 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity Scaling Laws for Neural Models using Combinatorial Optimization
Jun 15, 2025Recent work on neural scaling laws demonstrates that model performance scales predictably with compute budget, model size, and dataset size. In this work, we develop scaling laws based on problem complexity. We analyze two fundamental complexity measures: solution space size and representation space size. Using the Traveling Salesman Problem (TSP) as a case study, we show that combinatorial optimization promotes smooth cost trends, and therefore meaningful scaling laws can be obtained even in the absence of an interpretable loss. We then show that suboptimality grows predictably for fixed-size models when scaling the number of TSP nodes or spatial dimensions, independent of whether the model was trained with reinforcement learning or supervised fine-tuning on a static dataset. We conclude with an analogy to problem complexity scaling in local search, showing that a much simpler gradient descent of the cost landscape produces similar trends.
Noise-Driven AI Sensors: Secure Healthcare Monitoring with PUFs
Jun 05, 2025



Wearable and implantable healthcare sensors are pivotal for real-time patient monitoring but face critical challenges in power efficiency, data security, and signal noise. This paper introduces a novel platform that leverages hardware noise as a dual-purpose resource to enhance machine learning (ML) robustness and secure data via Physical Unclonable Functions (PUFs). By integrating noise-driven signal processing, PUFbased authentication, and ML-based anomaly detection, our system achieves secure, low-power monitoring for devices like ECG wearables. Simulations demonstrate that noise improves ML accuracy by 8% (92% for detecting premature ventricular contractions (PVCs) and atrial fibrillation (AF)), while PUFs provide 98% uniqueness for tamper-resistant security, all within a 50 uW power budget. This unified approach not only addresses power, security, and noise challenges but also enables scalable, intelligent sensing for telemedicine and IoT applications.
Re-evaluation of Face Anti-spoofing Algorithm in Post COVID-19 Era Using Mask Based Occlusion Attack
Aug 23, 2024



Face anti-spoofing algorithms play a pivotal role in the robust deployment of face recognition systems against presentation attacks. Conventionally, full facial images are required by such systems to correctly authenticate individuals, but the widespread requirement of masks due to the current COVID-19 pandemic has introduced new challenges for these biometric authentication systems. Hence, in this work, we investigate the performance of presentation attack detection (PAD) algorithms under synthetic facial occlusions using masks and glasses. We have used five variants of masks to cover the lower part of the face with varying coverage areas (low-coverage, medium-coverage, high-coverage, round coverage), and 3D cues. We have also used different variants of glasses that cover the upper part of the face. We systematically tested the performance of four PAD algorithms under these occlusion attacks using a benchmark dataset. We have specifically looked at four different baseline PAD algorithms that focus on, texture, image quality, frame difference/motion, and abstract features through a convolutional neural network (CNN). Additionally we have introduced a new hybrid model that uses CNN and local binary pattern textures. Our experiment shows that adding the occlusions significantly degrades the performance of all of the PAD algorithms. Our results show the vulnerability of face anti-spoofing algorithms with occlusions, which could be in the usage of such algorithms in the post-pandemic era.
Color Invariant Skin Segmentation
Apr 22, 2022
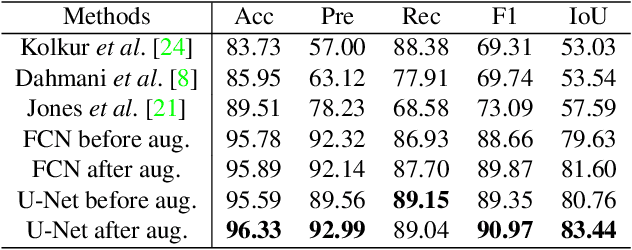
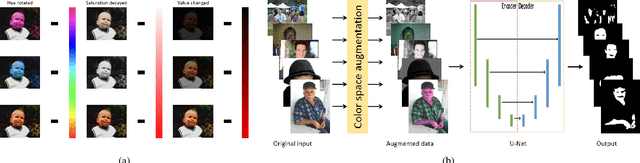
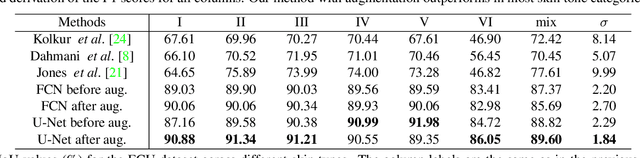
