 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep HVS-IQA Net: Human Visual System Inspired Deep Image Quality Assessment Networks
Feb 14, 2019

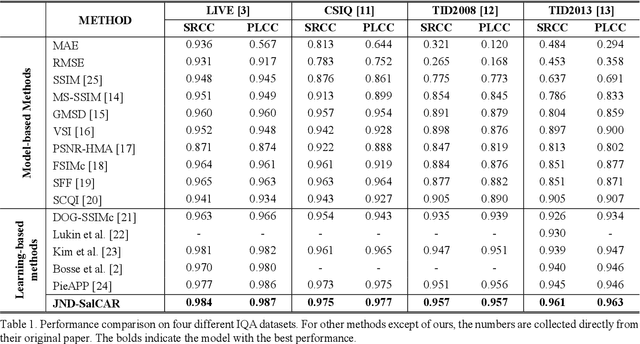
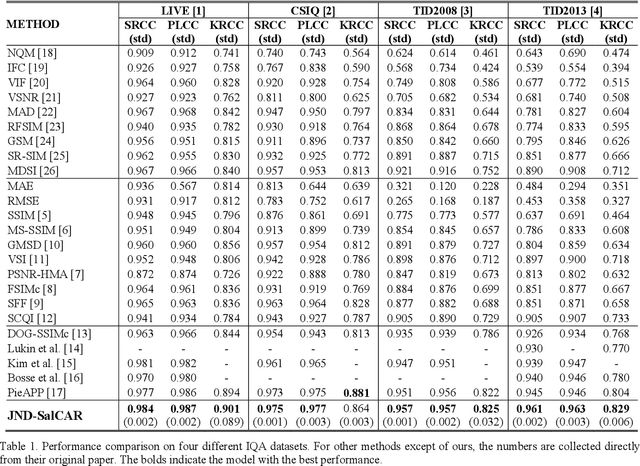
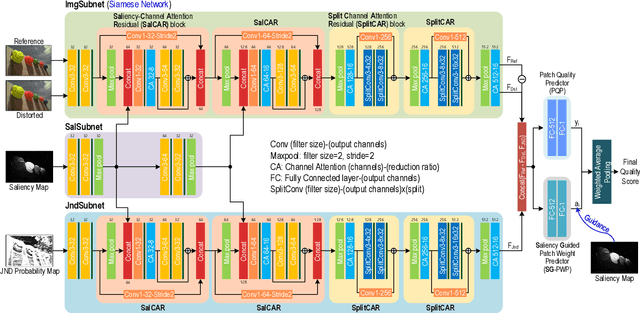
In image quality enhancement processing, it is the most important to predict how humans perceive processed images since human observers are the ultimate receivers of the images. Thus, objective image quality assessment (IQA) methods based on human visual sensitivity from psychophysical experiments have been extensively studied. Thanks to the powerfulness of deep convolutional neural networks (CNN), many CNN based IQA models have been studied. However, previous CNN-based IQA models have not fully utilized the characteristics of human visual systems (HVS) for IQA problems by simply entrusting everything to CNN where the CNN-based models are often trained as a regressor to predict the scores of subjective quality assessment obtained from IQA datasets. In this paper, we propose a novel HVS-inspired deep IQA network, called Deep HVS-IQA Net, where the human psychophysical characteristics such as visual saliency and just noticeable difference (JND) are incorporated at the front-end of the Deep HVS-IQA Net. To our best knowledge, our work is the first HVS-inspired trainable IQA network that considers both the visual saliency and JND characteristics of HVS. Furthermore, we propose a rank loss to train our Deep HVS-IQA Net effectively so that perceptually important features can be extracted for image quality prediction. The rank loss can penalize the Deep HVS-IQA Net when the order of its predicted quality scores is different from that of the ground truth scores. We evaluate the proposed Deep HVS-IQA Net on large IQA datasets where it outperforms all the recent state-of-the-art IQA methods.
