 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-Modal Alignment with Mixture Experts Neural Network for Intral-City Retail Recommendation
Sep 17, 2020
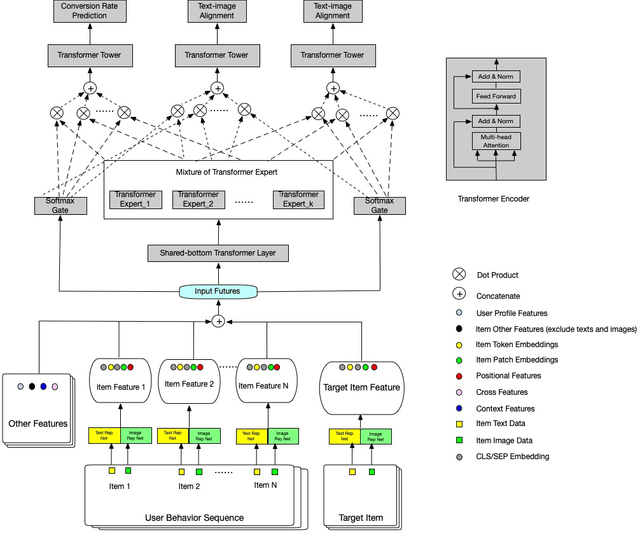
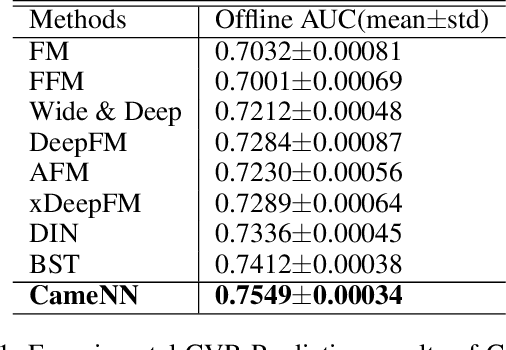
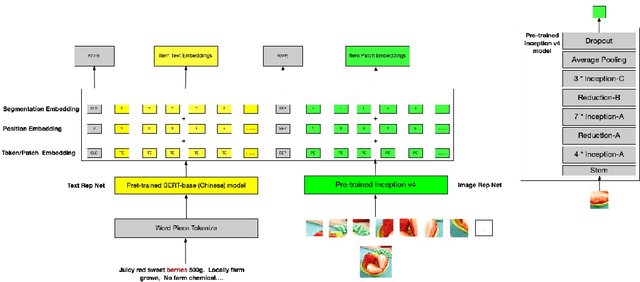

In this paper, we introduce Cross-modal Alignment with mixture experts Neural Network (CameNN) recommendation model for intral-city retail industry, which aims to provide fresh foods and groceries retailing within 5 hours delivery service arising for the outbreak of Coronavirus disease (COVID-19) pandemic around the world. We propose CameNN, which is a multi-task model with three tasks including Image to Text Alignment (ITA) task, Text to Image Alignment (TIA) task and CVR prediction task. We use pre-trained BERT to generate the text embedding and pre-trained InceptionV4 to generate image patch embedding (each image is split into small patches with the same pixels and treat each patch as an image token). Softmax gating networks follow to learn the weight of each transformer expert output and choose only a subset of experts conditioned on the input. Then transformer encoder is applied as the share-bottom layer to learn all input features' shared interaction. Next, mixture of transformer experts (MoE) layer is implemented to model different aspects of tasks. At top of the MoE layer, we deploy a transformer layer for each task as task tower to learn task-specific information. On the real word intra-city dataset, experiments demonstrate CameNN outperform baselines and achieve significant improvements on the image and text representation. In practice, we applied CameNN on CVR prediction in our intra-city recommender system which is one of the leading intra-city platforms operated in China.
