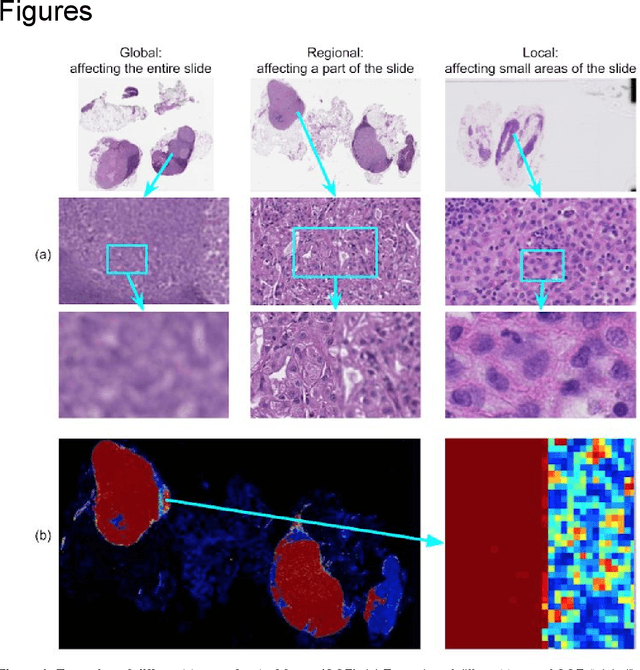
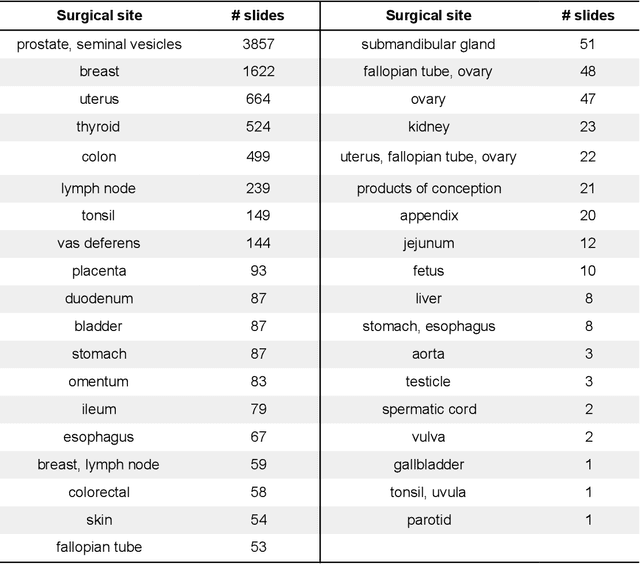
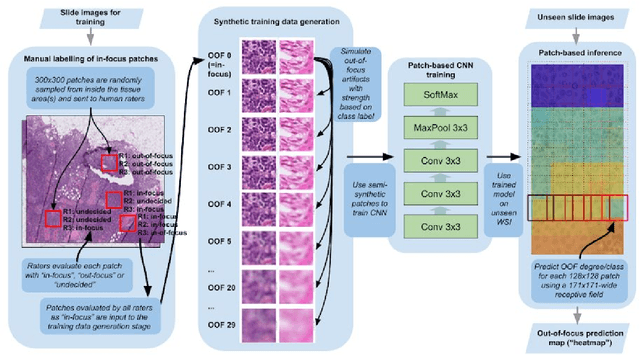
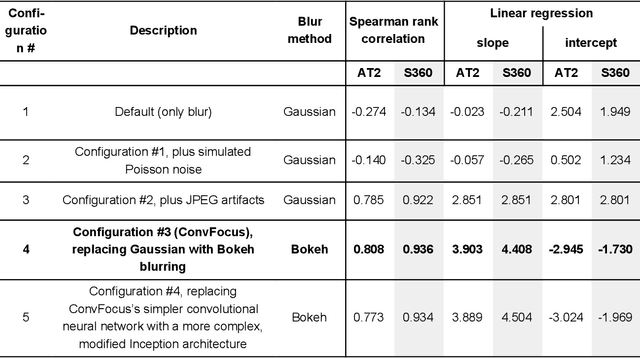
Digital pathology enables remote access or consults and powerful image analysis algorithms. However, the slide digitization process can create artifacts such as out-of-focus (OOF). OOF is often only detected upon careful review, potentially causing rescanning and workflow delays. Although scan-time operator screening for whole-slide OOF is feasible, manual screening for OOF affecting only parts of a slide is impractical. We developed a convolutional neural network (ConvFocus) to exhaustively localize and quantify the severity of OOF regions on digitized slides. ConvFocus was developed using our refined semi-synthetic OOF data generation process, and evaluated using real whole-slide images spanning 3 different tissue types and 3 different stain types that were digitized by two different scanners. ConvFocus's predictions were compared with pathologist-annotated focus quality grades across 514 distinct regions representing 37,700 35x35{\mu}m image patches, and 21 digitized "z-stack" whole-slide images that contain known OOF patterns. When compared to pathologist-graded focus quality, ConvFocus achieved Spearman rank coefficients of 0.81 and 0.94 on two scanners, and reproduced the expected OOF patterns from z-stack scanning. We also evaluated the impact of OOF on the accuracy of a state-of-the-art metastatic breast cancer detector and saw a consistent decrease in performance with increasing OOF. Comprehensive whole-slide OOF categorization could enable rescans prior to pathologist review, potentially reducing the impact of digitization focus issues on the clinical workflow. We show that the algorithm trained on our semi-synthetic OOF data generalizes well to real OOF regions across tissue types, stains, and scanners. Finally, quantitative OOF maps can flag regions that might otherwise be misclassified by image analysis algorithms, preventing OOF-induced errors.
