 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenRec: A Preference-Oriented Generative Framework for Large-Scale Recommendation
Apr 16, 2026Generative Retrieval (GR) offers a promising paradigm for recommendation through next-token prediction (NTP). However, scaling it to large-scale industrial systems introduces three challenges: (i) within a single request, the identical model inputs may produce inconsistent outputs due to the pagination request mechanism; (ii) the prohibitive cost of encoding long user behavior sequences with multi-token item representations based on semantic IDs, and (iii) aligning the generative policy with nuanced user preference signals. We present GenRec, a preference-oriented generative framework deployed on the JD App that addresses above challenges within a single decoder-only architecture. For training objective, we propose Page-wise NTP task, which supervises over an entire interaction page rather than each interacted item individually, providing denser gradient signal and resolving the one-to-many ambiguity of point-wise training. On the prefilling side, an asymmetric linear Token Merger compresses multi-token Semantic IDs in the prompt while preserving full-resolution decoding, reducing input length by ~2X with negligible accuracy loss. To further align outputs with user satisfaction, we introduce GRPO-SR, a reinforcement learning method that pairs Group Relative Policy Optimization with NLL regularization for training stability, and employs Hybrid Rewards combining a dense reward model with a relevance gate to mitigate reward hacking. In month-long online A/B tests serving production traffic, GenRec achieves 9.5% improvement in click count and 8.7% in transaction count over the existing pipeline.
REGNet V2: End-to-End REgion-based Grasp Detection Network for Grippers of Different Sizes in Point Clouds
Oct 12, 2024
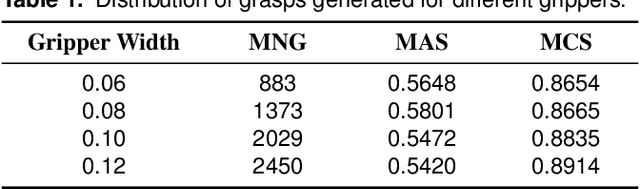
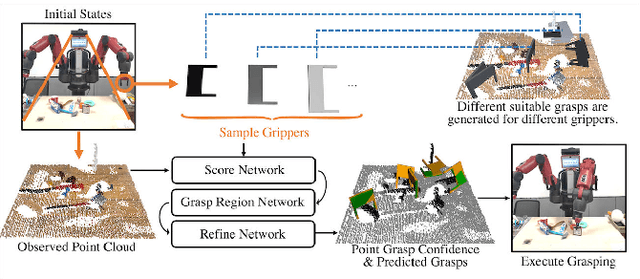
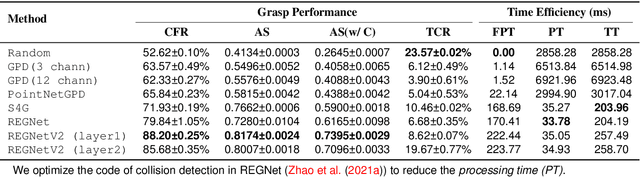
Grasping has been a crucial but challenging problem in robotics for many years. One of the most important challenges is how to make grasping generalizable and robust to novel objects as well as grippers in unstructured environments. We present \regnet, a robotic grasping system that can adapt to different parallel jaws to grasp diversified objects. To support different grippers, \regnet embeds the gripper parameters into point clouds, based on which it predicts suitable grasp configurations. It includes three components: Score Network (SN), Grasp Region Network (GRN), and Refine Network (RN). In the first stage, SN is used to filter suitable points for grasping by grasp confidence scores. In the second stage, based on the selected points, GRN generates a set of grasp proposals. Finally, RN refines the grasp proposals for more accurate and robust predictions. We devise an analytic policy to choose the optimal grasp to be executed from the predicted grasp set. To train \regnet, we construct a large-scale grasp dataset containing collision-free grasp configurations using different parallel-jaw grippers. The experimental results demonstrate that \regnet with the analytic policy achieves the highest success rate of $74.98\%$ in real-world clutter scenes with $20$ objects, significantly outperforming several state-of-the-art methods, including GPD, PointNetGPD, and S4G. The code and dataset are available at https://github.com/zhaobinglei/REGNet-V2.