This paper addresses the problem of automatically detecting human skin in images without reliance on color information. A primary motivation of the work has been to achieve results that are consistent across the full range of skin tones, even while using a training dataset that is significantly biased toward lighter skin tones. Previous skin-detection methods have used color cues almost exclusively, and we present a new approach that performs well in the absence of such information. A key aspect of the work is dataset repair through augmentation that is applied strategically during training, with the goal of color invariant feature learning to enhance generalization. We have demonstrated the concept using two architectures, and experimental results show improvements in both precision and recall for most Fitzpatrick skin tones in the benchmark ECU dataset. We further tested the system with the RFW dataset to show that the proposed method performs much more consistently across different ethnicities, thereby reducing the chance of bias based on skin color. To demonstrate the effectiveness of our work, extensive experiments were performed on grayscale images as well as images obtained under unconstrained illumination and with artificial filters. Source code: https://github.com/HanXuMartin/Color-Invariant-Skin-Segmentation
Leveraging SE(3) Equivariance for Self-Supervised Category-Level Object Pose Estimation
Oct 30, 2021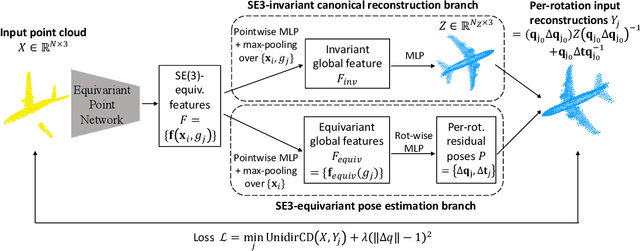

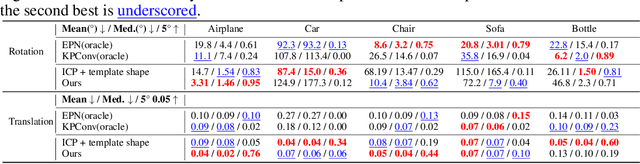

Category-level object pose estimation aims to find 6D object poses of previously unseen object instances from known categories without access to object CAD models. To reduce the huge amount of pose annotations needed for category-level learning, we propose for the first time a self-supervised learning framework to estimate category-level 6D object pose from single 3D point clouds.During training, our method assumes no ground-truth pose annotations, no CAD models, and no multi-view supervision. The key to our method is to disentangle shape and pose through an invariant shape reconstruction module and an equivariant pose estimation module, empowered by SE(3) equivariant point cloud networks.The invariant shape reconstruction module learns to perform aligned reconstructions, yielding a category-level reference frame without using any annotations. In addition, the equivariant pose estimation module achieves category-level pose estimation accuracy that is comparable to some fully supervised methods. Extensive experiments demonstrate the effectiveness of our approach on both complete and partial depth point clouds from the ModelNet40 benchmark, and on real depth point clouds from the NOCS-REAL 275 dataset. The project page with code and visualizations can be found at: https://dragonlong.github.io/equi-pose.
Adaptive Label Smoothing
Sep 14, 2020
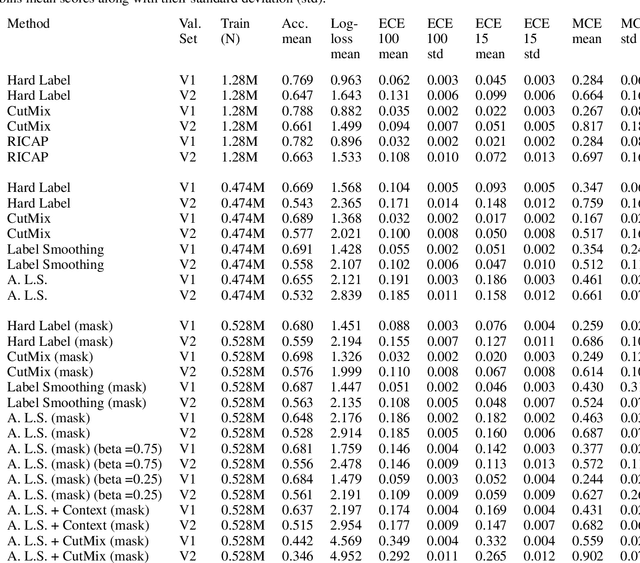
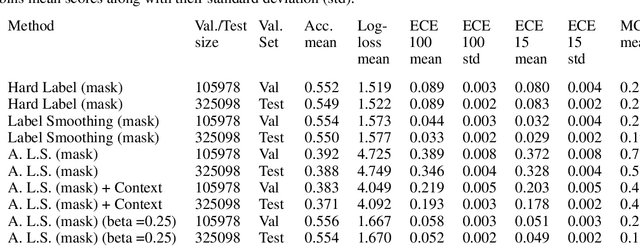
This paper concerns the use of objectness measures to improve the calibration performance of Convolutional Neural Networks (CNNs). Objectness is a measure of likelihood of an object from any class being present in a given image. CNNs have proven to be very good classifiers and generally localize objects well; however, the loss functions typically used to train classification CNNs do not penalize inability to localize an object, nor do they take into account an object's relative size in the given image. We present a novel approach to object localization that combines the ideas of objectness and label smoothing during training. Unlike previous methods, we compute a smoothing factor that is adaptive based on relative object size within an image. We present extensive results using ImageNet and OpenImages to demonstrate that CNNs trained using adaptive label smoothing are much less likely to be overconfident in their predictions, as compared to CNNs trained using hard targets. We also show qualitative results using class activation maps to illustrate the improvements.
