 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Document Embedding via Contrastive Augmentation
Paper and Code
Mar 26, 2021
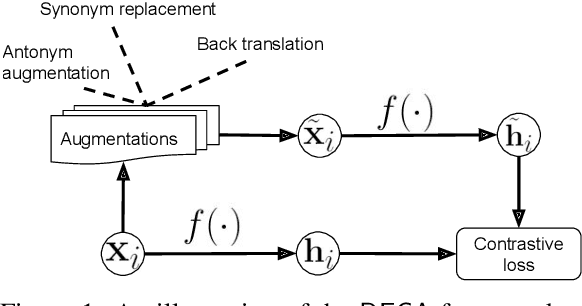
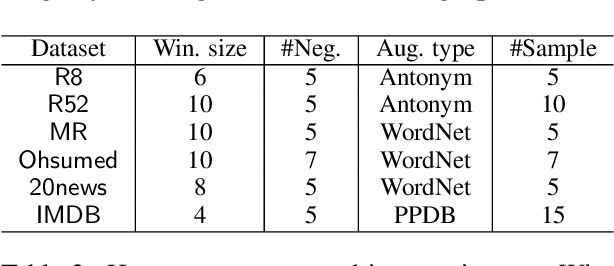
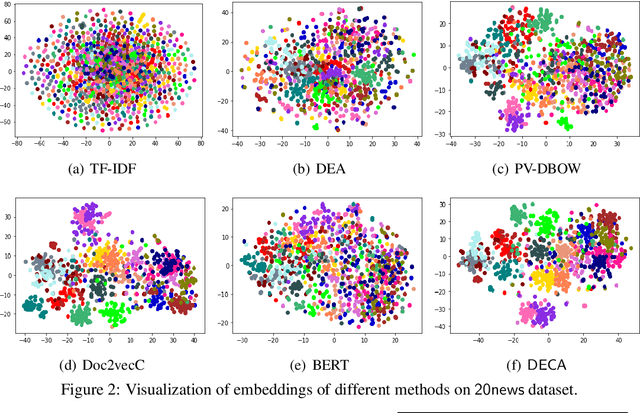
We present a contrasting learning approach with data augmentation techniques to learn document representations in an unsupervised manner. Inspired by recent contrastive self-supervised learning algorithms used for image and NLP pretraining, we hypothesize that high-quality document embedding should be invariant to diverse paraphrases that preserve the semantics of the original document. With different backbones and contrastive learning frameworks, our study reveals the enormous benefits of contrastive augmentation for document representation learning with two additional insights: 1) including data augmentation in a contrastive way can substantially improve the embedding quality in unsupervised document representation learning, and 2) in general, stochastic augmentations generated by simple word-level manipulation work much better than sentence-level and document-level ones. We plug our method into a classifier and compare it with a broad range of baseline methods on six benchmark datasets. Our method can decrease the classification error rate by up to 6.4% over the SOTA approaches on the document classification task, matching or even surpassing fully-supervised methods.