Fast Bi-layer Neural Synthesis of One-Shot Realistic Head Avatars
Aug 24, 2020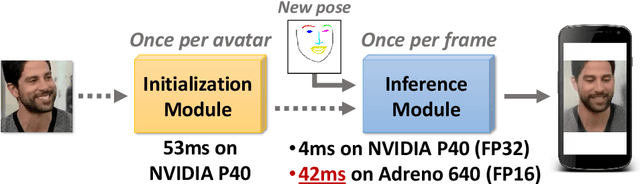
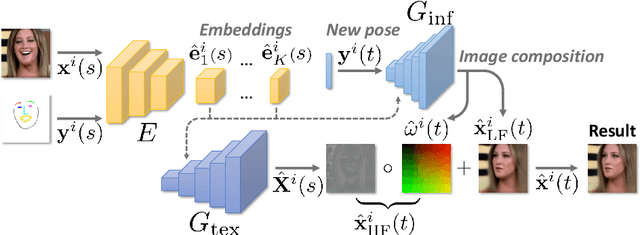
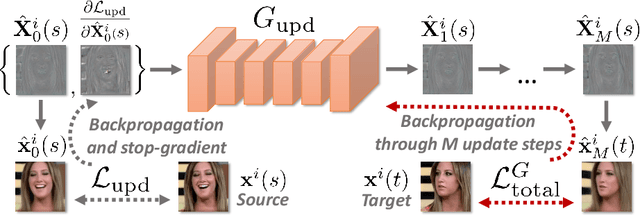
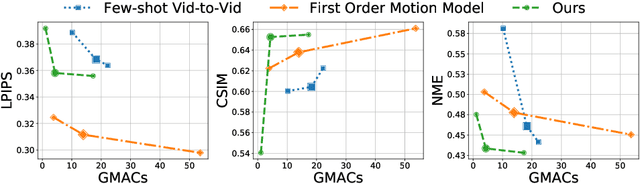
We propose a neural rendering-based system that creates head avatars from a single photograph. Our approach models a person's appearance by decomposing it into two layers. The first layer is a pose-dependent coarse image that is synthesized by a small neural network. The second layer is defined by a pose-independent texture image that contains high-frequency details. The texture image is generated offline, warped and added to the coarse image to ensure a high effective resolution of synthesized head views. We compare our system to analogous state-of-the-art systems in terms of visual quality and speed. The experiments show significant inference speedup over previous neural head avatar models for a given visual quality. We also report on a real-time smartphone-based implementation of our system.
Audio Transformers:Transformer Architectures For Large Scale Audio Understanding. Adieu Convolutions
May 01, 2021
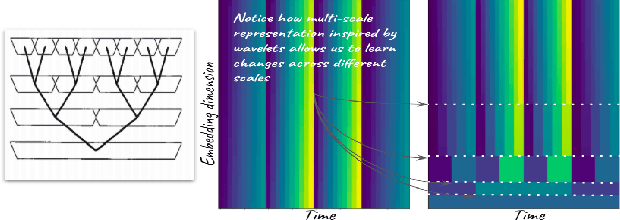
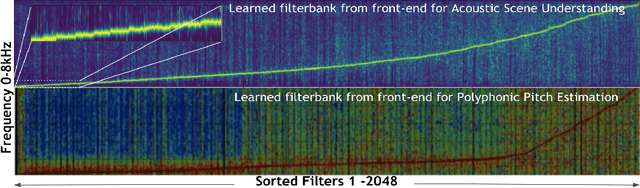
Over the past two decades, CNN architectures have produced compelling models of sound perception and cognition, learning hierarchical organizations of features. Analogous to successes in computer vision, audio feature classification can be optimized for a particular task of interest, over a wide variety of datasets and labels. In fact similar architectures designed for image understanding have proven effective for acoustic scene analysis. Here we propose applying Transformer based architectures without convolutional layers to raw audio signals. On a standard dataset of Free Sound 50K,comprising of 200 categories, our model outperforms convolutional models to produce state of the art results. This is significant as unlike in natural language processing and computer vision, we do not perform unsupervised pre-training for outperforming convolutional architectures. On the same training set, with respect mean aver-age precision benchmarks, we show a significant improvement. We further improve the performance of Transformer architectures by using techniques such as pooling inspired from convolutional net-work designed in the past few years. In addition, we also show how multi-rate signal processing ideas inspired from wavelets, can be applied to the Transformer embeddings to improve the results. We also show how our models learns a non-linear non constant band-width filter-bank, which shows an adaptable time frequency front end representation for the task of audio understanding, different from other tasks e.g. pitch estimation.