C2FNAS: Coarse-to-Fine Neural Architecture Search for 3D Medical Image Segmentation
Dec 20, 2019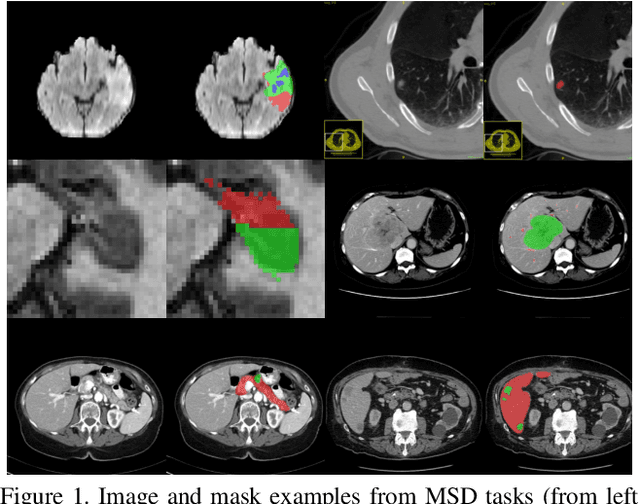
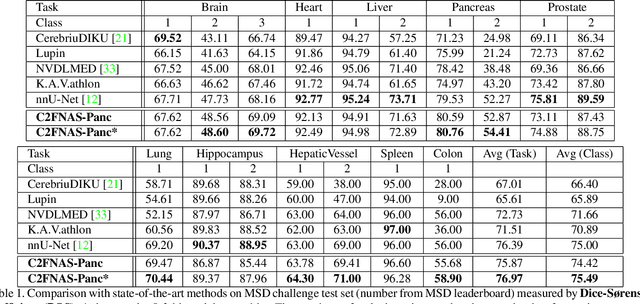

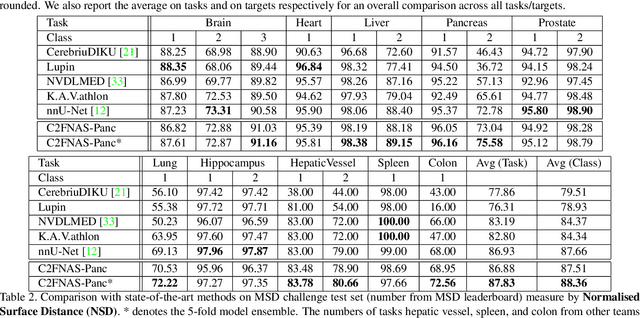
3D convolution neural networks (CNN) have been proved very successful in parsing organs or tumours in 3D medical images, but it remains sophisticated and time-consuming to choose or design proper 3D networks given different task contexts. Recently, Neural Architecture Search (NAS) is proposed to solve this problem by searching for the best network architecture automatically. However, the inconsistency between search stage and deployment stage often exists in NAS algorithms due to memory constraints and large search space, which could become more serious when applying NAS to some memory and time consuming tasks, such as 3D medical image segmentation. In this paper, we propose coarse-to-fine neural architecture search (C2FNAS) to automatically search a 3D segmentation network from scratch without inconsistency on network size or input size. Specifically, we divide the search procedure into two stages: 1) the coarse stage, where we search the macro-level topology of the network, i.e. how each convolution module is connected to other modules; 2) the fine stage, where we search at micro-level for operations in each cell based on previous searched macro-level topology. The coarse-to-fine manner divides the search procedure into two consecutive stages and meanwhile resolves the inconsistency. We evaluate our method on 10 public datasets from Medical Segmentation Decalthon (MSD) challenge, and achieve state-of-the-art performance with the network searched using one dataset, which demonstrates the effectiveness and generalization of our searched models.
