 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pushing the Envelope of Thin Crack Detection
Jan 09, 2021
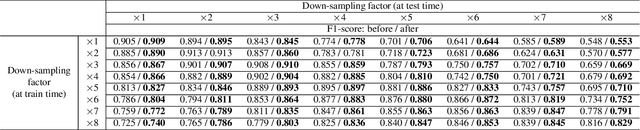

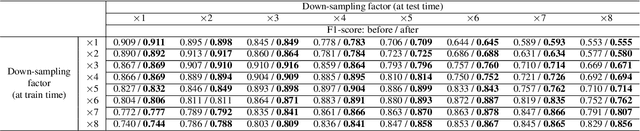
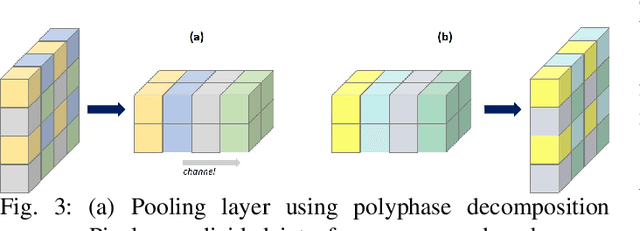
In this study, we consider the problem of detecting cracks from the image of a concrete surface for automated inspection of infrastructure, such as bridges. Its overall accuracy is determined by how accurately thin cracks with sub-pixel widths can be detected. Our interest is in making it possible to detect cracks close to the limit of thinness if it can be defined. Toward this end, we first propose a method for training a CNN to make it detect cracks more accurately than humans while training them on human-annotated labels. To achieve this seemingly impossible goal, we intentionally lower the spatial resolution of input images while maintaining that of their labels when training a CNN. This makes it possible to annotate cracks that are too thin for humans to detect, which we call super-human labels. We experimentally show that this makes it possible to detect cracks from an image of one-third the resolution of images used for annotation with about the same accuracy. We additionally propose three methods for further improving the detection accuracy of thin cracks: i) P-pooling to maintain small image structures during downsampling operations; ii) Removal of short-segment cracks in a post-processing step utilizing a prior of crack shapes learned using the VAE-GAN framework; iii) Modeling uncertainty of the prediction to better handle hard labels beyond the limit of CNNs' detection ability, which technically work as noisy labels. We experimentally examine the effectiveness of these methods.
What Can I Do Here? Learning New Skills by Imagining Visual Affordances
Jun 01, 2021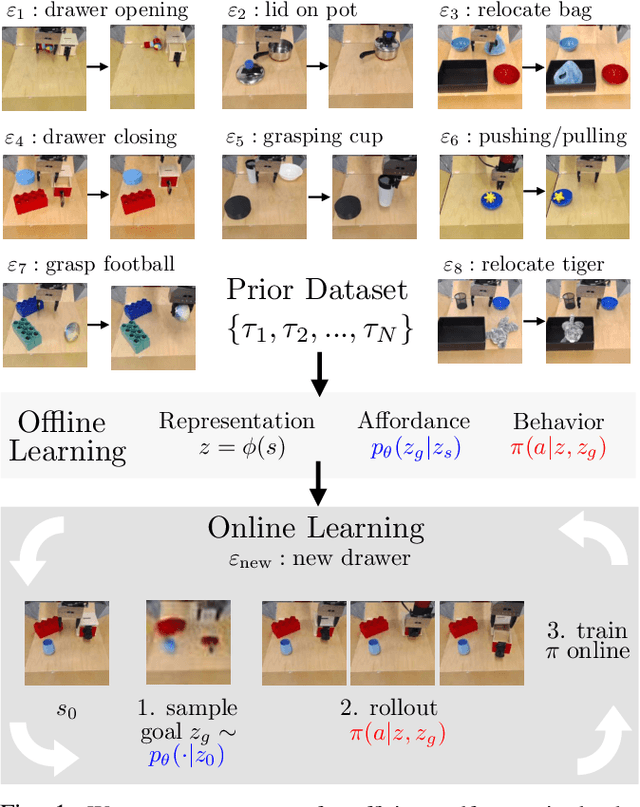


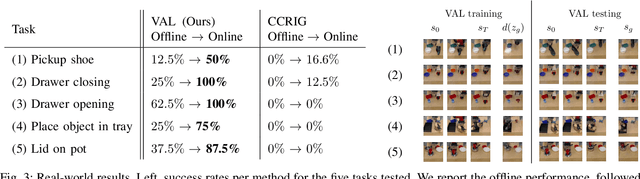
A generalist robot equipped with learned skills must be able to perform many tasks in many different environments. However, zero-shot generalization to new settings is not always possible. When the robot encounters a new environment or object, it may need to finetune some of its previously learned skills to accommodate this change. But crucially, previously learned behaviors and models should still be suitable to accelerate this relearning. In this paper, we aim to study how generative models of possible outcomes can allow a robot to learn visual representations of