Quality Classified Image Analysis with Application to Face Detection and Recognition
Jan 19, 2018
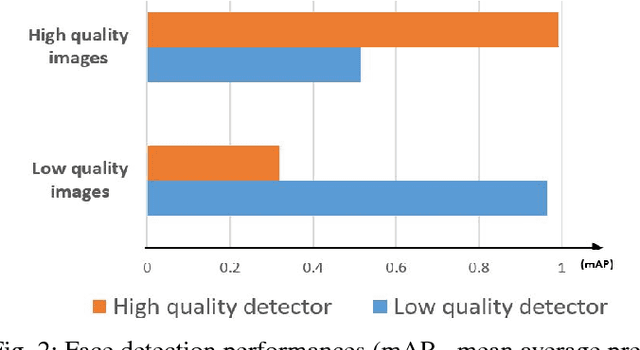
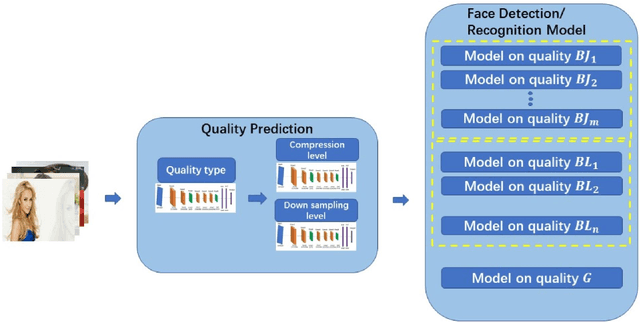
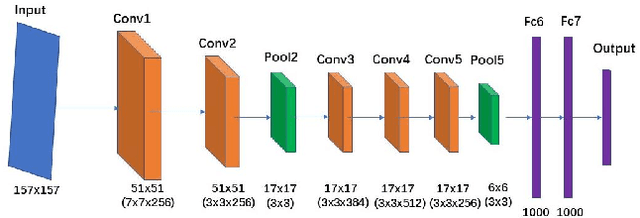
Motion blur, out of focus, insufficient spatial resolution, lossy compression and many other factors can all cause an image to have poor quality. However, image quality is a largely ignored issue in traditional pattern recognition literature. In this paper, we use face detection and recognition as case studies to show that image quality is an essential factor which will affect the performances of traditional algorithms. We demonstrated that it is not the image quality itself that is the most important, but rather the quality of the images in the training set should have similar quality as those in the testing set. To handle real-world application scenarios where images with different kinds and severities of degradation can be presented to the system, we have developed a quality classified image analysis framework to deal with images of mixed qualities adaptively. We use deep neural networks first to classify images based on their quality classes and then design a separate face detector and recognizer for images in each quality class. We will present experimental results to show that our quality classified framework can accurately classify images based on the type and severity of image degradations and can significantly boost the performances of state-of-the-art face detector and recognizer in dealing with image datasets containing mixed quality images.