Group Sparsity Residual Constraint for Image Denoising
Jul 31, 2017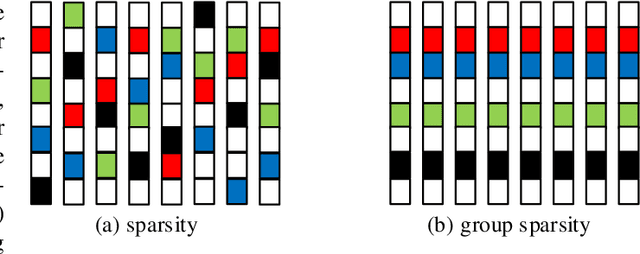



Group-based sparse representation has shown great potential in image denoising. However, most existing methods only consider the nonlocal self-similarity (NSS) prior of noisy input image. That is, the similar patches are collected only from degraded input, which makes the quality of image denoising largely depend on the input itself. However, such methods often suffer from a common drawback that the denoising performance may degrade quickly with increasing noise levels. In this paper we propose a new prior model, called group sparsity residual constraint (GSRC). Unlike the conventional group-based sparse representation denoising methods, two kinds of prior, namely, the NSS priors of noisy and pre-filtered images, are used in GSRC. In particular, we integrate these two NSS priors through the mechanism of sparsity residual, and thus, the task of image denoising is converted to the problem of reducing the group sparsity residual. To this end, we first obtain a good estimation of the group sparse coefficients of the original image by pre-filtering, and then the group sparse coefficients of the noisy image are used to approximate this estimation. To improve the accuracy of the nonlocal similar patch selection, an adaptive patch search scheme is designed. Furthermore, to fuse these two NSS prior better, an effective iterative shrinkage algorithm is developed to solve the proposed GSRC model. Experimental results demonstrate that the proposed GSRC modeling outperforms many state-of-the-art denoising methods in terms of the objective and the perceptual metrics.
End-to-end Training for Whole Image Breast Cancer Screening using An All Convolutional Design
Sep 22, 2018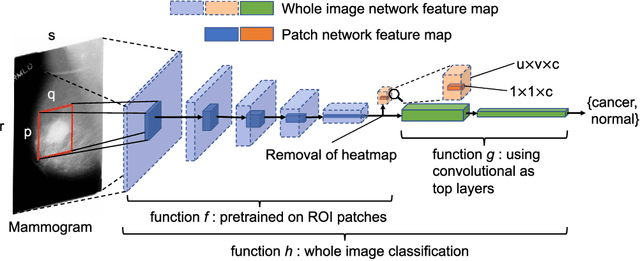
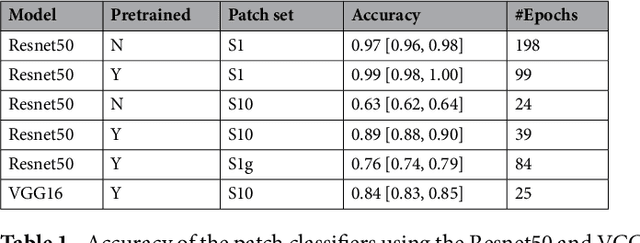
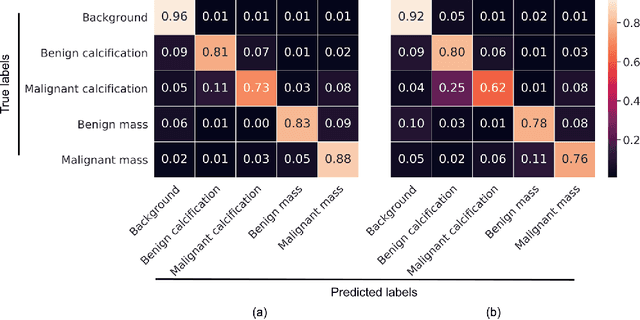
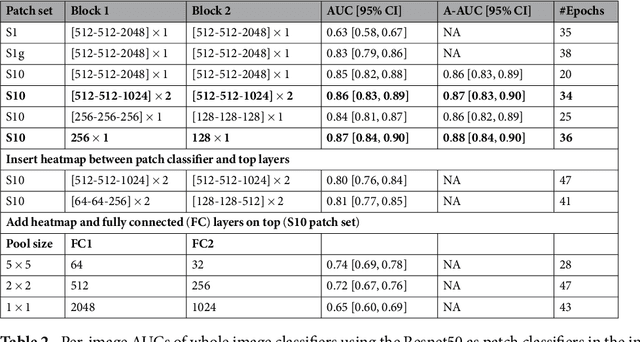
