 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Aesthetic Sonifications on the Web with SIREN
Mar 28, 2024
SIREN is a flexible, extensible, and customizable web-based general-purpose interface for auditory data display (sonification). Designed as a digital audio workstation for sonification, synthesizers written in JavaScript using the Web Audio API facilitate intuitive mapping of data to auditory parameters for a wide range of purposes. This paper explores the breadth of sound synthesis techniques supported by SIREN, and details the structure and definition of a SIREN synthesizer module. The paper proposes further development that will increase SIREN's utility.
One-Shot Acoustic Matching Of Audio Signals -- Learning to Hear Music In Any Room/ Concert Hall
Oct 31, 2022
The acoustic space in which a sound is created and heard plays an essential role in how that sound is perceived by affording a unique sense of \textit{presence}. Every sound we hear results from successive convolution operations intrinsic to the sound source and external factors such as microphone characteristics and room impulse responses. Typically, researchers use an excitation such as a pistol shot or balloon pop as an impulse signal with which an auralization can be created. The room "impulse" responses convolved with the signal of interest can transform the input sound into the sound played in the acoustic space of interest. Here we propose a novel architecture that can transform a sound of interest into any other acoustic space(room or hall) of interest by using arbitrary audio recorded as a proxy for a balloon pop. The architecture is grounded in simple signal processing ideas to learn residual signals from a learned acoustic signature and the input signal. Our framework allows a neural network to adjust gains of every point in the time-frequency representation, giving sound qualitative and quantitative results.
Acoustically-Driven Phoneme Removal That Preserves Vocal Affect Cues
Oct 26, 2022


In this paper, we propose a method for removing linguistic information from speech for the purpose of isolating paralinguistic indicators of affect. The immediate utility of this method lies in clinical tests of sensitivity to vocal affect that are not confounded by language, which is impaired in a variety of clinical populations. The method is based on simultaneous recordings of speech audio and electroglottographic (EGG) signals. The speech audio signal is used to estimate the average vocal tract filter response and amplitude envelop. The EGG signal supplies a direct correlate of voice source activity that is mostly independent of phonetic articulation. These signals are used to create a third signal designed to capture as much paralinguistic information from the vocal production system as possible -- maximizing the retention of bioacoustic cues to affect -- while eliminating phonetic cues to verbal meaning. To evaluate the success of this method, we studied the perception of corresponding speech audio and transformed EGG signals in an affect rating experiment with online listeners. The results show a high degree of similarity in the perceived affect of matched signals, indicating that our method is effective.
The Role of Voice Persona in Expressive Communication:An Argument for Relevance in Speech Synthesis Design
Sep 06, 2022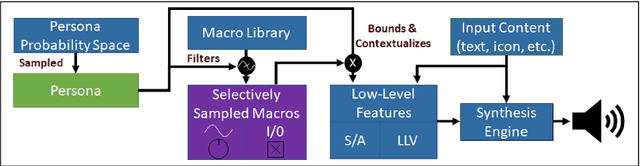
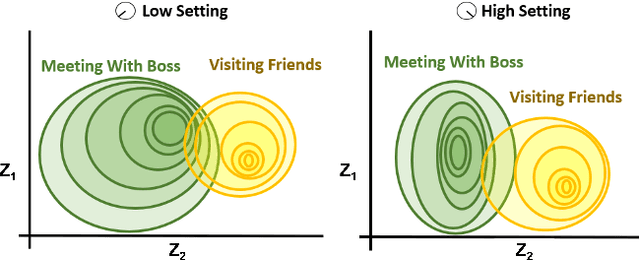
We present an approach to imbuing expressivity in a synthesized voice by acquiring a thematic analysis of 10 interviews with vocal studies and performance experts to inform the design framework for a real-time, interactive vocal persona that would generate compelling and appropriate contextually-dependent expression. The resultant tone of voice is defined as a point existing within a continuous, contextually-dependent probability space. The inclusion of voice persona in synthesized voice can be significant in a broad range of applications. Of particular interest is the potential impact in augmentative and assistive communication (AAC) community. Finally, we conclude with an introduction to our ongoing research investigating the themes of vocal persona and how they may continue to inform proposed expressive speech synthesis design frameworks.