Unsupervised Document Embedding via Contrastive Augmentation
Mar 26, 2021
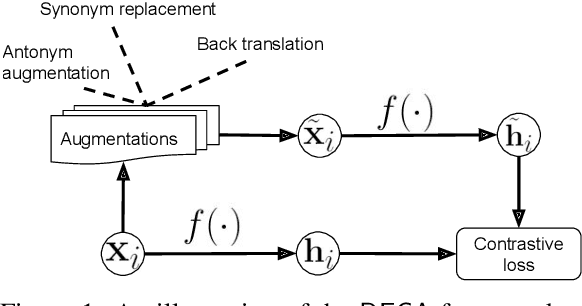
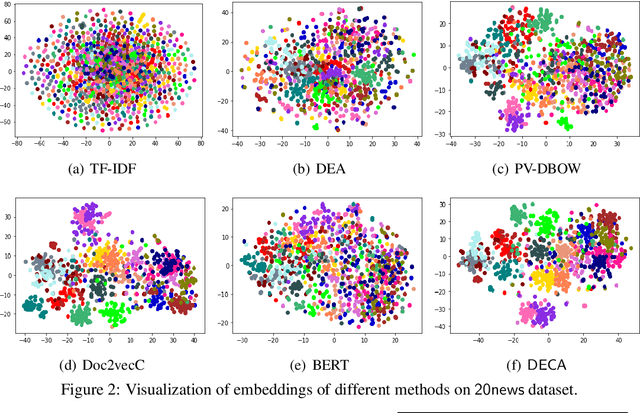
We present a contrasting learning approach with data augmentation techniques to learn document representations in an unsupervised manner. Inspired by recent contrastive self-supervised learning algorithms used for image and NLP pretraining, we hypothesize that high-quality document embedding should be invariant to diverse paraphrases that preserve the semantics of the original document. With different backbones and contrastive learning frameworks, our study reveals the enormous benefits of contrastive augmentation for document representation learning with two additional insights: 1) including data augmentation in a contrastive way can substantially improve the embedding quality in unsupervised document representation learning, and 2) in general, stochastic augmentations generated by simple word-level manipulation work much better than sentence-level and document-level ones. We plug our method into a classifier and compare it with a broad range of baseline methods on six benchmark datasets. Our method can decrease the classification error rate by up to 6.4% over the SOTA approaches on the document classification task, matching or even surpassing fully-supervised methods.
A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
Apr 15, 2021

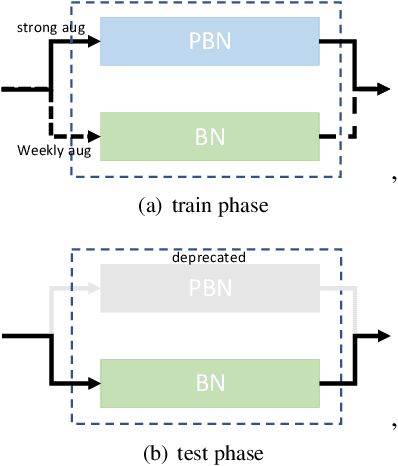

Recently, significant progress has been made on semantic segmentation. However, the success of supervised semantic segmentation typically relies on a large amount of labelled data, which is time-consuming and costly to obtain. Inspired by the success of semi-supervised learning methods in image classification, here we propose a simple yet effective semi-supervised learning framework for semantic segmentation. We demonstrate that the devil is in the details: a set of simple design and training techniques can collectively improve the performance of semi-supervised semantic segmentation significantly. Previous works [3, 27] fail to employ strong augmentation in pseudo label learning efficiently, as the large distribution change caused by strong augmentation harms the batch normalisation statistics. We design a new batch normalisation, namely distribution-specific batch normalisation (DSBN) to address this problem and demonstrate the importance of strong augmentation for semantic segmentation. Moreover, we design a self correction loss which is effective in noise resistance. We conduct a series of ablation studies to show the effectiveness of each component. Our method achieves state-of-the-art results in the semi-supervised settings on the Cityscapes and Pascal VOC datasets.