An end-to-end training algorithm for the detection and classification of breast cancer on digital mammograms was created. In the initial training stage lesion annotations were used, but in subsequent stages, a whole image classifier was trained using only image-level labels, eliminating the reliance on rarely available lesion annotations. The simple all convolutional design provided superior performance in comparison with previous methods. For example, on the Digital Database for Screening Mammography (DDSM), the best single model achieved a per-image AUC of 0.88 on a holdout test set, and three-model averaging increased the AUC to 0.91. On an independent holdout set of images from the INbreast database, the best single model achieved a per-image AUC of 0.96. We also demonstrated that a whole image model trained on DDSM can be transferred to INbreast without using its lesion annotations and using only a small amount of INbreast data for fine-tuning. Code and model available at: https://github.com/lishen/end2end-all-conv
CASSOD-Net: Cascaded and Separable Structures of Dilated Convolution for Embedded Vision Systems and Applications
Apr 29, 2021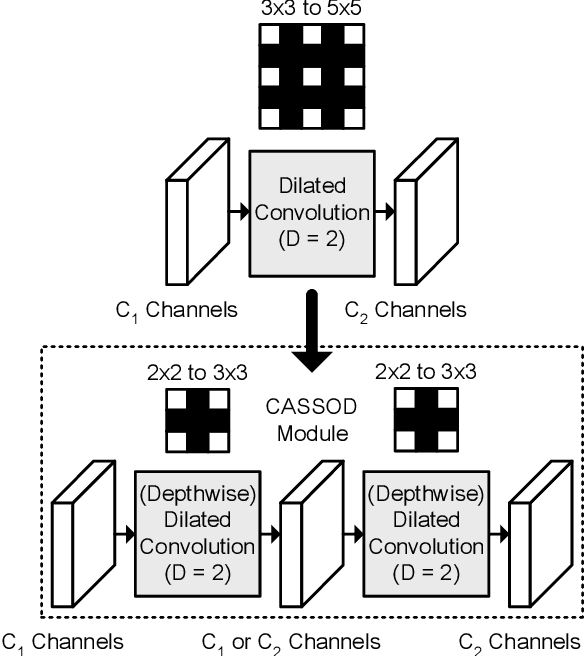

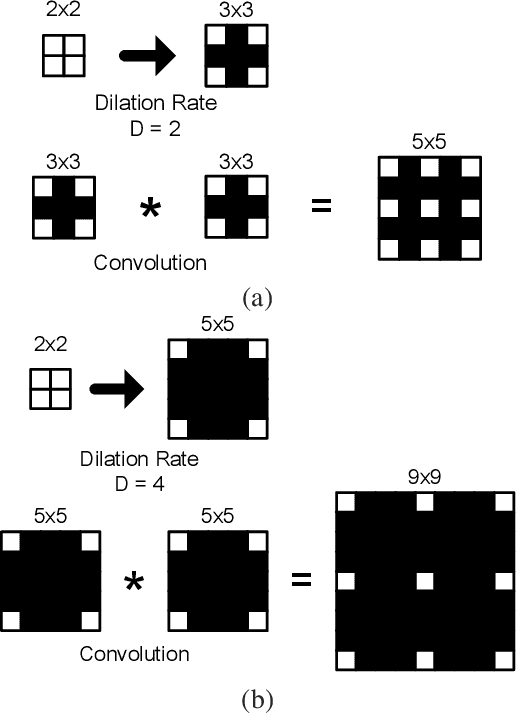
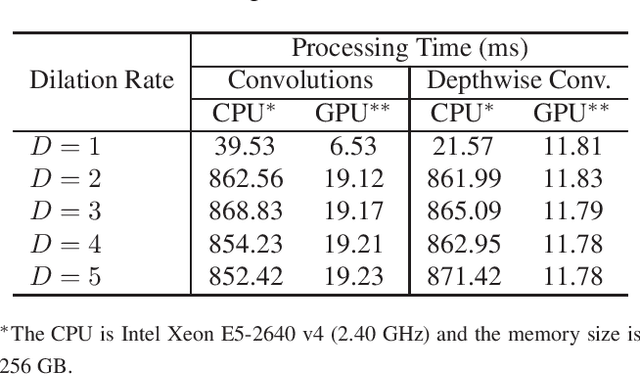
The field of view (FOV) of convolutional neural networks is highly related to the accuracy of inference. Dilated convolutions are known as an effective solution to the problems which require large FOVs. However, for general-purpose hardware or dedicated hardware, it usually takes extra time to handle dilated convolutions compared with standard convolutions. In this paper, we propose a network module, Cascaded and Separable Structure of Dilated (CASSOD) Convolution, and a special hardware system to handle the CASSOD networks efficiently. A CASSOD-Net includes multiple cascaded $2 \times 2$ dilated filters, which can be used to replace the traditional $3 \times 3$ dilated filters without decreasing the accuracy of inference. Two example applications, face detection and image segmentation, are tested with dilated convolutions and the proposed CASSOD modules. The new network for face detection achieves higher accuracy than the previous work with only 47% of filter weights in the dilated convolution layers of the context module. Moreover, the proposed hardware system can accelerate the computations of dilated convolutions, and it is 2.78 times faster than traditional hardware systems when the filter size is $3 \times 3$.