AutoDO: Robust AutoAugment for Biased Data with Label Noise via Scalable Probabilistic Implicit Differentiation
Mar 11, 2021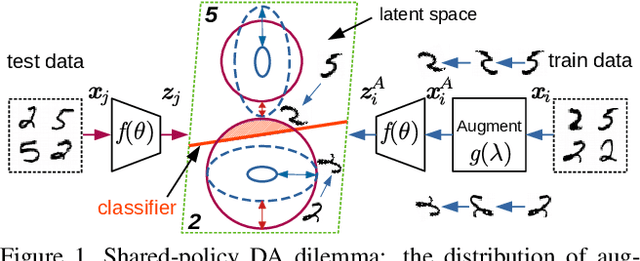
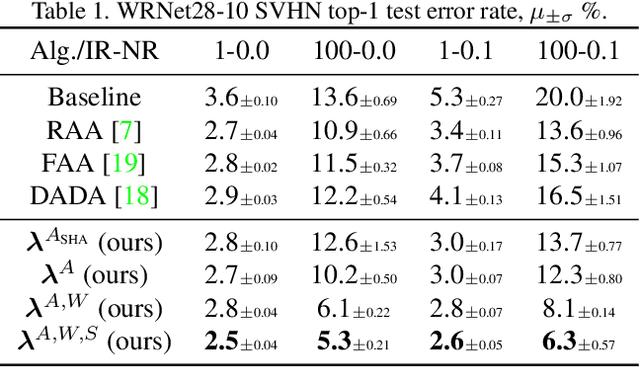

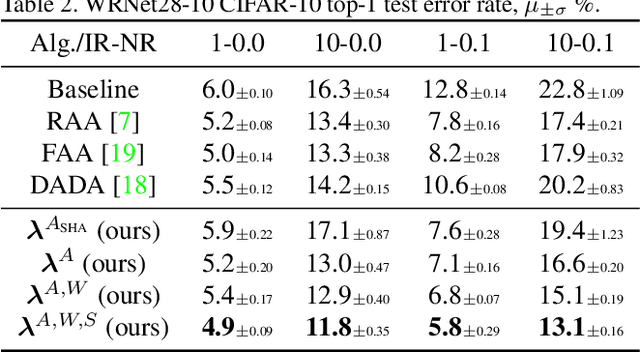
AutoAugment has sparked an interest in automated augmentation methods for deep learning models. These methods estimate image transformation policies for train data that improve generalization to test data. While recent papers evolved in the direction of decreasing policy search complexity, we show that those methods are not robust when applied to biased and noisy data. To overcome these limitations, we reformulate AutoAugment as a generalized automated dataset optimization (AutoDO) task that minimizes the distribution shift between test data and distorted train dataset. In our AutoDO model, we explicitly estimate a set of per-point hyperparameters to flexibly change distribution of train data. In particular, we include hyperparameters for augmentation, loss weights, and soft-labels that are jointly estimated using implicit differentiation. We develop a theoretical probabilistic interpretation of this framework using Fisher information and show that its complexity scales linearly with the dataset size. Our experiments on SVHN, CIFAR-10/100, and ImageNet classification show up to 9.3% improvement for biased datasets with label noise compared to prior methods and, importantly, up to 36.6% gain for underrepresented SVHN classes.