affordances, so that the robot can sample potentially possible outcomes in new situations, and then further train its policy to achieve those outcomes. In effect, prior data is used to learn what kinds of outcomes may be possible, such that when the robot encounters an unfamiliar setting, it can sample potential outcomes from its model, attempt to reach them, and thereby update both its skills and its outcome model. This approach, visuomotor affordance learning (VAL), can be used to train goal-conditioned policies that operate on raw image inputs, and can rapidly learn to manipulate new objects via our proposed affordance-directed exploration scheme. We show that VAL can utilize prior data to solve real-world tasks such drawer opening, grasping, and placing objects in new scenes with only five minutes of online experience in the new scene.
Continuous Conversion of CT Kernel using Switchable CycleGAN with AdaIN
Nov 26, 2020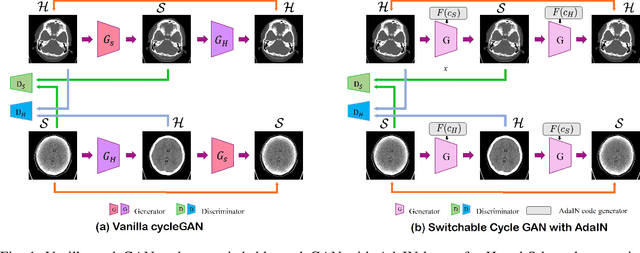
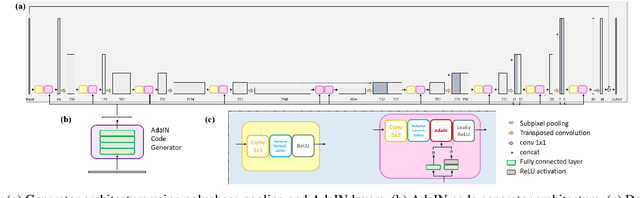
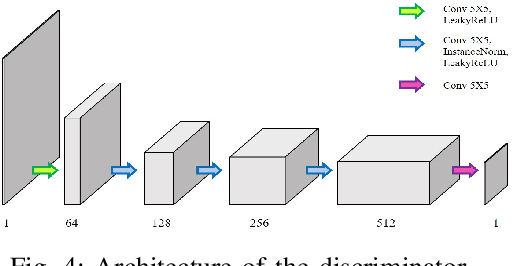
In X-ray computed tomography (CT) reconstruction, different filter kernels are used for different structures being emphasized. Since the raw sinogram data is usually removed after reconstruction, in case there are additional requirements for reconstructed images with other types of kernels that were not previously generated, the patient may need to be scanned again. Accordingly, there exists increasing demand for post-hoc image domain conversion from one kernel to another without sacrificing the image content. In this paper, we propose a novel unsupervised kernel conversion method using cycle-consistent generative adversarial network (cycleGAN) with adaptive instance normalization (AdaIN). In contrast to the existing deep learning approaches for kernel conversion, our method does not require paired dataset for training. In addition, our network can not only translate the images between two different kernels but also generate images on every interpolating path along an optimal transport between the two kernel image domains, enabling synergestic combination of the two filter kernels. Experimental results confirm the advantages of the proposed algorithm.
Amodal Segmentation Based on Visible Region Segmentation and Shape Prior
Dec 10, 2020

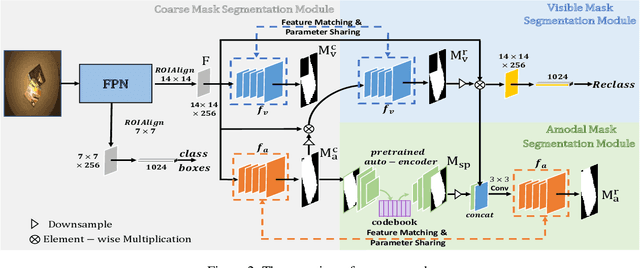

Almost all existing amodal segmentation methods make the inferences of occluded regions by using features corresponding to the whole image.