REGRAD: A Large-Scale Relational Grasp Dataset for Safe and Object-Specific Robotic Grasping in Clutter
Apr 29, 2021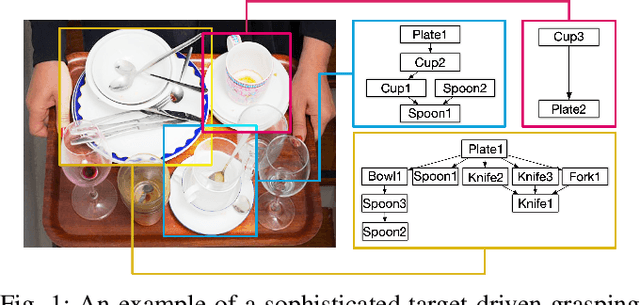
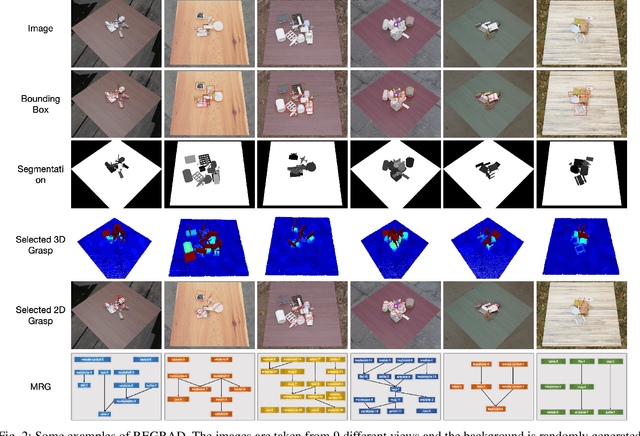
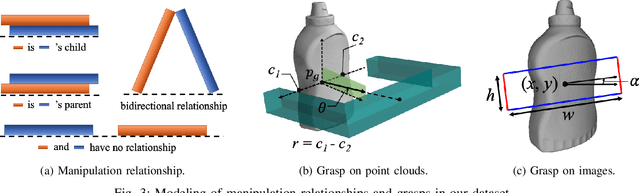
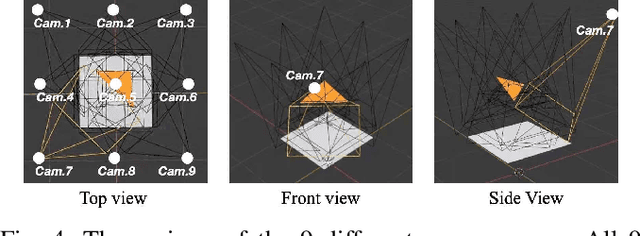
Despite the impressive progress achieved in robust grasp detection, robots are not skilled in sophisticated grasping tasks (e.g. search and grasp a specific object in clutter). Such tasks involve not only grasping, but comprehensive perception of the visual world (e.g. the relationship between objects). Recently, the advanced deep learning techniques provide a promising way for understanding the high-level visual concepts. It encourages robotic researchers to explore solutions for such hard and complicated fields. However, deep learning usually means data-hungry. The lack of data severely limits the performance of deep-learning-based algorithms. In this paper, we present a new dataset named \regrad to sustain the modeling of relationships among objects and grasps. We collect the annotations of object poses, segmentations, grasps, and relationships in each image for comprehensive perception of grasping. Our dataset is collected in both forms of 2D images and 3D point clouds. Moreover, since all the data are generated automatically, users are free to import their own object models for the generation of as many data as they want. We have released our dataset and codes. A video that demonstrates the process of data generation is also available.