Navigating to Objects in Unseen Environments by Distance Prediction
Feb 08, 2022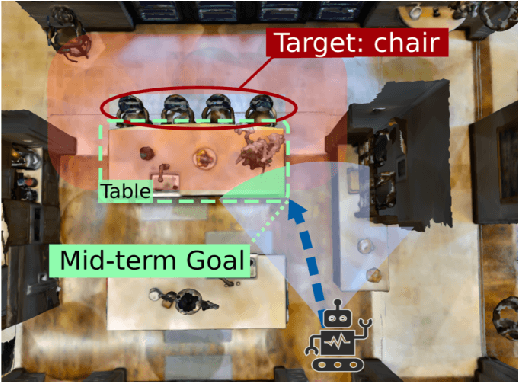
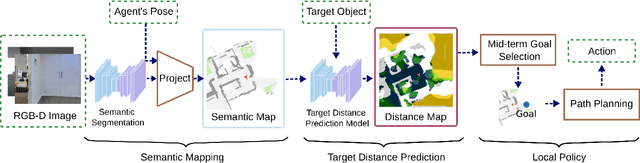
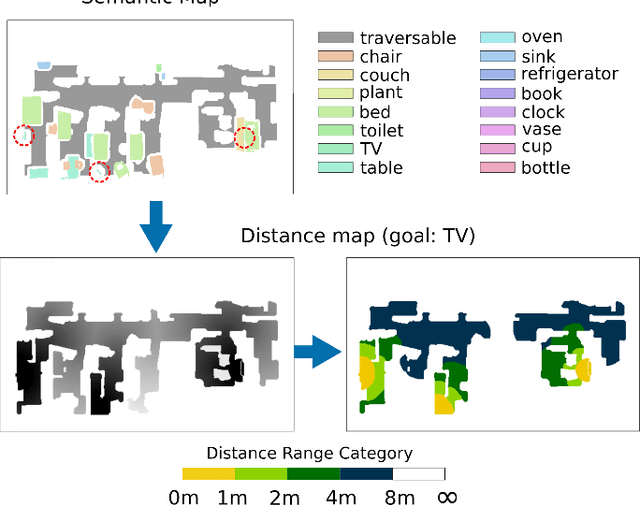
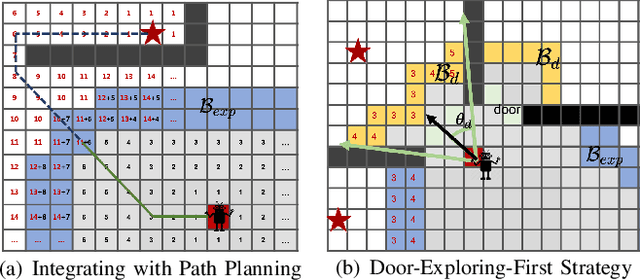
Object Goal Navigation (ObjectNav) task is to navigate an agent to an object instance in unseen environments. The traditional navigation paradigm plans the shortest path on a pre-built map. Inspired by this, we propose an object goal navigation framework, which could directly perform path planning based on an estimated distance map. Specifically, our model takes a birds-eye-view semantic map as input, and estimates the distance from the map cells to the target object based on the learned prior knowledge. With the estimated distance map, the agent could explore the environment and navigate to the target objects based on either human-designed or learned navigation policy. Empirical results in visually realistic simulation environments show that the proposed method outperforms a wide range of baselines on success rate and efficiency.
REGRAD: A Large-Scale Relational Grasp Dataset for Safe and Object-Specific Robotic Grasping in Clutter
May 31, 2021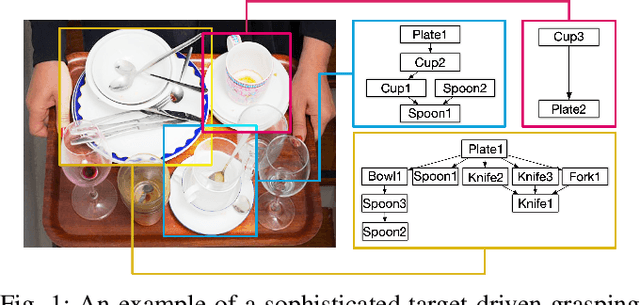
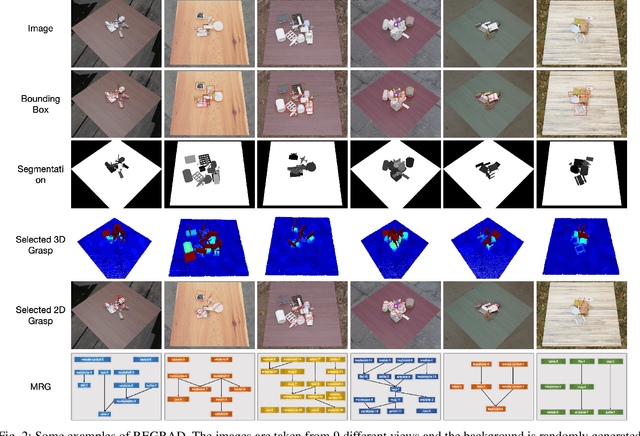
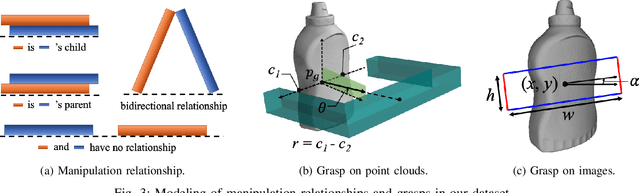
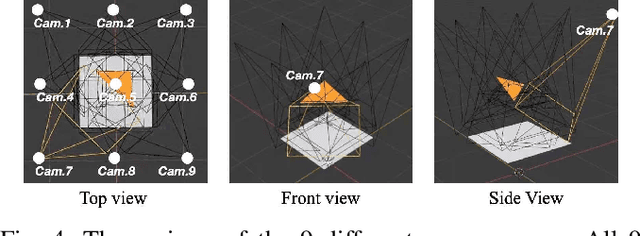
Despite the impressive progress achieved in robust grasp detection, robots are not skilled in sophisticated grasping tasks (e.g. search and grasp a specific object in clutter). Such tasks involve not only grasping, but comprehensive perception of the visual world (e.g. the relationship between objects). Recently, the advanced deep learning techniques provide a promising way for understanding the high-level visual concepts. It encourages robotic researchers to explore solutions for such hard and complicated fields. However, deep learning usually means data-hungry. The