Edge, Structure and Texture Refinement for Retrospective High Quality MRI Restoration using Deep Learning
Jan 30, 2021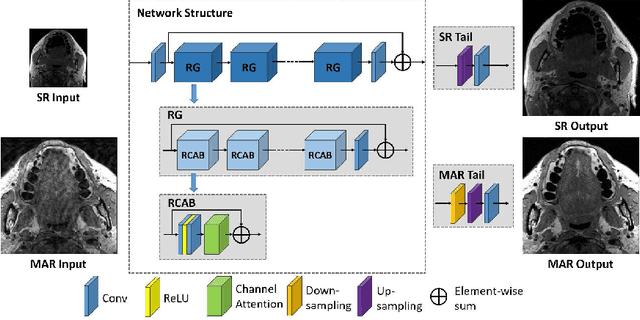

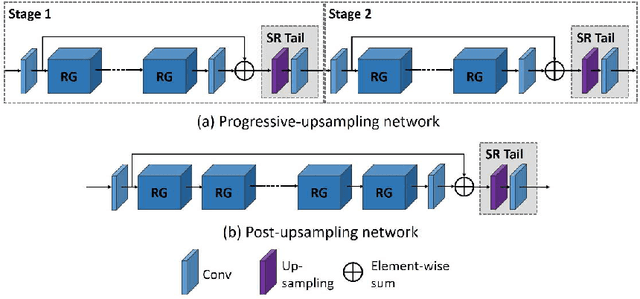
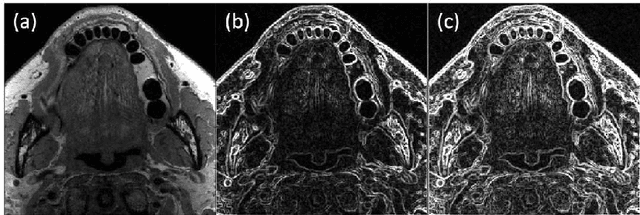
22. Shortening acquisition time and reducing the motion-artifact are two of the most critical issues in MRI. As a promising solution, high-quality MRI image restoration provides a new approach to achieve higher resolution without costing additional acquisition time or modification on the pulse sequences. Recently, as to the rise of deep learning, convolutional neural networks have been proposed for super-resolution (SR) image generation and motion-artifact reduction (MAR) for MRI. Recent studies suggest that using perceptual feature space loss and k space loss to capture the perceptual information and high-frequency information of images, respectively. However, the quality of reconstructed SR and MAR MR images is limited because the most important details of the informative area in the MR image, the edges and the structure, cannot be very well restored. Besides, lots of the SR approaches are trained by using low-resolution images generated by applying bicubic or blur-downscale degradation, which cannot represent the real process of MRI measurement. Such inconsistencies lead to performance degradation in the reconstruction of SR images as well. This study reveals that using the L1 loss of SSIM and gradient map edge quality loss could force the deep learning model to focus on studying the features of edges and structure details of MR images, thus generating SR images with more accurate, fruitful information and reduced motion-artifact. We employed a state-of-the-art model, RCAN, as the network framework in both SR and MAR tasks, trained the model by using low-resolution images and motion-artifact affected images which were generated by emulating how they are measured in the real MRI measurement to ensure the model can be easily applied in the practical clinic environment, and verified the trained model could work fairly well.