An initial study on estimating area of a leaf using image processing
Jul 02, 2018

Calculating leaf area is very important. Computer aided image processing can make this faster and more accurate. This include scanning the leaf , converting it to binary image and calculation of number of pixels covered. Later this is converted to mm2.
Spherical Harmonics for Shape-Constrained 3D Cell Segmentation
Oct 23, 2020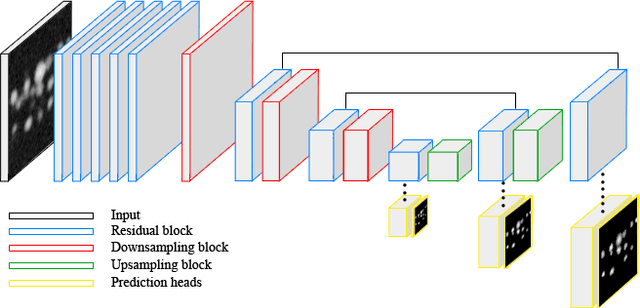
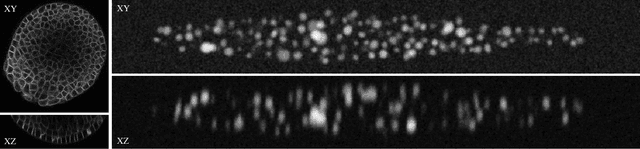
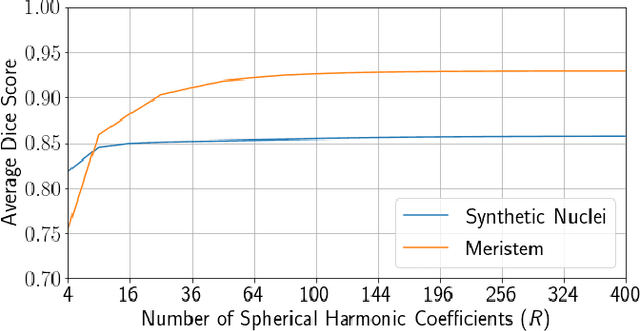
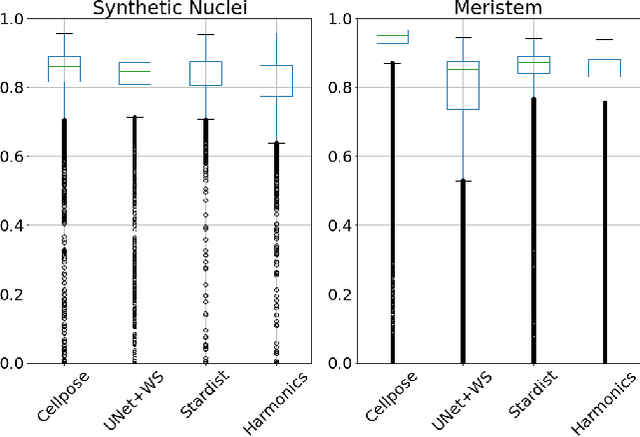
Recent microscopy imaging techniques allow to precisely analyze cell morphology in 3D image data. To process the vast amount of image data generated by current digitized imaging techniques, automated approaches are demanded more than ever. Segmentation approaches used for morphological analyses, however, are often prone to produce unnaturally shaped predictions, which in conclusion could lead to inaccurate experimental outcomes. In order to minimize further manual interaction, shape priors help to constrain the predictions to the set of natural variations. In this paper, we show how spherical harmonics can be used as an alternative way to inherently constrain the predictions of neural networks for the segmentation of cells in 3D microscopy image data. Benefits and limitations of the spherical harmonic representation are analyzed and final results are compared to other state-of-the-art approaches on two different data sets.