CANDY: Conditional Adversarial Networks based Fully End-to-End System for Single Image Haze Removal
May 02, 2018
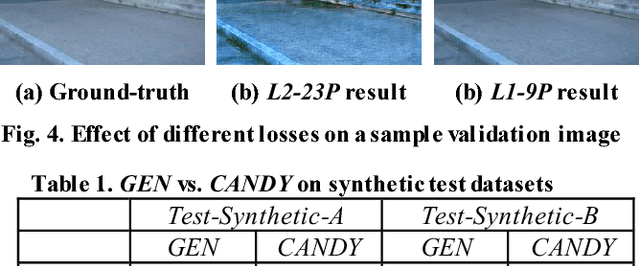
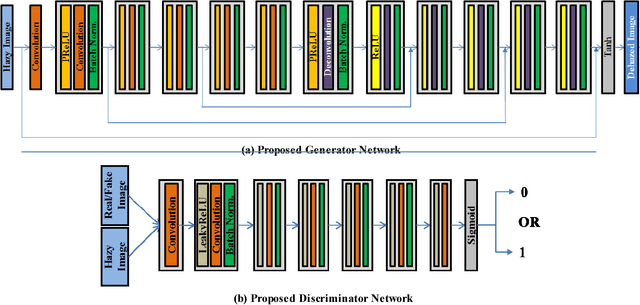
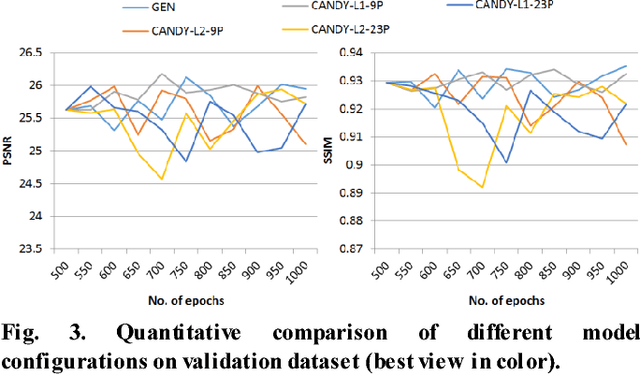
Single image haze removal is a very challenging and ill-posed problem. The existing haze removal methods in literature, including the recently introduced deep learning methods, model the problem of haze removal as that of estimating intermediate parameters, viz., scene transmission map and atmospheric light. These are used to compute the haze-free image from the hazy input image. Such an approach only focuses on accurate estimation of intermediate parameters, while the aesthetic quality of the haze-free image is unaccounted for in the optimization framework. Thus, errors in the estimation of intermediate parameters often lead to generation of inferior quality haze-free images. In this paper, we present CANDY (Conditional Adversarial Networks based Dehazing of hazY images), a fully end-to-end model which directly generates a clean haze-free image from a hazy input image. CANDY also incorporates the visual quality of haze-free image into the optimization function; thus, generating a superior quality haze-free image. To the best of our knowledge, this is the first work in literature to propose a fully end-to-end model for single image haze removal. Also, this is the first work to explore the newly introduced concept of generative adversarial networks for the problem of single image haze removal. The proposed model CANDY was trained on a synthetically created haze image dataset, while evaluation was performed on challenging synthetic as well as real haze image datasets. The extensive evaluation and comparison results of CANDY reveal that it significantly outperforms existing state-of-the-art haze removal methods in literature, both quantitatively as well as qualitatively.