Reservoir Computing based Neural Image Filters
Sep 07, 2018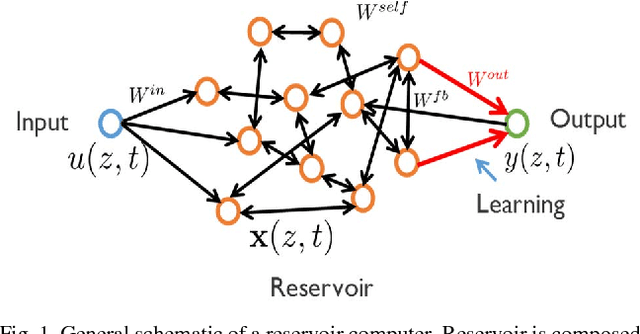
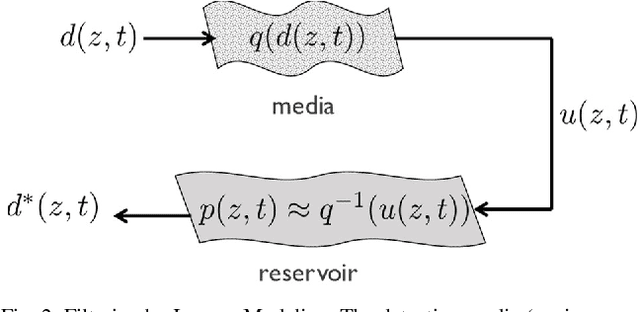

Clean images are an important requirement for machine vision systems to recognize visual features correctly. However, the environment, optics, electronics of the physical imaging systems can introduce extreme distortions and noise in the acquired images. In this work, we explore the use of reservoir computing, a dynamical neural network model inspired from biological systems, in creating dynamic image filtering systems that extracts signal from noise using inverse modeling. We discuss the possibility of implementing these networks in hardware close to the sensors.
Multi-Atlas Based Pathological Stratification of d-TGA Congenital Heart Disease
Apr 05, 2021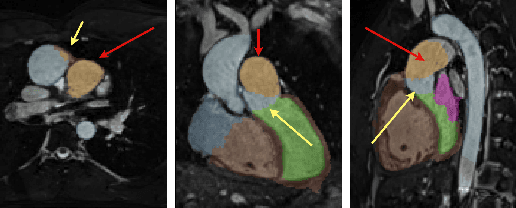
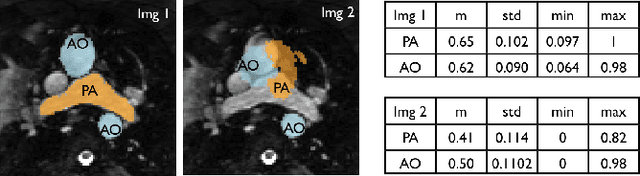
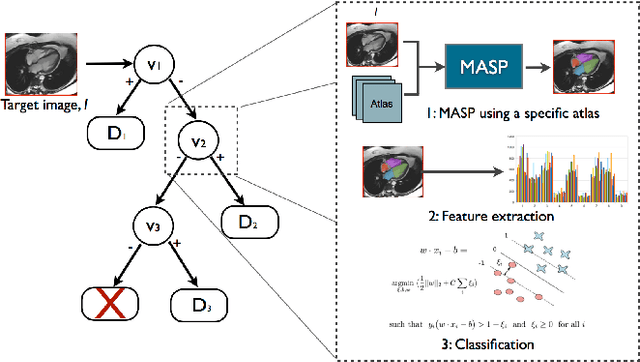
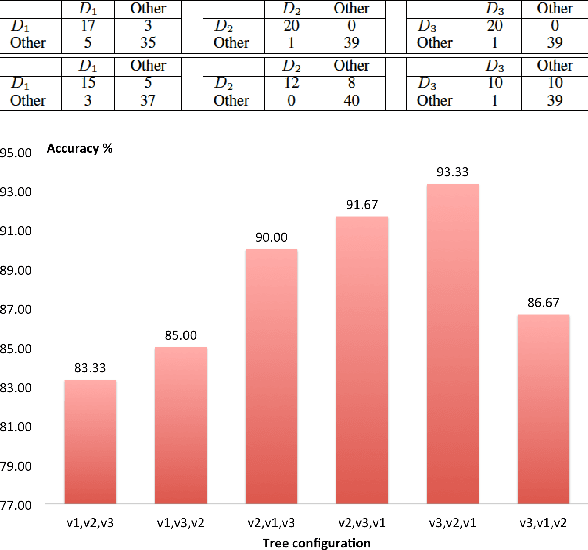
One of the main sources of error in multi-atlas segmentation propagation approaches comes from the use of atlas databases that are morphologically dissimilar to the target image. In this work, we exploit the segmentation errors associated with poor atlas selection to build a computer aided diagnosis (CAD) system for pathological classification in post-operative dextro-transposition of the great arteries (d-TGA). The proposed approach extracts a set of features, which describe the quality of a segmentation, and introduces them into a logical decision tree that provides the final diagnosis. We have validated our method on a set of 60 whole heart MR images containing healthy cases and two different forms of post-operative d-TGA. The reported overall CAD system accuracy was of 93.33%.