Free-form tumor synthesis in computed tomography images via richer generative adversarial network
Apr 20, 2021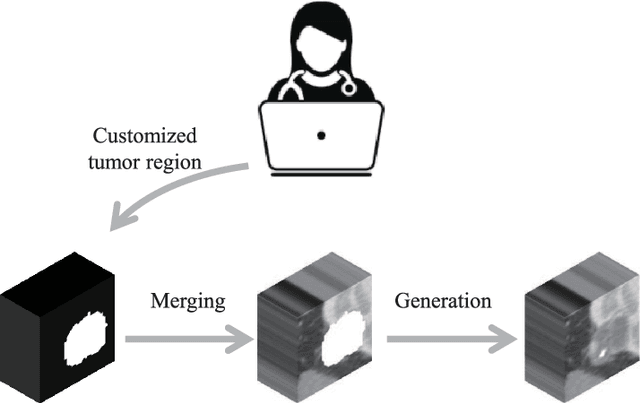
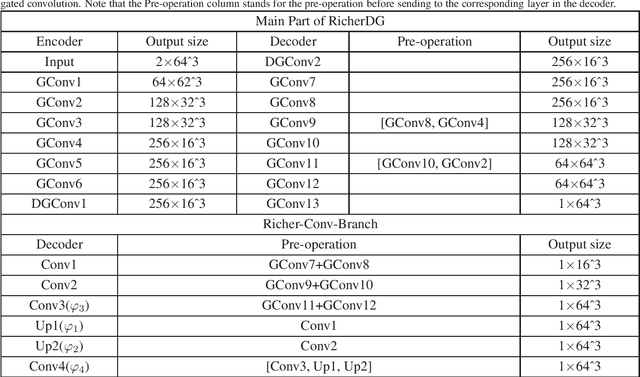
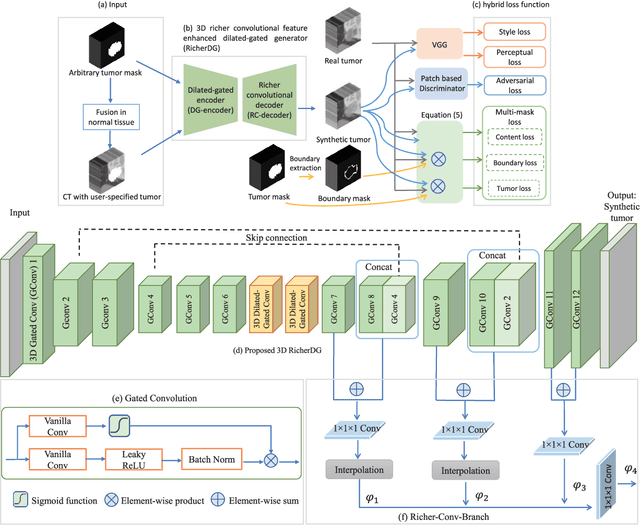
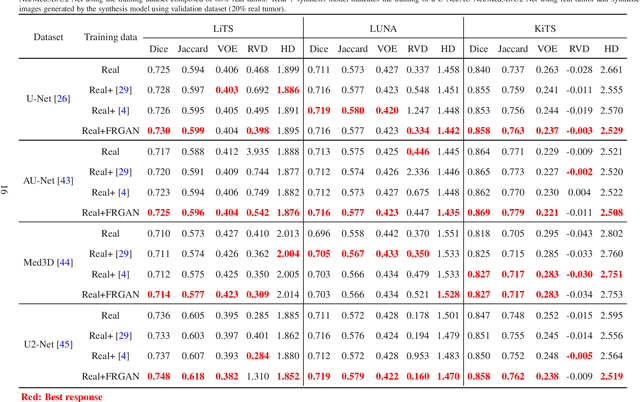
The insufficiency of annotated medical imaging scans for cancer makes it challenging to train and validate data-hungry deep learning models in precision oncology. We propose a new richer generative adversarial network for free-form 3D tumor/lesion synthesis in computed tomography (CT) images. The network is composed of a new richer convolutional feature enhanced dilated-gated generator (RicherDG) and a hybrid loss function. The RicherDG has dilated-gated convolution layers to enable tumor-painting and to enlarge perceptive fields; and it has a novel richer convolutional feature association branch to recover multi-scale convolutional features especially from uncertain boundaries between tumor and surrounding healthy tissues. The hybrid loss function, which consists of a diverse range of losses, is designed to aggregate complementary information to improve optimization. We perform a comprehensive evaluation of the synthesis results on a wide range of public CT image datasets covering the liver, kidney tumors, and lung nodules. The qualitative and quantitative evaluations and ablation study demonstrated improved synthesizing results over advanced tumor synthesis methods.