Towards Trustworthy Deception Detection: Benchmarking Model Robustness across Domains, Modalities, and Languages
Apr 23, 2021

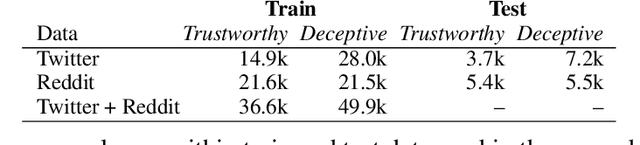
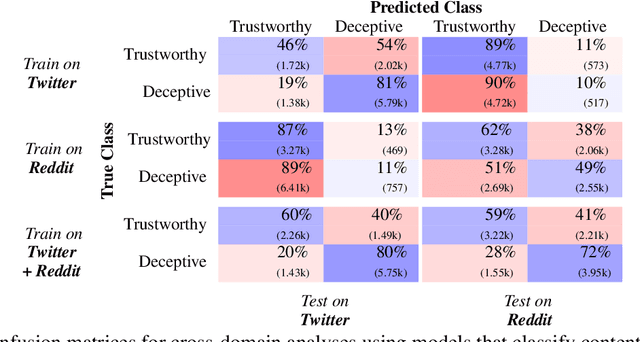
Evaluating model robustness is critical when developing trustworthy models not only to gain deeper understanding of model behavior, strengths, and weaknesses, but also to develop future models that are generalizable and robust across expected environments a model may encounter in deployment. In this paper we present a framework for measuring model robustness for an important but difficult text classification task - deceptive news detection. We evaluate model robustness to out-of-domain data, modality-specific features, and languages other than English. Our investigation focuses on three type of models: LSTM models trained on multiple datasets(Cross-Domain), several fusion LSTM models trained with images and text and evaluated with three state-of-the-art embeddings, BERT ELMo, and GloVe (Cross-Modality), and character-level CNN models trained on multiple languages (Cross-Language). Our analyses reveal a significant drop in performance when testing neural models on out-of-domain data and non-English languages that may be mitigated using diverse training data. We find that with additional image content as input, ELMo embeddings yield significantly fewer errors compared to BERT orGLoVe. Most importantly, this work not only carefully analyzes deception model robustness but also provides a framework of these analyses that can be applied to new models or extended datasets in the future.
TextMage: The Automated Bangla Caption Generator Based On Deep Learning
Oct 15, 2020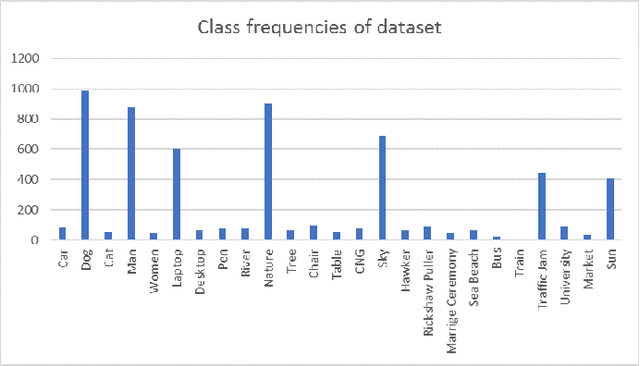
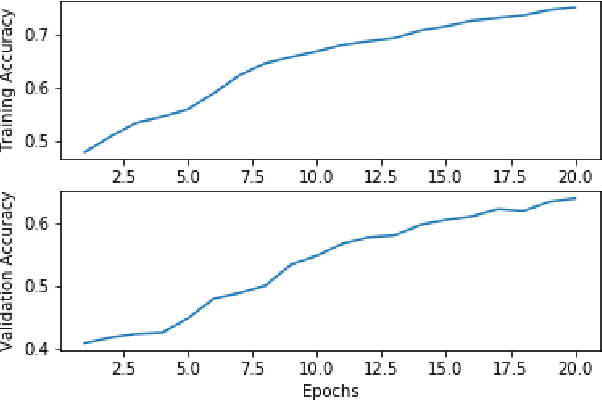
Neural Networks and Deep Learning have seen an upsurge of research in the past decade due to the improved results. Generates text from the given image is a crucial task that requires the combination of both sectors which are computer vision and natural language processing in order to understand an image and represent it using a natural language. However existing works have all been done on a particular lingual domain and on the same set of data. This leads to the systems being developed to perform poorly on images that belong to specific locales' geographical context. TextMage is a system that is capable of understanding visual scenes that belong to the Bangladeshi geographical context and use its knowledge to represent what it understands in Bengali. Hence, we have trained a model on our previously developed and published dataset named BanglaLekhaImageCaptions. This dataset contains 9,154 images along with two annotations for each image. In order to access performance, the proposed model has been implemented and evaluated.