Enhancing Audio Perception of Music By AI Picked Room Acoustics
Aug 16, 2022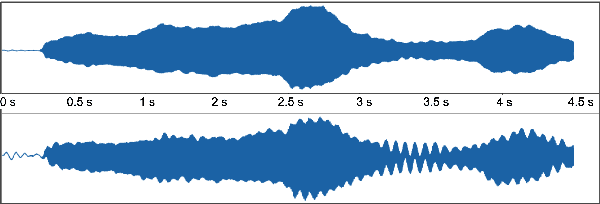
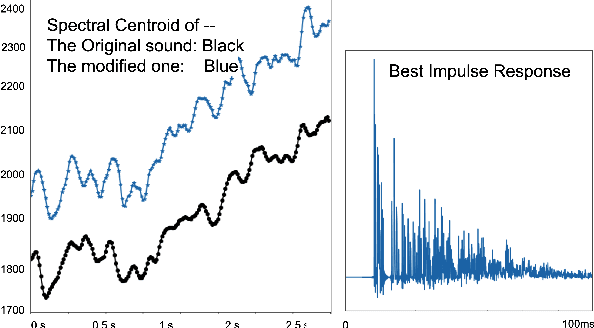
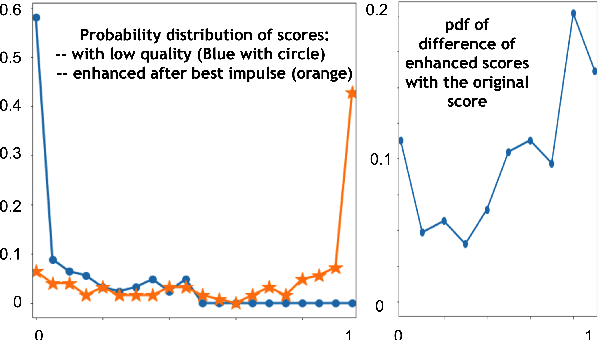
Every sound that we hear is the result of successive convolutional operations (e.g. room acoustics, microphone characteristics, resonant properties of the instrument itself, not to mention characteristics and limitations of the sound reproduction system). In this work we seek to determine the best room in which to perform a particular piece using AI. Additionally, we use room acoustics as a way to enhance the perceptual qualities of a given sound. Historically, rooms (particularly Churches and concert halls) were designed to host and serve specific musical functions. In some cases the architectural acoustical qualities enhanced the music performed there. We try to mimic this, as a first step, by designating room impulse responses that would correlate to producing enhanced sound quality for particular music. A convolutional architecture is first trained to take in an audio sample and mimic the ratings of experts with about 78 % accuracy for various instrument families and notes for perceptual qualities. This gives us a scoring function for any audio sample which can rate the perceptual pleasantness of a note automatically. Now, via a library of about 60,000 synthetic impulse responses mimicking all kinds of room, materials, etc, we use a simple convolution operation, to transform the sound as if it was played in a particular room. The perceptual evaluator is used to rank the musical sounds, and yield the "best room or the concert hall" to play a sound. As a byproduct it can also use room acoustics to turn a poor quality sound into a "good" sound.
Audio Transformers:Transformer Architectures For Large Scale Audio Understanding. Adieu Convolutions
May 01, 2021
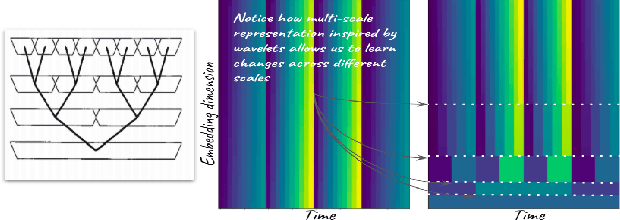
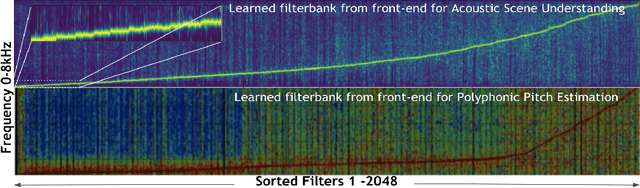
Over the past two decades, CNN architectures have produced compelling models of sound perception and cognition, learning hierarchical organizations of features. Analogous to successes in computer vision, audio feature classification can be optimized for a particular task of interest, over a wide variety of datasets and labels. In fact similar architectures designed for image understanding have proven effective for acoustic scene analysis. Here we propose applying Transformer based architectures without convolutional layers to raw audio signals. On a standard dataset of Free Sound 50K,comprising of 200 categories, our model outperforms convolutional models to produce state of the art results. This is significant as unlike in natural language processing and computer vision, we do not perform unsupervised pre-training for outperforming convolutional architectures. On the same training set, with respect mean aver-age precision benchmarks, we show a significant improvement. We further improve the performance of Transformer architectures by using techniques such as pooling inspired from convolutional net-work designed in the past few years. In addition, we also show how multi-rate signal processing ideas inspired from wavelets, can be applied to the Transformer embeddings to improve the results. We also show how our models learns a non-linear non constant band-width filter-bank, which shows an adaptable time frequency front end representation for the task of audio understanding, different from other tasks e.g. pitch estimation.