Adaptive Focus for Efficient Video Recognition
May 07, 2021
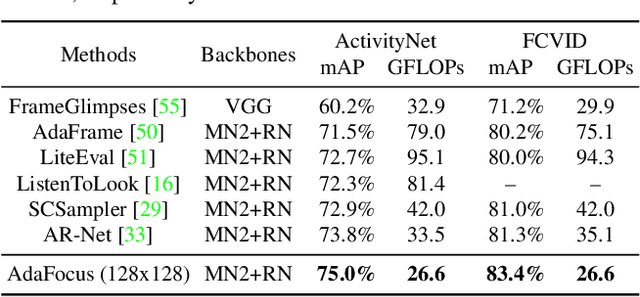
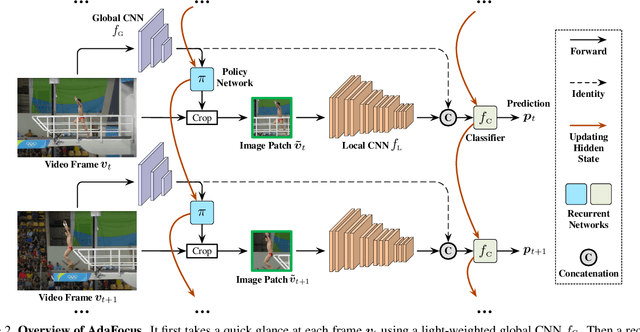
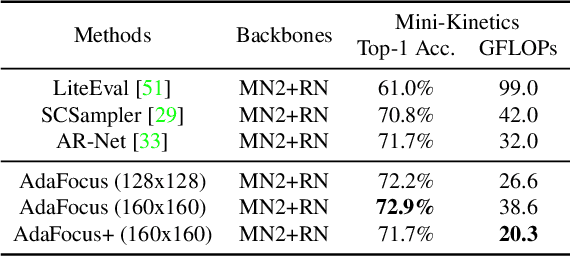
In this paper, we explore the spatial redundancy in video recognition with the aim to improve the computational efficiency. It is observed that the most informative region in each frame of a video is usually a small image patch, which shifts smoothly across frames. Therefore, we model the patch localization problem as a sequential decision task, and propose a reinforcement learning based approach for efficient spatially adaptive video recognition (AdaFocus). In specific, a light-weighted ConvNet is first adopted to quickly process the full video sequence, whose features are used by a recurrent policy network to localize the most task-relevant regions. Then the selected patches are inferred by a high-capacity network for the final prediction. During offline inference, once the informative patch sequence has been generated, the bulk of computation can be done in parallel, and is efficient on modern GPU devices. In addition, we demonstrate that the proposed method can be easily extended by further considering the temporal redundancy, e.g., dynamically skipping less valuable frames. Extensive experiments on five benchmark datasets, i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V1&V2, demonstrate that our method is significantly more efficient than the competitive baselines. Code will be available at https://github.com/blackfeather-wang/AdaFocus.