Category-Level Articulated Object Pose Estimation
Dec 26, 2019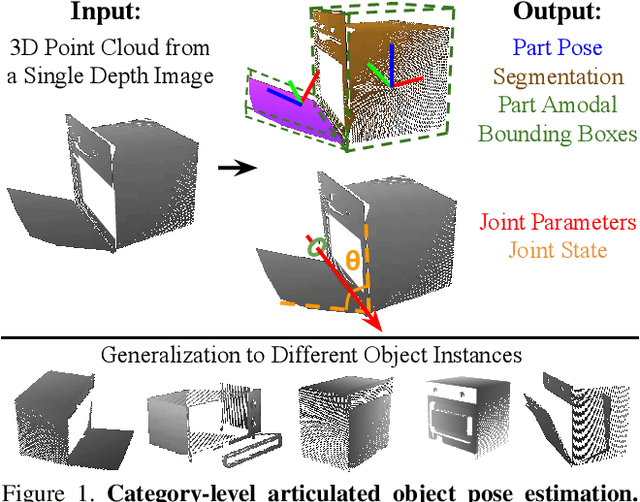
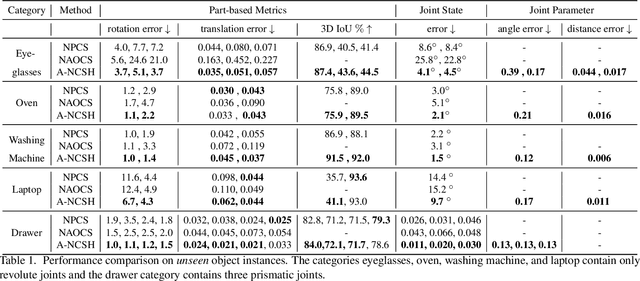
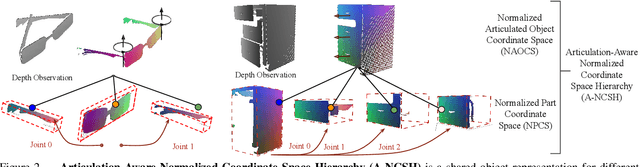
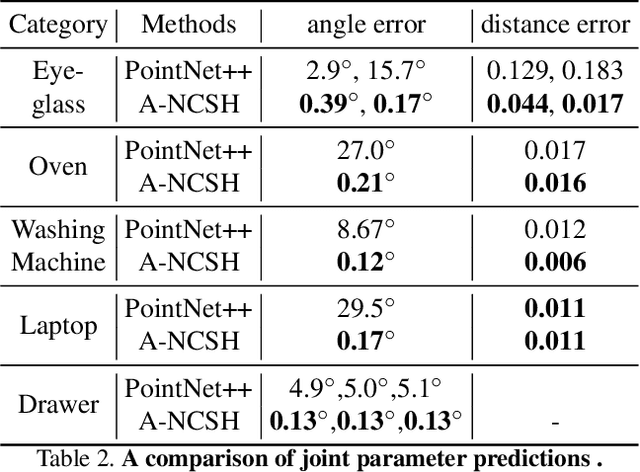
This paper addresses the task of category-level pose estimation for articulated objects from a single depth image. We present a novel category-level approach that correctly accommodates object instances not previously seen during training. A key aspect of the work is the new Articulation-Aware Normalized Coordinate Space Hierarchy (A-NCSH), which represents the different articulated objects for a given object category. This approach not only provides the canonical representation of each rigid part, but also normalizes the joint parameters and joint states. We developed a deep network based on PointNet++ that is capable of predicting an A-NCSH representation for unseen object instances from single depth input. The predicted A-NCSH representation is then used for global pose optimization using kinematic constraints. We demonstrate that constraints associated with joints in the kinematic chain lead to improved performance in estimating pose and relative scale for each part of the object. We also demonstrate that the approach can tolerate cases of severe occlusion in the observed data. Project webpage https://articulated-pose.github.io/
Input Fast-Forwarding for Better Deep Learning
May 23, 2017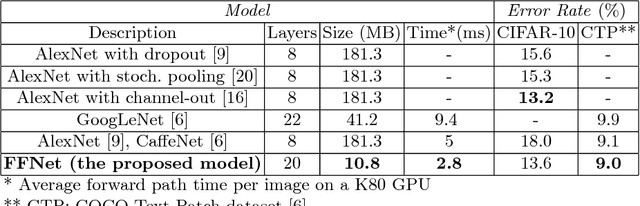
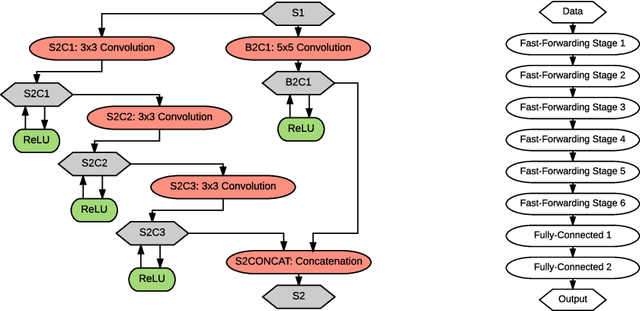
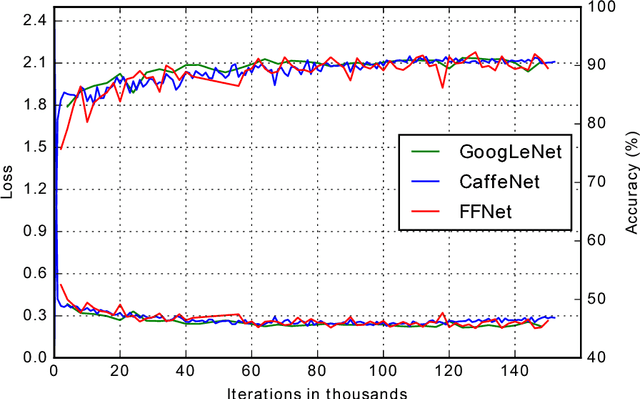
This paper introduces a new architectural framework, known as input fast-forwarding, that can enhance the performance of deep networks. The main idea is to incorporate a parallel path that sends representations of input values forward to deeper network layers. This scheme is substantially different from "deep supervision" in which the loss layer is re-introduced to earlier layers. The parallel path provided by fast-forwarding enhances the training process in two ways. First, it enables the individual layers to combine higher-level information (from the standard