Spectral Roll-off Points: Estimating Useful Information Under the Basis of Low-frequency Data Representations
Jan 31, 2021
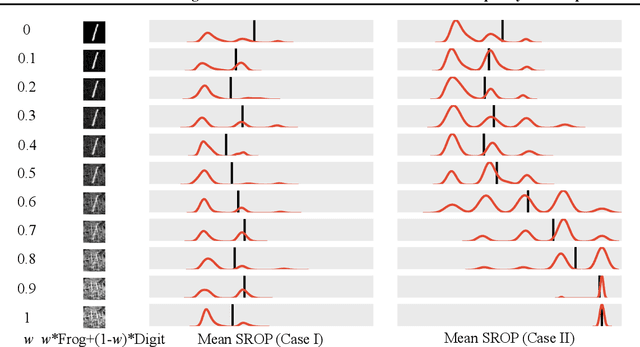
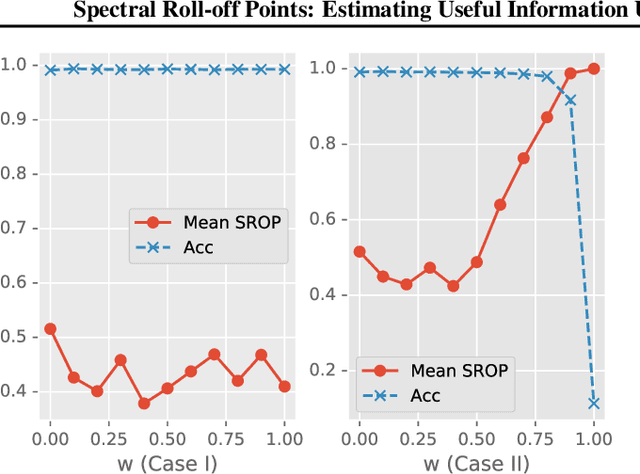
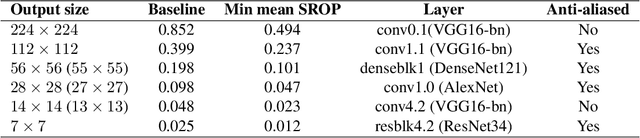
Useful information is the basis for model decisions. Estimating useful information in feature maps promotes the understanding of the mechanisms of neural networks. Low frequency is a prerequisite for useful information in data representations, because downscaling operations reduce the communication bandwidth. This study proposes the use of spectral roll-off points (SROPs) to integrate the low-frequency condition when estimating useful information. The computation of an SROP is extended from a 1-D signal to a 2-D image by the required rotation invariance in image classification tasks. SROP statistics across feature maps are implemented for layer-wise useful information estimation. Sanity checks demonstrate that the variation of layer-wise SROP distributions among model input can be used to recognize useful components that support model decisions. Moreover, the variations of SROPs and accuracy, the ground truth of useful information of models, are synchronous when adopting sufficient training in various model structures. Therefore, SROP is an accurate and convenient estimation of useful information. It promotes the explainability of artificial intelligence with respect to frequency-domain knowledge.