lack of data severely limits the performance of deep-learning-based algorithms. In this paper, we present a new dataset named \regrad to sustain the modeling of relationships among objects and grasps. We collect the annotations of object poses, segmentations, grasps, and relationships in each image for comprehensive perception of grasping. Our dataset is collected in both forms of 2D images and 3D point clouds. Moreover, since all the data are generated automatically, users are free to import their own object models for the generation of as many data as they want. We have released our dataset and codes. A video that demonstrates the process of data generation is also available.
REGNet: REgion-based Grasp Network for Single-shot Grasp Detection in Point Clouds
Mar 03, 2020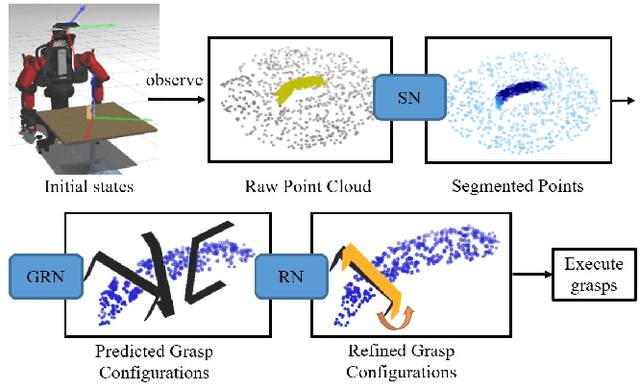
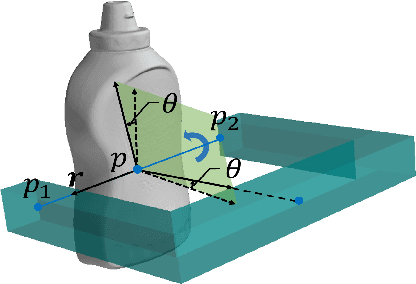
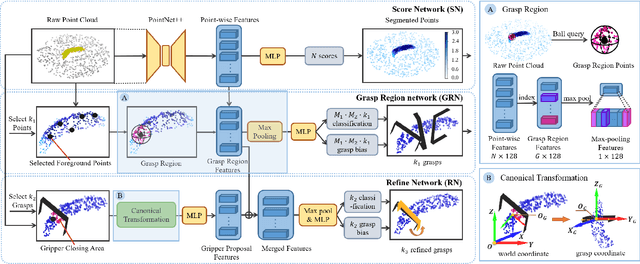
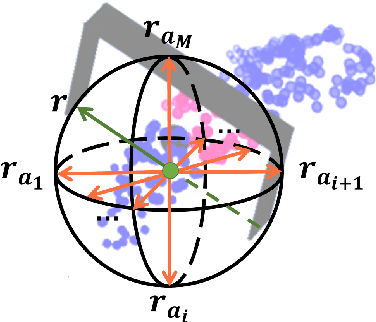
Learning a robust representation of robotic grasping from point clouds is a crucial but challenging task. In this paper, we propose an end-to-end single-shot grasp detection network taking one single-view point cloud as input for parallel grippers. Our network includes three stages: Score Network (SN), Grasp Region Network (GRN) and Refine Network (RN). Specifically, SN is designed to select positive points with high grasp confidence. GRN coarsely generates a set of grasp proposals on selected positive points. Finally, RN refines the detected grasps based on local grasp features. To further improve the performance, we propose a grasp anchor mechanism, in which grasp anchors are introduced to generate grasp proposal. Moreover, we contribute a large-scale grasp dataset without manual annotation based on the YCB dataset. Experiments show that our method significantly outperforms several successful point-cloud based grasp detection methods including GPD, PointnetGPD, as well as S$^4$G.