processing path) with lower-level information (from the fast-forward path). Second, this new architecture reduces the problem of vanishing gradients substantially because the fast-forwarding path provides a shorter route for gradient backpropagation. In order to evaluate the utility of the proposed technique, a Fast-Forward Network (FFNet), with 20 convolutional layers along with parallel fast-forward paths, has been created and tested. The paper presents empirical results that demonstrate improved learning capacity of FFNet due to fast-forwarding, as compared to GoogLeNet (with deep supervision) and CaffeNet, which are 4x and 18x larger in size, respectively. All of the source code and deep learning models described in this paper will be made available to the entire research community
An Image Dataset of Text Patches in Everyday Scenes
Oct 20, 2016
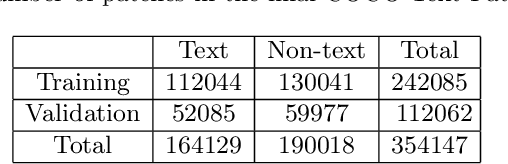

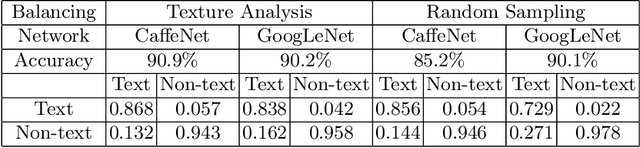
This paper describes a dataset containing small images of text from everyday scenes. The purpose of the dataset is to support the development of new automated systems that can detect and analyze text. Although much research has been devoted to text detection and recognition in scanned documents, relatively little attention has been given to text detection in other types of images, such as photographs that are posted on social-media sites. This new dataset, known as COCO-Text-Patch, contains approximately 354,000 small images that are each labeled as "text" or "non-text". This dataset particularly addresses the problem of text verification, which is an essential stage in the end-to-end text detection and recognition pipeline. In order to evaluate the utility of this dataset, it has been used to train two deep convolution neural networks to distinguish text from non-text. One network is inspired by the GoogLeNet architecture, and the second one is based on CaffeNet. Accuracy levels of 90.2% and 90.9% were obtained using the two networks, respectively. All of the images, source code, and deep-learning trained models described in this paper will be publicly available