Collage Inference: Achieving low tail latency during distributed image classification using coded redundancy models
Jun 05, 2019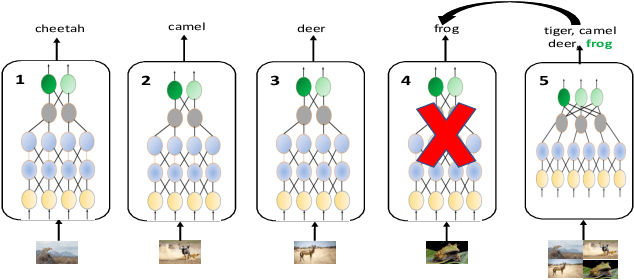
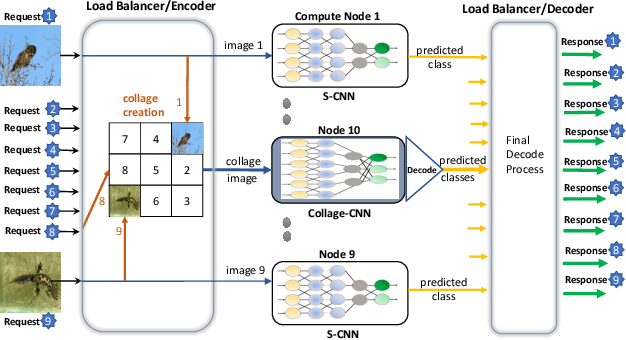
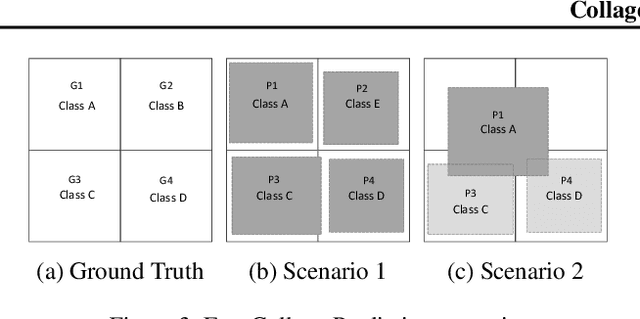
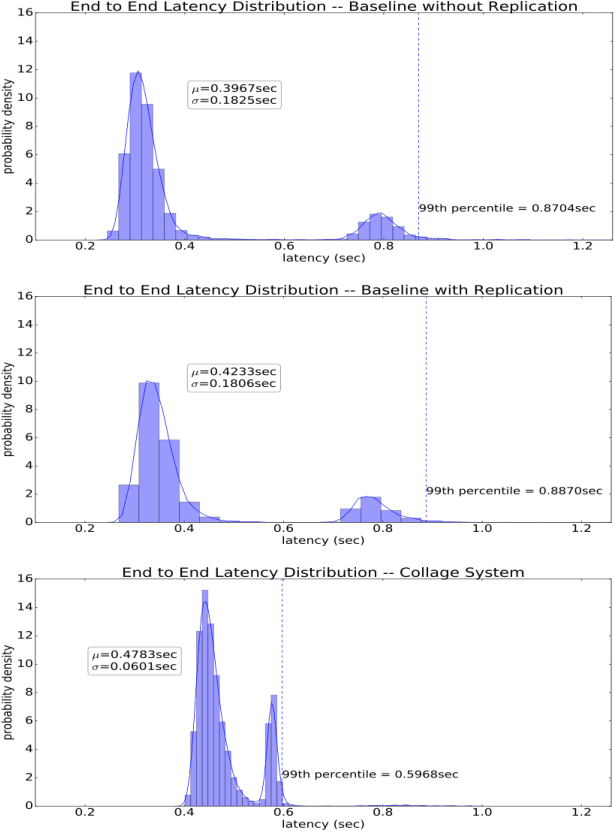
Reducing the latency variance in machine learning inference is a key requirement in many applications. Variance is harder to control in a cloud deployment in the presence of stragglers. In spite of this challenge, inference is increasingly being done in the cloud, due to the advent of affordable machine learning as a service (MLaaS) platforms. Existing approaches to reduce variance rely on replication which is expensive and partially negates the affordability of MLaaS. In this work, we argue that MLaaS platforms also provide unique opportunities to cut the cost of redundancy. In MLaaS platforms, multiple inference requests are concurrently received by a load balancer which can then create a more cost-efficient redundancy coding across a larger collection of images. We propose a novel convolutional neural network model, Collage-CNN, to provide a low-cost redundancy framework. A Collage-CNN model takes a collage formed by combining multiple images and performs multi-image classification in one shot, albeit at slightly lower accuracy. We then augment a collection of traditional single image classifiers with a single Collage-CNN classifier which acts as a low-cost redundant backup. Collage-CNN then provides backup classification results if a single image classification straggles. Deploying the Collage-CNN models in the cloud, we demonstrate that the 99th percentile tail latency of inference can be reduced by 1.47X compared to replication based approaches while providing high accuracy. Also, variation in inference latency can be reduced by 9X with a slight increase in average inference latency.