Unsupervised Representation Learning For Context of Vocal Music
Jul 17, 2020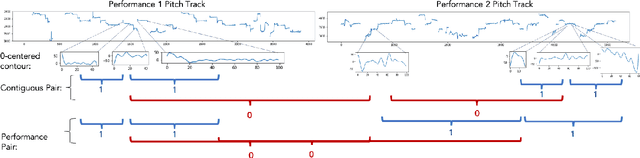

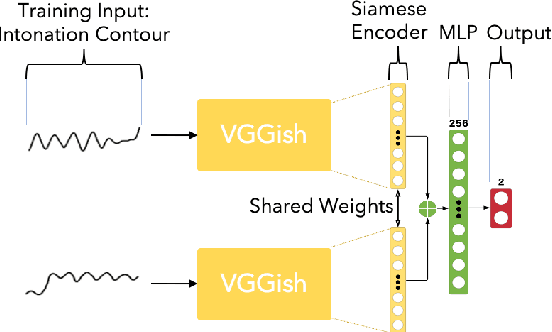
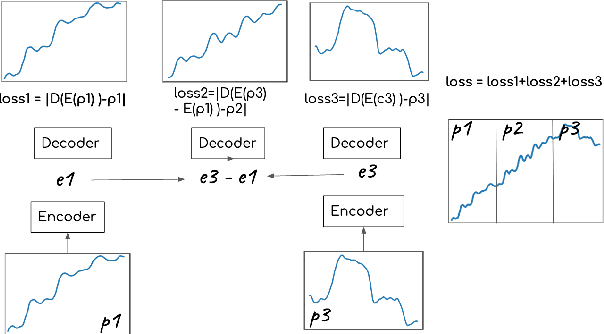
In this paper we aim to learn meaningful representations of sung intonation patterns derived from surrounding data without supervision. We focus on two facets of context in which a vocal line is produced: 1) within the short-time context of contiguous vocalizations, and 2) within the larger context of a recording. We propose two unsupervised deep learning methods, pseudo-task learning and slot filling, to produce latent encodings of these con-textual representations. To evaluate the quality of these representations and their usefulness as meaningful feature space, we conduct classification tasks on recordings sung by both professional and amateur singers. Initial results indicate that the learned representations enhance the performance of downstream classification tasks by several points, as compared to learning directly from the intonation contours alone. Larger increases in performance on classification of technique and vocal phrase patterns suggest that the representations encode short-time temporal context learned directly from the original recordings. Additionally, their ability to improve singer and gender identification suggest the learning of more broad contextual pat-terns. The growing availability of large unlabeled datasets makes this idea of contextual representation learning additionally promising, with larger amounts of meaningful samples often yielding better performance
Neuralogram: A Deep Neural Network Based Representation for Audio Signals
Apr 10, 2019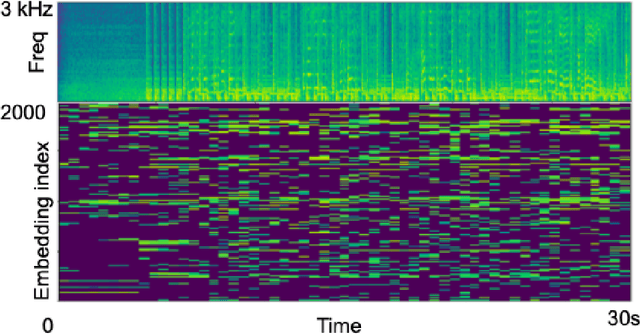
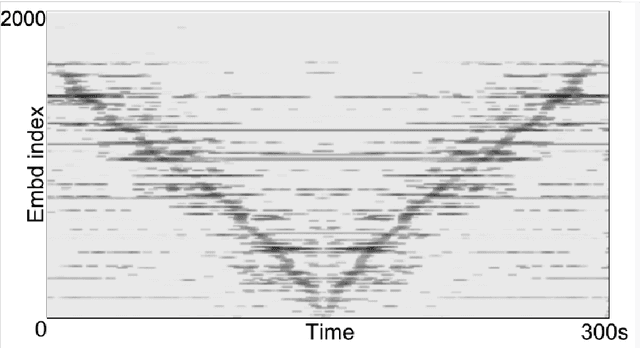

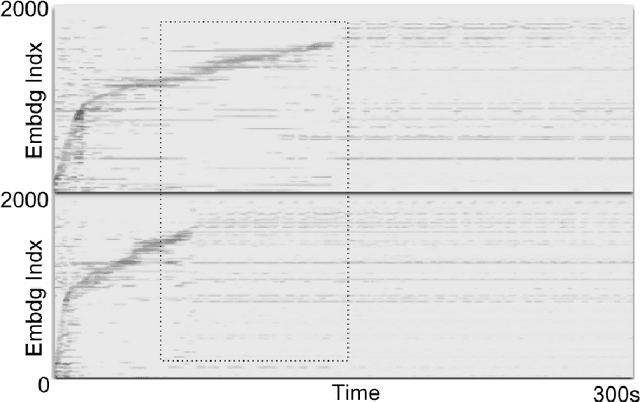
We propose the Neuralogram -- a deep neural network based representation for understanding audio signals which, as the name suggests, transforms an audio signal to a dense, compact representation based upon embeddings learned via a neural architecture. Through a series of probing signals, we show how our representation can encapsulate pitch, timbre and rhythm-based information, and other attributes. This representation suggests a method for revealing meaningful relationships in arbitrarily long audio signals that are not readily represented by existing algorithms. This has the potential for numerous applications in audio understanding, music recommendation, meta-data extraction to name a few.