MetaKernel: Learning Variational Random Features with Limited Labels
May 08, 2021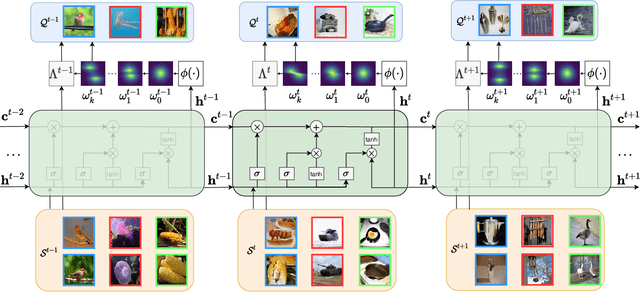
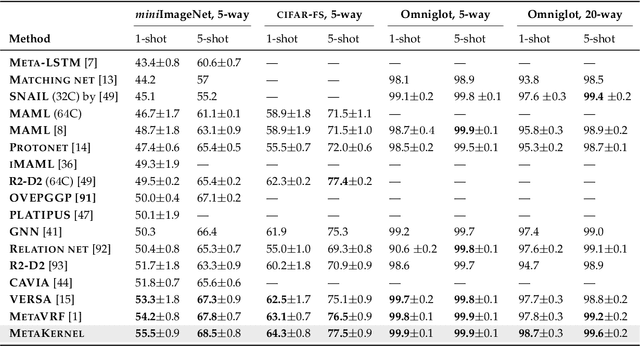
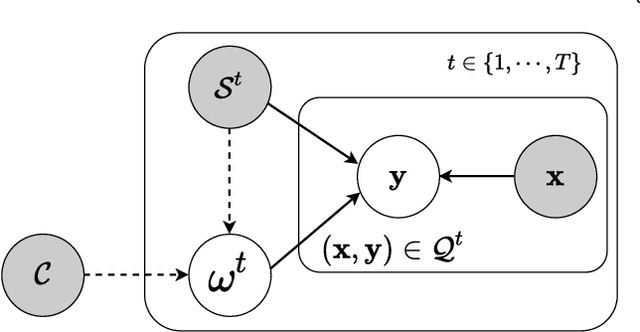
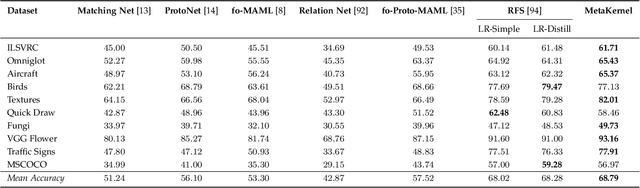
Few-shot learning deals with the fundamental and challenging problem of learning from a few annotated samples, while being able to generalize well on new tasks. The crux of few-shot learning is to extract prior knowledge from related tasks to enable fast adaptation to a new task with a limited amount of data. In this paper, we propose meta-learning kernels with random Fourier features for few-shot learning, we call MetaKernel. Specifically, we propose learning variational random features in a data-driven manner to obtain task-specific kernels by leveraging the shared knowledge provided by related tasks in a meta-learning setting. We treat the random feature basis as the latent variable, which is estimated by variational inference. The shared knowledge from related tasks is incorporated into a context inference of the posterior, which we achieve via a long-short term memory module. To establish more expressive kernels, we deploy conditional normalizing flows based on coupling layers to achieve a richer posterior distribution over random Fourier bases. The resultant kernels are more informative and discriminative, which further improves the few-shot learning. To evaluate our method, we conduct extensive experiments on both few-shot image classification and regression tasks. A thorough ablation study demonstrates that the effectiveness of each introduced component in our method. The benchmark results on fourteen datasets demonstrate MetaKernel consistently delivers at least comparable and often better performance than state-of-the-art alternatives.