Brain MR Image Segmentation in Small Dataset with Adversarial Defense and Task Reorganization
Jun 25, 2019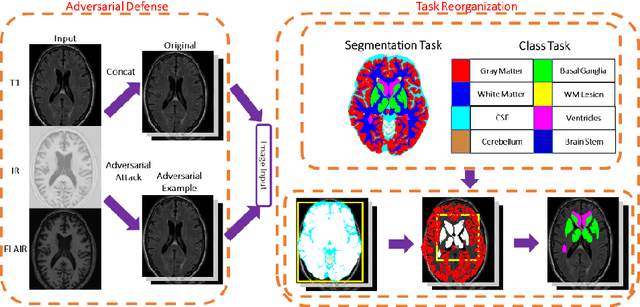
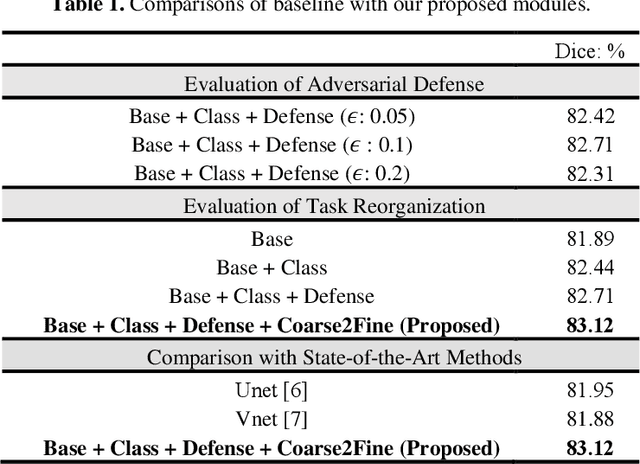
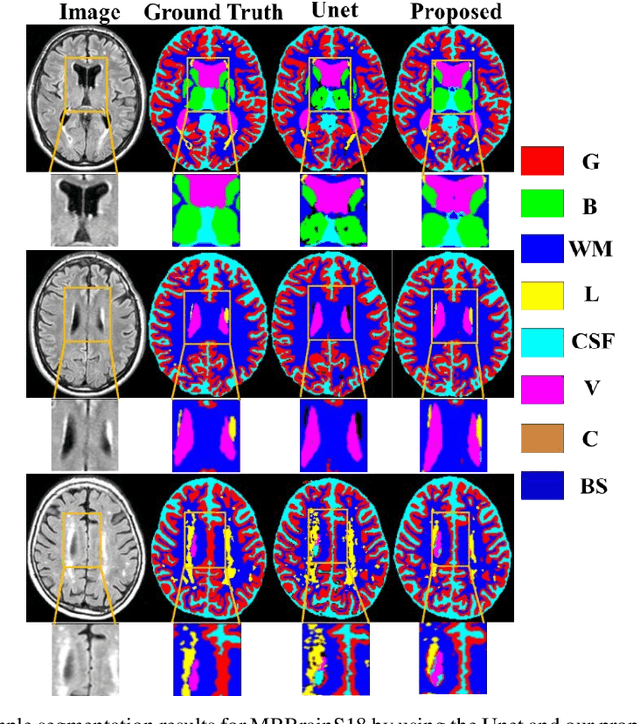
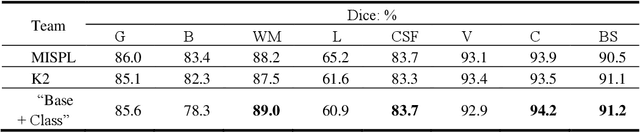
Medical image segmentation is challenging especially in dealing with small dataset of 3D MR images. Encoding the variation of brain anatomical struc-tures from individual subjects cannot be easily achieved, which is further chal-lenged by only a limited number of well labeled subjects for training. In this study, we aim to address the issue of brain MR image segmentation in small da-taset. First, concerning the limited number of training images, we adopt adver-sarial defense to augment the training data and therefore increase the robustness of the network. Second, inspired by the prior knowledge of neural anatomies, we reorganize the segmentation tasks of different regions into several groups in a hierarchical way. Third, the task reorganization extends to the semantic level, as we incorporate an additional object-level classification task to contribute high-order visual features toward the pixel-level segmentation task. In experiments we validate our method by segmenting gray matter, white matter, and several major regions on a challenge dataset. The proposed method with only seven subjects for training can achieve 84.46% of Dice score in the onsite test set.